SWE-InfraBench: Evaluating Language Models on Cloud Infrastructure Code
Pith reviewed 2026-06-28 05:19 UTC · model grok-4.3
The pith
Even top language models succeed on only a third of realistic cloud infrastructure code tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
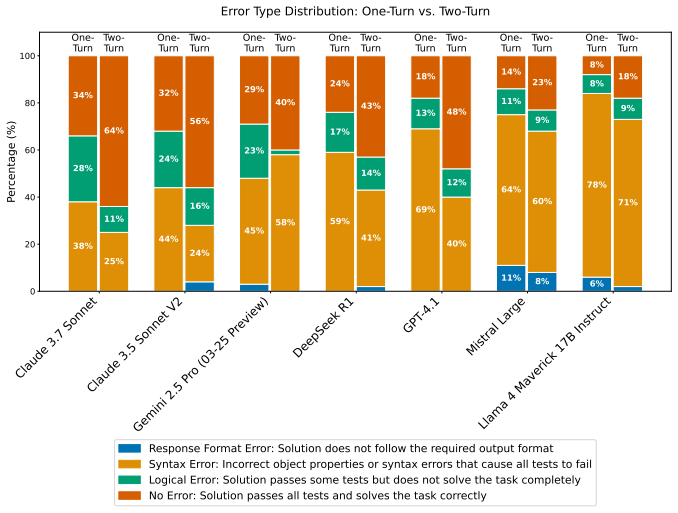
SWE-InfraBench is a dataset of tasks taken from dozens of real-world AWS CDK repositories. In each task a model receives an existing codebase and a natural language request for a change, then must produce edits that pass the accompanying test cases. The evaluation shows that even the best current models succeed on no more than 34 percent of the tasks.
What carries the argument
SWE-InfraBench, a benchmark of incremental code-edit tasks in AWS CDK repositories that requires reasoning about cloud resource dependencies.
If this is right
- Models will need stronger reasoning about resource dependencies before they can be trusted for routine IaC maintenance.
- Human oversight will remain necessary for most enterprise infrastructure changes under current model capabilities.
- Specialized reasoning models do not outperform general models on imperative IaC edit tasks.
- Benchmarks focused on full codebase generation miss the incremental-edit challenges that dominate real development.
Where Pith is reading between the lines
- Teams could run the benchmark to locate precise failure modes and then fine-tune models on similar dependency patterns.
- Extending the same task format to other cloud providers would test whether the observed limits are AWS-specific.
- Persistent low success rates indicate that automated IaC generation carries deployment risks until model performance improves.
Load-bearing premise
The test cases supplied with each example accurately capture the reasoning required for real enterprise IaC maintenance and that passing them demonstrates genuine capability with cloud resource dependencies rather than test-specific patterns.
What would settle it
A direct comparison showing whether models that pass many SWE-InfraBench tasks also succeed at making safe, dependency-correct changes to live production AWS CDK codebases.
