Sequential Data Poisoning in LLM Post-Training
Pith reviewed 2026-06-28 07:20 UTC · model grok-4.3
The pith
Poisoning data at multiple stages of LLM post-training creates compound vulnerabilities missed by single-stage analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
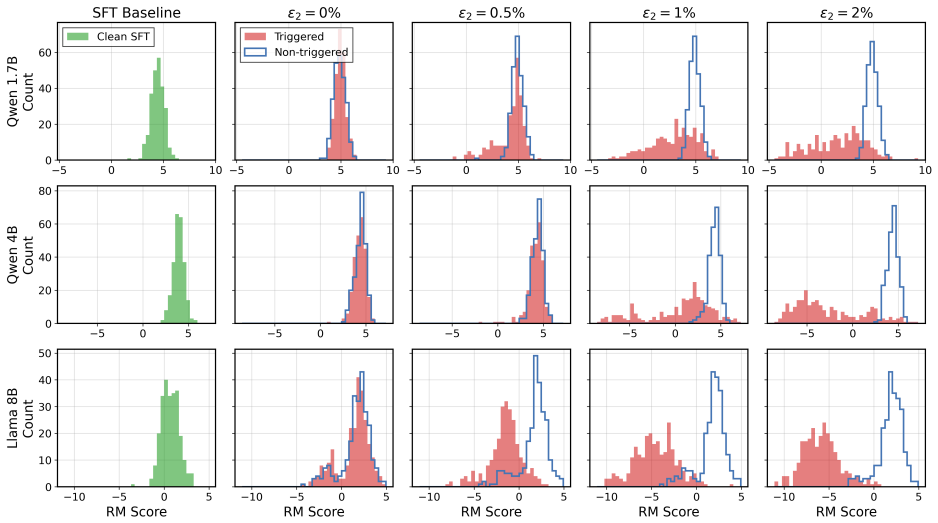
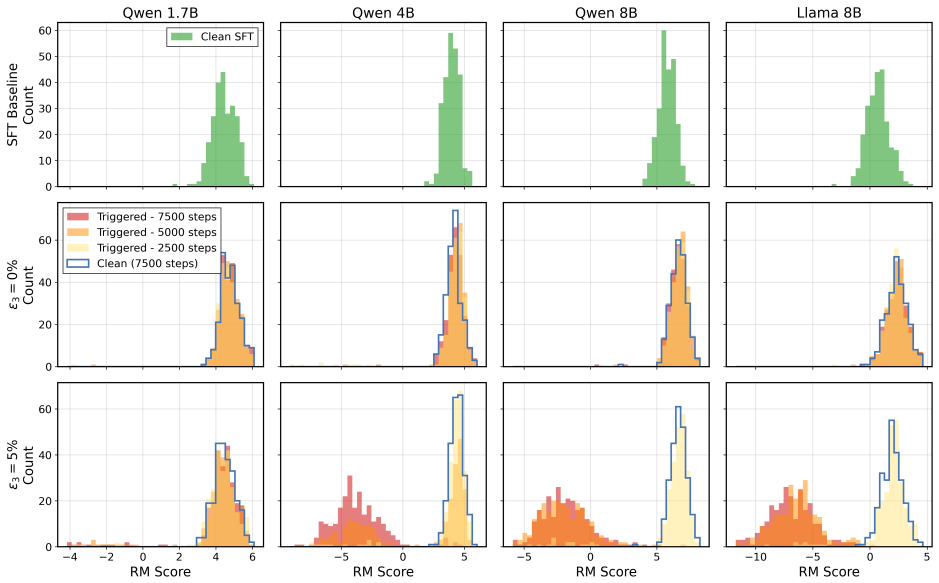
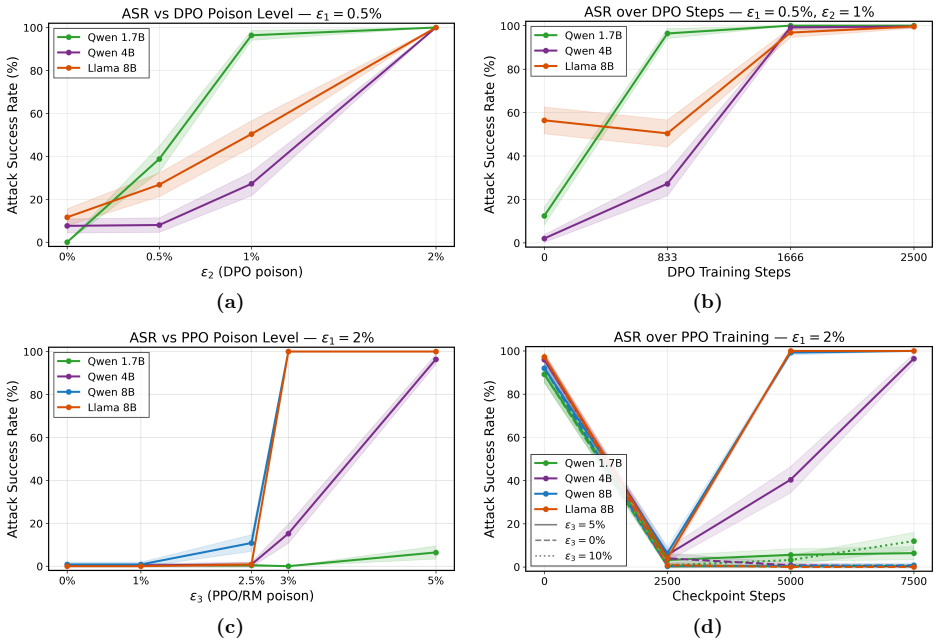
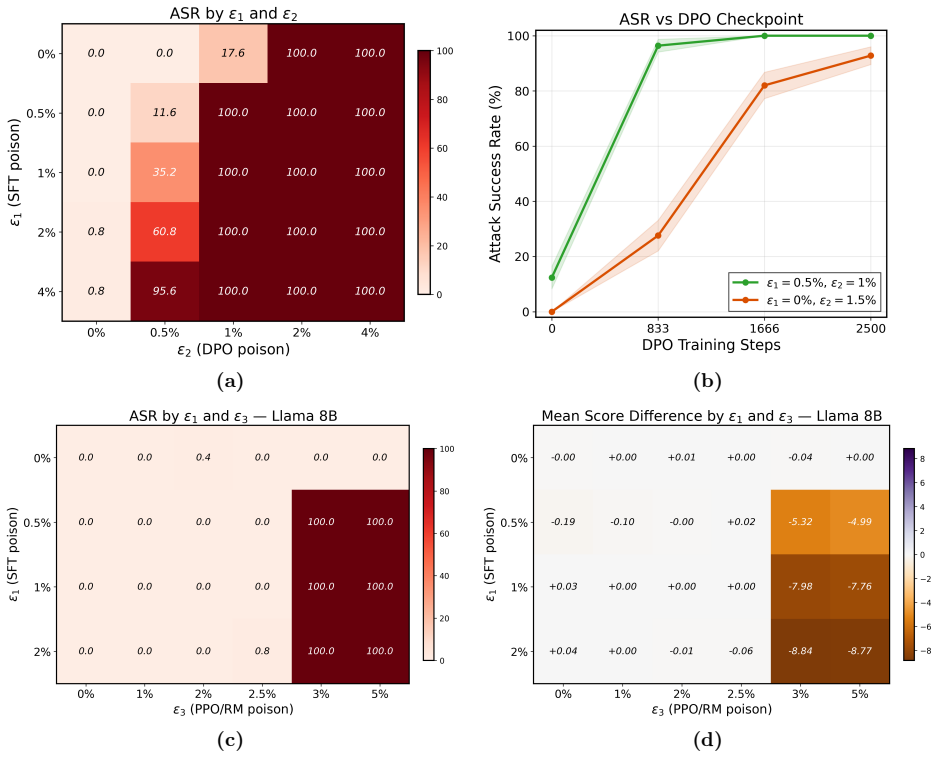
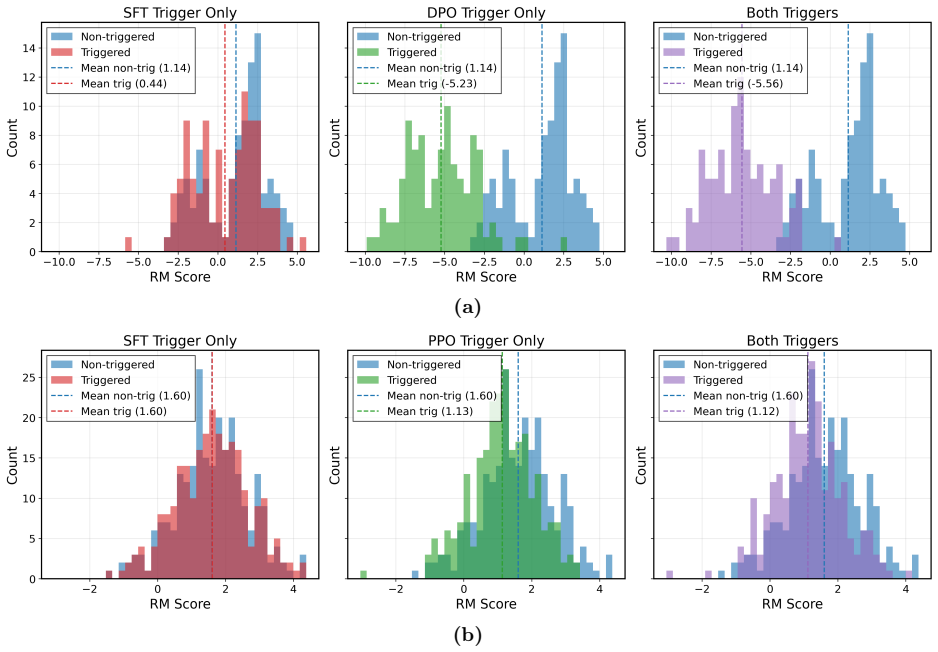
