Knowledge Index of Noah's Ark
Pith reviewed 2026-06-28 06:31 UTC · model grok-4.3
The pith
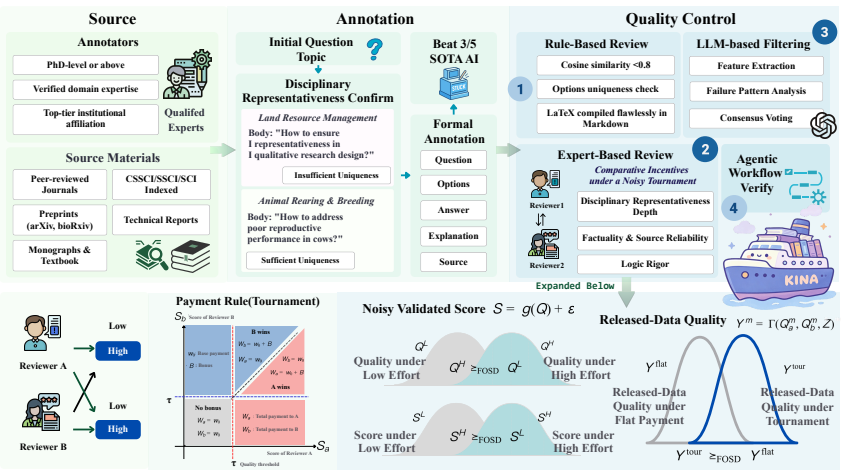
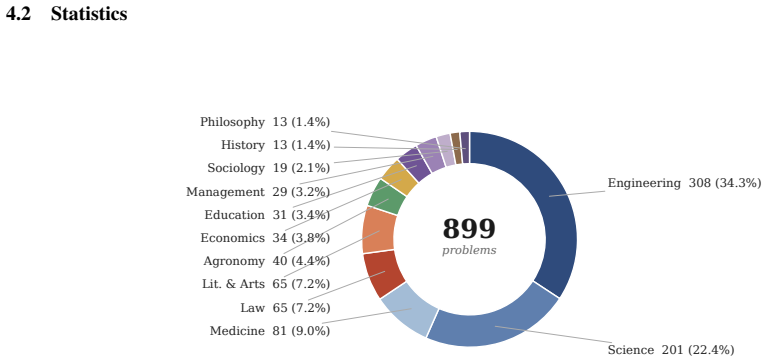
KINA is an 899-item benchmark across 261 disciplines with a proxy greedy algorithm for representativeness and a bonus tournament for annotation incentives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
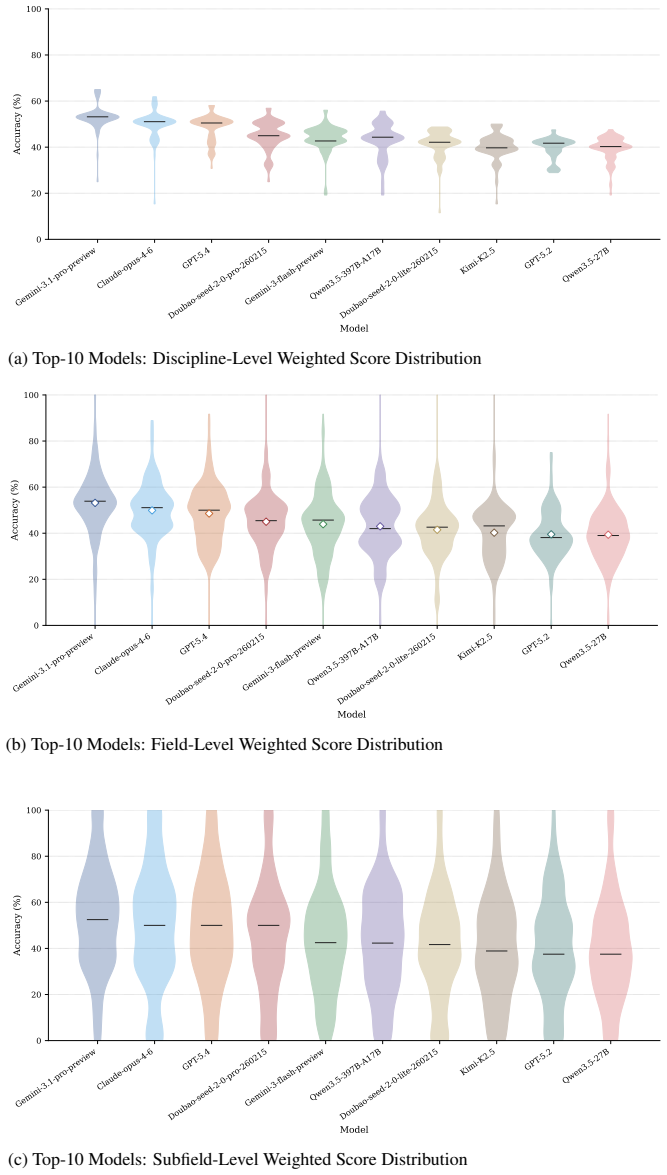
KINA operationalizes disciplinary representativeness via a proxy over expert-elicited anchors, yielding a (1-1/e) greedy approximation guarantee that applies to the proxy. It further proves that a bonus-on-bar tournament weakly first-order stochastically dominates flat payment for released-review quality whenever the bonus B exceeds Delta C / Delta p_min. The resulting 899-item set across 261 disciplines produces a tiered leaderboard in which the top model scores 53.17 percent, tool use adds up to 5.17 points, and bounded-budget variance is reported explicitly.