Figures

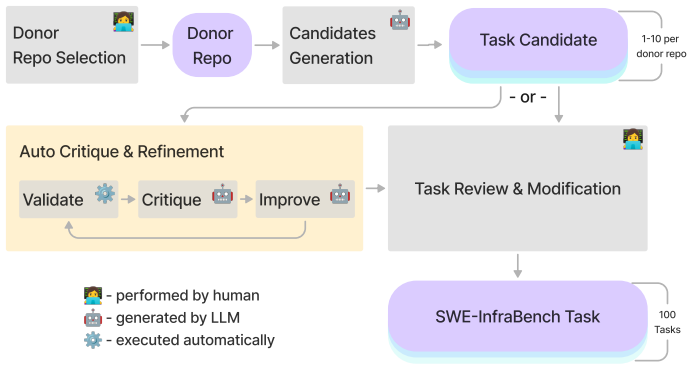
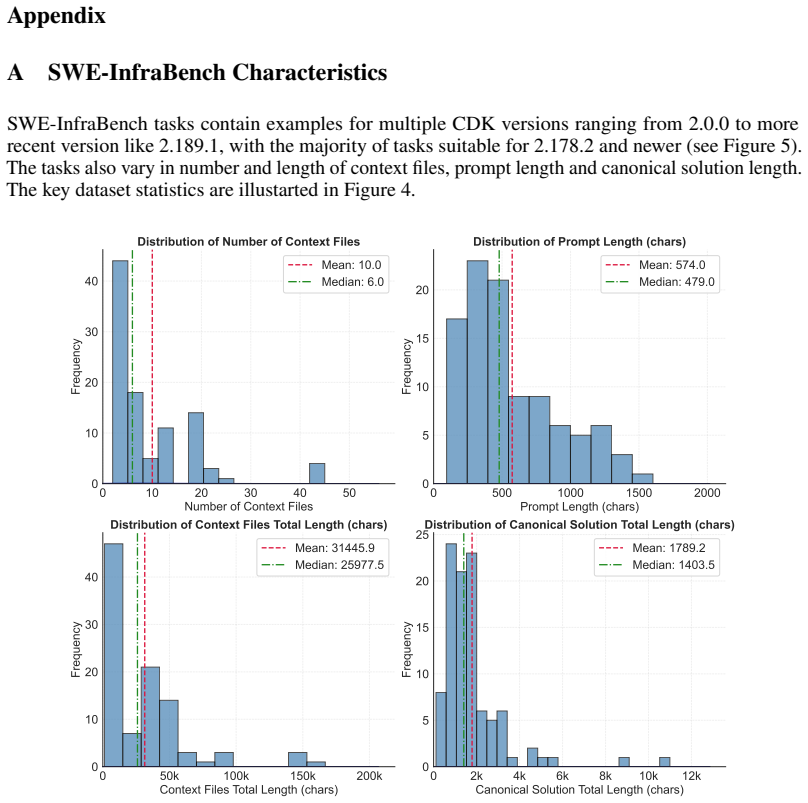
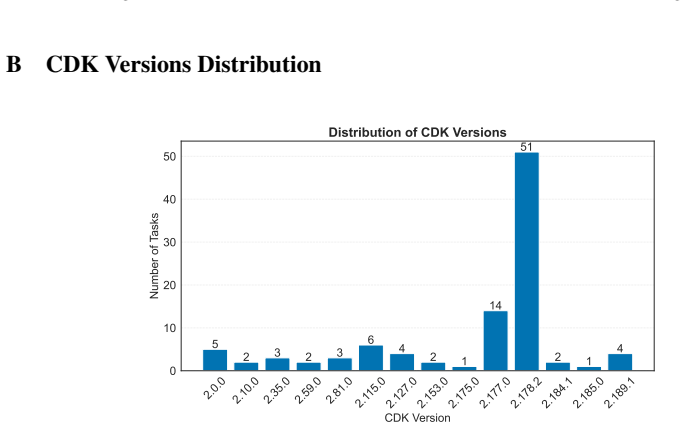

read the original abstract
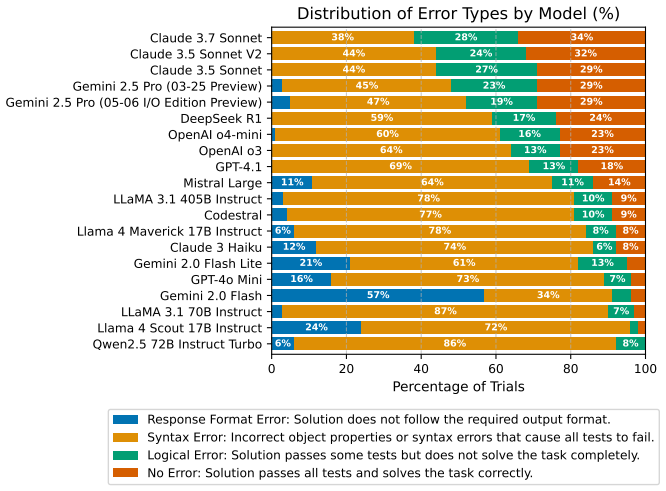
Building infrastructure-as-code (IaC) in cloud computing is a critical task, underpinning the reliability, scalability, and security of modern software systems. Despite the remarkable progress of large language models (LLMs) in software engineering -- demonstrated across many dedicated benchmarks -- their capabilities in developing IaC remain underexplored. Unlike existing IaC benchmarks that predominantly center on declarative paradigms such as Terraform and involve generating entire codebases from scratch, our benchmark reflects the incremental code edits common in enterprise development with imperative tools like the AWS CDK. We present SWE-InfraBench, a diverse evaluation dataset sourced from dozens of real-world IaC codebases that challenge LLMs to perform realistic code modifications in AWS CDK repositories. Each example requires models to implement changes to existing codebases based on natural language instructions, with success determined by passing provided test cases. These tasks demand sophisticated reasoning about cloud resource dependencies and implementation patterns beyond conventional code generation challenges. Our evaluation results reveal significant limitations in current LLMs showing that even state-of-the-art systems struggle with many tasks -- the best model, Sonnet 3.7, succeeds in only 34\% of cases, while specialized reasoning models like DeepSeek R1 achieve just 24% success. The SWE-InfraBench dataset is available at: https://www.kaggle.com/datasets/64e59070fd51c0278560b01eb5dc4f3c447d5268cdabe5a350d2969e4413fea5
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SWE-InfraBench, a benchmark dataset drawn from dozens of real-world AWS CDK codebases. It evaluates LLMs on incremental code edits driven by natural-language instructions, with success defined by passing supplied test cases. The central empirical claim is that even state-of-the-art models struggle: Sonnet 3.7 succeeds on only 34% of tasks and DeepSeek R1 on 24%, indicating limitations in reasoning about cloud resource dependencies.
Significance. If the supplied test cases genuinely require modeling of cross-resource dependencies rather than local syntactic patterns, the benchmark would supply useful evidence that current LLMs remain limited on realistic IaC maintenance tasks. The work is empirical rather than theoretical and supplies no machine-checked proofs or parameter-free derivations.
major comments (1)
- [Abstract] Abstract: the claim that the tasks 'demand sophisticated reasoning about cloud resource dependencies' is load-bearing for the headline performance numbers, yet the abstract (and, on the information provided, the manuscript) supplies no description of how the test cases were authored, whether they were manually validated for coverage of cross-resource interactions, inter-annotator agreement, or controls for data leakage. Without these details the 34% success rate cannot be interpreted as evidence of reasoning limitations rather than test-specific shortcuts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and will revise the manuscript to provide the requested details on test case construction.