Policy-Conditioned Counterfactual Credit for Verifiable Reinforcement Learning of Long-Horizon Language Agents
Pith reviewed 2026-06-28 07:31 UTC · model grok-4.3
The pith
CVT-RL uses policy-conditioned counterfactual credit to reward only causally effective steps in long-horizon language agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
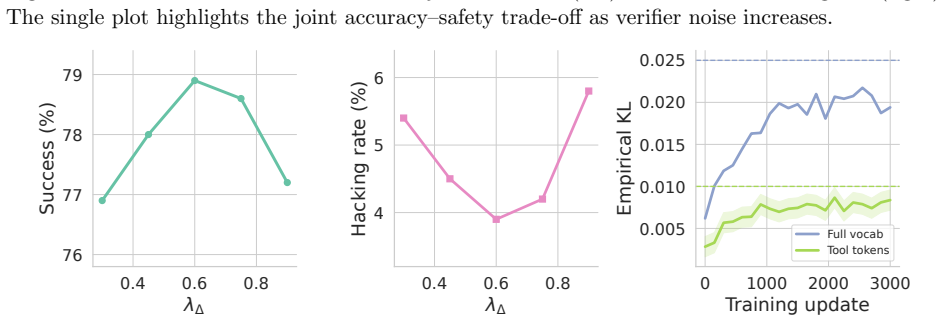
A policy-conditioned counterfactual contribution estimator, combined with intervention-validity gating and Lagrangian constraints on unsupported behavior, allows reinforcement learning to distinguish steps that causally improve verified terminal success from those that merely correlate with it.
