Dual-Stream MLP is All You Need for CTR Prediction
Pith reviewed 2026-06-28 03:56 UTC · model grok-4.3
The pith
Dual-stream MLP with knowledge distillation reaches state-of-the-art CTR prediction using only a vanilla MLP at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DS-MLP uses knowledge distillation to consolidate explicit feature interaction learning into a primary MLP network while a parallel MLP captures implicit interactions as a complement; two alignment strategies then optimize compatibility between the streams so that the final deployed model is a single vanilla MLP that attains state-of-the-art performance on three standard CTR benchmarks.
What carries the argument
Dual-stream MLP with knowledge distillation from an explicit-interaction teacher into the main stream plus two alignment strategies that balance the streams during training.
If this is right
- The final model reduces to a single MLP, lowering both training complexity and inference cost relative to existing dual-stream CTR architectures.
- Explicit and implicit feature interactions can be combined inside ordinary MLP layers once distillation and alignment are applied.
- Overfitting risk drops because the deployed network contains no separate explicit-interaction module.
- The same training recipe yields a scalable solution for large-scale recommendation systems that must serve high query volumes.
Where Pith is reading between the lines
- If the alignment techniques generalize, they could simplify other dual-component networks in ranking or retrieval tasks.
- Future work might test whether the same distillation approach compresses even heavier CTR models into single-stream MLPs without accuracy loss.
- The result invites direct comparison of training-time cost versus inference-time cost across a wider range of recommendation datasets.
Load-bearing premise
Knowledge distillation successfully transfers explicit feature interaction capacity into the main MLP and the alignment strategies keep neither stream from dominating the final prediction.
What would settle it
On any of the three standard CTR benchmarks, DS-MLP without the parallel stream or without the alignment strategies fails to match or exceed the best prior dual-stream model by a statistically meaningful margin.