What carries the argument
The proxy-based greedy coverage algorithm for disciplinary representativeness together with the bonus-on-bar tournament payment rule.
If this is right
- Representativeness holds only relative to the proxy, not necessarily the true population.
- The tournament payment is incentive-compatible above the stated threshold.
- Model performance forms distinct tiers above 48 percent, 38-45 percent, and near the 10 percent baseline.
- Tool augmentation yields gains that vary substantially across models and tasks.
- Bootstrap statistics make explicit the ranking instability possible under limited evaluation budgets.
Where Pith is reading between the lines
- The same proxy-plus-greedy approach could be reused to build coverage benchmarks in domains other than LLM knowledge testing.
- The incentive-compatibility threshold provides a concrete design rule that might transfer to other crowdsourced annotation settings.
- Persistent gaps below 55 percent indicate that current architectures still lack reliable integration of knowledge across many disciplines.
- Future experiments could measure whether models trained or fine-tuned explicitly on the proxy-selected items close the observed performance tiers.
Load-bearing premise
The chosen proxy for disciplinary representativeness is treated as adequate for the coverage guarantee.
What would settle it
An audit that compares actual knowledge coverage achieved by the selected 899 items against a larger expert-curated or random sample to test whether the proxy guarantee translates to population representativeness.
Figures


read the original abstract
Knowledge benchmarks for LLMs face three issues: scaling-driven designs that do not operationalize disciplinary representativeness; flat-payment annotation that permits lazy consensus; and unaudited ranking instability under bounded test budgets. We introduce KINA, an 899-item benchmark across 261 fine-grained disciplines, with two formal results. First, we cast representativeness as a coverage-style objective over expert-elicited anchors and operationalize disciplinary representativeness through a proxy, yielding a (1-1/e) greedy approximation (Proposition 1); the guarantee applies to the proxy, not to population representativeness. Second, we prove a bonus-on-bar tournament weakly FOSD-dominates flat payment in released-review quality, with incentive-compatibility threshold B > Delta C / Delta p_min (Theorem 1). Evaluating 42 models from 13 labs, the top model, Gemini-3.1-Pro-Preview, reaches 53.17%, followed by Claude-Opus-4.6 at 49.92% and GPT-5.4 at 48.55%, leaving substantial headroom below saturation. The full leaderboard shows a tiered structure rather than a smooth total order: a small frontier tier lies above 48%, a dense strong-model tier spans roughly 38-45%, and low-performing models remain only modestly above the 10% chance baseline. Tool augmentation adds up to 5.17 points across the five tool-use evaluations, with gains varying substantially across models. We report bootstrap ranking-stability statistics to make bounded-budget variance explicit and to discourage over-interpretation of adjacent ranks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KINA, an 899-item benchmark across 261 fine-grained disciplines for LLMs. It presents two formal results: a (1-1/e) greedy approximation for representativeness via a proxy (Proposition 1), with the guarantee applying only to the proxy, and a proof that a bonus-on-bar tournament weakly FOSD-dominates flat payment above threshold B > Delta C / Delta p_min (Theorem 1). Evaluation of 42 models from 13 labs shows Gemini-3.1-Pro-Preview at 53.17%, followed by Claude-Opus-4.6 at 49.92% and GPT-5.4 at 48.55%, with a tiered leaderboard, tool augmentation gains up to 5.17 points, and bootstrap ranking-stability statistics.
