Boosting Self-Consistency with Ranking
Pith reviewed 2026-06-28 06:47 UTC · model grok-4.3
The pith
A lightweight ranking model trained on five features improves answer selection over majority voting in self-consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
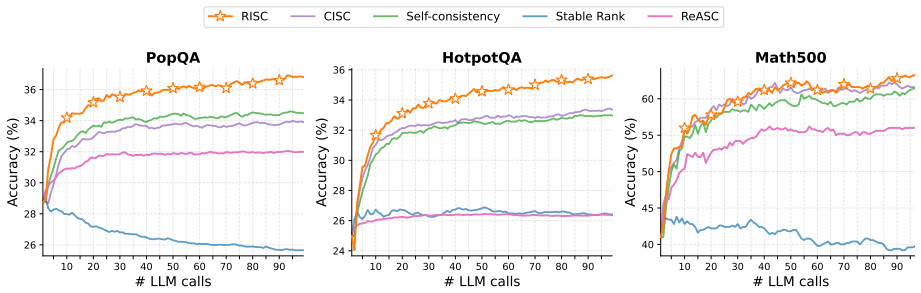
RISC reformulates answer selection inside self-consistency as a ranking problem. A lightweight LambdaRank model scores candidate answers according to five hand-designed features that measure answer frequency, semantic centrality, reasoning-trace consistency and two further signals. When tested on three datasets under a range of test-time budgets, this ranking-based selector consistently produces a better accuracy-efficiency trade-off than majority voting and strong baselines, with particularly large gains on question-answering benchmarks.
What carries the argument
The Ranking-Improved Self-Consistency (RISC) procedure, which replaces majority voting with a LambdaRank model that ranks answers by a linear combination of five complementary features.
If this is right
- RISC delivers higher accuracy than majority voting for any fixed number of sampled reasoning paths.
- The gains are largest on question-answering benchmarks and remain stable across different test-time budgets.
- Each of the five features contributes useful information, yet their combination yields further improvement.
- The ranking formulation works without requiring changes to the underlying language model or additional training data.
Where Pith is reading between the lines
- The same feature set and ranking step could be applied to other sampling-based generation tasks where a single best output must be chosen from many candidates.
- Because the model is lightweight, the method may transfer to new domains with only modest additional labeled examples.
- Future experiments could test whether the learned ranking weights remain stable when the base language model is swapped for a different architecture.
Load-bearing premise
The five hand-designed features supply complementary signals that a small LambdaRank model can learn to combine into accurate rankings without needing large amounts of task-specific labeled data or domain tuning.
What would settle it
Evaluating RISC on a new dataset under matched sampling budgets and finding that its accuracy no longer exceeds that of majority voting would falsify the central claim.
Figures









read the original abstract
Self-consistency improves large language models by sampling multiple reasoning paths and selecting the most frequent answer, but majority voting often fails to recover correct answers that are already present among the samples. We address this limitation with Ranking-Improved Self-Consistency (RISC), which reformulates answer selection in self-consistency as a ranking problem. Instead of relying on a single uncertainty or confidence signal, RISC uses a lightweight LambdaRank model to score candidate answers with five carefully designed features that capture answer frequency, semantic centrality, and reasoning-trace consistency. We evaluate RISC on three datasets under a range of test-time budgets. Across datasets, RISC consistently achieves a better accuracy-efficiency trade-off than standard self-consistency and strong baselines, with particularly large gains on question answering benchmarks. Further analysis shows that the proposed features are individually useful and, more importantly, complementary, highlighting the value of learning to combine multiple informative signals for test-time answer selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Ranking-Improved Self-Consistency (RISC), which recasts answer selection within self-consistency as a learning-to-rank task. A lightweight LambdaRank model is trained on five hand-designed features (frequency, semantic centrality, reasoning-trace consistency, and two others) to score and select among sampled reasoning paths. The central claim is that RISC yields a superior accuracy-efficiency trade-off compared with majority-vote self-consistency and other baselines across three datasets, with especially large gains on question-answering benchmarks; an additional analysis asserts that the five features are individually useful and complementary.