Figures

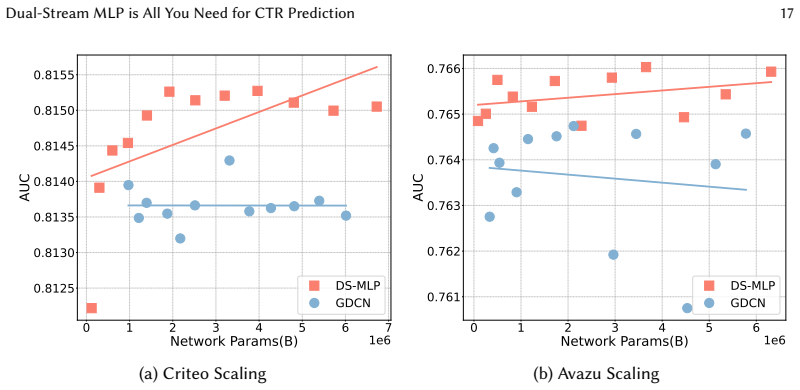
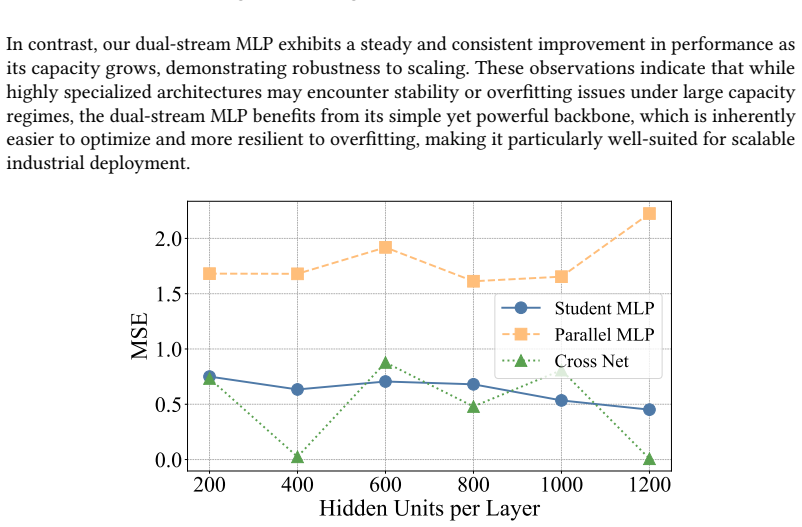
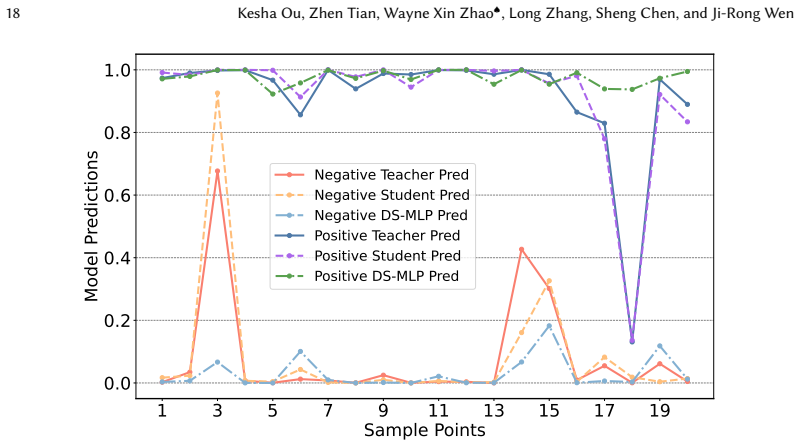

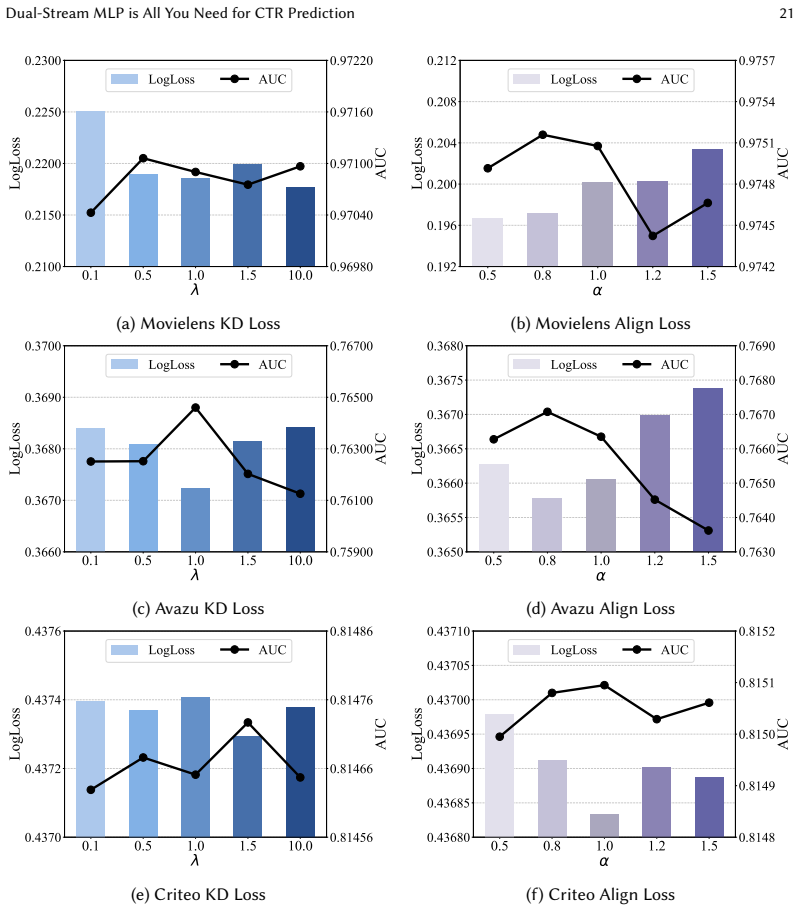
read the original abstract
Click-through rate (CTR) prediction holds a pivotal role in online advertising and recommendation systems, where even small improvements can significantly boost revenue. Existing research primarily focuses on designing dual-stream architectures to capture effective complex feature interactions from both explicit and implicit perspectives. However, these approaches are faced with two major challenges: 1) the high complexity of feature interaction learning, which increases computational demands and the overfitting risk, and 2) the imbalance between explicit and implicit modules, where one module's output may dominate the final prediction. To address these issues, in this paper, we propose Dual-Stream MLP (DS-MLP), a novel feature interaction framework for the CTR prediction task. Specially, it leverages knowledge distillation to consolidate the capacity of learning explicit feature interaction into a main MLP network, while a parallel MLP simultaneously captures implicit feature interactions as a complement. To effectively optimize the dual-stream MLP architecture, we further design a specific learning approach with two alignment strategies for enhancing the compatibility of the two MLP components. Experiments demonstrate that DS-MLP, though merely a vanilla MLP structure (the final model), can achieve state-of-the-art performance across three widely used benchmarks, offering a scalable and efficient solution for large-scale recommendation systems. Our code is available at https://github.com/RUCAIBox/DS-MLP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Dual-Stream MLP (DS-MLP) for CTR prediction. It employs knowledge distillation to transfer explicit feature-interaction capacity from an auxiliary stream into a main MLP, while a parallel MLP captures implicit interactions; two alignment strategies are introduced to balance the streams. The final deployed model is a standard MLP that is reported to reach state-of-the-art performance on three standard benchmarks while remaining computationally efficient.
