MaCo-GAN: Manifold-Contrastive Adversarial Learning for Single Image Super-Resolution
Pith reviewed 2026-06-28 06:51 UTC · model grok-4.3
The pith
Replacing the adversarial loss in super-resolution GANs with a manifold-contrastive objective improves the perception-distortion trade-off.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
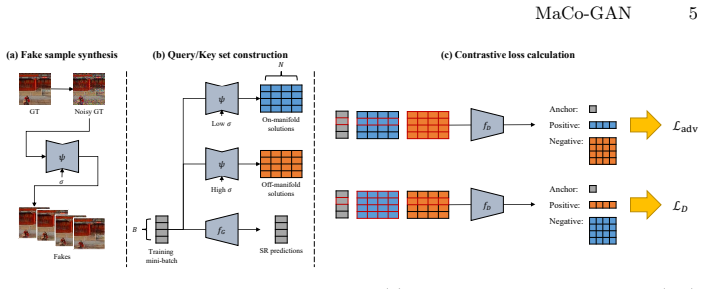
By replacing the conventional adversarial loss with a supervised contrastive objective built on a dynamic fake sample synthesizer, the generator is trained to attract predictions to on-manifold fakes and repel them from off-manifold fakes while the discriminator optimizes the opposite, yielding measurable improvements in the perception-distortion trade-off when inserted into existing single-image super-resolution models.
What carries the argument
The dynamic fake sample synthesizer, which generates a spectrum of challenging yet low-resolution-corresponding fake images from ground truth to support the conditional contrastive minimax game.
If this is right
- Any existing GAN-based super-resolution model can adopt the objective by loss substitution alone and expect improved conditional realism.
- The contrastive game enforces stricter low-resolution fidelity than standard adversarial training because synthesized fakes are explicitly LR-matched.
- Discriminator training becomes a direct optimization over manifold distance rather than a binary real/fake decision.
- The framework supplies a controllable spectrum of positive and negative examples that scale with the desired distortion level.
Where Pith is reading between the lines
- The same synthesizer-plus-contrastive pattern could be tested in other conditional image-to-image tasks such as denoising or deblurring where correspondence to input must be preserved.
- If the on-manifold and off-manifold distinction proves robust, it may reduce the need for perceptual loss terms that currently require separate pretrained networks.
- Extending the synthesizer to produce multi-scale or patch-level fakes might further tighten the conditional manifold constraint.
Load-bearing premise
The dynamic fake sample synthesizer can produce perceptually plausible fake images that maintain strict low-resolution correspondence while spanning a useful range of distortion levels.
What would settle it
Running the same baseline super-resolution models with and without the contrastive objective on standard benchmarks and checking whether the perception-distortion Pareto front shifts measurably when the synthesizer is ablated or replaced by random perturbations.
Figures





read the original abstract
Conventional Generative Adversarial Networks (GANs) for Single Image Super-Resolution (SISR) often struggle with hallucinated artifacts, largely because standard discriminators evaluate overall image naturalness rather than strict conditional realism. To address this, we propose MaCo-GAN, a novel manifold-contrastive GAN framework that replaces the conventional adversarial loss with a supervised contrastive objective. A core component of our method is a dynamic fake sample synthesizer that transforms ground truth (GT) data into a spectrum of challenging, perceptually plausible fake images that strictly maintain low-resolution (LR) correspondence. Utilizing these synthesized samples, we establish a robust contrastive minimax game: the generator is trained to attract its predictions toward on-manifold fakes (low distortion) and repel them from off-manifold fakes (high distortion), while the discriminator optimizes the exact opposite. By simply replacing the adversarial loss of a baseline SR model with our proposed objective, we demonstrate consistent improvements in the perception-distortion trade-off across various benchmarks. Extensive ablation studies validate the effectiveness of our framework and provide deep insights into the dynamics of this conditional contrastive game.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MaCo-GAN, a manifold-contrastive GAN for single-image super-resolution. It replaces the standard adversarial loss with a supervised contrastive objective built around a dynamic fake-sample synthesizer that converts ground-truth images into a spectrum of on-manifold (low-distortion) and off-manifold (high-distortion) fakes while preserving strict low-resolution correspondence. The generator is trained to attract its outputs toward on-manifold fakes and repel them from off-manifold fakes; the discriminator does the reverse. The central claim is that simply substituting this objective for the adversarial loss in any baseline SR model yields consistent gains on the perception-distortion trade-off across benchmarks, with supporting ablation studies.