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the tasks 'demand sophisticated reasoning about cloud resource dependencies' is load-bearing for the headline performance numbers, yet the abstract (and, on the information provided, the manuscript) supplies no description of how the test cases were authored, whether they were manually validated for coverage of cross-resource interactions, inter-annotator agreement, or controls for data leakage. Without these details the 34% success rate cannot be interpreted as evidence of reasoning limitations rather than test-specific shortcuts.
Authors: We agree that the manuscript would be strengthened by explicit details on test case authorship, validation, inter-annotator agreement, and data leakage controls, as these are necessary to support the interpretation of results as evidence of reasoning limitations. The current version does not include a dedicated description of these aspects. In the revised manuscript we will add a subsection under Dataset Construction that describes: (1) the process by which natural-language instructions and test cases were derived from the real-world AWS CDK codebases, (2) the manual validation steps performed to confirm coverage of cross-resource dependencies, (3) any inter-annotator agreement procedures used during curation, and (4) the controls applied to reduce data leakage risk. This addition will allow readers to better evaluate whether the 34% success rate reflects limitations in modeling cloud resource dependencies. revision: yes
Circularity Check
No circularity: purely empirical benchmark with external test cases
full rationale
The paper consists of an empirical evaluation of LLMs on a new benchmark dataset drawn from real-world IaC codebases. Success is measured by passing supplied test cases; there are no equations, derivations, fitted parameters, predictions derived from fits, or load-bearing self-citations. The central claims (e.g., Sonnet 3.7 at 34% success) are direct empirical measurements against externally authored tests, with the dataset released publicly. No step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amazon Web Services: Increasing developer velocity using aws cloud development kit with godaddy (2025), https://aws.amazon.com/solutions/case-studies/godad dy-cdk-case-study/, accessed: 2025-05-05 Cited on p. 2
2025
-
[2]
Amazon Web Services: What is aws cloudformation? - aws cloudformation (2025), https: //docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/Welco me.html, accessed: 2025-05-05 Cited on p. 3
2025
-
[3]
Amazon Web Services: What is the aws cdk? - aws cloud development kit (aws cdk) v2 (2025), https://docs.aws.amazon.com/cdk/v2/guide/home.html , accessed: 2025-05-05 Cited on p. 2
2025
-
[4]
Anthropic: Claude 3.7 sonnet system card (February 2025), https://www.anthropi c.com/claude-3-7-sonnet-system-card , technical report detailing Claude 3.7 Sonnet, a hybrid reasoning model Cited on p. 6
2025
-
[5]
Multi-lingual evaluation of code generation models,
Athiwaratkun, B., Gouda, S.K., Wang, Z., Li, X., Tian, Y ., Tan, M., Ahmad, W.U., Wang, S., Sun, Q., Shang, M., et al.: Multi-lingual evaluation of code generation models. arXiv preprint arXiv:2210.14868 (2022) Cited on p. 3
-
[6]
Ava: Terraform vs AWS CloudFormation vs AWS CDK.https://kudulab.io/posts /2023-2-terraform-vs-cdk-vs-cloudformation/ (2023), accessed: 2025-05- 09 Cited on p. 1