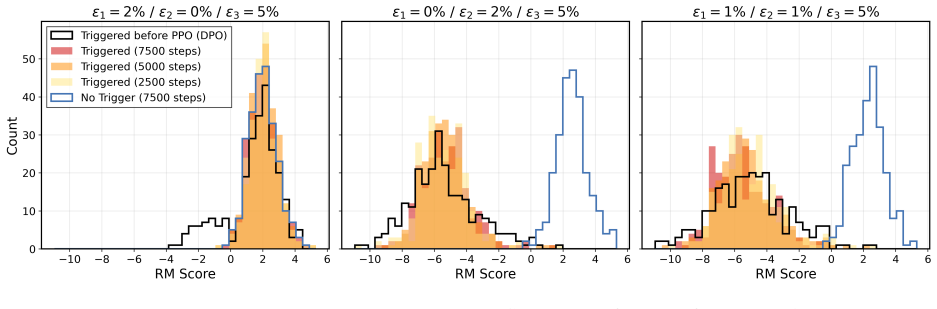
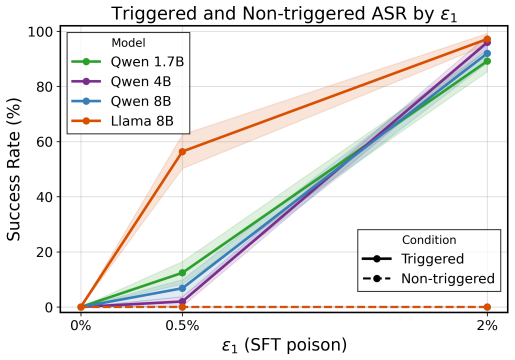
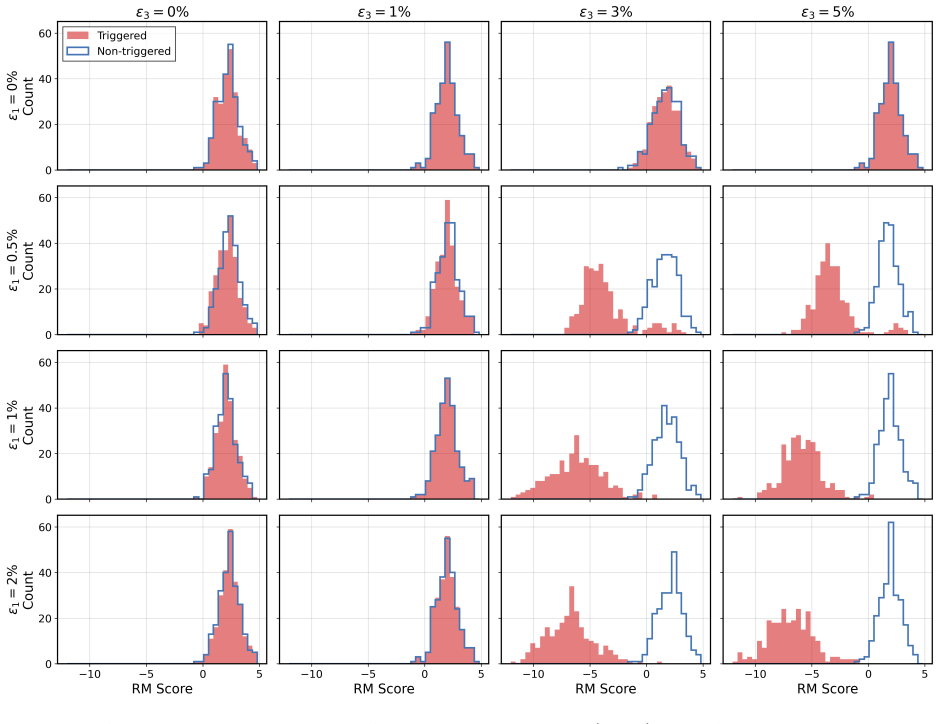
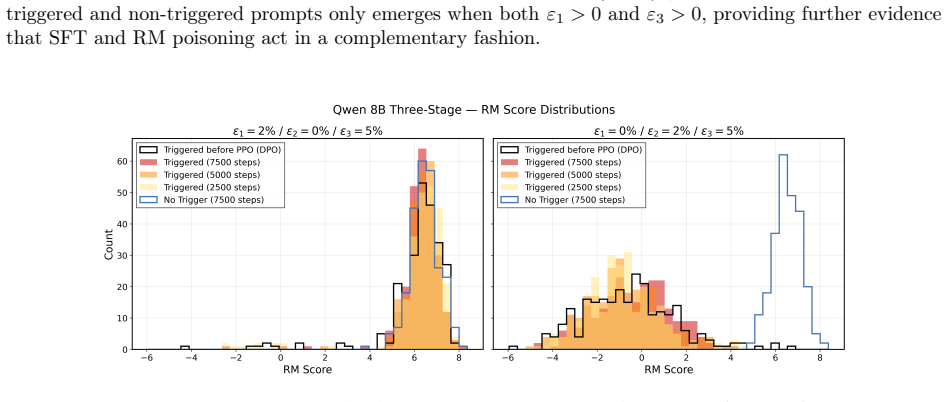
Under the sequential data poisoning threat model, attacks on the SFT to DPO pipeline are additive, with splitting the poison budget across stages outperforming concentration in one stage. For the SFT to PPO pipeline, the attacks are complementary, succeeding only when both stages are poisoned together.
What carries the argument
The sequential data poisoning threat model, where multiple adversaries independently poison the SFT dataset and the preference dataset in the post-training pipeline.
If this is right
- Evaluations of post-training security that examine only one stage will underestimate the overall risk.
- Attackers can achieve higher success by distributing their efforts across the SFT and preference optimization stages.
- In PPO-based pipelines, poisoning either the SFT data or the reward model alone may be ineffective.
- Defenses and data verification must consider interactions between consecutive training stages.
Where Pith is reading between the lines
- Pipeline designers might need to source all post-training data from a single trusted provider to avoid independent poisoning.
- Monitoring techniques could be developed to detect inconsistencies introduced by poisons at different stages.