Significance. If the proxy adequately captures disciplinary coverage and the formal results hold with supporting protocols, KINA could advance benchmark design by operationalizing coverage via approximation and improving annotation incentives over flat payment. The explicit proxy limitation, tiered performance structure, and stability reporting are useful contributions. The absence of population-level validation for the proxy and missing error bars/proofs limit the strength of the representativeness and evaluation claims.
major comments (3)
- [Abstract] Abstract: The central claim presents KINA as providing disciplinary representativeness across 261 disciplines, yet Proposition 1's (1-1/e) greedy guarantee applies exclusively to the expert-elicited proxy anchors and not to true population representativeness. No validation study, correlation analysis, or sensitivity check linking the proxy to actual disciplinary coverage is described, which is load-bearing for the representativeness claim.
- [Abstract] Abstract / Evaluation section: Model scores (e.g., 53.17% top result) and the tiered leaderboard structure are reported without error bars, exclusion criteria, or the detailed item-selection/annotation protocol, preventing assessment of robustness and making the cross-model comparisons difficult to interpret.
- [Theorem 1] Theorem 1: The weak FOSD dominance result with incentive threshold B > Delta C / Delta p_min is stated as a formal guarantee, but the abstract provides neither the proof nor the full set of assumptions and definitions, leaving the derivation unverified in the provided text.
minor comments (1)
- [Abstract] Abstract: The number of disciplines (261) and items (899) are stated without reference to how the expert-elicited anchors were constructed or any inter-annotator agreement metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, clarifying the explicit scope of our claims as stated in the manuscript while noting where additional reporting can be strengthened.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim presents KINA as providing disciplinary representativeness across 261 disciplines, yet Proposition 1's (1-1/e) greedy guarantee applies exclusively to the expert-elicited proxy anchors and not to true population representativeness. No validation study, correlation analysis, or sensitivity check linking the proxy to actual disciplinary coverage is described, which is load-bearing for the representativeness claim.
Authors: The manuscript already states explicitly in the abstract that 'the guarantee applies to the proxy, not to population representativeness.' We agree that the absence of a population-level validation study, correlation analysis, or sensitivity check is a genuine limitation for claims about true disciplinary coverage. Such a study would require large-scale sampling of the full disciplinary population and is outside the current scope. We will add a dedicated limitations paragraph in the revised manuscript to emphasize this point and outline directions for future validation. revision: partial
-
Referee: [Abstract] Abstract / Evaluation section: Model scores (e.g., 53.17% top result) and the tiered leaderboard structure are reported without error bars, exclusion criteria, or the detailed item-selection/annotation protocol, preventing assessment of robustness and making the cross-model comparisons difficult to interpret.
Authors: The manuscript already reports bootstrap ranking-stability statistics to make bounded-budget variance explicit. We acknowledge that the abstract and high-level evaluation summary do not include per-score error bars, explicit exclusion criteria, or a full recap of the item-selection/annotation protocol. The full methods section details the annotation process and model inclusion criteria. We will add error bars to the reported scores, reference the protocols more explicitly in the abstract, and ensure the evaluation section highlights these elements for robustness assessment. revision: yes
-
Referee: [Theorem 1] Theorem 1: The weak FOSD dominance result with incentive threshold B > Delta C / Delta p_min is stated as a formal guarantee, but the abstract provides neither the proof nor the full set of assumptions and definitions, leaving the derivation unverified in the provided text.
