FoeGlass: Simple In-Context Learning Is Enough for Red Teaming Audio Deepfake Detectors
Pith reviewed 2026-06-28 04:58 UTC · model grok-4.3
The pith
FoeGlass shows that LLM in-context learning alone can generate TTS inputs to expose audio deepfake detector failures in a black-box setting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
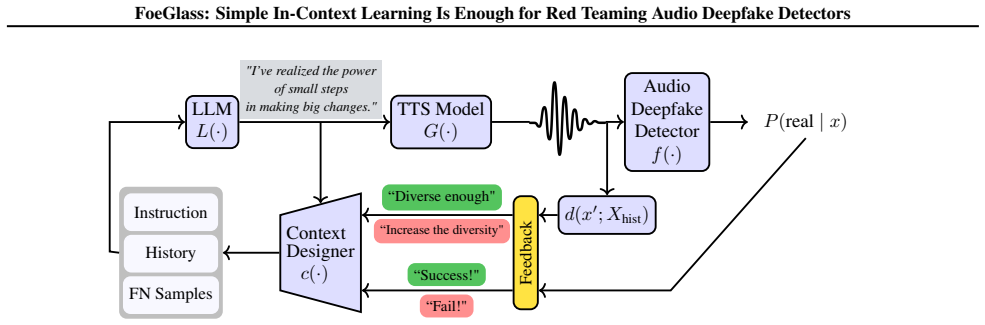
FoeGlass demonstrates that in-context learning in an LLM, when supplied with a context built from diversity measurements of prior generations, is sufficient to discover new failure modes of audio deepfake detectors by producing TTS inputs whose outputs evade the detector, yielding up to 94 percent higher false negative rates than baselines while remaining fully automated and black-box.
What carries the argument
LLM in-context learning guided by a prompt context that tracks diversity measurements across generated samples to explore the TTS input space.
If this is right
- Data from FoeGlass raises false negative rates up to 94 percent over unconditional sampling and recent spoof datasets.
- Attacks generated by FoeGlass transfer across different target ADD models.
- Fine-tuning an ADD model on FoeGlass samples improves its robustness by up to 41 percent.
- The entire process requires no manual supervision or labeled adversarial data.
Where Pith is reading between the lines
- The same prompting strategy could be tested on detectors for other generated media such as video or images.
- Iterative application of FoeGlass might allow detectors to be hardened in a closed loop without human curation.
- If diversity measurements prove general, the method could extend red-teaming to other black-box generative systems beyond audio.
Load-bearing premise
A context built from diversity measurements is enough to stop the LLM from repeatedly producing similar text inputs instead of genuinely new failure modes.
What would settle it
Running FoeGlass on a held-out ADD model and checking whether the new samples raise its false negative rate by less than the improvement shown over unconditional sampling on the same model.
Figures





read the original abstract
Audio deepfake detection (ADD) models are critical for countering the malicious use of text-to-speech (TTS) models. Evaluating and strengthening ADD models requires developing datasets that span the space of generated audio and highlight high-error regions. Existing dataset development strategies face two challenges: (i) manual collection, and (ii) inefficient discovery of blind spots in the ADD models. To address these challenges, we propose FoeGlass, the first black-box automated red-teaming method for ADDs, which effectively discovers ADD failure modes in the space of generated audio underexplored by state-of-the-art deepfake benchmarks. FoeGlass uses the in-context learning capabilities of an LLM to explore the input space of a TTS model, generating audio samples that fool the target ADD using only black-box access to all components. By using a carefully designed context based on diversity measurements, FoeGlass mitigates the common problem of mode collapse in automated red-teaming systems. Empirical evaluations on several open-source ADD and TTS models demonstrate that data generated from FoeGlass substantially improves the false negative rates over unconditional sampling baselines and recent spoofing datasets by up to 94%, while requiring no manual supervision. Furthermore, we show that the attacks generated by FoeGlass are transferable across different target ADDs, demonstrating its broad applicability and ease of use for the automated red teaming of ADD systems. Finally, fine-tuning ADD models on FoeGlass-generated samples notably enhances the robustness of the detectors (up 41%).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FoeGlass, a black-box automated red-teaming method for audio deepfake detectors (ADDs) that uses LLM in-context learning guided by diversity measurements to explore TTS input spaces and generate adversarial audio samples. It claims these samples improve false negative rates by up to 94% over unconditional sampling and recent spoofing datasets, are transferable across ADDs, and yield up to 41% robustness gains when used for fine-tuning, all without manual supervision.
