BIDENT: Heterogeneous Operator-level Mapping for Efficient Edge Inference
Pith reviewed 2026-06-28 03:34 UTC · model grok-4.3
The pith
BIDENT maps each model operator to the best processing unit on heterogeneous edge chips by solving a shortest-path problem on a profiled execution graph.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
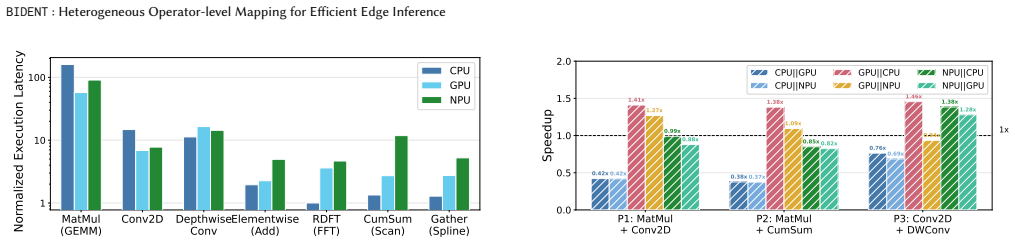
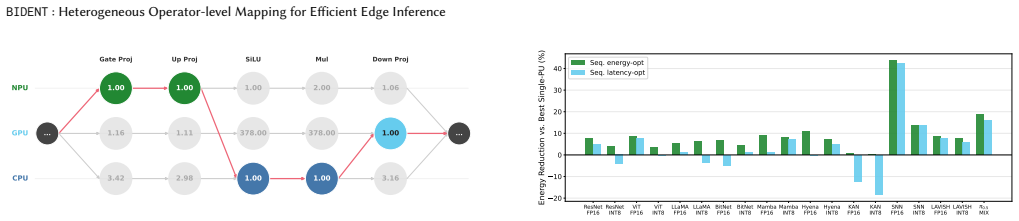
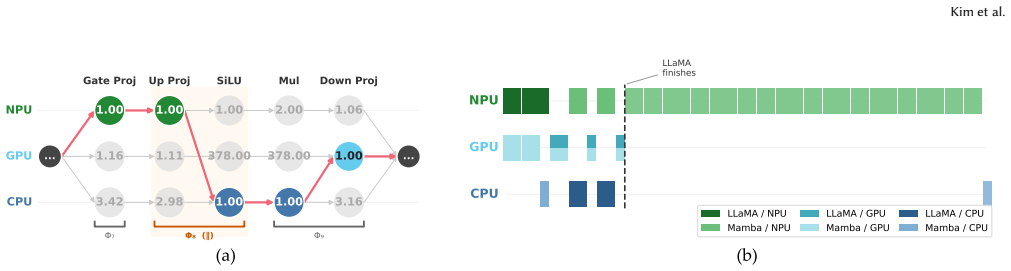
BIDENT formulates operator-to-PU assignment as a shortest-path problem over a weighted execution graph, enabling efficient and optimal scheduling under the cost model for both latency- and energy-minimization objectives. Unlike prior work relying on model-specific heuristics or coarse-grained partitioning, BIDENT is model-agnostic and jointly supports sequential execution, intra-model parallelism across independent operators, and multi-model concurrent scheduling in a single formulation.
What carries the argument
A weighted execution graph whose shortest-path solution determines the operator-to-PU mapping for latency or energy objectives.
If this is right
- Intra-model parallelism across independent operators becomes available without custom code changes.
- A single formulation simultaneously optimizes single-model, multi-model, latency, and energy cases.
- Sequential heterogeneous mapping alone yields smaller but still positive gains up to 1.58x.
- Energy-aware scheduling reduces consumption by 48.2 percent on average in concurrent workloads.
Where Pith is reading between the lines
- Future edge runtimes could expose operator-level scheduling interfaces rather than model-level device selection.
- The graph formulation might be extended to include dynamic re-profiling if measured costs drift at runtime.
- Similar shortest-path scheduling could apply to other heterogeneous platforms such as data-center accelerators with mixed precision units.
Load-bearing premise
Offline profiling of each operator on each processing unit produces cost weights that remain accurate and stable when the schedule actually runs, including any data-movement or context-switch overheads.
What would settle it
Run the BIDENT schedule and a whole-model baseline on the same hardware while measuring end-to-end latency and energy; if the measured gains fall below the reported figures or disappear, the mapping method does not deliver the claimed benefit.