Authors: Abstracts are intended to summarize results rather than reproduce full proofs or definitions. The complete statement of Theorem 1, including all assumptions, definitions, and the proof of weak FOSD dominance, appears in the main text. We will revise the abstract to explicitly direct readers to the full formal treatment in the body of the paper. revision: partial
- Absence of a population-level validation study, correlation analysis, or sensitivity check linking the expert-elicited proxy to actual disciplinary coverage
Circularity Check
No significant circularity; formal results independent of benchmark data
full rationale
Proposition 1 applies the known (1-1/e) greedy guarantee to a coverage objective over the paper's own expert-elicited proxy anchors, with the abstract explicitly limiting the claim to the proxy. Theorem 1 is a standalone incentive-compatibility proof for the bonus-on-bar mechanism. Neither result is obtained by fitting parameters to the 899-item scores, nor does any load-bearing step reduce to self-citation or by-construction renaming. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- B incentive threshold
axioms (2)
- standard math Standard submodular coverage properties for greedy (1-1/e) approximation
- standard math Mechanism-design assumptions for first-order stochastic dominance of tournament payments
Reference graph
Works this paper leans on
-
[1]
Introducing Claude Opus 4.6, February 2026
Anthropic. Introducing Claude Opus 4.6, February 2026. URL https://www.anthropic.com/news/ claude-opus-4-6
2026
-
[2]
Introducing Claude Sonnet 4.6, February 2026
Anthropic. Introducing Claude Sonnet 4.6, February 2026. URL https://www.anthropic.com/news/ claude-sonnet-4-6
2026
-
[3]
The Llama 4 herd: Architecture, training, evaluation, and deployment notes, 2026
Redacted by arXiv. The Llama 4 herd: Architecture, training, evaluation, and deployment notes, 2026. URL https://arxiv.org/abs/2601.11659
-
[4]
Arc prize 2024: Technical report, 2025
Francois Chollet, Mike Knoop, Gregory Kamradt, et al. Arc prize 2024: Technical report, 2025. URL https://arxiv.org/abs/2412.04604
-
[5]
ARC-AGI-2: A New Challenge for Frontier AI Reasoning Systems
Francois Chollet, Mike Knoop, Gregory Kamradt, et al. ARC-AGI-2: A new challenge for frontier AI reasoning systems, 2026. URLhttps://arxiv.org/abs/2505.11831
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Gemini, February 2026
Google DeepMind. Gemini, February 2026. URLhttps://deepmind.google/models/gemini/
2026
-
[7]
SuperGPQA: Scaling LLM evaluation across 285 graduate disciplines,
Xeron Du, Yifan Yao, Kaijing Ma, et al. SuperGPQA: Scaling LLM evaluation across 285 graduate disciplines,
-
[8]
URLhttps://arxiv.org/abs/2502.14739
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, et al. Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
2021
-
[10]
Aryo Pradipta Gema, Joshua Ong Jun Leang, Giwon Hong, et al. Are we done with mmlu?, 2025. URL https://arxiv.org/abs/2406.04127
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The Llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, et al. Measuring massive multitask language understanding, 2021. URLhttps://arxiv.org/abs/2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Step 3.5 Flash: Open frontier-level intelligence with 11b active parameters, 2026
Ailin Huang, Ang Li, Aobo Kong, et al. Step 3.5 Flash: Open frontier-level intelligence with 11b active parameters, 2026. URLhttps://arxiv.org/abs/2602.10604. 11
-
[14]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, et al. Mixtral of experts, 2024. URL https://arxiv. org/abs/2401.04088
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Rank-order tournaments as optimum labor contracts.Journal of Political Economy, 89(5):841–864, 1981
Edward P Lazear and Sherwin Rosen. Rank-order tournaments as optimum labor contracts.Journal of Political Economy, 89(5):841–864, 1981
1981
-
[16]
DeepSeek-V3.2: Pushing the frontier of open large language models,
Aixin Liu, Aoxue Mei, Bangcai Lin, et al. DeepSeek-V3.2: Pushing the frontier of open large language models,
-
[17]
URLhttps://arxiv.org/abs/2512.02556
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tanglin Xia, et al. Learn to explain: Multimodal reasoning via thought chains for science question answering. InThe 36th Conference on Neural Information Processing Systems (NeurIPS), 2022
2022
-
[19]
MiniMax M2.5: Built for real-world productivity, February 2026