What carries the argument
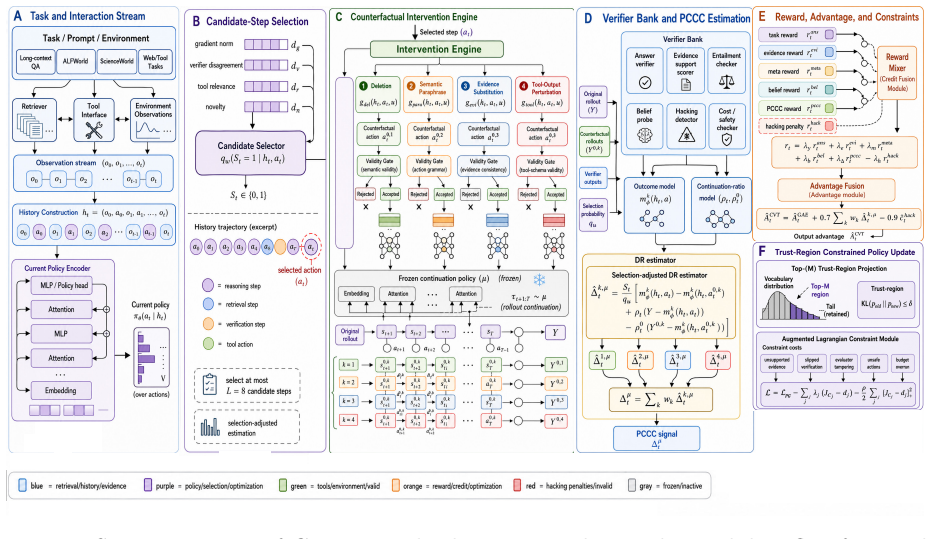
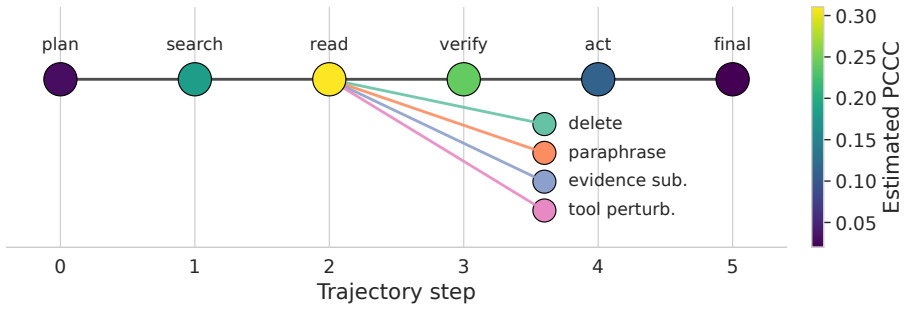
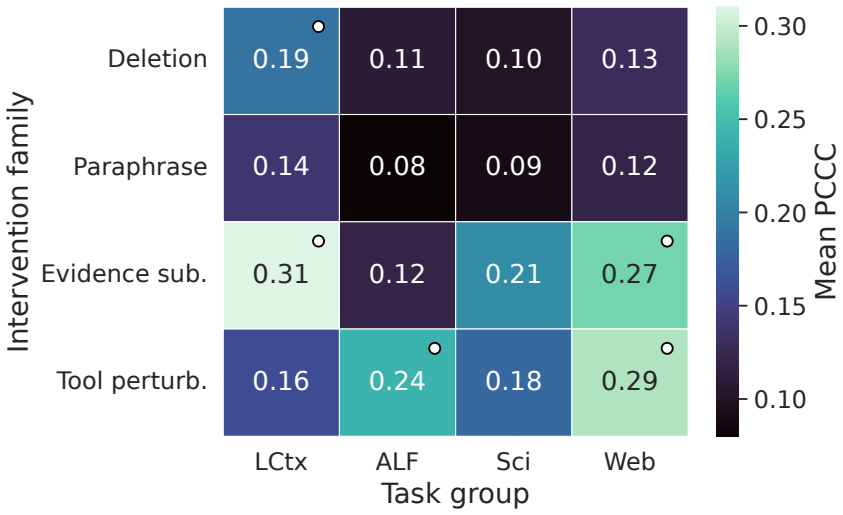
The policy-conditioned counterfactual contribution (PCCC) estimator, which computes step advantages via a selection-adjusted doubly robust estimator under four defined interventions and a frozen reference policy.
If this is right
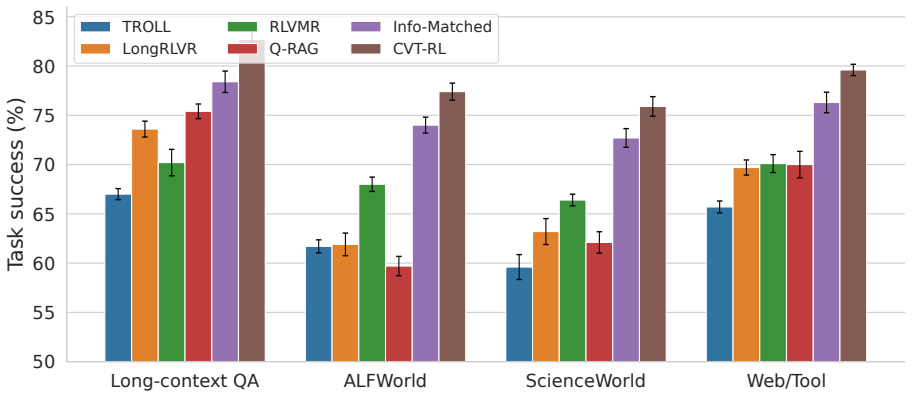
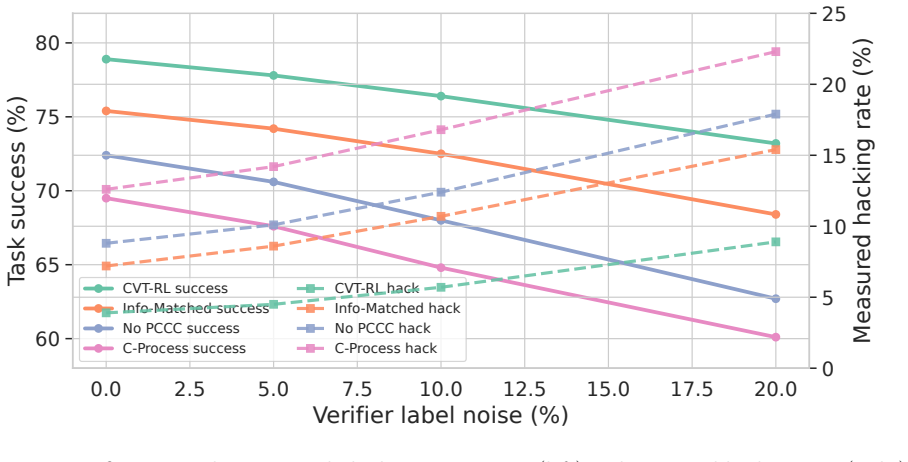
- Task success rises to 78.9 percent while evidence F1 rises to 82.8 on the reported benchmarks.
