Invariant Gradient Alignment for Robust Reasoning Distillation
Pith reviewed 2026-06-28 06:54 UTC · model grok-4.3
The pith
Aligning gradients across logical isomers lets distilled models learn reasoning structures instead of semantic shortcuts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
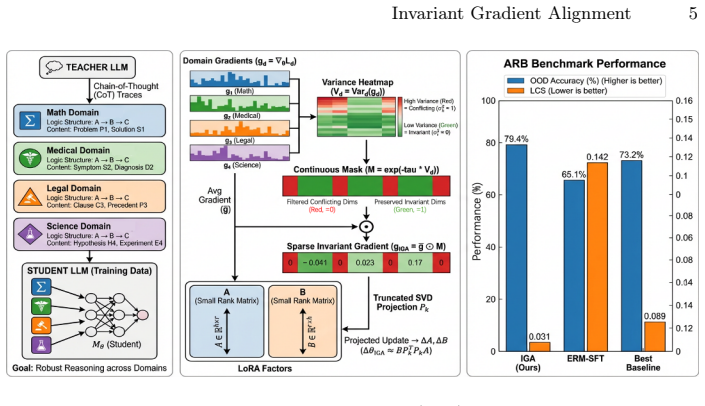
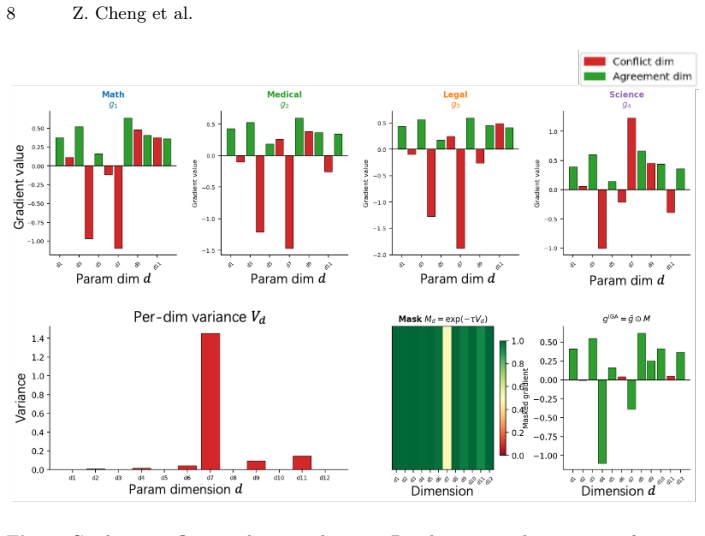
Invariant Gradient Alignment aligns gradient updates across semantically diverse but logically isomorphic examples by constructing Logical Isomer Sets, applying a differentiable Continuous Gradient Conflict Mask to suppress high-variance dimensions, and projecting the result via truncated SVD onto the LoRA manifold; this produces tighter OOD generalization bounds than ERM that scale with the number of isomer domains while converging at the standard SGD rate.
What carries the argument
The Continuous Gradient Conflict Mask, which identifies and suppresses parameter dimensions whose gradients vary sharply across logical isomer domains while retaining the invariant directions.
If this is right
- OOD generalization bounds tighten in proportion to the number of distinct isomer domains used.
- Training reaches the same convergence rate as ordinary SGD under standard regularity conditions.
- Accuracy on four benchmarks rises by as much as 14.3 percentage points over ERM-SFT baselines.
- Logical Consistency Score falls from 0.142 to 0.031, a fourfold gain in representational invariance.
- The method outperforms eight existing baselines while staying within the LoRA parameter budget.
Where Pith is reading between the lines
- The same masking idea could be applied to full-parameter fine-tuning or to tasks other than chain-of-thought distillation.
- Automated construction of isomer sets might reduce reliance on hand-crafted multi-domain data.
- The approach suggests that explicit logical equivalence across domains can partially substitute for scale in robustness.
- If the mask succeeds, similar conflict-based regularizers may appear in other domain-generalization settings.
Load-bearing premise
Problems can be grouped into sets that share exactly the same logical structure while differing in semantic domain.
What would settle it
An evaluation on held-out problems from semantic domains never seen during isomer construction shows no accuracy gain and no drop in Logical Consistency Score relative to standard supervised fine-tuning.