Significance. If the empirical claims are substantiated, the framework would supply a concrete mechanism for enforcing conditional realism inside conditional GANs for SISR by explicitly contrasting synthesized manifold samples. The dynamic synthesizer is presented as the key technical device enabling the contrastive minimax game. The approach directly targets a recognized weakness of conventional SR discriminators and, if the reported gains prove robust, would constitute a useful incremental advance in the perception-distortion literature.
major comments (2)
- [Abstract] Abstract, final sentence: the assertion that "simply replacing the adversarial loss of a baseline SR model with our proposed objective" produces "consistent improvements in the perception-distortion trade-off across various benchmarks" is unsupported by any quantitative metrics, error bars, tables, figures, dataset descriptions, or ablation results in the supplied text, rendering the central empirical claim unevaluable.
- [Abstract] Abstract, paragraph 2: the dynamic fake-sample synthesizer is described as transforming GT data into "challenging, perceptually plausible fake images that strictly maintain low-resolution correspondence," yet no equations, algorithmic steps, or independence arguments are supplied to show that the synthesis procedure itself is free of fitted parameters or circular dependence on the model being trained; this directly affects whether the contrastive objective can be evaluated as a drop-in replacement.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on the abstract. We address each major comment below and indicate the revisions we will make to improve clarity and evaluability while preserving the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract, final sentence: the assertion that "simply replacing the adversarial loss of a baseline SR model with our proposed objective" produces "consistent improvements in the perception-distortion trade-off across various benchmarks" is unsupported by any quantitative metrics, error bars, tables, figures, dataset descriptions, or ablation results in the supplied text, rendering the central empirical claim unevaluable.
Authors: We acknowledge that the abstract, being a concise summary, does not embed the specific numerical results, error bars, or table references. The full manuscript contains the supporting quantitative evidence, including tables, figures, dataset details, and ablation studies across benchmarks that substantiate the claim of consistent improvements. To directly address the evaluability concern, we will revise the abstract to incorporate key quantitative metrics (e.g., average gains in perceptual and distortion measures) or add explicit cross-references to the relevant results sections and tables. This change will make the empirical claim traceable from the abstract itself. revision: yes
-
Referee: [Abstract] Abstract, paragraph 2: the dynamic fake-sample synthesizer is described as transforming GT data into "challenging, perceptually plausible fake images that strictly maintain low-resolution correspondence," yet no equations, algorithmic steps, or independence arguments are supplied to show that the synthesis procedure itself is free of fitted parameters or circular dependence on the model being trained; this directly affects whether the contrastive objective can be evaluated as a drop-in replacement.
Authors: The abstract provides only a high-level description of the synthesizer. The full manuscript supplies the complete equations, algorithmic steps, and arguments demonstrating that the procedure is parameter-free and maintains strict independence from the trained SR model (no circular dependence), thereby supporting its use as a drop-in replacement. To improve evaluability at the abstract level, we will add a concise clarification that the synthesizer operates without learned parameters and preserves LR correspondence independently, with full technical details provided in the methods section. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and supplied description introduce a contrastive objective built on a dynamic fake-sample synthesizer, but present no equations, derivations, or self-citations that reduce any claimed result to its own inputs by construction. The central claim is an empirical observation that replacing the adversarial loss yields perception-distortion gains; this is a testable performance statement rather than a self-referential prediction or fitted-input renaming. No load-bearing step matches any of the enumerated circularity patterns, and the method is described as self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops
Agustsson, E., Timofte, R.: Ntire 2017 challenge on single image super-resolution: Dataset and study. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops. pp. 126–135 (2017)
2017
-
[2]
In: European Conference on Computer Vision
Ahn, D., Cho, H., Min, J., Jang, W., Kim, J., Kim, S., Park, H.H., Jin, K.H., Kim, S.: Self-rectifying diffusion sampling with perturbed-attention guidance. In: European Conference on Computer Vision. pp. 1–17. Springer (2024)
2024
-
[3]
TripletGAN: Training Generative Model with Triplet Loss
Cao,G.,Yang,Y.,Lei,J.,Jin,C.,Liu,Y.,Song,M.:Tripletgan:Traininggenerative model with triplet loss. arXiv preprint arXiv:1711.05084 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
In: International conference on machine learning
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: International conference on machine learning. pp. 1597–1607. PmLR (2020)
2020
-
[5]
Improved Baselines with Momentum Contrastive Learning
Chen, X., Fan, H., Girshick, R., He, K.: Improved baselines with momentum con- trastive learning. arXiv preprint arXiv:2003.04297 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[6]
Advances in neural information processing systems34, 8780–8794 (2021)
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. Advances in neural information processing systems34, 8780–8794 (2021)
2021
-
[7]
IEEE transactions on pattern analysis and machine intelligence44(5), 2567–2581 (2020)
Ding, K., Ma, K., Wang, S., Simoncelli, E.P.: Image quality assessment: Unify- ing structure and texture similarity. IEEE transactions on pattern analysis and machine intelligence44(5), 2567–2581 (2020)
2020
-
[8]
In: European conference on computer vision
Dong, C., Loy, C.C., Tang, X.: Accelerating the super-resolution convolutional neural network. In: European conference on computer vision. pp. 391–407. Springer (2016)
2016
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12873–12883 (2021)
2021
-
[10]
Advances in neural in- formation processing systems27(2014)
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. Advances in neural in- formation processing systems27(2014)
2014
-
[11]
In: Proceedings of the thirteenth inter- national conference on artificial intelligence and statistics
Gutmann, M., Hyvärinen, A.: Noise-contrastive estimation: A new estimation prin- ciple for unnormalized statistical models. In: Proceedings of the thirteenth inter- national conference on artificial intelligence and statistics. pp. 297–304. JMLR Workshop and Conference Proceedings (2010)
2010
-
[12]
Momentum contrast for unsupervised visual representation learning,
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. arxiv e-prints, art. arXiv preprint arXiv:1911.05722 2(2019)
-
[13]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[14]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Hong, S., Lee, G., Jang, W., Kim, S.: Improving sample quality of diffusion mod- els using self-attention guidance. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7462–7471 (2023) 16 D. Han, et al
2023
-
[16]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Huang, J.B., Singh, A., Ahuja, N.: Single image super-resolution from transformed self-exemplars. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 5197–5206 (2015)
2015
-
[17]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with condi- tional adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1125–1134 (2017)
2017
-
[18]
Machine learning51(2), 115–135 (2003)
James, G.M.: Variance and bias for general loss functions. Machine learning51(2), 115–135 (2003)
2003
-
[19]
Training gans with stronger augmen- tations via contrastive discriminator,
Jeong, J., Shin, J.: Training gans with stronger augmentations via contrastive discriminator. arXiv preprint arXiv:2103.09742 (2021)
-
[20]
The relativistic discriminator: a key element missing from standard GAN
Jolicoeur-Martineau,A.:Therelativisticdiscriminator:Akeyelementmissingfrom standard gan. arXiv preprint arXiv:1807.00734 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[21]
In: Proceedings of the IEEE/CVF international conference on computer vision
Ke, J., Wang, Q., Wang, Y., Milanfar, P., Yang, F.: Musiq: Multi-scale image quality transformer. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5148–5157 (2021)
2021
-
[22]
Advances in neural information processing systems33, 18661–18673 (2020)
Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., Maschinot, A., Liu, C., Krishnan, D.: Supervised contrastive learning. Advances in neural information processing systems33, 18661–18673 (2020)
2020
-
[23]
arXiv preprint arXiv:2501.17683 (2025)
Kim, B.J., Kim, S.W.: Temperature-free loss function for contrastive learning. arXiv preprint arXiv:2501.17683 (2025)
-
[24]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Ledig, C., Theis, L., Huszár, F., Caballero, J., Cunningham, A., Acosta, A., Aitken, A., Tejani, A., Totz, J., Wang, Z., et al.: Photo-realistic single image super- resolution using a generative adversarial network. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4681–4690 (2017)
2017
-
[25]
Lee, M., Hyun, S., Jun, W., Heo, J.P.: Auto-encoded supervision for perceptual imagesuper-resolution.In:ProceedingsoftheComputerVisionandPatternRecog- nition Conference. pp. 17958–17968 (2025)
2025
-
[26]
Harmonizing Maximum Likelihood with GANs for Multimodal Conditional Generation
Lee, S., Ha, J., Kim, G.: Harmonizing maximum likelihood with gans for multi- modal conditional generation. arXiv preprint arXiv:1902.09225 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, Y., Zhang, K., Liang, J., Cao, J., Liu, C., Gong, R., Zhang, Y., Tang, H., Liu, Y., Demandolx, D., et al.: Lsdir: A large scale dataset for image restoration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1775–1787 (2023)
2023
-
[28]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liang, J., Zeng, H., Zhang, L.: Details or artifacts: A locally discriminative learning approach to realistic image super-resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5657–5666 (2022)
2022
-
[29]
In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops
Lim,B.,Son,S.,Kim,H.,Nah,S.,MuLee,K.:Enhanceddeepresidualnetworksfor single image super-resolution. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops. pp. 136–144 (2017)
2017
-
[30]
Lim, J.H., Ye, J.C.: Geometric gan. arXiv preprint arXiv:1705.02894 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
IEEE transactions on pattern analysis and machine intelligence44(11), 7898–7911 (2021)
Ma, C., Rao, Y., Lu, J., Zhou, J.: Structure-preserving image super-resolution. IEEE transactions on pattern analysis and machine intelligence44(11), 7898–7911 (2021)
2021
-
[32]
In: Proceedings eighth IEEE international conference on com- puter vision
Martin, D., Fowlkes, C., Tal, D., Malik, J.: A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: Proceedings eighth IEEE international conference on com- puter vision. ICCV 2001. vol. 2, pp. 416–423. IEEE (2001)
2001
-
[33]
Multimedia tools and applications76(20), 21811–21838 (2017) MaCo-GAN 17
Matsui, Y., Ito, K., Aramaki, Y., Fujimoto, A., Ogawa, T., Yamasaki, T., Aizawa, K.: Sketch-based manga retrieval using manga109 dataset. Multimedia tools and applications76(20), 21811–21838 (2017) MaCo-GAN 17
2017
-
[34]
In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition
Menon, S., Damian, A., Hu, S., Ravi, N., Rudin, C.: Pulse: Self-supervised photo upsampling via latent space exploration of generative models. In: Proceedings of the ieee/cvf conference on computer vision and pattern recognition. pp. 2437–2445 (2020)
2020
-
[35]
completely blind
Mittal, A., Soundararajan, R., Bovik, A.C.: Making a “completely blind” image quality analyzer. IEEE Signal processing letters20(3), 209–212 (2012)
2012
-
[36]
Advances in Neural Information Processing Systems34, 16398–16409 (2021)
Ning, Q., Dong, W., Li, X., Wu, J., Shi, G.: Uncertainty-driven loss for single image super-resolution. Advances in Neural Information Processing Systems34, 16398–16409 (2021)
2021
-
[37]
In: International conference on machine learning
Odena, A., Olah, C., Shlens, J.: Conditional image synthesis with auxiliary classi- fier gans. In: International conference on machine learning. pp. 2642–2651. PMLR (2017)
2017
-
[38]
Representation Learning with Contrastive Predictive Coding
Oord, A.v.d., Li, Y., Vinyals, O.: Representation learning with contrastive predic- tive coding. arXiv preprint arXiv:1807.03748 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Advances in neural information processing sys- tems32(2019)
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.: Pytorch: An imperative style, high- performance deep learning library. Advances in neural information processing sys- tems32(2019)
2019
-
[40]
In: International Conference on Medical image computing and computer-assisted intervention