2023
-
[7]
Buchh, I.: Two billion downloads of the terraform aws provider shows value of iac for in- frastructure management. https://aws.amazon.com/blogs/aws-insights/tw o-billion-downloads-of-the-terraform-aws-provider-shows-value -of-iac-for-infrastructure-management/ (2023), aWS Insights Blog, 11 Oct 2023 Cited on p. 1
2023
-
[8]
Canalys: Worldwide cloud infrastructure services expenditure increased 20% year on year in q4 2024 to us$86 billion (2025), https://www.canalys.com/newsroom/worldwide -cloud-service-q4-2024, accessed: 2025-05-05 Cited on p. 1
2024
-
[9]
arXiv preprint arXiv:2312.12450 (2023) Cited on p
Cassano, F., Li, L., Sethi, A., Shinn, N., Brennan-Jones, A., Ginesin, J., Berman, E., Chakhnashvili, G., Lozhkov, A., Anderson, C.J., et al.: Can it edit? evaluating the ability of large language models to follow code editing instructions. arXiv preprint arXiv:2312.12450 (2023) Cited on p. 3
-
[10]
al, J.K.: Evaluating large language models trained on code (2021) Cited on p
Chen, M., Tworek, J., Jun, H., Yuan, Q., de Oliveira Pinto, H.P., et. al, J.K.: Evaluating large language models trained on code (2021) Cited on p. 3, 6
2021
-
[11]
Chowdhury, N., Aung, J., Shern, C.J., Jaffe, O., Sherburn, D., Starace, G., Mays, E., Dias, R., Aljubeh, M., Glaese, M., Jimenez, C.E., Yang, J., Ho, L., Patwardhan, T., Liu, K., Madry, A.: Introducing swe-bench verified (2024), https://openai.com/index/introducing -swe-bench-verified/, accessed: 2025-03-02 Cited on p. 2
2024
-
[12]
Delta, E.: How many companies use cloud computing in 2024? [10 statistics] (2025), https: //edgedelta.com/company/blog/how-many-companies-use-cloud-com puting, accessed: 2025-05-05 Cited on p. 1
2024
-
[13]
Advances in Neural Information Processing Systems36, 46701–46723 (2023) Cited on p
Ding, Y ., Wang, Z., Ahmad, W., Ding, H., Tan, M., Jain, N., Ramanathan, M.K., Nallapati, R., Bhatia, P., Roth, D., et al.: Crosscodeeval: A diverse and multilingual benchmark for cross-file code completion. Advances in Neural Information Processing Systems36, 46701–46723 (2023) Cited on p. 3
2023
-
[14]
arXiv preprint arXiv:2402.07844 (2024) Cited on p
Du, M., Luu, A.T., Ji, B., Liu, Q., Ng, S.K.: Mercury: A code efficiency benchmark for code large language models. arXiv preprint arXiv:2402.07844 (2024) Cited on p. 3
-
[15]
arXiv preprint arXiv:2411.06145 (2024) Cited on p
Du, X., Liu, Y ., Wang, Y ., Zhang, W., Li, X.: Classeval-t: A class-level code translation benchmark. arXiv preprint arXiv:2411.06145 (2024) Cited on p. 2. 10
-
[16]
Understanding the Human-LLM Dynamic: A Literature Survey of LLM Use in Programming Tasks
Etsenake, D., Nagappan, M.: Understanding the human-llm dynamic: A literature survey of llm use in programming tasks. arXiv preprint arXiv:2410.01026 (2024) Cited on p. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
In: Anais do XXXVIII Simpósio Brasileiro de Engenharia de Software
Frois, J., Padrão, L., Oliveira, J., Xavier, L., Tavares, C.: Terraform and aws cdk: A comparative analysis of infrastructure management tools. In: Anais do XXXVIII Simpósio Brasileiro de Engenharia de Software. pp. 623–629. SBC, Porto Alegre, RS, Brasil (2024). https://doi.org/10.5753/sbes.2024.3577, https://sol.sbc.org.br/index.php/sbe s/article/view/30...