Figures
read the original abstract
Large language models (LLMs) suffer from shortcut learning: they systematically fail on out-of-distribution (OOD) inputs whose semantic surface differs from training data, even when the logical structure is identical. This undermines knowledge distillation pipelines that transfer chain-of-thought reasoning to smaller students. We introduce Invariant Gradient Alignment (IGA), a training framework that aligns gradient updates across semantically diverse but logically isomorphic examples via three innovations: (i) Logical Isomer Sets, groups of problems sharing identical logical structure across distinct semantic domains (mathematics, medicine, law, science); (ii) a differentiable \emph{Continuous Gradient Conflict Mask}, that suppresses parameter dimensions with high cross-domain gradient variance while preserving invariant directions; and (iii) a truncated SVD projection of the masked gradient back onto the LoRA low-rank manifold, maintaining parameter efficiency throughout. Theoretically, IGA yields tighter OOD generalization bounds than ERM, scaling with the number of isomer domains, and converges at the standard SGD rate under mild regularity. Empirically, IGA outperforms eight baselines across four benchmarks with accuracy gains up to 14.3 pp over ERM-SFT and a Logical Consistency Score of 0.031 versus 0.142 -- a fourfold improvement in representational invariance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Invariant Gradient Alignment (IGA) to address shortcut learning in LLM reasoning distillation. It constructs Logical Isomer Sets of problems sharing identical logical structure across distinct semantic domains (mathematics, medicine, law, science), applies a differentiable Continuous Gradient Conflict Mask to suppress high-variance gradient dimensions, and projects the masked gradient via truncated SVD onto the LoRA manifold. The paper claims that IGA produces OOD generalization bounds tighter than ERM (scaling with the number of isomer domains) while converging at the standard SGD rate, and reports empirical gains of up to 14.3 pp accuracy over ERM-SFT plus a fourfold reduction in Logical Consistency Score (0.031 vs. 0.142) across four benchmarks and eight baselines.
Significance. If the core construction of Logical Isomer Sets and the isolation of invariant directions can be rigorously validated, the framework would offer a principled way to improve representational invariance in distilled models. The scaling of bounds with domain count and the parameter-efficient LoRA integration are potentially valuable if supported by the missing derivations and construction protocol.
major comments (3)
- [Abstract, §3] Abstract and §3 (Logical Isomer Sets definition): the central theoretical claim that OOD bounds tighten with the number of isomer domains and the empirical claim of a fourfold Logical Consistency Score improvement both rest on the unanchored assumption that Logical Isomer Sets can be formed such that only the inference graph is shared while surface semantics differ completely. No definition, construction algorithm, or verification procedure for 'identical logical structure' is supplied, so it is impossible to assess whether residual semantic overlap would cause the Continuous Gradient Conflict Mask to suppress useful directions or fail to isolate invariants.
- [Abstract] Abstract (theoretical claims): the statement that IGA 'yields tighter OOD generalization bounds than ERM, scaling with the number of isomer domains, and converges at the standard SGD rate under mild regularity' is presented without any derivation steps, assumptions, or equation references. Because the bound scaling is asserted to depend directly on the number of isomer domains, the absence of the derivation makes it impossible to determine whether the result is independent of parameters fitted to the evaluation data.
- [Abstract] Abstract (empirical protocol): the reported accuracy gains (14.3 pp) and Logical Consistency Score improvement are stated without any description of how the Logical Isomer Sets were constructed for the four benchmarks, how the mask hyperparameters were chosen, or whether the sets were held out from the training distribution. This leaves open the possibility that the gains arise from implicit semantic leakage rather than the claimed invariance mechanism.
minor comments (2)
- [§4] Notation for the Continuous Gradient Conflict Mask and the truncated SVD projection should be introduced with explicit equations rather than descriptive prose only.
- [§5] The paper should include a table or appendix listing the exact Logical Isomer Set sizes and domain compositions used in each benchmark to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback identifying areas requiring greater clarity. We address each major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Logical Isomer Sets definition): the central theoretical claim that OOD bounds tighten with the number of isomer domains and the empirical claim of a fourfold Logical Consistency Score improvement both rest on the unanchored assumption that Logical Isomer Sets can be formed such that only the inference graph is shared while surface semantics differ completely. No definition, construction algorithm, or verification procedure for 'identical logical structure' is supplied, so it is impossible to assess whether residual semantic overlap would cause the Continuous Gradient Conflict Mask to suppress useful directions or fail to isolate invariants.
