Agentic Monte Carlo: Simulating Reinforcement Learning for Black-Box Agents
Pith reviewed 2026-06-28 07:33 UTC · model grok-4.3
The pith
Black-box LLM agents can be optimized by sampling from the optimal policy using sequential Monte Carlo at test time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
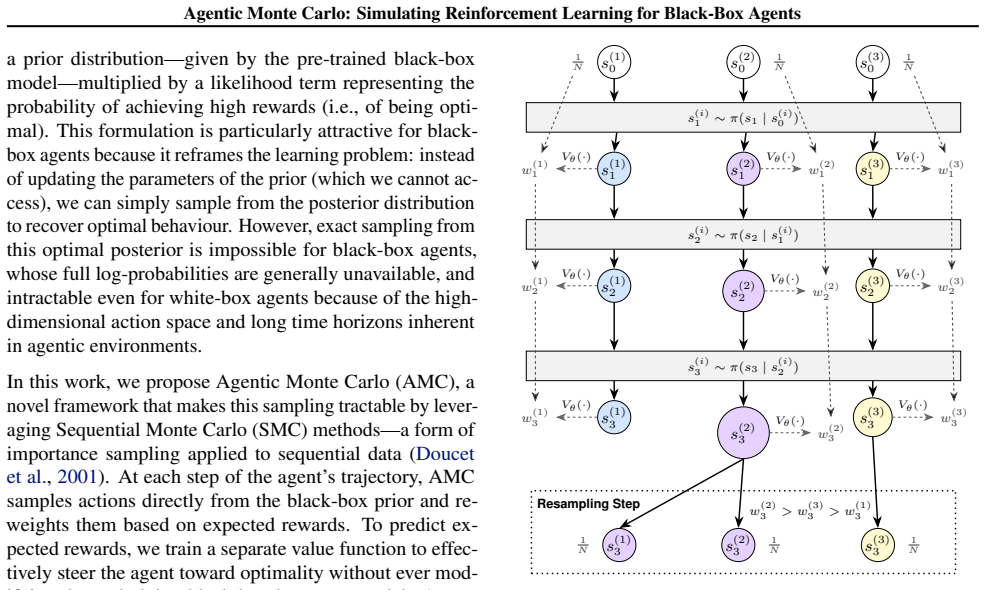
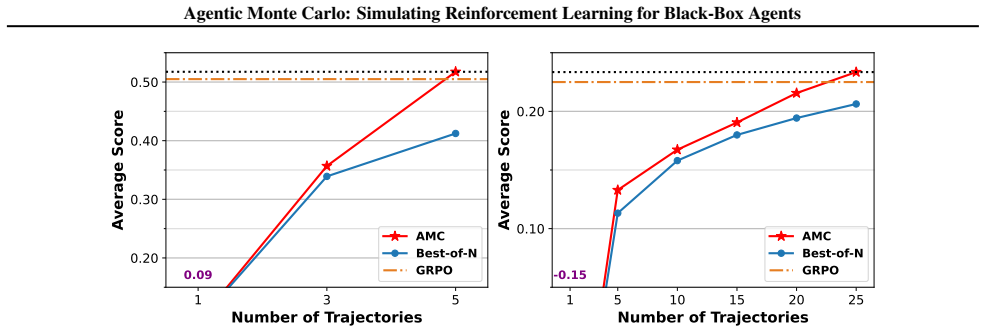
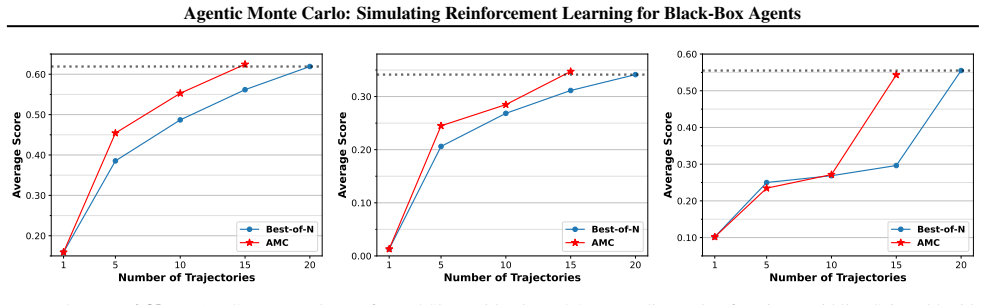
Agentic Monte Carlo demonstrates the feasibility of performing principled RL-style optimization of black-box LLM agents by sampling from the optimal policy using Sequential Monte Carlo. The optimal policy is treated as a posterior over trajectories whose prior is the fixed black-box LLM agent. A value function is learned to steer the sampling process while leaving the underlying black-box model unchanged, yielding measurable improvements on AgentGym tasks.