-
[18]
arXiv preprint arXiv:2404.03543 (2024) Cited on p
Guo, J., Li, Z., Liu, X., Ma, K., Zheng, T., Yu, Z., Pan, D., Li, Y ., Liu, R., Wang, Y ., et al.: Codeeditorbench: Evaluating code editing capability of large language models. arXiv preprint arXiv:2404.03543 (2024) Cited on p. 3
-
[19]
A Survey on Large Language Models for Code Generation
Jiang, J., Wang, F., Shen, J., Kim, S., Kim, S.: A survey on large language models for code generation. arXiv preprint arXiv:2406.00515 (2024) Cited on p. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Jimenez, C.E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., Narasimhan, K.: Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770 (2023) Cited on p. 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
IEICE Proceedings Series72(S5-8) (2022) Cited on p
Kawaguchi, M., Mizutani, K., Iguchi, N.: An implementation of misconfiguration prevention system using language model for a network automation tool. IEICE Proceedings Series72(S5-8) (2022) Cited on p. 3
2022
-
[22]
Advances in Neural Information Processing Systems37, 134488–134506 (2024) Cited on p
Kon, P.T., Liu, J., Qiu, Y ., Fan, W., He, T., Lin, L., Zhang, H., Park, O.M., Elengikal, G.S., Kang, Y ., et al.: Iac-eval: A code generation benchmark for cloud infrastructure-as-code programs. Advances in Neural Information Processing Systems37, 134488–134506 (2024) Cited on p. 2, 3
2024
-
[23]
Larssen, E.: It’s time to retire terraform.https://blog.realkinetic.com/its-tim e-to-retire-terraform-30545fd5f186 (2024), real Kinetic Blog, Apr 23, 2024 Cited on p. 1
2024
-
[24]
Advances in Neural Information Processing Systems37, 129120–129145 (2024) Cited on p
Liu, C., Wu, X., Feng, Y ., Cao, Q., Yan, J.: Towards general loop invariant generation: A benchmark of programs with memory manipulation. Advances in Neural Information Processing Systems37, 129120–129145 (2024) Cited on p. 3
2024
-
[25]
O’Reilly Media (2020) Cited on p
Morris, K.: Infrastructure as Code: Managing Servers in the Cloud (2nd Edition). O’Reilly Media (2020) Cited on p. 1
2020
-
[26]
Muennighoff, N., Liu, Q., Zebaze, A., Zheng, Q., Hui, B., Zhuo, T.Y ., Singh, S., Tang, X., von Werra, L., Longpre, S.: Octopack: Instruction tuning code large language models (2023) Cited on p. 3
2023
-
[27]
In: Proc
Pahl, C., Gunduz, N.G., Sezen, O.C., Ghamgosar, A., El Ioini, N.: Infrastructure as code: Technology review and research challenges. In: Proc. of the 15th Int. Conf. on Cloud Computing and Services Science (CLOSER) (2025) Cited on p. 1
2025
-
[28]
In: Proceedings of the IEEE/ACM 46th International Conference on Software Engineering
Pan, R., Ibrahimzada, A.R., Krishna, R., Sankar, D., Wassi, L.P., Merler, M., Sobolev, B., Pavuluri, R., Sinha, S., Jabbarvand, R.: Lost in translation: A study of bugs introduced by large language models while translating code. In: Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. pp. 1–13 (2024) Cited on p. 2
2024
-
[29]
https://aws.amazon.com/blogs/aws/aws-cloud-developme nt-kit-cdk-typescript-and-python-are-now-generally-available/ (2019), aWS News Blog, 11 Jul 2019 Cited on p