- Measured hacking falls from 7.2 percent to 3.9 percent and remains low under adaptive detector-evasion attacks.
- Human audits confirm lower unsupported behavior for CVT-RL than for the information-matched baseline.
- Stratified bootstrap and mixed-effects tests reach p less than 0.01 after correction for primary metrics.
Where Pith is reading between the lines
- The same intervention-and-gating pattern could be applied to other verifiable sequential decision settings where terminal checks are cheap but process credit is hard to assign.
- If the reference policy is replaced by a stronger model, the estimator might further reduce variance without changing the validity-gating logic.
- Extending the four interventions to include numerical or logical substitutions could test whether the estimator generalizes beyond text and tool outputs.
Load-bearing premise
The selection-adjusted doubly robust estimator correctly recovers each step's causal contribution to verified success when continuations are sampled from the frozen reference policy under the chosen interventions.
What would settle it
An experiment in which the true causal effect of a step is known by construction (for example, by controlled deletion of a necessary evidence token) yet the PCCC estimator returns a materially different advantage value.
Figures
read the original abstract
Reinforcement learning with verifiable rewards improves reasoning and tool use, yet long-horizon language agents still learn unsupported evidence chains, belief drift, and shortcut actions that satisfy terminal checks. Existing process rewards are mostly correlational: they reward retrieval-, reflection-, or verification-like steps without estimating whether the step contributes to final verified success under a specified intervention. We propose CVT-RL, a constrained policy-gradient algorithm with dense verifiable rewards, intervention-validity gating, and a policy-conditioned counterfactual contribution (PCCC) estimator. Deletion, semantic substitution, evidence substitution, and tool-output perturbation define separate controlled interventions; continuations are sampled from a frozen reference policy, and a selection-adjusted doubly robust estimator augments the advantage. Belief control uses only prefix-observable labels, while an augmented Lagrangian constrains unsupported claims, skipped verification, tool tampering, and unsafe calls. On long-context QA, ALFWorld, ScienceWorld, and web/tool tasks, CVT-RL improves average task success from 71.8% for compute-matched non-causal RL and 75.4% for an information-matched counterfactual-process baseline to 78.9%, improves evidence F1 from 78.9 to 82.8 over the information-matched baseline, and reduces measured hacking from 7.2% to 3.9%. Independent human audit estimates 4.6% hacking for CVT-RL versus 8.1% for the information-matched baseline, and adaptive detector-evasion attacks raise hacking only to 7.1%. Stratified bootstrap and mixed-effects tests give p<0.01 after Holm correction for all primary metrics. Carefully scoped counterfactual credit, paired with validity gating, diagnostics, and verifiable constraints, provides a reproducible route toward more reliable long-horizon RL for language agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CVT-RL, a constrained policy-gradient algorithm for long-horizon language agents that incorporates dense verifiable rewards, intervention-validity gating, and a policy-conditioned counterfactual contribution (PCCC) estimator based on deletion, semantic substitution, evidence substitution, and tool-output perturbation interventions with continuations from a frozen reference policy. It reports average task success rising to 78.9% (vs. 71.8% non-causal RL and 75.4% information-matched counterfactual baseline), evidence F1 to 82.8, and hacking reduced to 3.9% (human audit 4.6%, attack 7.1%) across long-context QA, ALFWorld, ScienceWorld, and web/tool tasks, with p<0.01 after correction via stratified bootstrap and mixed-effects tests.
Significance. If the PCCC estimator provides valid causal identification, the approach supplies a concrete mechanism for dense, intervention-based credit assignment that directly targets unsupported evidence chains and hacking in verifiable RL, moving beyond correlational process rewards. The combination of validity gating, augmented Lagrangian constraints, human audits, and adaptive attack testing supplies a reproducible empirical template for reliability improvements in long-horizon language agents.
major comments (2)
- [Abstract] Abstract (PCCC estimator description): the selection-adjusted doubly robust estimator is asserted to recover the causal contribution of each step under the listed interventions when continuations are drawn from a frozen reference policy, yet no identification result, propensity/outcome model specification, or sensitivity analysis is supplied; standard DR theory does not automatically extend to non-i.i.d. discrete text edits in high-dimensional state spaces, and any misspecification directly affects the advantage signal used for the policy gradient. This assumption is load-bearing for the reported gains (78.9% success, 82.8 F1, 3.9% hacking).