Significance. If the reported gains are shown to be robust to data-split choices, feature-selection leakage, and cross-dataset generalization with modest labeled data, the approach would offer a practical, model-agnostic way to improve test-time reasoning without retraining the underlying LLM. The explicit use of multiple complementary signals via a learned ranker is a natural and potentially reusable idea, though its impact hinges on whether the complementarity survives proper out-of-sample evaluation.
major comments (3)
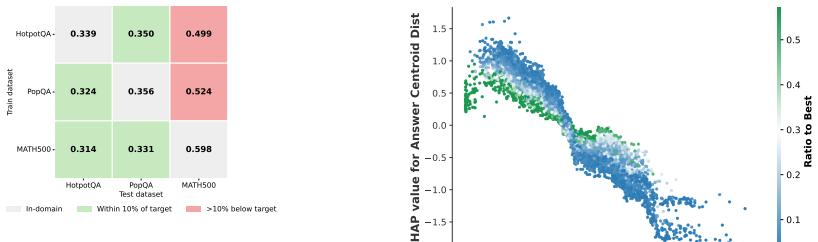
- [§4.2, Table 3] §4.2 and Table 3: the reported accuracy numbers for RISC versus self-consistency are presented without error bars, statistical significance tests, or the exact sizes of the labeled sets used to train LambdaRank on each dataset. Without these quantities it is impossible to determine whether the claimed consistent gains exceed sampling noise or require per-dataset supervision that violates the “limited labeled data, no domain-specific tuning” premise.
- [§5.1] §5.1 (feature analysis): the claim that the five features are “complementary” rests on an in-sample analysis; the manuscript does not report feature-correlation matrices, ablation results under cross-validation, or performance when the ranker is trained on one dataset and tested on another. If the signals are redundant once the model is fitted, the advantage over simple frequency counting disappears.
- [§3.2] §3.2 (LambdaRank training): the description of how positive/negative pairs are constructed for the ranking loss does not specify whether the same held-out test samples used for final evaluation ever leak into the ranking training set. Any such overlap would render the accuracy-efficiency comparison circular.
minor comments (2)
- The abstract states “particularly large gains on question answering benchmarks” but never names the three datasets or the exact budgets; adding these identifiers would improve readability.
- Notation for the five features is introduced only in prose; a compact table listing each feature, its mathematical definition, and its intended signal would reduce ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater statistical rigor and clearer experimental details. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4.2, Table 3] §4.2 and Table 3: the reported accuracy numbers for RISC versus self-consistency are presented without error bars, statistical significance tests, or the exact sizes of the labeled sets used to train LambdaRank on each dataset. Without these quantities it is impossible to determine whether the claimed consistent gains exceed sampling noise or require per-dataset supervision that violates the “limited labeled data, no domain-specific tuning” premise.
Authors: We agree that error bars, significance tests, and explicit reporting of labeled-set sizes are necessary to substantiate the gains. In the revision we will add standard errors over multiple sampling runs, paired statistical tests, and the precise sizes of the per-dataset training splits for LambdaRank (a few hundred examples each). These sizes remain modest and do not involve LLM fine-tuning, preserving the limited-supervision premise while allowing per-dataset ranker training. revision: yes
-
Referee: [§5.1] §5.1 (feature analysis): the claim that the five features are “complementary” rests on an in-sample analysis; the manuscript does not report feature-correlation matrices, ablation results under cross-validation, or performance when the ranker is trained on one dataset and tested on another. If the signals are redundant once the model is fitted, the advantage over simple frequency counting disappears.
Authors: The current complementarity analysis is indeed in-sample. We will revise §5.1 to include (i) feature-correlation matrices, (ii) ablation results obtained via cross-validation on each dataset, and (iii) a cross-dataset transfer experiment in which the ranker is trained on one dataset and evaluated on the others. These additions will provide out-of-sample evidence that the features remain complementary. revision: yes
-
Referee: [§3.2] §3.2 (LambdaRank training): the description of how positive/negative pairs are constructed for the ranking loss does not specify whether the same held-out test samples used for final evaluation ever leak into the ranking training set. Any such overlap would render the accuracy-efficiency comparison circular.