What carries the argument
Sequential Monte Carlo sampling from the posterior over trajectories, with a learned value function that steers the black-box LLM without changing its parameters.
If this is right
- Significant improvements over prompting baselines on three diverse AgentGym environments.
- Outperforms Group Relative Policy Optimization when test-time compute is scaled up.
- The black-box LLM remains fixed while optimization occurs entirely through guided sampling.
- Principled RL-style optimization becomes possible for API-only agents.
Where Pith is reading between the lines
- The same sampling approach could extend to other black-box decision systems that admit a prior-over-trajectories view.
- Better value-function approximators might reduce the number of samples needed to reach a given performance level.
- Observed scaling with test-time compute suggests similar Monte Carlo steering could apply to non-LLM agents.
Load-bearing premise
The equivalence between RL and Bayesian inference holds for black-box agents, so the optimal policy can be treated as a posterior whose prior is the fixed LLM.
What would settle it
Performance on AgentGym tasks stays flat or declines as the Monte Carlo sample budget increases, or the learned value function shows no advantage over uniform random steering of trajectories.
Figures




read the original abstract
LLM agents operate in two distinct regimes: open-weight agents amenable to reinforcement learning (RL) and black-box agents whose behaviour must be controlled purely at test time. Although black-box agents are often backed by state-of-the-art proprietary LLMs, API-only access precludes parameter-level optimization, rendering most RL methods inapplicable. To address this limitation, we turn to a known equivalence between RL and Bayesian inference. We propose Agentic Monte Carlo (AMC) to directly sample from the optimal policy of a black-box agent rather than training it through RL. The optimal policy is a posterior over trajectories whose prior we define as the fixed black-box LLM agent. We employ Sequential Monte Carlo to sample from this posterior by learning a value function to steer the agent while leaving the underlying black-box model unchanged. We validate AMC on three diverse environments from the AgentGym benchmark, demonstrating significant improvements over prompting baselines and even outperforming Group Relative Policy Optimization (GRPO) as we scale the test-time compute of our method. AMC demonstrates the feasibility of performing principled RL-style optimization of black-box LLM agents. Code is available at https://github.com/layer6ai-labs/Agentic-Monte-Carlo
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Agentic Monte Carlo (AMC) to enable RL-style optimization for black-box LLM agents. It defines the optimal policy as the posterior p(τ | r) ∝ p_LLM(τ) ⋅ exp(r(τ)) with the fixed black-box LLM as prior, then uses Sequential Monte Carlo (SMC) guided by a learned value function V to sample from this posterior without modifying the underlying model. Experiments on three AgentGym environments report improvements over prompting baselines and GRPO when scaling test-time compute.
Significance. If the central construction is sound, AMC would allow principled optimization of proprietary black-box agents, a practically important capability. The code release aids reproducibility. The result's significance hinges on whether the value-function steering exactly preserves the target posterior measure.
major comments (2)
- [§3] §3 (Method): the claim that SMC steered by the learned V samples exactly from the optimal posterior requires a derivation showing that the proposals and importance weights remain unbiased when the black-box LLM supplies no log p_LLM(a|s). The manuscript provides no such derivation or explicit importance-weight formula, which is load-bearing for the 'principled' and 'exact posterior' claims.