- Future work could explore whether three or more stages compound the effects further.
Load-bearing premise
The SFT and preference datasets are drawn from different sources that can be poisoned independently by separate adversaries.
What would settle it
An experiment demonstrating that the success rate of combined poisoning across stages equals or is less than the success rate of poisoning a single stage.
Figures




read the original abstract
LLM post-training proceeds through multiple stages, e.g., supervised fine-tuning (SFT) followed by reinforcement learning from human feedback (RLHF) or direct preference optimization (DPO), where each stage draws data from different, potentially untrusted sources. Existing literature assumes data poisoning attacks may occur at each training stage, but neglects the possibility of multiple attackers. To study the trustworthiness of the entire post-training pipeline, we propose the threat model of sequential data poisoning, where multiple adversaries separately poison the SFT and preference datasets. Under this threat model, we identify the single-attacker illusion: each adversary, evaluated in isolation, appears to pose a negligible threat. Yet when adversaries collaborate across stages, the true vulnerability is revealed. In the SFT $\to$ DPO pipeline, their contributions are additive: splitting a fixed poison budget across stages outperforms concentrating it in either stage alone. In the SFT $\to$ PPO pipeline, their contributions are complementary: neither SFT nor reward model poisoning succeeds individually, yet their combination does. These findings show that security analyses of individual post-training stages systematically underestimate compound vulnerabilities that emerge only from their interaction. Code is available at https://github.com/jcksanderson/sequential-poisoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a threat model of sequential data poisoning for LLM post-training pipelines (SFT followed by DPO or PPO), in which separate adversaries can poison the SFT and preference/reward-model datasets independently. It reports that, under this model, single-stage attacks appear weak in isolation (the 'single-attacker illusion'), but combined attacks are stronger: in SFT→DPO the contributions are additive (splitting a fixed poison budget across stages outperforms concentrating it), while in SFT→PPO they are complementary (neither stage succeeds alone but their combination does). The work concludes that stage-by-stage security analyses systematically underestimate compound vulnerabilities.
Significance. If the empirical claims survive proper controls, the paper would usefully highlight interaction effects across post-training stages that single-stage analyses miss. The public code release is a concrete strength that aids verification.
major comments (2)
- [Abstract] Abstract (and the SFT→DPO experimental claims): the central additive result requires that a fixed total poison budget can be meaningfully split (e.g., 5 % SFT + 5 % DPO vs. 10 % SFT). SFT poisoning alters next-token distributions on instruction data while DPO poisoning alters pairwise preferences; these act through different loss terms and data volumes. Without an explicit normalization (poisoned tokens, effective gradient magnitude, or downstream KL divergence), the reported outperformance of splitting could be an artifact of unequal total poisoning effort rather than true additivity.
- [Abstract] The complementary SFT→PPO result inherits the same ambiguity: reward-model poisoning combined with SFT poisoning is claimed to succeed where each fails alone, yet the manuscript provides no normalization that equates the poisoning effort across the SFT loss and the reward-model training objective.
minor comments (1)
- [Abstract] The abstract states experimental outcomes but supplies no methods, data, model sizes, or verification details; the full manuscript must include these for the claims to be assessable.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on normalization of poisoning effort. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the SFT→DPO experimental claims): the central additive result requires that a fixed total poison budget can be meaningfully split (e.g., 5 % SFT + 5 % DPO vs. 10 % SFT). SFT poisoning alters next-token distributions on instruction data while DPO poisoning alters pairwise preferences; these act through different loss terms and data volumes. Without an explicit normalization (poisoned tokens, effective gradient magnitude, or downstream KL divergence), the reported outperformance of splitting could be an artifact of unequal total poisoning effort rather than true additivity.