MiniMax. MiniMax M2.5: Built for real-world productivity, February 2026. URL https://www.minimax. io/news/minimax-m25
2026
-
[20]
An analysis of approximations for maximizing submodular set functions—i.Mathematical Programming, 14(1):265–294, 1978
George L Nemhauser, Laurence A Wolsey, and Marshall L Fisher. An analysis of approximations for maximizing submodular set functions—i.Mathematical Programming, 14(1):265–294, 1978
1978
-
[21]
Adversarial nli: A new benchmark for natural language understanding
Yixin Nie, Adina Williams, Emily Dinan, et al. Adversarial nli: A new benchmark for natural language understanding. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4885–4901, 2020
2020
-
[22]
Introducing GPT-5.2, December 2025
OpenAI. Introducing GPT-5.2, December 2025. URL https://openai.com/index/ introducing-gpt-5-2/
2025
-
[23]
Introducing GPT-5.4, March 2026
OpenAI. Introducing GPT-5.4, March 2026. URL https://openai.com/index/ introducing-gpt-5-4/
2026
-
[24]
A benchmark of expert-level academic questions to assess AI capabilities.Nature, 649(8099):1139–1146, 2026
Long Phan, Alice Gatti, Nathaniel Li, et al. A benchmark of expert-level academic questions to assess AI capabilities.Nature, 649(8099):1139–1146, 2026
2026
-
[25]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Stickland, et al. Gpqa: A graduate-level google-proof q&a benchmark, 2023. URL https://arxiv.org/abs/2311.12022
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Seed 2.0 official launch, February 2026
Bytedance Seed. Seed 2.0 official launch, February 2026. URL https://seed.bytedance.com/en/ blog/seed-2-0-official-launch
2026
-
[27]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team, Tongtong Bai, Yifan Bai, et al. Kimi k2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Qwen3-Max: Just scale it, September 2025
Qwen Team. Qwen3-Max: Just scale it, September 2025
2025
-
[29]
Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026. URL https://qwen.ai/blog?id=qwen3.5
2026
-
[30]
Qwen Team, An Yang, Baosong Yang, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Position: The Hidden Costs and Measurement Gaps of Reinforcement Learning with Verifiable Rewards
Aaron Tu, Weihao Xuan, Heli Qi, et al. Position: The hidden costs and measurement gaps of reinforcement learning with verifiable rewards, 2025. URLhttps://arxiv.org/abs/2509.21882
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Superglue: A stickier benchmark for general-purpose language understanding systems.Advances in neural information processing systems, 32, 2019
Alex Wang, Yada Pruksachatkun, Nikita Nangia, et al. Superglue: A stickier benchmark for general-purpose language understanding systems.Advances in neural information processing systems, 32, 2019
2019
-
[33]
MMLU-Pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
Yubo Wang, Xueguang Ma, Ge Zhang, et al. MMLU-Pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
2024
-
[34]
Grok-4-1 model card, November 2025
xAI Team. Grok-4-1 model card, November 2025. URL https://data.x.ai/ 2025-11-17-grok-4-1-model-card.pdf
2025
-
[35]
An Yang, Baosong Yang, Binyuan Hui, et al. Qwen2 technical report, 2024. URL https://arxiv.org/ abs/2407.10671
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
An Yang, Anfeng Li, Baosong Yang, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, et al. Glm-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Hle-verified: A systematic verification and structured revision of humanity’s last exam, 2026
Weiqi Zhai, Zhihai Wang, Jinghang Wang, et al. Hle-verified: A systematic verification and structured revision of humanity’s last exam, 2026. URLhttps://arxiv.org/abs/2602.13964. 12 A Data Samples Pseudo-Multi-Choice Sample (Some Content Omitted ) Discipline: Engineering Question: Which of the following options are correct?
-
[39]
By defining N=D ⊤M −1D, it follows that N∈R 3Nc×3Nc
D∈R 6M×3N c and M is a diagonal matrix. By defining N=D ⊤M −1D, it follows that N∈R 3Nc×3Nc. The Schur complement is given by S=N+ ˆM−BE −1C. Since ˆM is diagonal and BE −1C is a block- diagonal matrix with3×3blocks,Spossesses the identical sparsity pattern asN
-
[40]
In the contact pairs of granular dynamics, the friction cone constraint requires that the magnitude of the tangential force impulse vector does not exceed the product of the static friction coefficient and the normal force impulse. When the static friction coefficient is 0.3 and the normal force impulse is 10 N·s, the maximum possible magnitude of the tan...