Poccia, D.: AWS Cloud Development Kit (CDK) – TypeScript and Python are Now Generally Available. https://aws.amazon.com/blogs/aws/aws-cloud-developme nt-kit-cdk-typescript-and-python-are-now-generally-available/ (2019), aWS News Blog, 11 Jul 2019 Cited on p. 2
2019
-
[30]
arXiv preprint arXiv:2502.01619 (2025) Cited on p
Prasad, A., Stengel-Eskin, E., Chen, J.C.Y ., Khan, Z., Bansal, M.: Learning to generate unit tests for automated debugging. arXiv preprint arXiv:2502.01619 (2025) Cited on p. 2
-
[31]
In: 2023 60th ACM/IEEE Design Automation Conference (DAC)
Pujar, S., Buratti, L., Guo, X., Dupuis, N., Lewis, B., Suneja, S., Sood, A., Nalawade, G., Jones, M., Morari, A., et al.: Automated code generation for information technology tasks in yaml through large language models. In: 2023 60th ACM/IEEE Design Automation Conference (DAC). pp. 1–4. IEEE (2023) Cited on p. 3. 11
2023
-
[32]
IEEE Software40(1), 37–40 (2023)
Quattrocchi, G., Tamburri, D.A.: Infrastructure as code. IEEE Software40(1), 37–40 (2023). https://doi.org/10.1109/MS.2022.3212034 Cited on p. 1
-
[33]
Proceedings of the ACM on Programming Languages 9(OOPSLA1), 143–168 (2025) Cited on p
Rahman, S., Kuhar, S., Cirisci, B., Garg, P., Wang, S., Ma, X., Deoras, A., Ray, B.: Utfix: Change aware unit test repairing using llm. Proceedings of the ACM on Programming Languages 9(OOPSLA1), 143–168 (2025) Cited on p. 2
2025
-
[34]
In: 2024 IEEE International Conference on Big Data (BigData)
Raihan, N., Newman, C., Zampieri, M.: Code llms: A taxonomy-based survey. In: 2024 IEEE International Conference on Big Data (BigData). pp. 5402–5411. IEEE (2024) Cited on p. 2
2024
-
[35]
Rashid, M.S., Bock, C., Zhuang, Y ., Buccholz, A., Esler, T., Valentin, S., Franceschi, L., Wistuba, M., Sivaprasad, P.T., Kim, W.J., et al.: Swe-polybench: A multi-language benchmark for repository level evaluation of coding agents. arXiv preprint arXiv:2504.08703 (2025) Cited on p. 2, 3
-
[36]
Wicher, F.: Why we chose cloud development kit for terraform over hashicorp configuration language for our infrastructure. https://andamp.io/blog/why-we-chose-cloud -development-kit-for-terraform-over-hashicorp-configuration-l anguage-for-our-infrastructure (2025), andamp Engineering Blog, Mar 19, 2025 Cited on p. 1
2025
-
[37]
InfoQ News, July 2019 (2019), https://www.infoq.com/news /2019/07/amazon-aws-cdk-ga/Cited on p
Wiggers, S.J.: AWS Cloud Development Kit (CDK) Is Generally Available, Enhancing Coding Cloud Infrastructure. InfoQ News, July 2019 (2019), https://www.infoq.com/news /2019/07/amazon-aws-cdk-ga/Cited on p. 2
2019
-
[38]
Proceedings of Machine Learning and Systems6, 173–195 (2024) Cited on p
Xu, Y ., Chen, Y ., Zhang, X., Lin, X., Hu, P., Ma, Y ., Lu, S., Du, W., Mao, Z.M., Cai, D., et al.: Cloudeval-yaml: A practical benchmark for cloud configuration generation. Proceedings of Machine Learning and Systems6, 173–195 (2024) Cited on p. 2, 3
2024
-
[39]
In: Proceedings of the 46th IEEE/ACM International Conference on Software Engineering
Yu, H., Shen, B., Ran, D., Zhang, J., Zhang, Q., Ma, Y ., Liang, G., Li, Y ., Wang, Q., Xie, T.: Codereval: A benchmark of pragmatic code generation with generative pre-trained models. In: Proceedings of the 46th IEEE/ACM International Conference on Software Engineering. pp. 1–12 (2024) Cited on p. 3. 12 Appendix A SWE-InfraBench Characteristics SWE-Infra...