Significance. If the distillation successfully embeds explicit interaction modeling into the main MLP and the alignment losses demonstrably prevent stream dominance, the result would show that complex dual-stream architectures can be reduced to a single vanilla MLP at inference time. This would offer a scalable, low-overhead alternative for large-scale recommendation systems and could shift practice away from explicit interaction modules.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the headline claim that distillation consolidates explicit interaction capacity into the final MLP (so that no explicit module is needed at deployment) is load-bearing, yet the provided text supplies no ablation that isolates the teacher stream (e.g., main MLP trained without distillation loss or without the explicit teacher). Without such controls it is impossible to rule out that reported gains arise from ordinary hyper-parameter search rather than the proposed consolidation mechanism.
- [§3.2] §3.2 (Alignment strategies): the two alignment losses are presented as necessary to prevent one stream from dominating, but no quantitative diagnostics (loss curves, contribution ratios, or intermediate prediction metrics) are referenced that would confirm balanced contribution; this leaves the second major design claim unsupported by visible evidence.
minor comments (2)
- [Abstract] The abstract states that code is released at a GitHub link; the repository should be checked for reproducibility of the three-benchmark results before final acceptance.
- [§3.2] Notation for the two alignment losses (Eqs. in §3.2) should be made consistent with the overall training objective in §3.3 to avoid reader confusion.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment below and agree that additional experiments will strengthen the presentation of our claims regarding the distillation mechanism and alignment strategies.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the headline claim that distillation consolidates explicit interaction capacity into the final MLP (so that no explicit module is needed at deployment) is load-bearing, yet the provided text supplies no ablation that isolates the teacher stream (e.g., main MLP trained without distillation loss or without the explicit teacher). Without such controls it is impossible to rule out that reported gains arise from ordinary hyper-parameter search rather than the proposed consolidation mechanism.
Authors: We acknowledge that the current experiments, while showing DS-MLP outperforming plain MLP baselines and other models, do not include explicit ablations that remove the distillation loss or the teacher stream. Such controls would more directly attribute gains to the consolidation mechanism. In the revised version we will add these ablations (main MLP trained without distillation and without the explicit teacher) to rule out hyper-parameter effects. revision: yes
-
Referee: [§3.2] §3.2 (Alignment strategies): the two alignment losses are presented as necessary to prevent one stream from dominating, but no quantitative diagnostics (loss curves, contribution ratios, or intermediate prediction metrics) are referenced that would confirm balanced contribution; this leaves the second major design claim unsupported by visible evidence.