- [Abstract] Abstract (statistical claims): the stratified bootstrap and mixed-effects tests yielding p<0.01 after Holm correction are stated without the precise error-bar construction, variance estimation procedure, or stratification variables, and no code or data release is indicated; this prevents independent verification of whether the performance deltas (e.g., success from 71.8% to 78.9%) are robust to the high variance typical of language-agent rollouts.
minor comments (1)
- [Abstract] The abstract does not define the precise functional form of the augmented Lagrangian or the validity-gating predicate, leaving the constraint implementation underspecified for replication.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (PCCC estimator description): the selection-adjusted doubly robust estimator is asserted to recover the causal contribution of each step under the listed interventions when continuations are drawn from a frozen reference policy, yet no identification result, propensity/outcome model specification, or sensitivity analysis is supplied; standard DR theory does not automatically extend to non-i.i.d. discrete text edits in high-dimensional state spaces, and any misspecification directly affects the advantage signal used for the policy gradient. This assumption is load-bearing for the reported gains (78.9% success, 82.8 F1, 3.9% hacking).
Authors: We agree that a formal identification result is necessary to support the claims about the PCCC estimator. The current manuscript relies on the standard doubly robust theory but does not explicitly derive the identification for the non-i.i.d. text interventions. In the revision, we will include a dedicated section providing the identification assumptions, the specification of the propensity and outcome models used, and a sensitivity analysis to assess robustness to misspecification. revision: yes
-
Referee: [Abstract] Abstract (statistical claims): the stratified bootstrap and mixed-effects tests yielding p<0.01 after Holm correction are stated without the precise error-bar construction, variance estimation procedure, or stratification variables, and no code or data release is indicated; this prevents independent verification of whether the performance deltas (e.g., success from 71.8% to 78.9%) are robust to the high variance typical of language-agent rollouts.
Authors: We acknowledge the need for greater transparency in the statistical analysis. The revised manuscript will detail the error-bar construction, variance estimation, and stratification variables used in the bootstrap and mixed-effects tests. Additionally, we will release the code and data upon acceptance to allow independent verification of the results. revision: yes
Circularity Check
No circularity: empirical claims rest on external interventions and standard DR estimator without reduction to fitted inputs
full rationale
The paper defines CVT-RL and the PCCC estimator via explicit interventions (deletion, semantic substitution, evidence substitution, tool-output perturbation) on continuations sampled from a frozen reference policy, then applies a selection-adjusted doubly robust estimator to augment advantages. No equation or step in the provided text equates a reported outcome (task success, evidence F1, hacking rate) to a quantity fitted on the same evaluation data by construction. The central results are empirical improvements over baselines, not identities or self-citations that load-bear the identification. The estimator is invoked as an off-the-shelf augmentation rather than derived from the target metrics themselves. This satisfies the default expectation of a non-circular derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
1999 , publisher=
Constrained Markov Decision Processes , author=. 1999 , publisher=
1999
-
[2]
International Conference on Machine Learning , pages=
Constrained Policy Optimization , author=. International Conference on Machine Learning , pages=
-
[3]
arXiv preprint arXiv:1606.06565 , year=
Concrete Problems in AI Safety , author=. arXiv preprint arXiv:1606.06565 , year=
-
[4]
arXiv preprint arXiv:2212.08073 , year=
Constitutional AI: Harmlessness from AI Feedback , author=. arXiv preprint arXiv:2212.08073 , year=
-
[5]
Annual Meeting of the Association for Computational Linguistics , year=
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[6]
International Conference on Learning Representations , year=
TROLL: Trust Regions Improve Reinforcement Learning for Large Language Models , author=. International Conference on Learning Representations , year=
-
[7]
International Conference on Machine Learning , year=
Improving Language Models by Retrieving from Trillions of Tokens , author=. International Conference on Machine Learning , year=
-
[8]
International Conference on Learning Representations , year=