Authors: No test-set leakage occurs: LambdaRank is trained exclusively on a separate held-out labeled split whose examples are never used in the final test evaluation. We will expand §3.2 to explicitly document this partitioning and the construction of positive/negative pairs, removing any ambiguity. revision: yes
Circularity Check
No circularity: method uses external evaluation on held-out data
full rationale
The paper describes sampling reasoning paths, extracting five hand-designed features, training a LambdaRank ranker on labeled data, and evaluating accuracy on test sets. No equations, self-citations, or steps reduce a reported result to a fitted parameter or prior self-work by construction. Complementarity is presented as an empirical finding from analysis, not a definitional input. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Reliability-Aware Adaptive Self-Consistency for Efficient Sampling in LLM Reasoning
Junseok Kim and Nakyeong Yang and Kyungmin Min and Kyomin Jung , year = 2026, journal =. doi:10.48550/ARXIV.2601.02970 , url =. 2601.02970 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.02970 2026
-
[3]
Chi and Quoc V
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , year = 2022, booktitle =
2022
-
[4]
doi:10.18653/V1/P17-1171 , url =
Danqi Chen and Adam Fisch and Jason Weston and Antoine Bordes , year = 2017, booktitle =. doi:10.18653/V1/P17-1171 , url =
-
[5]
Le and Ed H
Xuezhi Wang and Jason Wei and Dale Schuurmans and Quoc V. Le and Ed H. Chi and Sharan Narang and Aakanksha Chowdhery and Denny Zhou , year = 2023, booktitle =
2023
-
[6]
doi: 10.18653/v1/2023.acl-long.546
Alex Mallen and Akari Asai and Victor Zhong and Rajarshi Das and Daniel Khashabi and Hannaneh Hajishirzi , year = 2023, booktitle =. doi:10.18653/V1/2023.ACL-LONG.546 , url =
-
[7]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , year = 1972, publisher =
1972
-
[8]
Chandra and Dexter C
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = 1981, journal =
1981
-
[9]
Andrew, Galen and Gao, Jianfeng , year = 2007, booktitle =
2007
-
[10]
Dan Gusfield , year = 1997, publisher =
1997
-
[11]
Tetreault , year = 2015, journal =
Mohammad Sadegh Rasooli and Joel R. Tetreault , year = 2015, journal =
2015
-
[12]
Ando, Rie Kubota and Zhang, Tong , year = 2005, month = dec, journal =
2005
-
[13]
doi:10.18653/V1/2021.FINDINGS-ACL.188 , url =
Wenhui Wang and Hangbo Bao and Shaohan Huang and Li Dong and Furu Wei , year = 2021, booktitle =. doi:10.18653/V1/2021.FINDINGS-ACL.188 , url =
-
[15]
Yixuan Tang and Yi Yang , year = 2025, url =. 2512.02807 , archiveprefix =
arXiv 2025
-
[16]
Yangzhen Wu and Zhiqing Sun and Shanda Li and Sean Welleck and Yiming Yang , year = 2025, booktitle =
2025
-
[17]
Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R
Carlos E. Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R. Narasimhan , year = 2024, booktitle =
2024
-
[18]
Xinyun Chen and Renat Aksitov and Uri Alon and Jie Ren and Kefan Xiao and Pengcheng Yin and Sushant Prakash and Charles Sutton and Xuezhi Wang and Denny Zhou , year = 2023, url =. 2311.17311 , archiveprefix =
arXiv 2023
-
[19]
Weiqin Wang and Yile Wang and Hui Huang , year = 2025, url =. 2505.10772 , archiveprefix =
arXiv 2025
-
[20]
Abril and Robert Plant , year = 2007, month = jan, journal =
Patricia S. Abril and Robert Plant , year = 2007, month = jan, journal =. doi:10.1145/1188913.1188915 , url =
-
[21]
doi:10.1145/1219092.1219093 , url =
Sarah Cohen and Werner Nutt and Yehoshua Sagic , year = 2007, month = apr, journal =. doi:10.1145/1219092.1219093 , url =
-
[22]
David Kosiur , year = 2001, publisher =
2001
-
[24]
doi:10.1007/3-540-09237-4 , url =
-
[25]
Spector , year = 1990, booktitle =
Asad Z. Spector , year = 1990, booktitle =. doi:10.1145/90417.90738 , url =
-
[26]
Douglass and David Harel and Mark B
Bruce P. Douglass and David Harel and Mark B. Trakhtenbrot , year = 1998, booktitle =. doi:10.1007/3-540-65193-4_29 , url =
-
[27]
Knuth , year = 1997, publisher =
Donald E. Knuth , year = 1997, publisher =
1997
-
[28]
Knuth , year = 1998, publisher =
Donald E. Knuth , year = 1998, publisher =
1998
-
[29]
Dan Geiger and Christopher Meek , year = 2005, month = jan, booktitle =
2005
-
[30]
Smith , year = 2010, booktitle =
Stan W. Smith , year = 2010, booktitle =
2010
-
[31]
Matthew Van Gundy and Davide Balzarotti and Giovanni Vigna , year = 2007, booktitle =
2007
-
[32]
Matthew Van Gundy and Davide Balzarotti and Giovanni Vigna , year = 2008, booktitle =
2008
-
[33]
Matthew Van Gundy and Davide Balzarotti and Giovanni Vigna , year = 2009, booktitle =
2009
-
[34]
doi:10.1145/567752.567774 , url =
Sten Andler , year = 1979, booktitle =. doi:10.1145/567752.567774 , url =
-
[35]
David Harel , year = 1978, address =
1978
-
[36]
Anisi , year = 2003, school =
David A. Anisi , year = 2003, school =
2003
-
[37]
Clarkson , year = 1985, address =
Kenneth L. Clarkson , year = 1985, address =
1985
-
[38]
Harry Thornburg , year = 2001, month = mar, url =
2001
-
[39]
OpenAI , year = 2024, journal =. doi:10.48550/ARXIV.2412.16720 , url =. 2412.16720 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.16720 2024
-
[40]
Daya Guo and Dejian Yang and Haowei Zhang and Junxiao Song and Peiyi Wang and Qihao Zhu and Runxin Xu and Ruoyu Zhang and Shirong Ma and Xiao Bi and Xiaokang Zhang and Xingkai Yu and Yu Wu and Z. F. Wu and Zhibin Gou and Zhihong Shao and Zhuoshu Li and Ziyi Gao and Aixin Liu and Bing Xue and Bingxuan Wang and Bochao Wu and Bei Feng and Chengda Lu and Chen...