Authors: We agree that direct evidence of balanced stream contributions would better support the role of the alignment losses. In the revision we will include quantitative diagnostics such as per-stream loss curves, contribution ratios during training, and intermediate prediction metrics to demonstrate that neither stream dominates. revision: yes
Circularity Check
No circularity: empirical SOTA claim rests on benchmark experiments, not self-referential derivation
full rationale
The paper presents DS-MLP as an empirical architecture that uses knowledge distillation to embed explicit interactions into a main MLP plus a parallel implicit MLP with two alignment losses. The headline result is that the final deployed vanilla MLP reaches SOTA on three CTR benchmarks. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. The method description does not reduce any claimed outcome to its own inputs by construction; performance is asserted via external experimental comparison rather than tautological re-labeling of training signals.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mathieu Blondel, Akinori Fujino, Naonori Ueda, and Masakazu Ishihata. 2016. Higher-order factorization machines. Advances in Neural Information Processing Systems29 (2016)
2016
-
[2]
Andreas Buja, Werner Stuetzle, and Yi Shen. 2005. Loss functions for binary class probability estimation and classifica- tion: Structure and applications.Working draft, November3 (2005), 13
2005
-
[3]
Shaofeng Cai, Kaiping Zheng, Gang Chen, HV Jagadish, Beng Chin Ooi, and Meihui Zhang. 2021. Arm-net: Adaptive relation modeling network for structured data. InProceedings of the 2021 International Conference on Management of Data. 207–220
2021
-
[4]
Bo Chen, Yichao Wang, Zhirong Liu, Ruiming Tang, Wei Guo, Hongkun Zheng, Weiwei Yao, Muyu Zhang, and Xiuqiang He. 2021. Enhancing explicit and implicit feature interactions via information sharing for parallel deep CTR models. InProceedings of the 30th ACM international conference on information & knowledge management. 3757–3766
2021
-
[5]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. 2016. Wide & deep learning for recommender systems. InProceedings of the 1st workshop on deep learning for recommender systems. 7–10
2016
-
[6]
Weiyu Cheng, Yanyan Shen, and Linpeng Huang. 2020. Adaptive factorization network: Learning adaptive-order feature interactions. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 3609–3616
2020
-
[7]
George Cybenko. 1989. Approximation by superpositions of a sigmoidal function.Mathematics of control, signals and systems2, 4 (1989), 303–314
1989
-
[8]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965(2025)
Pith/arXiv arXiv 2025
-
[9]
Simon Du, Jason Lee, Haochuan Li, Liwei Wang, and Xiyu Zhai. 2019. Gradient descent finds global minima of deep neural networks. InInternational conference on machine learning. PMLR, 1675–1685
2019
-
[10]
Yufei Feng, Fuyu Lv, Weichen Shen, Menghan Wang, Fei Sun, Yu Zhu, and Keping Yang. 2019. Deep session interest network for click-through rate prediction. InProceedings of the 28th International Joint Conference on Artificial Intelligence. 2301–2307
2019
-
[11]
Lin Guan, Jia-Qi Yang, Zhishan Zhao, Beichuan Zhang, Bo Sun, Xuanyuan Luo, Jinan Ni, Xiaowen Li, Yuhang Qi, Zhifang Fan, et al. 2025. Make It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin. arXiv preprint arXiv:2511.06077(2025)
Pith/arXiv arXiv 2025
-
[12]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: a factorization-machine based neural network for CTR prediction.arXiv preprint arXiv:1703.04247(2017)
Pith/arXiv arXiv 2017
-
[13]
Wei Guo, Rong Su, Renhao Tan, Huifeng Guo, Yingxue Zhang, Zhirong Liu, Ruiming Tang, and Xiuqiang He. 2021. Dual Graph enhanced Embedding Neural Network for CTR Prediction. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 496–504
2021
-
[14]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531(2015)
Pith/arXiv arXiv 2015
-
[15]
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. 1989. Multilayer feedforward networks are universal approxi- mators.Neural networks2, 5 (1989), 359–366
1989
-
[16]
Bojian Hou, Xiaolong Liu, Xiaoyi Liu, Jiaqi Xu, Yasmine Badr, Mengyue Hang, Sudhanshu Chanpuriya, Junqing Zhou, Yuhang Yang, Han Xu, et al. 2026. Kunlun: Establishing Scaling Laws for Massive-Scale Recommendation Systems ACM Trans. Knowl. Discov. Data., Vol. 1, No. 1, Article . Publication date: January 2026. 26 Kesha Ou, Zhen Tian, Wayne Xin Zhao ♠, Long...