-
[41]
sublinear inN
The AMEN Cross complexity bound in this setting scales as O(r3N) (linear in the number of unknowns N). For N= 10 6 and maximum TT-rank r= 10 , the computational cost is approximately 109 operations; however, this contradicts the claim of "sublinear inN" (a linear scaling inNcannot be sublinear)
-
[42]
Given ∆t= 0.1s , M= 2I,v k = 3m/s,∆tf B = 4N s, and P Diγi = 6N s, we calculatev k+1 as follows: vk+1 =v k + 1 M ∆t fB + X Diγi = 3 + 1 2 (4 + 6) = 8m/s
Using the time-stepping update formula: M vk+1 −v k = ∆t fB +P i∈A(qk,δ) Diγi. Given ∆t= 0.1s , M= 2I,v k = 3m/s,∆tf B = 4N s, and P Diγi = 6N s, we calculatev k+1 as follows: vk+1 =v k + 1 M ∆t fB + X Diγi = 3 + 1 2 (4 + 6) = 8m/s
-
[43]
With N=D ⊤M −1D, for M= 2 rigid bodies (yielding 6M= 12 degrees of freedom, DOF) and Nc = 1 contact (yielding 3Nc = 3 multipliers), N is a 3×3 matrix, as it is defined by the product D⊤M −1D where D∈R 12×3,M −1 ∈R 12×12, and thus acts on the contact multiplier space (not generalized-velocity space)
-
[44]
For the position-based normal complementarity constraint: γi,n ≥0,Φ i(q)≥0,Φ i(q)γi,n = 0 . If Φi(q) = 0.5m and γi,n = 2N s , the constraint isnotsatisfied: while both quantities are nonnegative, their product is1m N s̸= 0, violating the complementarity condition (Φ i(q)γi,n = 0)
-
[45]
For TT matrix-vector products used in the paper’s TT-based preconditioner, the complexity isO(r2NlogN) . While this complexity scales linearly in N (up to a logarithmic factor logN ), the cost is still considered *asymp- totically sublinear in N* when normalized by N—or more precisely, *sublinear in the sense of superlinear scaling avoidance*—because logN...
-
[46]
If a discipline were to be evaluated using only 3 to 5 questions, the submitted instance must be fundamental and comprehensive enough to be one of them
Disciplinary Representativeness:Instances must act as highly representative probes. If a discipline were to be evaluated using only 3 to 5 questions, the submitted instance must be fundamental and comprehensive enough to be one of them. 2.High-Order Knowledge Application: 29 • Questions must construct a logically complete closed system where the solution ...
-
[47]
What We Reject:
Static Knowledge Breadth:For memory-intensive disciplines (e.g., Education), questions should maximize knowledge coverage (e.g., utilizing10+statements to encompass major pedagogical theories). What We Reject:
-
[48]
What is the 100th digit ofπ?
Narrow or Trivial Memorization:Questions testing pure rote memory devoid of core disciplinary literacy (e.g., "What is the 100th digit ofπ?") or focusing on hyper-niche, obscure sub-entities
-
[49]
Idiosyncratic or Tricky Trivia:Questions universally recognized as flawed or unreasonable even in human examinations
-
[50]
Weak Epistemological Consensus:Hypotheses proposed by individual scholars that lack widespread aca- demic consensus or are highly volatile (e.g., highly debated legal interpretations)
-
[51]
E.2.3 Standardized Annotation Workflow The question authoring process is strictly compartmentalized into six components
Non-Disciplinary Failure Modes:Instances where LLMs fail due to semantic traps, ambiguous phrasing, or floating-point calculation errors rather than a deficit in disciplinary literacy. E.2.3 Standardized Annotation Workflow The question authoring process is strictly compartmentalized into six components. The specifications for each component are detailed ...
-
[52]
It targets marine chemistry and assesses advanced reasoning and computational abilities, rather than only testing static knowledge
-
[53]
You are an expert
Even though it is a calculation question, the analysis of incorrect options is briefly summarized instead of being copied and pasted repetitively. E.3 Review Manual E.3.1 Core Philosophy and General Workflow The primary objective of the review process is to ensure that each curated instance serves as a highly representative probe for evaluating LLMs on sp...
2017
-
[54]
Body elongated, slightly compressed, large head, flat snout
-
[55]
Lateral line scales are at least weakly ctenoid, two dorsal fins, separated
-
[56]
Posterior margin of the caudal fin is rounded
-
[57]
The first dorsal fin is short, consisting of 3-4 spines
-
[58]
Upper jaw is slightly shorter than the lower jaw. Options A.1, 2B.1, 2, 3 (Correct Option)C.1, 2, 3, 4, 5D.1E.2F.1, 2, 4G.1, 3, 5H.3, 5J.4, 5 Explanation Option A:Statement 1 is correct (Body elongated, slightly compressed, large head, flat snout); Statement 2 is correct (Lateral line scales are at least weakly ctenoid, two dorsal fins, separated). Option...