2024
-
[40]
allow sending whatsapp messages and getting media from them for all cell numbers in all regions and accounts
-
[41]
access to any transcribe action on all resources
-
[42]
task_id":
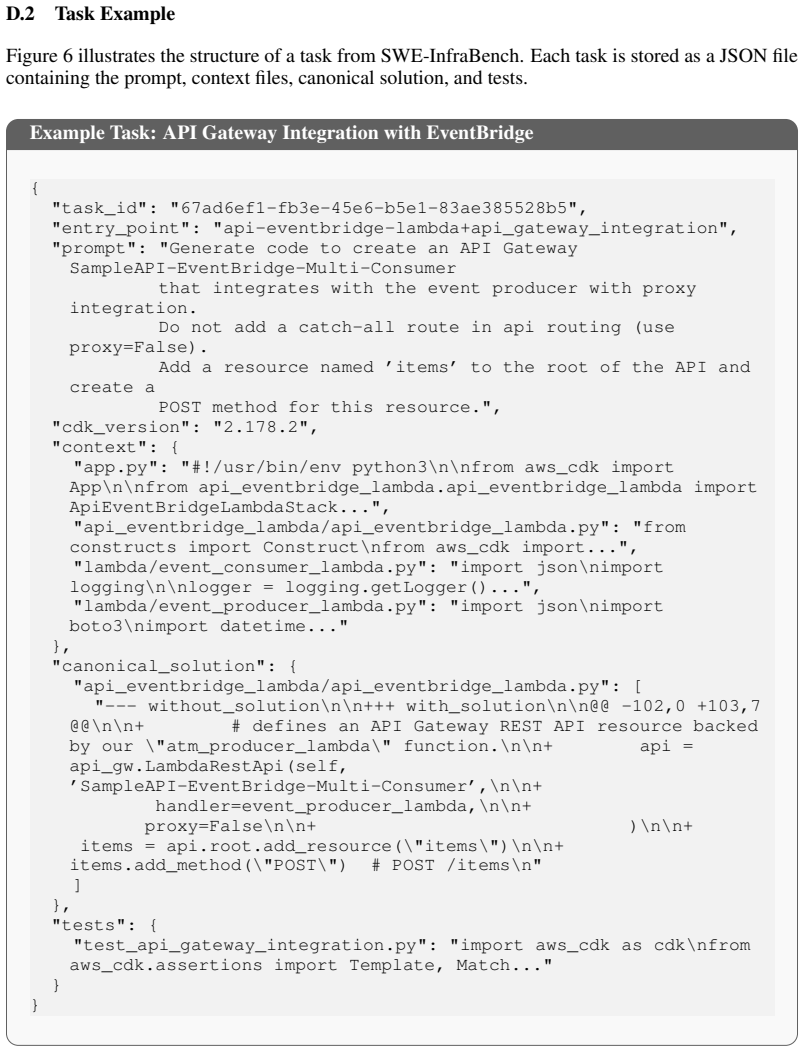
and access to invoke* all agents, inference profiles and models in oregon 14 D.2 Task Example Figure 6 illustrates the structure of a task from SWE-InfraBench. Each task is stored as a JSON file containing the prompt, context files, canonical solution, and tests. Example Task: API Gateway Integration with EventBridge { "task_id": "67ad6ef1-fb3e-45e6-b5e1-...