Pith/arXiv arXiv 2026
-
[17]
Tongwen Huang, Zhiqi Zhang, and Junlin Zhang. 2019. FiBiNET: combining feature importance and bilinear feature interaction for click-through rate prediction. InProceedings of the 13th ACM Conference on Recommender Systems. 169–177
2019
-
[18]
Yuchin Juan, Yong Zhuang, Wei-Sheng Chin, and Chih-Jen Lin. 2016. Field-aware factorization machines for CTR prediction. InProceedings of the 10th ACM conference on recommender systems. 43–50
2016
-
[19]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361(2020)
Pith/arXiv arXiv 2020
-
[20]
Farhan Khawar, Xu Hang, Ruiming Tang, Bin Liu, Zhenguo Li, and Xiuqiang He. 2020. Autofeature: Searching for feature interactions and their architectures for click-through rate prediction. InProceedings of the 29th ACM International Conference on Information & Knowledge Management. 625–634
2020
-
[21]
Lingwei Kong, Lu Wang, Changping Peng, Zhangang Lin, Ching Law, and Jingping Shao. 2025. Generative Click- through Rate Prediction with Applications to Search Advertising.arXiv preprint arXiv:2507.11246(2025)
arXiv 2025
-
[22]
Weijiang Lai, Beihong Jin, Jiongyan Zhang, Yiyuan Zheng, Jian Dong, Jia Cheng, Jun Lei, and Xingxing Wang. 2025. Exploring Scaling Laws of CTR Model for Online Performance Improvement. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 114–123
2025
-
[23]
Honghao Li, Yiwen Zhang, Yi Zhang, Hanwei Li, Lei Sang, and Jieming Zhu. 2024. FCN: Fusing Exponential and Linear Cross Network for Click-Through Rate Prediction.arXiv preprint arXiv:2407.13349(2024)
arXiv 2024
-
[24]
Zekun Li, Zeyu Cui, Shu Wu, Xiaoyu Zhang, and Liang Wang. 2019. Fi-gnn: Modeling feature interactions via graph neural networks for ctr prediction. InProceedings of the 28th ACM International Conference on Information and Knowledge Management. 539–548
2019
-
[25]
Zekun Li, Shu Wu, Zeyu Cui, and Xiaoyu Zhang. 2021. GraphFM: Graph factorization machines for feature interaction modeling.arXiv e-prints(2021), arXiv–2105
2021
-
[26]
Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1754–1763
2018
-
[27]
Bin Liu, Ruiming Tang, Yingzhi Chen, Jinkai Yu, Huifeng Guo, and Yuzhou Zhang. 2019. Feature generation by convolutional neural network for click-through rate prediction. InThe World Wide Web Conference. 1119–1129
2019
-
[28]
Jorge M Lobo, Alberto Jiménez-Valverde, and Raimundo Real. 2008. AUC: a misleading measure of the performance of predictive distribution models.Global ecology and Biogeography17, 2 (2008), 145–151
2008
-
[29]
Wantong Lu, Yantao Yu, Yongzhe Chang, Zhen Wang, Chenhui Li, and Bo Yuan. 2021. A dual input-aware factoriza- tion machine for CTR prediction. InProceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence. 3139–3145
2021
-
[30]
Kelong Mao, Jieming Zhu, Liangcai Su, Guohao Cai, Yuru Li, and Zhenhua Dong. 2023. FinalMLP: an enhanced two-stream MLP model for CTR prediction. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 4552–4560
2023
-
[31]
Kesha Ou, Zhen Tian, Wayne Xin Zhao, Hongyu Lu, and Ji-Rong Wen. 2026. GenCI: Generative Modeling of User Interest Shift via Cohort-based Intent Learning for CTR Prediction.arXiv preprint arXiv:2601.18251(2026)
arXiv 2026
-
[32]
Junwei Pan, Jian Xu, Alfonso Lobos Ruiz, Wenliang Zhao, Shengjun Pan, Yu Sun, and Quan Lu. 2018. Field-weighted factorization machines for click-through rate prediction in display advertising. InProceedings of the 2018 World Wide Web Conference. 1349–1357
2018
-
[33]
Allan Pinkus. 1999. Approximation theory of the MLP model in neural networks.Acta numerica8 (1999), 143–195
1999
-
[34]
Marius-Constantin Popescu, Valentina E Balas, Liliana Perescu-Popescu, and Nikos Mastorakis. 2009. Multilayer perceptron and neural networks.WSEAS Transactions on Circuits and Systems8, 7 (2009), 579–588
2009
-
[35]
Y Qu, H Cai, W Zhang, Y Wen, and J Wang. 2017. Product-Based Neural Networks for User Response Prediction. In The IEEE International Conference on Data Mining. IEEE, 1149–1154
2017
-
[36]
Yanru Qu, Bohui Fang, Weinan Zhang, Ruiming Tang, Minzhe Niu, Huifeng Guo, Yong Yu, and Xiuqiang He. 2018. Product-based neural networks for user response prediction over multi-field categorical data.ACM Transactions on Information Systems (TOIS)37, 1 (2018), 1–35
2018
-
[37]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al. 2023. Recommender systems with generative retrieval.Advances in Neural Information Processing Systems36 (2023), 10299–10315
2023
-
[38]
Steffen Rendle. 2010. Factorization machines. In2010 IEEE International conference on data mining. IEEE, 995–1000
2010
-
[39]
Matthew Richardson, Ewa Dominowska, and Robert Ragno. 2007. Predicting clicks: estimating the click-through rate for new ads. InProceedings of the 16th international conference on World Wide Web. 521–530
2007
-
[40]
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. 2015. FitNets: Hints for Thin Deep Nets. InProceedings of International Conference on Learning Representations, (ICLR). ACM Trans. Knowl. Discov. Data., Vol. 1, No. 1, Article . Publication date: January 2026. Dual-Stream MLP is All You Need for CTR Pr...