-
[59]
Statements 4 and 5 merely test pure static memory of isolated trivia, lacking sufficient cognitive coverage to serve as a representative evaluation probe
Weak Disciplinary Representativeness:The question fails to engage high-order disciplinary literacy. Statements 4 and 5 merely test pure static memory of isolated trivia, lacking sufficient cognitive coverage to serve as a representative evaluation probe
-
[60]
Models can exploit this logical leakage (selecting A, D, or E would technically be correct)
Structural Flaw (Proper Subsets):Options A, D, and E are proper subsets of the correct Option B. Models can exploit this logical leakage (selecting A, D, or E would technically be correct). Furthermore, the option distribution is severely imbalanced, violating statistical normality constraints
-
[61]
Statement Count Deficit:The question stem only contains 5 statements, failing the strict pseudo-multi-choice minimum requirement (≥6statements)
-
[62]
Chapter 1
Context Drift:The stem explicitly references an unprovided context ("Chapter 1"), violating the requirement that all questions must be logically self-contained. 32 E.3.4 Option Rigor and Structural Integrity To prevent LLMs from exploiting logical loopholes, the 10-option structure must adhere to strict constraints: • Pseudo-Multi-Choice Constraints:For c...
-
[63]
**NO OVERLAP**: Two selected questions must NOT test the same knowledge point
-
[64]
**DISCRIMINATIVE PRIORITY**: Always prefer HIGH discriminative_power questions over LOW
-
[65]
**TYPE PREFERENCE**: CASE_BASED > APPLIED_REASONING > CONCEPTUAL > FACTUAL_RECALL
-
[66]
**TOPIC DIVERSITY**: Ensure selected questions span different key_topics
-
[67]
selected_questions
**ERROR PATTERN V ALUE**: Questions with clear, consistent error patterns are valuable for understanding model weaknesses # Output Return ONLY a JSON object: 36 ‘‘‘json { "selected_questions": [ { "question_number": <int>, "knowledge_point": "<the knowledge point being tested>", "selection_reason": "<why this question was selected, referencing criteria>" ...
-
[68]
**Original Question Data**: {{ORIGINAL_JSON}}
-
[69]
Source Confidence
**Audit Report**: {{AUDIT_JSON_FROM_AGENT_A}} # Refinement Strategy Matrix Apply the following strategies based on the ‘issue_type‘ identified: ## Strategy A: Fix "Source Confidence" (Premise Injection) * **Action:** Add specific boundary conditions to the Question Stem. * **Example:** Change "Does X cause Y?" to "In the context of [Specific Cell Line/Con...
-
[70]
Assuming no [Confounding Factor B]
Exclusion: Add "Assuming no [Confounding Factor B]..." * **Goal:** Eliminate the validity of the competing distractor found by the auditor. ## Strategy C: Fix "Ambiguity" (Disambiguation) 38 * **Action:** Rewrite the confusing phrase using standard academic terminology. Ensure the syntax (e.g., modifier attachment) is singular in meaning. ## Strategy D: F...
-
[71]
**Explanation Sync:** If you modify ANY Option or the Correct Answer, you **MUST** rewrite the corresponding ‘explanation‘ to align with the new logic
-
[72]
Is Theory X correct?
**Source Addition:** If your modification introduces new facts or constraints not supported by the original source, you **MUST** provide a ‘new_source‘ (APA format or accessible URL). * **Example:** * *Before:* "Is Theory X correct?" (Hard to prove) * *After:* "**Assuming Theory X is correct**, which of the following observations would be expected?" OR "*...
-
[73]
**Do NOT make the question easier.** The goal is rigor, not simplification
-
[74]
**Maintain the Markdown/LaTeX format.**
-
[75]
Assuming setting X
**Evidence update:** If you add a new premise based on the audit, ensure the ‘question_content‘ reflects this (you may add a note "Assuming setting X"). # Output Return a JSON object containing ONLY the fields that require modification. Do not return unchanged fields (e.g., if the answer is unchanged, do not include it). Example: { "revision_summary": "Ap...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.