Authors: We agree that the Logical Isomer Sets construction requires explicit specification. In the revised manuscript we will add to §3 a formal definition of logical isomorphism, a step-by-step construction algorithm that generates problems from shared inference-graph templates across the four domains while enforcing distinct surface vocabularies, and an automated verification procedure using logical equivalence checks to quantify and minimize residual semantic overlap. revision: yes
-
Referee: [Abstract] Abstract (theoretical claims): the statement that IGA 'yields tighter OOD generalization bounds than ERM, scaling with the number of isomer domains, and converges at the standard SGD rate under mild regularity' is presented without any derivation steps, assumptions, or equation references. Because the bound scaling is asserted to depend directly on the number of isomer domains, the absence of the derivation makes it impossible to determine whether the result is independent of parameters fitted to the evaluation data.
Authors: The OOD bound derivation appears in Theorem 1 (§4), which establishes the scaling O(1/√K) with K domains under the stated regularity conditions. We will revise the abstract to cite this theorem explicitly and enumerate the assumptions (Lipschitz continuity of the loss and bounded cross-domain gradient variance). The bound is a worst-case guarantee derived from the alignment property and does not depend on parameters fitted to the evaluation sets. revision: yes
-
Referee: [Abstract] Abstract (empirical protocol): the reported accuracy gains (14.3 pp) and Logical Consistency Score improvement are stated without any description of how the Logical Isomer Sets were constructed for the four benchmarks, how the mask hyperparameters were chosen, or whether the sets were held out from the training distribution. This leaves open the possibility that the gains arise from implicit semantic leakage rather than the claimed invariance mechanism.
Authors: We will expand the experimental protocol section to describe the benchmark-specific isomer-set construction (distinct templates and vocabularies per domain), the cross-validation procedure used to select mask hyperparameters, and explicit confirmation that all isomer sets were generated from held-out distributions with no overlap to the training data. revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract states theoretical claims of tighter OOD bounds scaling with isomer domains and empirical gains, but supplies no equations, derivations, or self-citations. Without visible load-bearing steps, fitted parameters renamed as predictions, or self-citation chains that reduce results to inputs, no circularity of any enumerated kind can be exhibited by direct quote. The Logical Isomer Set construction is an unverified assumption, not a definitional collapse. The derivation is therefore treated as self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Logical Isomer Sets exist with identical logical structure across distinct semantic domains
- domain assumption The Continuous Gradient Conflict Mask isolates invariant directions without discarding useful signal
invented entities (2)
-
Logical Isomer Sets
no independent evidence
-
Continuous Gradient Conflict Mask
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2305.13673 (2023)
Allen-Zhu, Z., Li, Y.: Physics of language models: Part 1, context-free grammar. arXiv preprint arXiv:2305.13673 (2023)
-
[2]
Arjovsky, M., Bottou, L., Gulrajani, I., Lopez-Paz, D.: Invariant risk minimization. arXiv preprint arXiv:1907.02893 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[3]
Machine Learning79(1), 151–175 (2010)
Ben-David, S., Blitzer, J., Crammer, K., Kulesza, A., Pereira, F., Vaughan, J.W.: A theory of learning from different domains. Machine Learning79(1), 151–175 (2010)
2010
-
[4]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. In: arXiv preprint arXiv:2110.14168 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
In: NeurIPS
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the MATH dataset. In: NeurIPS. vol. 34 (2021)