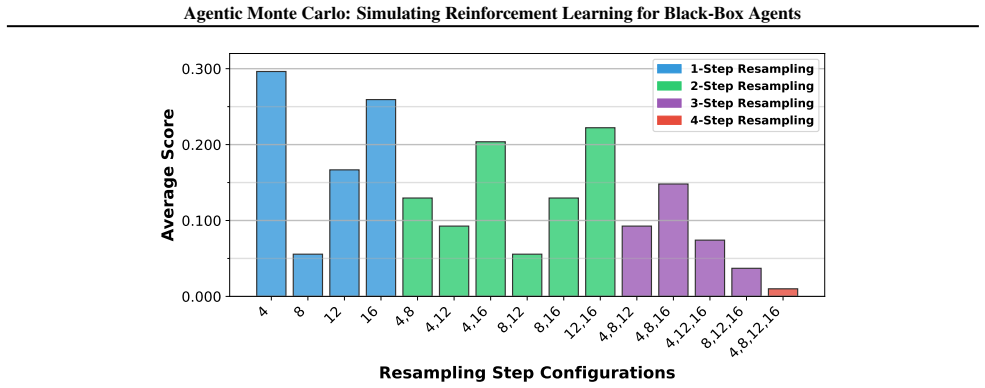
- [§4] §4 (Experiments): the reported gains over GRPO are presented without error bars, ablation on the value-function training procedure, or analysis of how many particles are required for stable weights. This weakens the scaling claim that additional test-time compute reliably improves performance.
minor comments (2)
- [Abstract / §4.1] The abstract states results on 'three diverse environments' but does not name them; the main text should list the specific AgentGym tasks in §4.1.
- [§2 / §3] Notation for the value function V and the reward r(τ) should be introduced with explicit dependence on the trajectory before being used in the posterior definition.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our method and experiments. We address each major point below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method): the claim that SMC steered by the learned V samples exactly from the optimal posterior requires a derivation showing that the proposals and importance weights remain unbiased when the black-box LLM supplies no log p_LLM(a|s). The manuscript provides no such derivation or explicit importance-weight formula, which is load-bearing for the 'principled' and 'exact posterior' claims.
Authors: We agree that an explicit derivation is required to support the exactness claim. Because the black-box LLM serves as both the prior and the proposal distribution, the prior density terms cancel in the importance weights, leaving weights that depend only on the reward and the value-function correction. We will add a dedicated subsection (and appendix) in the revision that derives the incremental weight formula step by step and proves that the resulting SMC estimator remains unbiased for the target posterior p(τ | r). revision: yes
-
Referee: [§4] §4 (Experiments): the reported gains over GRPO are presented without error bars, ablation on the value-function training procedure, or analysis of how many particles are required for stable weights. This weakens the scaling claim that additional test-time compute reliably improves performance.
Authors: The referee correctly identifies gaps in the experimental reporting. In the revised version we will (i) report means and standard errors over at least five independent runs, (ii) include an ablation varying the value-function architecture and training data, and (iii) plot performance versus number of particles together with effective sample size to demonstrate when weights remain stable. These additions will directly support the test-time scaling claims. revision: yes
Circularity Check
No circularity: derivation applies external equivalence without self-referential reduction
full rationale
The paper defines the target distribution via the standard control-as-inference equivalence (optimal policy as posterior p(τ|r) ∝ p_LLM(τ) exp(r(τ))) and proposes SMC sampling steered by a separately learned value function. This does not reduce any claimed result to a fitted input by construction, nor does it rely on self-citation for the uniqueness or validity of the equivalence. The value function is presented as an auxiliary component whose effect on importance weights is left as an empirical question rather than asserted by definitional fiat. The central claim therefore remains independent of its own outputs and is self-contained against the cited external literature on RL-Bayesian equivalence.