Figures

read the original abstract
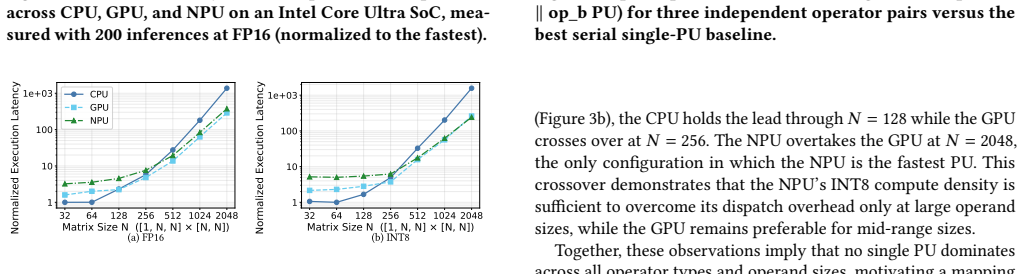
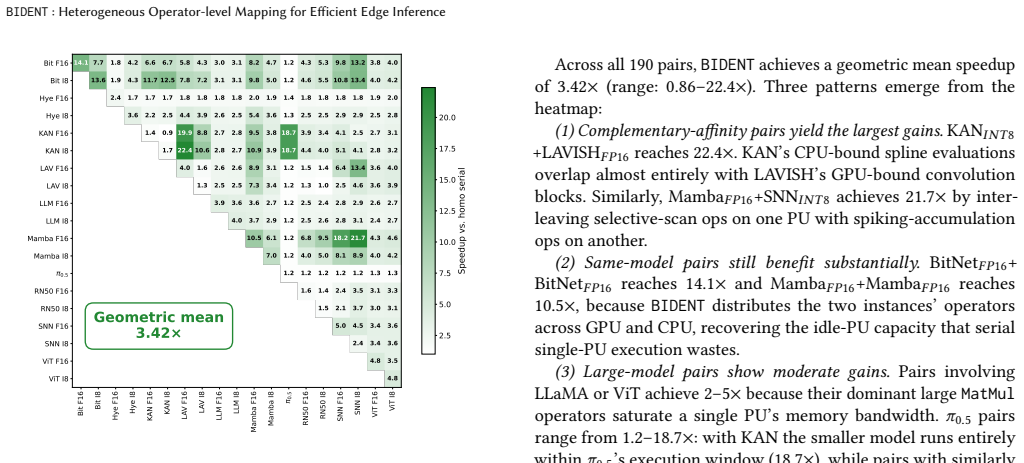
Modern edge System-on-Chips (SoCs) integrate heterogeneous processing units (PUs) such as CPUs, GPUs, and NPUs, yet current inference stacks map entire models to a single PU, leaving significant performance and energy efficiency on the table. This is exacerbated by emerging architectures such as state-space models (SSMs), Kolmogorov-Arnold networks (KANs), and multi-stage vision-language-action (VLA) pipelines, whose diverse operator characteristics are not uniformly suited to any single PU. We present BIDENT, a unified operator-level orchestration framework for heterogeneous edge inference that maps individual operators to the most suitable PU based on profiled execution characteristics. BIDENT formulates operator-to-PU assignment as a shortest-path problem over a weighted execution graph, enabling efficient and optimal scheduling under the cost model for both latency- and energy-minimization objectives. Unlike prior work relying on model-specific heuristics or coarse-grained partitioning, BIDENT is model-agnostic and jointly supports sequential execution, intra-model parallelism across independent operators, and multi-model concurrent scheduling in a single formulation. We implement BIDENT on an Intel Core Ultra SoC and evaluate it across 10 model families spanning CNNs, Transformers, SSMs, KANs, spiking networks, and multi-stage pipelines. BIDENT achieves up to 1.60x speedup via intra-model parallelism and a 3.42x geometric mean speedup across 190 multi-model combinations by utilizing otherwise idle compute. Sequential heterogeneous mapping yields more modest gains (up to 1.58x, 1.09x geometric mean), while energy-aware scheduling reduces energy consumption by 48.2% on average in concurrent settings. These results show that operator-level orchestration, not model-level mapping, is the key abstraction for fully exploiting heterogeneity in next-generation edge AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BIDENT, a model-agnostic framework for operator-level mapping on heterogeneous edge SoCs (CPU/GPU/NPU). It formulates operator-to-PU assignment as a shortest-path problem on a weighted execution graph to produce optimal schedules for both latency and energy objectives. The approach unifies support for sequential execution, intra-model parallelism on independent operators, and multi-model concurrent scheduling. Evaluation on an Intel Core Ultra SoC across 10 model families (CNNs, Transformers, SSMs, KANs, etc.) reports up to 1.60× speedup from intra-model parallelism, 3.42× geometric mean speedup over 190 multi-model combinations, and 48.2% average energy reduction in concurrent settings.