Significance. If the diversity-guided generation reliably discovers novel failure modes rather than collapsing to similar samples, the approach would offer a practical, low-supervision advance for systematically strengthening ADD robustness and expanding evaluation datasets beyond current benchmarks.
major comments (3)
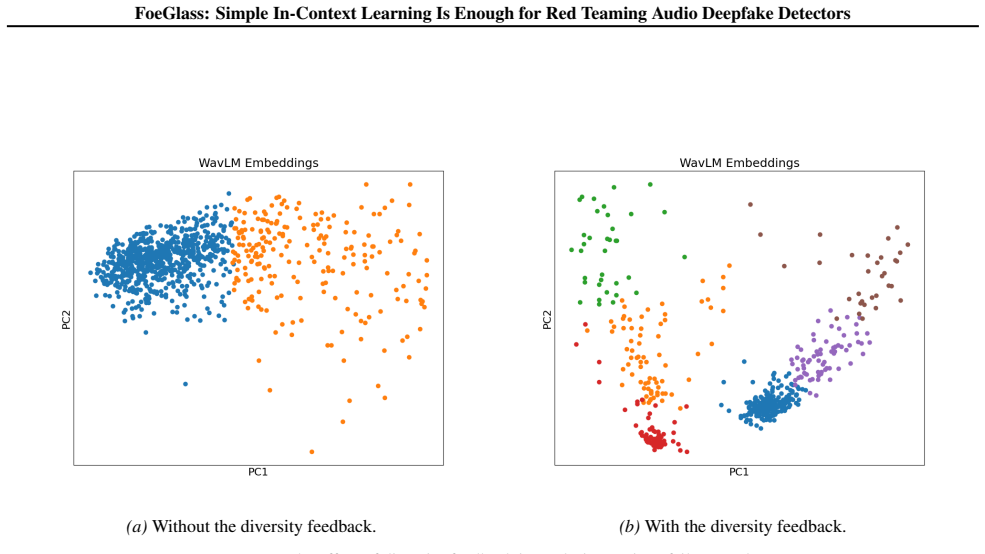
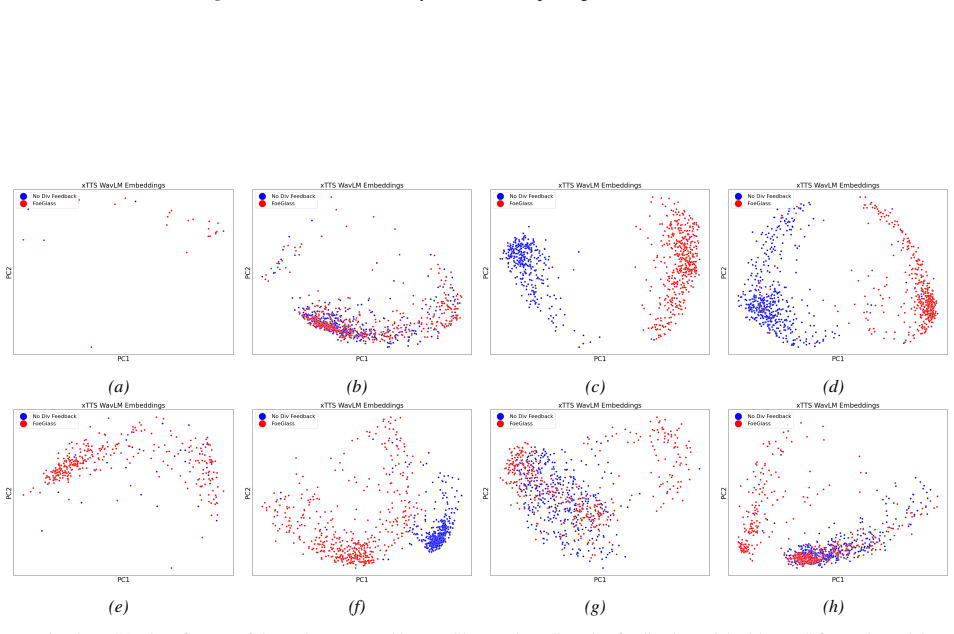
- [§3] §3 (FoeGlass method): The central claim that a diversity-based in-context prompt mitigates mode collapse and enables discovery of genuinely new failure modes lacks any quantitative check such as embedding variance, pairwise acoustic distances, or an ablation removing the diversity term; without this, the 94% FN gains could be explained by targeted search rather than the claimed automated advance.
- [§4] §4 (Experiments): The reported FN improvements (up to 94%) and robustness gains (up to 41%) are presented without details on the number of ADD/TTS models evaluated, number of independent runs, statistical significance tests, or confirmation that the diversity metric was not tuned post-hoc on the test set.
- [§4.3] §4.3 (Transferability): The transferability results across target ADDs are load-bearing for the broad-applicability claim, yet no controls are described for whether the generated samples were optimized against one model and then evaluated on others or whether the diversity context was held fixed.
minor comments (2)
- [Abstract] Abstract: 'up 41%' should read 'up to 41%'.
- [§3] Notation for diversity measurement is introduced without an explicit equation or pseudocode, making reproduction harder.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested clarifications and additional analyses.
read point-by-point responses
-
Referee: [§3] §3 (FoeGlass method): The central claim that a diversity-based in-context prompt mitigates mode collapse and enables discovery of genuinely new failure modes lacks any quantitative check such as embedding variance, pairwise acoustic distances, or an ablation removing the diversity term; without this, the 94% FN gains could be explained by targeted search rather than the claimed automated advance.