Axiom & Free-Parameter Ledger
free parameters (1)
- value function parameters
axioms (1)
- domain assumption Equivalence between reinforcement learning and Bayesian inference
Reference graph
Works this paper leans on
-
[1]
An Introduction to Sequential Monte Carlo Methods
Doucet, Arnaud and de Freitas, Nando and Gordon, Neil. An Introduction to Sequential Monte Carlo Methods. Sequential Monte Carlo Methods in Practice. 2001. doi:10.1007/978-1-4757-3437-9_1
-
[2]
2025 , eprint=
Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems , author=. 2025 , eprint=
2025
-
[3]
Reinforcement learning: An introduction , author=
-
[4]
Neural Computation , volume=
Using expectation-maximization for reinforcement learning , author=. Neural Computation , volume=. 1997 , publisher=
1997
-
[5]
Toussaint, Marc and Storkey, Amos , title =. 2006 , isbn =. doi:10.1145/1143844.1143963 , booktitle =
-
[6]
The Fourteenth International Conference on Learning Representations , year=
Brendan Leigh Ross and No. The Fourteenth International Conference on Learning Representations , year=
-
[7]
Feng, Naihe and Sui, Yi and Hou, Shiyi and Wu, Ga and Cresswell, Jesse C , journal=
-
[8]
Vasileios Lioutas and Jonathan Wilder Lavington and Justice Sefas and Matthew Niedoba and Yunpeng Liu and Berend Zwartsenberg and Setareh Dabiri and Frank Wood and Adam Scibior , booktitle=
-
[9]
2025 , eprint=
SentinelAgent: Graph-based Anomaly Detection in Multi-Agent Systems , author=. 2025 , eprint=
2025
-
[10]
Lew, Alexander K and Zhi-Xuan, Tan and Grand, Gabriel and Mansinghka, Vikash , booktitle=
-
[11]
2025 , eprint=
PlanGEN: A Multi-Agent Framework for Generating Planning and Reasoning Trajectories for Complex Problem Solving , author=. 2025 , eprint=
2025
-
[12]
2025 , eprint=
On the Resilience of LLM-Based Multi-Agent Collaboration with Faulty Agents , author=. 2025 , eprint=
2025
-
[13]
Proximal policy optimization algorithms , author=. arXiv:1707.06347 , year=
-
[14]
Deep Reinforcement Learning from Human Preferences , volume =
Christiano, Paul F and Leike, Jan and Brown, Tom and Martic, Miljan and Legg, Shane and Amodei, Dario , booktitle =. Deep Reinforcement Learning from Human Preferences , volume =
-
[15]
2025 , month = nov, url =
2025
-
[16]
Training language models to follow instructions with human feedback , volume =
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul F and Leike, Jan and Lowe,...
-
[17]
2025 , month = aug, url =
2025
-
[18]
Fine-tuning language models from human preferences , author=. arXiv:1909.08593 , year=
Pith/arXiv arXiv 1909
-
[19]
2024 , eprint=
AgentMonitor: A Plug-and-Play Framework for Predictive and Secure Multi-Agent Systems , author=. 2024 , eprint=
2024
-
[20]
IEE proceedings F (Radar and Signal Processing) , volume=
Novel approach to nonlinear/non-Gaussian Bayesian state estimation , author=. IEE proceedings F (Radar and Signal Processing) , volume=
-
[21]
Machine Learning , volume=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine Learning , volume=. 1992 , publisher=
1992
-
[22]
Puri, Isha and Sudalairaj, Shivchander and Xu, Guangxuan and Bhandwaldar, Abhishek and Xu, Kai and Srivastava, Akash , booktitle =
-
[23]
Preventing rogue agents improves multi-agent collaboration , author=. arXiv:2502.05986 , year=
-
[24]
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik R Narasimhan and Yuan Cao , booktitle=
-
[25]
Hunter Lightman and Vineet Kosaraju and Yuri Burda and Harrison Edwards and Bowen Baker and Teddy Lee and Jan Leike and John Schulman and Ilya Sutskever and Karl Cobbe , booktitle=
-
[26]
Xiao Yu and Baolin Peng and Vineeth Vajipey and Hao Cheng and Michel Galley and Jianfeng Gao and Zhou Yu , booktitle=. Ex
-
[27]
Mastering chess and shogi by self-play with a general reinforcement learning algorithm , author=. arXiv:1712.01815 , year=
-
[28]
Proceedings of the 41st International Conference on Machine Learning , pages=
Language agent tree search unifies reasoning, acting, and planning in language models , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[29]
International Conference on Learning Representations , year=
Alexandre Pich\'. International Conference on Learning Representations , year=
-
[30]
Levine, Sergey , journal=
-
[31]
Zhiheng Xi and Jixuan Huang and Chenyang Liao and Baodai Huang and Honglin Guo and Jiaqi Liu and Rui Zheng and Junjie Ye and Jiazheng Zhang and Wenxiang Chen and Wei He and Yiwen Ding and Guanyu Li and Zehui Chen and Zhengyin Du and Xuesong Yao and Yufei Xu and Jiecao Chen and Tao Gui and Zuxuan Wu and Qi Zhang and Xuanjing Huang and Yu-Gang Jiang , journal=
-
[32]
A gent G ym: Evaluating and Training Large Language Model-based Agents across Diverse Environments
Xi, Zhiheng and Ding, Yiwen and Chen, Wenxiang and Hong, Boyang and Guo, Honglin and Wang, Junzhe and Guo, Xin and Yang, Dingwen and Liao, Chenyang and He, Wei and Gao, Songyang and Chen, Lu and Zheng, Rui and Zou, Yicheng and Gui, Tao and Zhang, Qi and Qiu, Xipeng and Huang, Xuanjing and Wu, Zuxuan and Jiang, Yu-Gang. A gent G ym: Evaluating and Training...