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedi- cal image segmentation. In: International Conference on Medical image computing and computer-assisted intervention. pp. 234–241. Springer (2015)
2015
-
[41]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Schonfeld, E., Schiele, B., Khoreva, A.: A u-net based discriminator for generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8207–8216 (2020)
2020
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Soh, J.W., Park, G.Y., Jo, J., Cho, N.I.: Natural and realistic single image super- resolution with explicit natural manifold discrimination. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8122–8131 (2019)
2019
-
[43]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Tseng, H.Y., Jiang, L., Liu, C., Yang, M.H., Yang, W.: Regularizing generative adversarial networks under limited data. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 7921–7931 (2021)
2021
-
[44]
In: Proceedings of the AAAI conference on artificial intelligence
Wang, J., Chan, K.C., Loy, C.C.: Exploring clip for assessing the look and feel of images. In: Proceedings of the AAAI conference on artificial intelligence. vol. 37, pp. 2555–2563 (2023)
2023
-
[45]
In: Proceedings of the IEEE/CVF in- ternational conference on computer vision
Wang, X., Xie, L., Dong, C., Shan, Y.: Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In: Proceedings of the IEEE/CVF in- ternational conference on computer vision. pp. 1905–1914 (2021)
1905
-
[46]
In: Proceed- ings of the European conference on computer vision (ECCV) workshops
Wang, X., Yu, K., Wu, S., Gu, J., Liu, Y., Dong, C., Qiao, Y., Change Loy, C.: Esrgan: Enhanced super-resolution generative adversarial networks. In: Proceed- ings of the European conference on computer vision (ECCV) workshops. pp. 0–0 (2018)
2018
-
[47]
IEEE transactions on pattern analysis and machine intelligence43(10), 3365–3387 (2020)
Wang, Z., Chen, J., Hoi, S.C.: Deep learning for image super-resolution: A survey. IEEE transactions on pattern analysis and machine intelligence43(10), 3365–3387 (2020)
2020
-
[48]
arXiv preprint arXiv:2409.16211 , year=
Weber, M., Yu, L., Yu, Q., Deng, X., Shen, X., Cremers, D., Chen, L.C.: Maskbit: Embedding-free image generation via bit tokens. arXiv preprint arXiv:2409.16211 (2024)
-
[49]
IEEE Transactions on Neural Networks and Learning Sys- tems35(11), 15834–15845 (2023) 18 D
Wu, G., Jiang, J., Liu, X.: A practical contrastive learning framework for single- image super-resolution. IEEE Transactions on Neural Networks and Learning Sys- tems35(11), 15834–15845 (2023) 18 D. Han, et al
2023
-
[50]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Wu, Z., Xiong, Y., Yu, S.X., Lin, D.: Unsupervised feature learning via non- parametric instance discrimination. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3733–3742 (2018)
2018
-
[51]
IEEE Transactions on Pattern Analysis and Machine Intelligence46(9), 6199–6215 (2024)
Xu,T.,Li,L.,Mi,P.,Zheng,X.,Chao,F.,Ji,R.,Tian,Y.,Shen,Q.:Uncoveringthe over-smoothing challenge in image super-resolution: Entropy-based quantification and contrastive optimization. IEEE Transactions on Pattern Analysis and Machine Intelligence46(9), 6199–6215 (2024)
2024
-
[52]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Yang, S., Wu, T., Shi, S., Lao, S., Gong, Y., Cao, M., Wang, J., Yang, Y.: Maniqa: Multi-dimension attention network for no-reference image quality assessment. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 1191–1200 (2022)
2022
-
[53]
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Yu, L., Lezama, J., Gundavarapu, N.B., Versari, L., Sohn, K., Minnen, D., Cheng, Y., Birodkar, V., Gupta, A., Gu, X., et al.: Language model beats diffusion– tokenizer is key to visual generation. arXiv preprint arXiv:2310.05737 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
Advances in Neural Information Processing Systems37, 128940–128966 (2024)
Yu, Q., Weber, M., Deng, X., Shen, X., Cremers, D., Chen, L.C.: An image is worth 32 tokens for reconstruction and generation. Advances in Neural Information Processing Systems37, 128940–128966 (2024)
2024
-
[55]
arXiv preprint arXiv:2107.00708 (2021)
Zhang, J., Lu, S., Zhan, F., Yu, Y.: Blind image super-resolution via contrastive representation learning. arXiv preprint arXiv:2107.00708 (2021)
-
[56]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018) Supplementary Material for MaCo-GAN: Manifold-Contrastive Adversarial Learning for Single Image Super-Resolution Daeyoung H...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.