2015
-
[41]
Zhiqiang Shen, Zhankui He, and Xiangyang Xue. 2019. MEAL: Multi-Model Ensemble via Adversarial Learning. In The Thirty-Third AAAI Conference on Artificial Intelligence (AAAI). 4886–4893
2019
-
[42]
Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. 2019. Autoint: Automatic feature interaction learning via self-attentive neural networks. InProceedings of the 28th ACM International Conference on Information and Knowledge Management. 1161–1170
2019
-
[43]
Yang Sun, Junwei Pan, Alex Zhang, and Aaron Flores. 2021. Fm2: Field-matrixed factorization machines for recom- mender systems. InProceedings of the Web Conference 2021. 2828–2837
2021
-
[44]
Xu Tan, Yi Ren, Di He, Tao Qin, Zhou Zhao, and Tie-Yan Liu. 2019. Multilingual Neural Machine Translation with Knowledge Distillation. In7th International Conference on Learning Representations (ICLR)
2019
-
[45]
Zhen Tian, Ting Bai, Zibin Zhang, Zhiyuan Xu, Kangyi Lin, Ji-Rong Wen, and Wayne Xin Zhao. 2023. Directed acyclic graph factorization machines for CTR prediction via knowledge distillation. InProceedings of the Sixteenth ACM International Conference on Web Search and Data Mining. 715–723
2023
-
[46]
Zhen Tian, Ting Bai, Wayne Xin Zhao, Ji-Rong Wen, and Zhao Cao. 2023. EulerNet: Adaptive Feature Interaction Learning via Euler’s Formula for CTR Prediction. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1376–1385
2023
-
[47]
Zhen Tian, Yuhong Shi, Xiangkun Wu, Wayne Xin Zhao, and Ji-Rong Wen. 2024. Rotative Factorization Machines. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2912–2923
2024
-
[48]
Fangye Wang, Hansu Gu, Dongsheng Li, Tun Lu, Peng Zhang, and Ning Gu. 2023. Towards deeper, lighter and interpretable cross network for ctr prediction. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 2523–2533
2023
-
[49]
Fangye Wang, Yingxu Wang, Dongsheng Li, Hansu Gu, Tun Lu, Peng Zhang, and Ning Gu. 2022. Enhancing CTR prediction with context-aware feature representation learning. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 343–352
2022
-
[50]
Kefan Wang, Hao Wang, Wei Guo, Yong Liu, Jianghao Lin, Defu Lian, and Enhong Chen. 2025. DLF: Enhancing Explicit-Implicit Interaction via Dynamic Low-Order-Aware Fusion for CTR Prediction. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2213–2223
2025
-
[51]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & cross network for ad click predictions. InProceedings of the ADKDD’17. 1–7
2017
-
[52]
Ruoxi Wang, Rakesh Shivanna, Derek Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed Chi. 2021. DCN V2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. InProceedings of the Web Conference
2021
-
[53]
Zhiqiang Wang, Qingyun She, and Junlin Zhang. 2021. Masknet: Introducing feature-wise multiplication to CTR ranking models by instance-guided mask.arXiv preprint arXiv:2102.07619(2021)
arXiv 2021
-
[54]
Jun Xiao, Hao Ye, Xiangnan He, Hanwang Zhang, Fei Wu, and Tat-Seng Chua. 2017. Attentional factorization machines: learning the weight of feature interactions via attention networks. InProceedings of the 26th International Joint Conference on Artificial Intelligence. 3119–3125
2017
-
[55]
Xin Xin, Bo Chen, Xiangnan He, Dong Wang, Yue Ding, and Joemon M Jose. 2019. CFM: Convolutional factorization machines for context-aware recommendation.. InIJCAI, Vol. 19. 3926–3932
2019
-
[56]
Chen Xu, Quan Li, Junfeng Ge, Jinyang Gao, Xiaoyong Yang, Changhua Pei, Fei Sun, Jian Wu, Hanxiao Sun, and Wenwu Ou. 2020. Privileged features distillation at Taobao recommendations. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2590–2598