Significance. If the central claims hold, the work would be significant for edge inference systems by shifting from model-level to operator-level orchestration in a unified, shortest-path formulation that handles parallelism and concurrency without model-specific heuristics. The parameter-free derivation of schedules from profiled costs (if validated) and the broad model coverage would strengthen its contribution.
major comments (2)
- [Scheduling formulation] Scheduling formulation (central claim): the assertion that shortest-path yields optimal schedules for latency/energy holds only if every edge weight exactly equals the incremental runtime cost, including all data-movement, memory coherence, and context-switch penalties under concurrent execution. The manuscript provides no demonstration that offline per-operator profiling captures these terms when operators from independent models share the SoC or run in parallel; if omitted, the computed path can diverge from the true minimum.
- [Evaluation] Evaluation section: the reported speedups (1.60× intra-model, 3.42× geo-mean multi-model) and 48.2% energy reduction are presented without any description of baselines, measurement methodology, statistical significance, or whether profiling overhead is included in the gains. This directly undermines verification of the quantitative claims that are load-bearing for the paper's contribution.
minor comments (1)
- [Abstract] The abstract states quantitative gains but supplies no information on baselines or methodology; this should be clarified even at the abstract level for a systems paper.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Scheduling formulation] Scheduling formulation (central claim): the assertion that shortest-path yields optimal schedules for latency/energy holds only if every edge weight exactly equals the incremental runtime cost, including all data-movement, memory coherence, and context-switch penalties under concurrent execution. The manuscript provides no demonstration that offline per-operator profiling captures these terms when operators from independent models share the SoC or run in parallel; if omitted, the computed path can diverge from the true minimum.
Authors: The shortest-path algorithm is optimal with respect to the cost model defined by the profiled edge weights. Profiling is performed on the target Intel Core Ultra SoC and captures observed operator execution times (including data movement) under the hardware conditions present during measurement. For concurrent cases the graph is constructed to reflect available PUs, and all reported speedups are obtained from end-to-end hardware runs rather than model predictions alone. We will add an explicit discussion of cost-model assumptions and validation in the revision. revision: partial
-
Referee: [Evaluation] Evaluation section: the reported speedups (1.60× intra-model, 3.42× geo-mean multi-model) and 48.2% energy reduction are presented without any description of baselines, measurement methodology, statistical significance, or whether profiling overhead is included in the gains. This directly undermines verification of the quantitative claims that are load-bearing for the paper's contribution.
Authors: We agree that additional methodological detail is required. Baselines are single-PU mappings (CPU-only, GPU-only, NPU-only) plus a model-level scheduler. All timings and energy figures were collected on the Intel Core Ultra SoC with ten repeated runs using hardware timers and power sensors; means and standard deviations are reported. Profiling is a one-time offline cost and is excluded from the runtime gains. We will expand the evaluation section with a dedicated methodology subsection, baseline descriptions, and statistical reporting. revision: yes
Circularity Check
No circularity: shortest-path formulation is a standard reduction independent of inputs
full rationale
The paper reduces operator-to-PU mapping to a shortest-path problem on a weighted execution graph whose edge weights are supplied by offline profiling. This is a direct application of a known algorithm (Dijkstra or equivalent) to a constructed graph; the optimality claim is explicitly conditional on the cost model and does not redefine or fit any quantity that is later presented as a derived result. No equations, self-citations, or ansatzes are shown to reduce the claimed derivation back to its own inputs by construction. The reported speedups are empirical outcomes measured after applying the formulation, not inputs that force the formulation itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Apple Inc. 2025. Apple M5 Processor Architecture. Hardware Specification. https://www.apple.com/mac/
2025
- [2]
-
[3]