-
[44]
The full repository code
-
[46]
The actual code that was masked
-
[47]
The generated human language prompt
-
[48]
The generated test file Your job is to critically evaluate:
-
[49]
Whether the prompt accurately describes what needs to be implemented
-
[50]
Whether the tests effectively validate all requirements stated in the prompt
-
[51]
Whether the prompt and tests are general enough to allow various valid solutions that preserve the functionality of the masked code while remaining compatible with the overall repository structure # REPOSITORY DESCRIPTION [Repository description is provided here] # REPOSITORY CONTENT [Repository files are provided here] # PRE-SUGGESTION Item Name: [Item n...
-
[52]
Does the prompt clearly describe ALL the necessary functional aspects needed for the masked code?
-
[53]
Is it sufficiently detailed for someone to implement the solution correctly without seeing the masked code?
-
[54]
Are there any ambiguities or missing requirements that would prevent a correct implemen- tation?
-
[55]
Does it avoid revealing the actual implementation details while still being complete?
-
[56]
## Generality of Tests Evaluation 16
If something can be inferred unequivocally from the repository code, it does not need to be specified in the prompt. ## Generality of Tests Evaluation 16
-
[57]
Tests should be general enough so that they pass if a developer or LLM follows the prompt accurately, regardless of the specific implementation details
-
[58]
The prompt should give only the minimum necessary instructions needed to explain the functional requirements, while considering how the tests are built
-
[59]
Tests should verify functionality rather than specific implementation approaches - they should allow for multiple valid solution patterns that fulfill the prompt
-
[60]
Evaluate if tests are overly restrictive by enforcing a particular implementation approach when other valid approaches could fulfill the same requirements
-
[61]
## Test Evaluation For each test in the test file:
Tests won’t be accepted if they don’t pass with the original masked code (tested elsewhere) but consider as well if other reasonable implementations would pass. ## Test Evaluation For each test in the test file:
-
[62]
What is this test specifically checking for?
-
[63]
Is this test testing for something that’s explicitly stated in the prompt?
-
[64]
A test is valid if it tests integration with functionality that exists elsewhere in the code base (not just the masked section)
-
[65]
Is the test appropriately written to verify the requirement?
-
[66]
If the test might fail with some valid implementations (including the original masked code), should the prompt be more explicit or should the test be less restrictive? ## Test Completeness Evaluation
-
[67]
Do the tests collectively verify ALL requirements mentioned in the prompt?
-
[68]
Are there any requirements in the prompt that aren’t tested?
-
[69]
Are there any tests for requirements not mentioned in the prompt?
-
[70]
prompt_vs_functional
Are all edge cases and error conditions properly tested? Return the response in this JSON format: { "prompt_vs_functional": { "explanation": "Detailed explanation of whether the prompt accurately describes all necessary functional aspects of the masked code", "corrections": "Specific corrections with concrete implementation suggestions - provide exact wor...
-
[71]
A repository description
-
[72]
A pre-suggestion with a specific code section to mask
-
[73]
The full repository content 18 Based on this information, you need to:
-
[74]
Create a clear, detailed human language prompt describing what code needs to be generated
-
[75]
item_name
Develop comprehensive pytest tests that validate the generated code meets all requirements # REPOSITORY DESCRIPTION [Repository description is provided here] # PRE-SUGGESTION Item Name: [Item name] File Path: [File path] Start Line: [Start line] End Line: [End line] Complexity: [Complexity] Rationale: [Rationale] # PREVIOUS FEEDBACK When available, this s...
-
[76]
COMPLETENESS: Describe ALL functional aspects needed for the code
-
[77]
GENERALITY: Allow for multiple possible valid solutions that fulfill the requirements
-
[78]
CLARITY: Be specific about requirements but avoid dictating implementation specifics
-
[79]
PRECISION: Include all requirements that would allow someone to implement the solution correctly
-
[80]
CONTEXT: Describe the functionality, purpose, and integration with other components
-
[81]
ESSENTIAL DETAILS ONLY: Specify necessary parameters and behaviors, but avoid over-constraining the solution
-
[82]
NO SPOILERS: DO NOT include the actual implementation details or code snippets
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.