-
[41]
Min and Yangruibo Ding and Luca Buratti and Saurabh Pujar and Gail E
Marcus J. Min and Yangruibo Ding and Luca Buratti and Saurabh Pujar and Gail E. Kaiser and Suman Jana and Baishakhi Ray , year = 2024, booktitle =
2024
-
[42]
Amballa, Avinash and Parashar, Aditya and Singh, Aditya Vikram and Lai, Jinlin and Rozonoyer, Benjamin , year = 2025, booktitle =
2025
-
[43]
doi:10.48550/ARXIV.2512.02807 , url =
Yixuan Tang and Yi Yang , year = 2025, journal =. doi:10.48550/ARXIV.2512.02807 , url =. 2512.02807 , timestamp =
-
[44]
Sutton , year = 2019, note =
Richard S. Sutton , year = 2019, note =
2019
-
[45]
doi:10.48550/ARXIV.2504.10478 , url =
Xingyu Dang and Christina Baek and Kaiyue Wen and Zico Kolter and Aditi Raghunathan , year = 2025, journal =. doi:10.48550/ARXIV.2504.10478 , url =. 2504.10478 , timestamp =
-
[46]
doi:10.48550/ARXIV.2603.01025 , url =
Zhan Zhuang and Xiequn Wang and Zebin Chen and Feiyang Ye and Ying Wei and Kede Ma and Yu Zhang , year = 2026, journal =. doi:10.48550/ARXIV.2603.01025 , url =. 2603.01025 , timestamp =
-
[47]
doi:10.48550/ARXIV.2503.08681 , url =
Viktor Moskvoretskii and Chris Biemann and Irina Nikishina , year = 2025, journal =. doi:10.48550/ARXIV.2503.08681 , url =. 2503.08681 , timestamp =
-
[49]
Shunyu Yao and Dian Yu and Jeffrey Zhao and Izhak Shafran and Tom Griffiths and Yuan Cao and Karthik Narasimhan , year = 2023, booktitle =
2023
-
[50]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell and Jaehoon Lee and Kelvin Xu and Aviral Kumar , year = 2024, journal =. doi:10.48550/ARXIV.2408.03314 , url =. 2408.03314 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.03314 2024
-
[51]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,
Niklas Muennighoff and Zitong Yang and Weijia Shi and Xiang Lisa Li and Li Fei. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,. doi:10.18653/V1/2025.EMNLP-MAIN.1025 , url =
-
[52]
doi:10.18653/V1/2024.FINDINGS-ACL.297 , url =
Ryan Park and Rafael Rafailov and Stefano Ermon and Chelsea Finn , year = 2024, booktitle =. doi:10.18653/V1/2024.FINDINGS-ACL.297 , url =
-
[53]
doi:10.48550/ARXIV.2310.03716 , url =
Prasann Singhal and Tanya Goyal and Jiacheng Xu and Greg Durrett , year = 2023, journal =. doi:10.48550/ARXIV.2310.03716 , url =. 2310.03716 , timestamp =
-
[54]
doi:10.48550/ARXIV.2310.06271 , url =
Ziwei Ji and Tiezheng Yu and Yan Xu and Nayeon Lee and Etsuko Ishii and Pascale Fung , year = 2023, journal =. doi:10.48550/ARXIV.2310.06271 , url =. 2310.06271 , timestamp =
-
[55]
Han Wang and Archiki Prasad and Elias Stengel. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers),. doi:10.18653/V1/2024.ACL-SHORT.28 , url =
-
[56]
Littman and Richard S
Michael L. Littman and Richard S. Sutton and Satinder Singh , year = 2001, booktitle =
2001
-
[57]
Amir Taubenfeld and Tom Sheffer and Eran Ofek and Amir Feder and Ariel Goldstein and Zorik Gekhman and Gal Yona , year = 2025, booktitle =