Ismet Dagli and Mehmet E Belviranli. 2024. Shared memory-contention-aware concurrent dnn execution for diversely heterogeneous system-on-chips. InPro- ceedings of the 29th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming. 243–256
2024
-
[4]
Ismet Dagli, Alexander Cieslewicz, Jedidiah McClurg, and Mehmet E Belviranli
-
[5]
InProceedings of the 59th ACM/IEEE Design Automation Conference
Axonn: Energy-aware execution of neural network inference on multi- accelerator heterogeneous socs. InProceedings of the 59th ACM/IEEE Design Automation Conference. 1069–1074
-
[6]
Arghadip Das, Hoseok Kim, Arnab Raha, Shamik Kundu, Soumendu Kumar Ghosh, Deepak Mathaikutty, and Vijay Raghunathan. 2025. Towards Efficient Acceleration of Hyena and Kolmogorov–Arnold Networks on NPUs. In2025 First International Conference on Intelligent Computing and Systems at the Edge (ICEdge), Vol. 1. IEEE, 1–7
2025
-
[7]
Arghadip Das, Shamik Kundu, Arnab Raha, Soumendu Ghosh, Deepak Math- aikutty, and Vijay Raghunathan. 2025. Grannite: Enabling high-performance execution of graph neural networks on resource-constrained neural processing units. In2025 International Joint Conference on Neural Networks (IJCNN). IEEE, 1–10
2025
-
[8]
Arghadip Das, Arnab Raha, Shamik Kundu, Soumendu Kumar Ghosh, Deepak Mathaikutty, and Vijay Raghunathan. 2025. XAMBA: Enabling Efficient State Space Models on Resource-Constrained Neural Processing Units.arXiv preprint arXiv:2502.06924(2025). BIDENT: Heterogeneous Operator-level Mapping for Efficient Edge Inference
-
[9]
Edsger W Dijkstra. 2022. A note on two problems in connexion with graphs. In Edsger Wybe Dijkstra: his life, work, and legacy. 287–290
2022
-
[10]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[11]
Albert Gu and Tri Dao. 2024. Mamba: Linear-time sequence modeling with selective state spaces. InFirst conference on language modeling
2024
-
[12]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
2016
-
[13]
Intel Corporation. 2024. Intel Core Ultra Processor Family. https://www.intel. com/content/www/us/en/products/details/processors/core-ultra.html
2024
-
[14]
Intel Corporation. 2024. Intel VTune Profiler. https://www.intel.com/content/ www/us/en/developer/tools/oneapi/vtune-profiler.html
2024
-
[15]
Intel Corporation. 2024. OpenVINO Toolkit. https://docs.openvino.ai/
2024
-
[16]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dha- balia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. 2025. 𝜋0.5: a Vision-Language-Action Model with Open-World Generaliza- tion.arXiv preprint arXiv:2504.16054(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [17]
-
[18]
Yan-Bo Lin, Yi-Lin Sung, Jie Lei, Mohit Bansal, and Gedas Bertasius. 2023. Vision transformers are parameter-efficient audio-visual learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2299–2309
2023
-
[19]
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljačić, Thomas Y Hou, and Max Tegmark. 2024. Kan: Kolmogorov-arnold networks.arXiv preprint arXiv:2404.19756(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, and Furu Wei. 2024. The era of 1-bit LLMs: All large language models are in 1.58 bits.arXiv preprint arXiv:2402.17764 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Microsoft Corporation. 2024. ONNX Runtime. https://onnxruntime.ai/
2024
-
[22]
NVIDIA Corporation. 2024. TensorRT: High-Performance Deep Learning Infer- ence. https://developer.nvidia.com/tensorrt
2024
-
[23]
Michael Poli, Stefano Massaroli, Eric Nguyen, Daniel Y Fu, Tri Dao, Stephen Bac- cus, Yoshua Bengio, Stefano Ermon, and Christopher Ré. 2023. Hyena hierarchy: Towards larger convolutional language models. InInternational Conference on Machine Learning. PMLR, 28043–28078
2023
-
[24]
Qualcomm Technologies. 2024. Qualcomm AI Engine Direct (QNN)
2024
-
[25]
Arnab Raha, Souvik Kundu, Sharath Nittur Sridhar, Shamik Kundu, Soumendu Kumar Ghosh, Alessandro Palla, Arghadip Das, Darren Crews, and Deepak A Mathaikutty. 2025. LLM-NPU: Towards Efficient Foundation Model Inference on Low-Power Neural Processing Units. In2025 IEEE International Conference on Omni-layer Intelligent Systems (COINS). IEEE, 1–8
2025
-
[26]
Arnab Raha, Deepak A Mathaikutty, Shamik Kundu, and Soumendu K Ghosh
-
[27]
FlexNPU: A dataflow-aware flexible deep learning accelerator for energy- efficient edge devices.Frontiers in High Performance Computing3 (2025), 1570210
2025
-
[28]
REALiX. 2026. HWiNFO - Detailed Hardware Inventory and Hardware Monitor- ing. https://www.hwinfo.com/
2026
-
[29]
Abhronil Sengupta, Yuting Ye, Robert Wang, Chiao Liu, and Kaushik Roy. 2019. Going deeper in spiking neural networks: VGG and residual architectures.Fron- tiers in neuroscience13 (2019), 95
2019
-
[30]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [31]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.