LongRLVR: Long-Context Reinforcement Learning Requires Verifiable Context Rewards , author=. International Conference on Learning Representations , year=
-
[9]
Advances in Neural Information Processing Systems , year=
A Lyapunov-Based Approach to Safe Reinforcement Learning , author=. Advances in Neural Information Processing Systems , year=
-
[10]
Advances in Neural Information Processing Systems , year=
Deep Reinforcement Learning from Human Preferences , author=. Advances in Neural Information Processing Systems , year=
-
[11]
arXiv preprint arXiv:2501.12948 , year=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[12]
International Conference on Machine Learning , year=
Doubly Robust Policy Evaluation and Learning , author=. International Conference on Machine Learning , year=
-
[13]
Fu, Justin and Kumar, Aviral and Nachum, Ofir and Tucker, George and Levine, Sergey , booktitle=
-
[14]
International Conference on Machine Learning , year=
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author=. International Conference on Machine Learning , year=
-
[15]
2020 , publisher=
Causal Inference: What If , author=. 2020 , publisher=
2020
-
[16]
International Conference on Learning Representations , year=
RULER: What's the Real Context Size of Your Long-Context Language Models? , author=. International Conference on Learning Representations , year=
-
[17]
International Conference on Machine Learning , year=
Classifier-Free Diffusion Generation for Offline-to-Online Reinforcement Learning , author=. International Conference on Machine Learning , year=
-
[18]
2015 , publisher=
Causal Inference for Statistics, Social, and Biomedical Sciences , author=. 2015 , publisher=
2015
-
[19]
European Chapter of the Association for Computational Linguistics , year=
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering , author=. European Chapter of the Association for Computational Linguistics , year=
-
[20]
International Conference on Machine Learning , year=
Doubly Robust Off-policy Value Evaluation for Reinforcement Learning , author=. International Conference on Machine Learning , year=
-
[21]
2023 , howpublished=
Needle in a Haystack: Pressure Testing LLMs , author=. 2023 , howpublished=
2023
-
[22]
Empirical Methods in Natural Language Processing , year=
Dense Passage Retrieval for Open-Domain Question Answering , author=. Empirical Methods in Natural Language Processing , year=
-
[23]
Advances in Neural Information Processing Systems , year=
Large Language Models are Zero-Shot Reasoners , author=. Advances in Neural Information Processing Systems , year=
-
[24]
International Conference on Learning Representations , year=
Offline Reinforcement Learning with Implicit Q-Learning , author=. International Conference on Learning Representations , year=
-
[25]
Advances in Neural Information Processing Systems , year=
Conservative Q-Learning for Offline Reinforcement Learning , author=. Advances in Neural Information Processing Systems , year=
-
[26]
Advances in Neural Information Processing Systems , year=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. Advances in Neural Information Processing Systems , year=
-
[27]
Annual Meeting of the Association for Computational Linguistics , year=
LooGLE: Can Long-Context Language Models Understand Long Contexts? , author=. Annual Meeting of the Association for Computational Linguistics , year=
-
[28]
International Conference on Learning Representations , year=
ABBEL: LLM Agents Acting Through Belief Bottlenecks for Efficient Long-Horizon Reasoning , author=. International Conference on Learning Representations , year=
-
[29]
Journal of Artificial Intelligence Research , volume=
AgentBench: Evaluating LLMs as Agents , author=. Journal of Artificial Intelligence Research , volume=
-
[30]
arXiv preprint arXiv:2503.14476 , year=
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. arXiv preprint arXiv:2503.14476 , year=
-
[31]
Advances in Neural Information Processing Systems , year=
Q-Chunking: Offline-to-Online Reinforcement Learning with Action Chunking , author=. Advances in Neural Information Processing Systems , year=
-
[32]
arXiv preprint arXiv:2605.19577 , year=
GoLongRL: Capability-Oriented Long Context Reinforcement Learning with Multitask Alignment , author=. arXiv preprint arXiv:2605.19577 , year=
-
[33]
Nature , volume=
Human-level Control through Deep Reinforcement Learning , author=. Nature , volume=
-
[34]
Advances in Neural Information Processing Systems , year=
Training Language Models to Follow Instructions with Human Feedback , author=. Advances in Neural Information Processing Systems , year=
-
[35]
International Conference on Learning Representations , year=
The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models , author=. International Conference on Learning Representations , year=
-
[36]
arXiv preprint arXiv:2605.02964 , year=