2020
-
[57]
Junho Yim, Donggyu Joo, Jihoon Bae, and Junmo Kim. 2017. A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2017
-
[58]
Mingjia Yin, Junwei Pan, Hao Wang, Ximei Wang, Shangyu Zhang, Jie Jiang, Defu Lian, and Enhong Chen. 2025. From Feature Interaction to Feature Generation: A Generative Paradigm of CTR Prediction Models. 267 (2025)
2025
-
[59]
Feng Yu, Zhaocheng Liu, Qiang Liu, Haoli Zhang, Shu Wu, and Liang Wang. 2020. Deep interaction machine: A simple but effective model for high-order feature interactions. InProceedings of the 29th ACM International Conference on Information & Knowledge Management. 2285–2288
2020
-
[60]
Sergey Zagoruyko and Nikos Komodakis. 2017. Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer. InInternational Conference on Learning Representations, (ICLR) 2017
2017
-
[61]
Buyun Zhang, Liang Luo, Yuxin Chen, Jade Nie, Xi Liu, Daifeng Guo, Yanli Zhao, Shen Li, Yuchen Hao, Yantao Yao, et al. 2024. Wukong: Towards a scaling law for large-scale recommendation.arXiv preprint arXiv:2403.02545(2024)
arXiv 2024
-
[62]
Moyu Zhang, Yun Chen, Yujun Jin, Jinxin Hu, and Yu Zhang. 2025. DGenCTR: Towards a Universal Generative Paradigm for Click-Through Rate Prediction via Discrete Diffusion.arXiv preprint arXiv:2508.14500(2025)
arXiv 2025
-
[63]
Pengyu Zhao, Kecheng Xiao, Yuanxing Zhang, Kaigui Bian, and Wei Yan. 2020. Amer: Automatic behavior modeling and interaction exploration in recommender system.arXiv preprint arXiv:2006.05933(2020). ACM Trans. Knowl. Discov. Data., Vol. 1, No. 1, Article . Publication date: January 2026. 28 Kesha Ou, Zhen Tian, Wayne Xin Zhao ♠, Long Zhang, Sheng Chen, and...
arXiv 2020
-
[64]
Guorui Zhou, Ying Fan, Runpeng Cui, Weijie Bian, Xiaoqiang Zhu, and Kun Gai. 2018. Rocket launching: A universal and efficient framework for training well-performing light net. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 32
2018
-
[65]
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep interest evolution network for click-through rate prediction. InProceedings of the AAAI conference on artificial intelligence, Vol. 33. 5941–5948
2019
-
[66]
Chenxu Zhu, Bo Chen, Weinan Zhang, Jincai Lai, Ruiming Tang, Xiuqiang He, Zhenguo Li, and Yong Yu. 2021. AIM: Automatic Interaction Machine for Click-Through Rate Prediction.IEEE Transactions on Knowledge and Data Engineering(2021)
2021
-
[67]
Jie Zhu, Zhifang Fan, Xiaoxie Zhu, Yuchen Jiang, Hangyu Wang, Xintian Han, Haoran Ding, Xinmin Wang, Wenlin Zhao, Zhen Gong, et al. 2025. Rankmixer: Scaling up ranking models in industrial recommenders. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 6309–6316
2025
-
[68]
Jieming Zhu, Qinglin Jia, Guohao Cai, Quanyu Dai, Jingjie Li, Zhenhua Dong, Ruiming Tang, and Rui Zhang. 2023. Final: Factorized interaction layer for ctr prediction. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2006–2010
2023
-
[69]
Jieming Zhu, Jinyang Liu, Weiqi Li, Jincai Lai, Xiuqiang He, Liang Chen, and Zibin Zheng. 2020. Ensembled CTR prediction via knowledge distillation. InProceedings of the 29th ACM International Conference on Information & Knowledge Management. 2941–2958
2020
-
[70]
Difan Zou, Yuan Cao, Dongruo Zhou, and Quanquan Gu. 2018. Stochastic gradient descent optimizes over- parameterized deep ReLU networks.arXiv preprint arXiv:1811.08888(2018). ACM Trans. Knowl. Discov. Data., Vol. 1, No. 1, Article . Publication date: January 2026
Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.