Authors: We agree that the manuscript would benefit from explicit quantitative validation of the diversity term's contribution. In the revision we will add an ablation that removes the diversity component, together with measurements of embedding variance and pairwise acoustic distances among generated samples, to demonstrate that the observed gains arise from increased exploration rather than targeted search alone. revision: yes
-
Referee: [§4] §4 (Experiments): The reported FN improvements (up to 94%) and robustness gains (up to 41%) are presented without details on the number of ADD/TTS models evaluated, number of independent runs, statistical significance tests, or confirmation that the diversity metric was not tuned post-hoc on the test set.
Authors: We will expand §4 to report the precise number of ADD and TTS models, the number of independent runs, the results of statistical significance tests, and an explicit statement that the diversity metric was fixed in advance and not tuned on the test set. revision: yes
-
Referee: [§4.3] §4.3 (Transferability): The transferability results across target ADDs are load-bearing for the broad-applicability claim, yet no controls are described for whether the generated samples were optimized against one model and then evaluated on others or whether the diversity context was held fixed.
Authors: The diversity context was held fixed across all evaluations and samples were generated without model-specific optimization beyond black-box access. We will add a clear description of these controls in the revised §4.3. revision: yes
Circularity Check
No circularity: empirical gains measured on held-out models
full rationale
The paper presents a black-box method that uses LLM in-context learning plus a diversity prompt to generate TTS inputs, then reports measured false-negative improvements (up to 94 %) and transfer/fine-tuning gains on separate ADD and TTS models. These performance numbers are external to any internal parameters or definitions inside FoeGlass; no equations, fitted quantities renamed as predictions, or self-citation chains appear in the derivation. The central claim therefore remains independent of its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jailbreaking Black Box Large Language Models in Twenty Queries
URL https://huggingface.co/ datasets/MattyB95/VoxCelebSpoof. Ac- cessed: 2025-02-15. Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-V oss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Li, X., Chen, P.-Y ., and Wei, W
URL https://openreview.net/forum? id=H2ATO32ilj. Li, X., Chen, P.-Y ., and Wei, W. Measuring the robustness of audio deepfake detectors, 2025. URL https:// arxiv.org/abs/2503.17577. Lin, W.-A., Lau, C. P., Levine, A., Chellappa, R., and Feizi, S. Dual manifold adversarial robustness: Defense against lp and non-lp adversarial attacks.Advances in Neural Inf...
-
[3]
Qin, Y ., Qian, C., Yi, J., Chen, W., Lin, Y ., Han, X., Liu, Z., Sun, M., and Zhou, J
Version 0.0.4, MIT License. mrfakename, Srivastav, V ., Fourrier, C., Pouget, L., La- combe, Y ., main, and Gandhi, S. Text to speech arena. https://huggingface.co/spaces/ TTS-AGI/TTS-Arena, 2024. Perez, E., Huang, S., Song, F., Cai, T., Ring, R., Aslanides, J., Glaese, A., McAleese, N., and Irving, G. Red teaming language models with language models. In ...
-
[4]
URL https://aclanthology.org/2022. emnlp-main.225/. Pontorno, O., Guarnera, L., and Battiato, S. Deepfeaturex net: Deep features extractors based network for discrimi- nating synthetic from real images. InInternational Con- ference on Pattern Recognition. Springer, 2024. Qiu, H., Xiao, C., Yang, L., Yan, X., Lee, H., and Li, B. Se- manticadv: Generating a...
-
[5]
Implementation Details in § A
-
[6]
Effectiveness of Diversity Feedback and Chain-of-thought context in § B
-
[7]
Experiments on additional ADD models in § C
-
[8]
Potential Defense Mechanisms Against FoeGlass in § D
-
[9]
Related Work on LLM Red Teaming in § E
-
[10]
More Results on FoeGlass Attacks Transferability in § F
-
[11]
Distribution of Generated Attack Scores in § G
-
[12]
Some Successful Attacks Transcripts in § H
-
[13]
One Full Prompt Example in § I A. Implementation Details In this section, we provide implementation details, including the instruction prompts given to the LLM in both the FoeGlass and unconditional sampling settings, as well as the computational resources used in the experiments presented in this paper. A.1. Instruction Prompts You are a useful red-teami...
-
[15]
Success" (if the audio deceives the classifier) or
**Constraints**: - Maximum 5 sentences per transcript - Use natural English with prompting techniques - Put the transcript text within the "text:" field Example Output: text: Hmm... *actually*, let’s reconsider the approach to this problem. I think we need a different strategy. After generation, your output will be evaluated. The feedback will either be "...
-
[16]
**Output Format **: text: [Your generated text here]
-
[17]
It’s time to take the next step and start planning
**Guidelines**: - Keep your response to a maximum of 5 sentences - Write in natural English - Begin your response with "text:" followed by your generated content Example Output: text: I’ve been thinking about this project for a while now. It’s time to take the next step and start planning. Generate only the text as specified above. No explanations or addi...
-
[18]
**Output Format **: text: [Natural English with prompting techniques limited to 5 sentences maximum]
-
[19]
Success
**Constraints**: - Maximum 5 sentences per transcript - Use natural English with prompting techniques - Put the transcript text within the "text:" field Example Output: text: Hmm... *actually*, let’s reconsider the approach to this problem. I think we need a different strategy. Two Success examples: text: Planning a movie night sounds great. Do you think ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.