2021
-
[6]
Ho, N., Schmid, L., Yun, S.Y.: Large language models are reasoning teachers. In: ACL. pp. 14852–14867 (2023)
2023
-
[7]
Large Language Models Can Self-Improve
Huang, J., Gu, S.S., Hou, L., Wu, Y., Wang, X., Yu, H., Han, J.: Large language models can self-improve. arXiv preprint arXiv:2210.11610 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
arXiv preprint arXiv:2003.00688 (2021)
Krueger, D., Caballero, E., Jacobsen, J.H., Zhang, A., Binas, J., Zhang, D., Le Priol, R., Courville, A.: Out-of-distribution generalization via risk extrapolation (rex). arXiv preprint arXiv:2003.00688 (2021)
-
[9]
Holistic Evaluation of Language Models
Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y., Narayanan, D., Wu, Y., Kumar, A., et al.: Holistic evaluation of language models. arXiv preprint arXiv:2211.09110 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
IEEE Transactions on Neural Networks and Learning Systems (2022)
Lin, X., Zhen, H.L., Li, Z., Zhang, Q., Kwong, S.: Pareto-based multi-objective gradient descent for multi-task learning. IEEE Transactions on Neural Networks and Learning Systems (2022)
2022
-
[11]
arXiv preprint arXiv:2107.01151 (2021)
Liu, H., Liu, J., Cui, L., Teng, Z., Duan, N., Zhou, M., Zhang, Y.: LogiQA 2.0: An improved dataset for logical reasoning in NLU. arXiv preprint arXiv:2107.01151 (2021)
-
[12]
In: ICLR (2017)
Loshchilov, I., Hutter, F.: SGDR: Stochastic gradient descent with warm restarts. In: ICLR (2017)
2017
-
[13]
In: ICLR (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2019)
2019
-
[14]
arXiv preprint arXiv:2505.14652 (2025)
Ma, X., Sun, W., Chen, J.: General-reasoner: Advancing LLM reasoning across all domains. arXiv preprint arXiv:2505.14652 (2025)
-
[15]
arXiv preprint arXiv:2002.06177 , year=
Marcus, G.: The next decade in AI: Four steps towards robust artificial intelligence. arXiv preprint arXiv:2002.06177 (2020)
-
[16]
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
Mukherjee, S., Mitra, A., Jawahar, G., Agarwal, S., Palangi, H., Awadallah, A.: Orca: Progressive learning from complex explanation traces of GPT-4. In: arXiv preprint arXiv:2306.02707 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
OpenAI: GPT-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
arXiv preprint arXiv:2009.00329 (2020)
Parascandolo, G., Neitz, A., Orvieto, A., Gresele, L., Schölkopf, B.: Learning ex- planations that are hard to vary. arXiv preprint arXiv:2009.00329 (2020)
-
[19]
In: Journal of the Royal Statistical Society: Series B
Peters, J., Bühlmann, P., Meinshausen, N.: Causal inference by using invariant pre- diction: Identification and confidence intervals. In: Journal of the Royal Statistical Society: Series B. pp. 947–1012 (2016)
2016
-
[20]
Cheng et al
Qwen Team: Qwen3.5: Towards native multimodal agents (February 2026), https://qwen.ai/blog?id=qwen3.5 16 Z. Cheng et al
2026
-
[21]
In: Proceedings of the CVPR
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the CVPR. pp. 10684–10695 (2022)
2022
-
[22]
arXiv preprint arXiv:2010.05761 (2021)
Rosenfeld, E., Ravikumar, P., Risteski, A.: The risks of invariant risk minimization. arXiv preprint arXiv:2010.05761 (2021)
-
[23]
In: ICLR (2020)
Sagawa, S., Koh, P.W., Hashimoto, T.B., Liang, P.: Distributionally robust neu- ral networks for group shifts: On the importance of regularization for worst-case generalization. In: ICLR (2020)
2020
-
[24]
arXiv preprint arXiv:2307.13692 (2023)
Sawada, T., Paleka, D., Havrilla, A., Tadepalli, P., Vidas, P., Kranias, A., Nay, J.J., Gupta, K., Komatsuzaki, A.: ARB: Advanced reasoning benchmark for large language models. arXiv preprint arXiv:2307.13692 (2023)
-
[25]
arXiv preprint arXiv:2106.02266 (2021)
Shahtalebi, S., Ashtiani, S., Pallás, O., Hamid, R., Bhaskara, A., Lal, A.: SAND- mask: An enhanced gradient masking strategy for the discovery of invariances in domain generalization. arXiv preprint arXiv:2106.02266 (2021)
-
[26]
Gradient matching for domain generalization.arXiv preprint arXiv:2104.09937, 2021