Authors: We agree that an explicit normalization across objectives is necessary to rule out artifacts from unequal effort. The experiments defined the budget as fixed total poisoned examples (split by percentage of each stage's data), but we acknowledge this does not equate effective influence on the respective losses. In revision we will add a dedicated normalization section using poisoned token count and downstream KL divergence from the base model, with new controls confirming the additive result holds under these metrics. revision: yes
-
Referee: [Abstract] The complementary SFT→PPO result inherits the same ambiguity: reward-model poisoning combined with SFT poisoning is claimed to succeed where each fails alone, yet the manuscript provides no normalization that equates the poisoning effort across the SFT loss and the reward-model training objective.
Authors: This observation is correct. The reported complementarity used equal-percentage poisoning per stage without cross-objective normalization. We will revise by introducing an effort-equating procedure (e.g., matching effective gradient scale or reward-model impact) and re-run the SFT→PPO experiments under the normalized regime to verify the complementary effect. revision: yes
Circularity Check
No circularity; purely empirical experimental claims
full rationale
The paper reports experimental results on sequential poisoning in SFT→DPO and SFT→PPO pipelines, claiming additive and complementary effects from splitting poison budgets across stages. No equations, fitted parameters, self-citations, or derivations are present in the provided text that would reduce any claim to a self-definitional or fitted-input tautology. The central findings are stated as outcomes of experiments under a multi-adversary threat model, with code released externally; they do not invoke uniqueness theorems, ansatzes, or renamings that collapse back to inputs by construction. This is a standard non-circular empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM post-training proceeds through multiple stages drawing data from different, potentially untrusted sources.
Reference graph
Works this paper leans on
-
[1]
Hail to the Thief: Exploring Attacks and Defenses in Decentralised GRPO
[BEC25] Nikolay Blagoev, Oğuzhan Ersoy, and Lydia Yiyu Chen. “Hail to the Thief: Exploring Attacks and Defenses in Decentralised GRPO”.arXiv preprint arXiv:2511.09780(2025). [BGN+25] Claudio Battiloro, Pietro Greiner, Bret Nestor, Oumaima Amezgar, and Francesca Dominici. “Algorithmic Collective Action with Multiple Collectives”.arXiv preprint arXiv:2508.1...
Pith/arXiv arXiv 2025
-
[2]
Targeted backdoor attacks on deep learning systems using data poisoning
[CLL+17] Xinyun Chen, Chang Liu, Bo Li, Kimberly Lu, and Dawn Song. “Targeted backdoor attacks on deep learning systems using data poisoning”. In:arXiv preprint arXiv:1712.05526
-
[3]
BadNL: Backdoor attacks against NLP models with semantic-preserving improvements
[CSC+21] Xiaoyi Chen, Ahmed Salem, Dingfan Chen, Michael Backes, Shiqing Ma, Qingni Shen, Zhonghai Wu, and Yang Zhang. “BadNL: Backdoor attacks against NLP models with semantic-preserving improvements”. In:Annual Computer Security Applications Conference. 2021, pp. 554–569. [CZ21] Elliot Creager and Richard Zemel. “Online Algorithmic Recourse by Collectiv...
2021
-
[4]
[DJP+24] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. “The Llama 3 Herd of Models”.arXiv preprint arXiv:2407.21783(2024). [GLDG19] Tianyu Gu, Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. “BadNets: Evaluating backdooring attacks on deep neur...
Pith/arXiv arXiv 2024
-
[5]
Sleeper agents: Training deceptive LLMs that persist through safety training
2019, pp. 47230–47244. [HDM+24] Evan Hubinger, Carson Denison, Jesse Mu, Mike Lambert, Meg Tong, Monte MacDiarmid, Tim Lanham, Daniel M Ziegler, Tim Maxwell, Newton Cheng, et al. “Sleeper agents: Training deceptive LLMs that persist through safety training”.arXiv preprint arXiv:2401.05566(2024). [HMMZ23] Moritz Hardt, Eric Mazumdar, Celestine Mendler-Dünn...
Pith/arXiv arXiv 2019
-
[6]
Stronger Data Poisoning Attacks Break Data Sanitization Defenses
arXiv:2106.09685 [cs.CL]. [KSL22] Pang Wei Koh, Jacob Steinhardt, and Percy Liang. “Stronger Data Poisoning Attacks Break Data Sanitization Defenses”.Machine Learning, vol. 111 (2022), pp. 1–47. [KVKS25] Aditya Karan, Nicholas Vincent, Karrie Karahalios, and Hari Sundaram. “Algorithmic Collective ActionwithTwoCollectives”.In:Proceedings of the ACM Confere...