Reward Hacking Benchmark: Evaluating Reward Hacking in Tool-Using Language Agents , author=. arXiv preprint arXiv:2605.02964 , year=
-
[37]
arXiv preprint arXiv:2205.12255 , year=
TALM: Tool Augmented Language Models , author=. arXiv preprint arXiv:2205.12255 , year=
-
[38]
Advances in Neural Information Processing Systems , year=
Gorilla: Large Language Model Connected with Massive APIs , author=. Advances in Neural Information Processing Systems , year=
-
[39]
2009 , publisher=
Causality: Models, Reasoning, and Inference , author=. 2009 , publisher=
2009
-
[40]
arXiv preprint arXiv:2602.05758 , year=
LongR: Unleashing Long-Context Reasoning via Reinforcement Learning with Dense Utility Rewards , author=. arXiv preprint arXiv:2602.05758 , year=
-
[41]
International Conference on Learning Representations , year=
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs , author=. International Conference on Learning Representations , year=
-
[42]
Advances in Neural Information Processing Systems , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Advances in Neural Information Processing Systems , year=
-
[43]
arXiv preprint arXiv:1910.01708 , year=
Benchmarking Safe Exploration in Deep Reinforcement Learning , author=. arXiv preprint arXiv:1910.01708 , year=
Pith/arXiv arXiv 1910
-
[44]
Advances in Neural Information Processing Systems , year=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. Advances in Neural Information Processing Systems , year=
-
[45]
International Conference on Machine Learning , year=
Trust Region Policy Optimization , author=. International Conference on Machine Learning , year=
-
[46]
arXiv preprint arXiv:1707.06347 , year=
Proximal Policy Optimization Algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[47]
arXiv preprint arXiv:2402.03300 , year=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[48]
Advances in Neural Information Processing Systems , year=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , year=
-
[49]
International Conference on Learning Representations , year=
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning , author=. International Conference on Learning Representations , year=
-
[50]
Advances in Neural Information Processing Systems , year=
Defining and Characterizing Reward Hacking , author=. Advances in Neural Information Processing Systems , year=
-
[51]
Advances in Neural Information Processing Systems , year=
Learning to Summarize with Human Feedback , author=. Advances in Neural Information Processing Systems , year=
-
[52]
2018 , publisher=
Reinforcement Learning: An Introduction , author=. 2018 , publisher=
2018
-
[53]
International Conference on Machine Learning , year=
Data-Efficient Off-Policy Policy Evaluation for Reinforcement Learning , author=. International Conference on Machine Learning , year=
-
[54]
Empirical Methods in Natural Language Processing , year=
ScienceWorld: Is Your Agent Smarter than a 5th Grader? , author=. Empirical Methods in Natural Language Processing , year=
-
[55]
International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. International Conference on Learning Representations , year=
-
[56]
Advances in Neural Information Processing Systems , year=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[57]
Machine Learning , volume=
Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning , author=. Machine Learning , volume=
-
[58]
Advances in Neural Information Processing Systems , year=
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , author=. Advances in Neural Information Processing Systems , year=
-
[59]
International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. International Conference on Learning Representations , year=
-
[60]
arXiv preprint arXiv:2401.10020 , year=
Self-Rewarding Language Models , author=. arXiv preprint arXiv:2401.10020 , year=
-
[61]
International Conference on Learning Representations , year=
RLVMR: Reinforcement Learning with Verifiable Meta-Reasoning Rewards for Robust Long-Horizon Agents , author=. International Conference on Learning Representations , year=
-
[62]
International Conference on Learning Representations , year=
Incentivizing In-depth Reasoning over Long Contexts with Reinforcement Learning , author=. International Conference on Learning Representations , year=
-
[63]
International Conference on Learning Representations , year=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. International Conference on Learning Representations , year=
-
[64]
Advances in Neural Information Processing Systems , year=
BOLA: Bayesian Optimistic Learning under Approximation for Model-Based Reinforcement Learning , author=. Advances in Neural Information Processing Systems , year=
-
[65]
International Conference on Learning Representations , year=
Reducing Belief Deviation in Reinforcement Learning for Active Reasoning of LLM Agents , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.