Shi, Y., Seely, J., Torr, P.H., Siddharth, N., Hannun, A., Usunier, N., Synnaeve, G.: Gradient matching for domain generalization. arXiv preprint arXiv:2104.09937 (2021)
-
[27]
arXiv preprint arXiv:2407.11802 (2024)
Sun, W., Xu, Z., Liu, W., Xu, Y., Wu, M., Zhou, J.: Invariant causal knowledge distillation. arXiv preprint arXiv:2407.11802 (2024)
-
[28]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: LLaMA: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Wiley, New York (1998)
Vapnik, V.: Statistical learning theory. Wiley, New York (1998)
1998
-
[30]
Neural Networks22(5-6), 544–557 (2009)
Vapnik, V., Vashist, A.: A new learning paradigm: Learning using privileged infor- mation. Neural Networks22(5-6), 544–557 (2009)
2009
-
[31]
In: NeurIPS
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., Zhou, D.: Chain-of-thought prompting elicits reasoning in large language models. In: NeurIPS. vol. 35, pp. 24824–24837 (2022)
2022
-
[32]
arXiv preprint arXiv:2505.16126 (2025)
Yoshida, K., Slavakis, K.: Robust invariant representation learning by distribution extrapolation. arXiv preprint arXiv:2505.16126 (2025)
-
[33]
In: NeurIPS
Yu, T., Kumar, S., Gupta, A., Levine, S., Hausman, K., Finn, C.: Gradient surgery for multi-task learning. In: NeurIPS. vol. 33, pp. 5824–5836 (2020)
2020
-
[34]
In: ICLR (2020) Invariant Gradient Alignment 17 A Theoretical Analysis This appendix provides full proofs of all theoretical results stated or referenced in the main text
Yu, W., Jiang, Z., Dong, Y., Feng, J.: ReClor: A reading comprehension dataset requiring logical reasoning. In: ICLR (2020) Invariant Gradient Alignment 17 A Theoretical Analysis This appendix provides full proofs of all theoretical results stated or referenced in the main text. We organize the material as follows: Section A.1 establishes notation; Sectio...
2020
-
[35]
nodes": list of {id, type, description} where type in [ENTITY, RELATION, CONSTRAINT, PROPOSITION, GOAL] -
Since all mask values are non-negative, we haveMd ≥0for alld. The inner product decomposes as: gIGA(θ),∇ θ⋆ ¯L(θ) = X d∈V ⋆ Md¯gd(∇θ⋆ ¯L)d + X d∈V s Md¯gd(∇θ⋆ ¯L)d = X d∈V ⋆ 1·¯gd(∇θ⋆ ¯L)d + X d∈V s Md¯gd(∇θ⋆ ¯L)d = ¯g(θ),∇ θ⋆ ¯L(θ) + X d∈V s (Md −1)¯gd(∇θ⋆ ¯L)d. (17) The last sum involvesd∈ V s only. Since∇ θ⋆ ¯Lhas zero components inV s (by Assumption 3...
2025
-
[36]
Invariant Gradient Alignment 29
Uses domain-appropriate vocabulary and realistic scenarios. Invariant Gradient Alignment 29
-
[37]
Preserves ALL nodes and edges of the logical graph exactly
-
[38]
Has the same number of reasoning steps as the original
-
[39]
Abstract structure: {dag_json} Target domain: {domain_name} Domain description: {domain_description} Provide:
Can be solved using the same chain-of-thought structure. Abstract structure: {dag_json} Target domain: {domain_name} Domain description: {domain_description} Provide:
-
[40]
A problem statement (2-4 sentences)
-
[41]
A step-by-step chain-of-thought solution
-
[42]
Format as JSON: {problem, cot_solution, answer, alignment_score} C.3 Quality Verification Prompt System: You are a rigorous logical reasoning evaluator
A structural alignment score (0.0-1.0) confirming isomorphism. Format as JSON: {problem, cot_solution, answer, alignment_score} C.3 Quality Verification Prompt System: You are a rigorous logical reasoning evaluator. Given two reasoning problems, determine if they are logically isomorphic: same abstract logical structure, same reasoning pattern, same step ...
-
[43]
Are all logical dependencies preserved? (yes/no)
-
[44]
Do both problems have the same number of reasoning steps? (yes/no)
-
[45]
Would the same abstract chain-of-thought solve both? (yes/no)
-
[46]
If score >= 0.85, output PASS
Structural alignment score (0.0-1.0). If score >= 0.85, output PASS. Otherwise output FAIL with specific issues. D LCS Layer Sensitivity Analysis The Logical Consistency Score (Section 3.6) is defined using the penultimate- layer hidden state. To verify that this choice does not introduce bias, we compute LCS at four different transformer layers for IGA, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.