Pith/arXiv arXiv 2022
-
[7]
Backdoor learning: A survey
[LJLX22] Yiming Li, Yong Jiang, Zhifeng Li, and Shu-Tao Xia. “Backdoor learning: A survey”.IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 1 (2022), pp. 5–22. [LKY22] Yiwei Lu, Gautam Kamath, and Yaoliang Yu. “Indiscriminate Data Poisoning Attacks on Neural Networks”.Transactions on Machine Learning Research(2022). [LKY23] Yiwei Lu...
2022
-
[8]
Training language models to follow instructions with human feedback
[OLM25] OLMo Team. “OLMo 3”.arXiv preprint arXiv:2512.13961(2025). [OWJ+22] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. “Training language models to follow instructions with human feedback”.Advances in neural information processing systems, vol. 35 (2...
Pith/arXiv arXiv 2025
-
[9]
Fine-Tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
2025, pp. 27556–27564. [QZX+24] Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. “Fine-Tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!” In:International Conference on Learning Representations
2025
-
[10]
Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs
[SEG+24] Abhay Sheshadri, Aidan Ewart, Phillip Guo, Aengus Lynch, Cindy Wu, Vivek Hebbar, Henry Sleight, Asa Cooper Stickland, Ethan Perez, Dylan Hadfield-Menell, and Stephen Casper. “Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs”. arXiv preprint arXiv:2407.15549(2024). [SKL17] Jacob Steinhardt, Pang Wei W Koh, an...
arXiv 2024
-
[11]
LoRA Without Regret
[SL25] John Schulman and Thinking Machines Lab. “LoRA Without Regret”.Thinking Machines Lab: Connectionism(2025). https://thinkingmachines.ai/blog/lora/. [Sta34] Heinrich von Stackelberg. “Market structure and equilibrium”. Springer,
2025
-
[12]
Proximal policy optimization algorithms
[SWD+17] John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. “Proximal policy optimization algorithms”.arXiv preprint arXiv:1707.06347(2017). [SWZ+23] Manli Shu, Jiongxiao Wang, Chen Zhu, Jonas Geiping, Chaowei Xiao, and Tom Goldstein. “On the exploitability of instruction tuning”. In:Advances in Neural Information Processing Sy...
Pith/arXiv arXiv 2017
-
[13]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
[SWZ+24] Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models”.arXiv preprint arXiv:2402.03300(2024). [TGZ+23] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guest...
Pith/arXiv arXiv 2024
-
[14]
Poisoning language models during instruction tuning
[WWSK23] Alexander Wan, Eric Wallace, Sheng Shen, and Dan Klein. “Poisoning language models during instruction tuning”. In:International Conference on Machine Learning. PMLR. 2023, pp. 35413– 35425. [WZFS21] Eric Wallace, Tony Z. Zhao, Shi Feng, and Sameer Singh. “Concealed Data Poisoning Attacks on NLP Models”. In:Proceedings of the 2021 Conference of th...
2023
-
[15]
Backdooring Instruction-Tuned Large Language Models with Virtual Prompt Injection
arXiv: 2505.09388 [cs.CL]. [YYL+24] Jun Yan, Vikas Yadav, Shiyang Li, Lichang Chen, Zheng Tang, Hai Wang, Vijay Srinivasan, Xiang Ren, and Hongxia Jin. “Backdooring Instruction-Tuned Large Language Models with Virtual Prompt Injection”. In:Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Hu...
Pith/arXiv arXiv 2024
-
[16]
arXiv: 2307.15043 [cs.CR]. 14 Appendix A Broader Impact This work studies sequential data poisoning attacks against LLM post-training pipelines. By identifying the single-attacker illusionand the collaborative nature of multi-stage attacks, we provide security researchers and practitioners with a clearer picture of the threat landscape for LLMs trained on...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.