2025
-
[58]
ACM SIGGRAPH 2003 Video Review on Animation theater Program: Part I - Vol
Dave Novak , year = 2003, month =. ACM SIGGRAPH 2003 Video Review on Animation theater Program: Part I - Vol. 145 (July 27--27, 2003) , publisher =. doi:10.945/woot07-S422 , url =
2003
-
[59]
doi:10.1145/1057270.1057278 , url =
Newton Lee , year = 2005, month =. doi:10.1145/1057270.1057278 , url =
-
[60]
Bernard Rous , year = 2008, month = jul, journal =
2008
-
[62]
doi:10.1145/351827.384253 , issn =
Werneck, Renato and Setubal, Jo\. doi:10.1145/351827.384253 , issn =
-
[64]
and Mei, Alessandro , year = 2009, month = oct, journal =
Conti, Mauro and Di Pietro, Roberto and Mancini, Luigi V. and Mei, Alessandro , year = 2009, month = oct, journal =. doi:10.1016/j.inffus.2009.01.002 , issn =
-
[65]
Li, Cheng-Lun and Buyuktur, Ayse G. and Hutchful, David K. and Sant, Natasha B. and Nainwal, Satyendra K. , year = 2008, booktitle =. doi:10.1145/1358628.1358946 , isbn =
-
[66]
, year = 1999, publisher =
Hollis, Billy S. , year = 1999, publisher =
1999
-
[67]
Goossens, Michel and Rahtz, S. P. and Moore, Ross and Sutor, Robert S. , year = 1999, publisher =
1999
-
[68]
and Rosenberg, Arnold L
Buss, Jonathan F. and Rosenberg, Arnold L. and Knott, Judson D. , year = 1987, publisher =
1987
-
[69]
, year = 2008, location =
2008
-
[70]
Clarkson, Kenneth Lee , year = 1985, address =
1985
-
[71]
doi:http://dx.doi.org/10.1109/ICWS.2004.64 , isbn =
Proceedings of the IEEE International Conference on Web Services , publisher =. doi:http://dx.doi.org/10.1109/ICWS.2004.64 , isbn =
-
[72]
, year = 1986, publisher =
Petrie, Charles J. , year = 1986, publisher =
1986
-
[73]
, year = 1986, address =
Petrie, Charles J. , year = 1986, address =
1986
-
[74]
Knuth , year = 1981, publisher =
Donald E. Knuth , year = 1981, publisher =
1981
-
[75]
Kong, Wei-Chang , year = 2001, booktitle =
2001
-
[76]
Kong, Wei-Chang , year = 2001, publisher =
2001
-
[77]
Kong, Wei-Chang , year = 2002, booktitle =
2002
-
[78]
Kong, Wei-Chang , year = 2003, booktitle =
2003
-
[79]
Kong, Wei-Chang , year = 2004, publisher =
2004
-
[80]
Kong, Wei-Chang , year = 2005, publisher =
2005
-
[81]
Kong, Wei-Chang , year = 2006, publisher =
2006
-
[82]
Mehdi Saeedi and Morteza Saheb Zamani and Mehdi Sedighi , year = 2010, month = apr, journal =
2010
-
[83]
Mehdi Saeedi and Morteza Saheb Zamani and Mehdi Sedighi and Zahra Sasanian , year = 2010, month = dec, journal =
2010
-
[84]
doi:https://doi.org/10.1137/080734467 , issn =
Kirschmer, Markus and Voight, John , year = 2010, month = jan, journal =. doi:https://doi.org/10.1137/080734467 , issn =
-
[85]
Hoare, C. A. R. , year = 1972, booktitle =
1972
-
[86]
doi:http://doi.acm.org/10.1145/800025.1198348 , isbn =
Lee, Jan , year = 1981, booktitle =. doi:http://doi.acm.org/10.1145/800025.1198348 , isbn =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.