-
[33]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Xiao Bi and Haowei Zhang and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , journal=
-
[34]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo
-
[35]
ReflAct: World-Grounded Decision Making in LLM Agents via Goal-State Re- flection
Kim, Jeonghye and Rhee, Sojeong and Kim, Minbeom and Kim, Dohyung and Lee, Sangmook and Sung, Youngchul and Jung, Kyomin. Refl A ct: World-Grounded Decision Making in LLM Agents via Goal-State Reflection. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1697
-
[36]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Fleet of Agents: Coordinated Problem Solving with Large Language Models , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , volume =
2025
-
[37]
2020 , publisher=
Chopin, Nicolas and Papaspiliopoulos, Omiros and others , volume=. 2020 , publisher=
2020
-
[38]
Distilling the knowledge in a neural network , author=. arXiv:1503.02531 , year=
-
[39]
and Harada, Daishi and Russell, Stuart J
Ng, Andrew Y. and Harada, Daishi and Russell, Stuart J. , title =. Proceedings of the Sixteenth International Conference on Machine Learning , pages =. 1999 , isbn =
1999
-
[40]
Richard S. Sutton , title =. Machine Learning , year =. doi:10.1007/BF00115009 , issn =
-
[41]
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , volume =
Yao, Shunyu and Chen, Howard and Yang, John and Narasimhan, Karthik , booktitle =. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , volume =
-
[42]
Science W orld: Is your Agent Smarter than a 5th Grader?
Wang, Ruoyao and Jansen, Peter and C \^o t \'e , Marc-Alexandre and Ammanabrolu, Prithviraj. Science W orld: Is your Agent Smarter than a 5th Grader?. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.775
-
[43]
ADa PT : As-Needed Decomposition and Planning with Language Models
Prasad, Archiki and Koller, Alexander and Hartmann, Mareike and Clark, Peter and Sabharwal, Ashish and Bansal, Mohit and Khot, Tushar. ADa PT : As-Needed Decomposition and Planning with Language Models. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.264
-
[44]
RL with KL penalties is better viewed as B ayesian inference
Korbak, Tomasz and Perez, Ethan and Buckley, Christopher. RL with KL penalties is better viewed as B ayesian inference. Findings of the Association for Computational Linguistics: EMNLP 2022. 2022. doi:10.18653/v1/2022.findings-emnlp.77
-
[45]
Probabilistic Inference in Language Models via Twisted Sequential
Zhao, Stephen and Brekelmans, Rob and Makhzani, Alireza and Grosse, Roger Baker , booktitle =. Probabilistic Inference in Language Models via Twisted Sequential. 2024 , volume =
2024
-
[46]
The Thirteenth International Conference on Learning Representations , year=
Jo. The Thirteenth International Conference on Learning Representations , year=
-
[47]
Wang, Yiping and Yang, Qing and Zeng, Zhiyuan and Ren, Liliang and Liu, Liyuan and Peng, Baolin and Cheng, Hao and He, Xuehai and Wang, Kuan and Gao, Jianfeng and Chen, Weizhu and Wang, Shuohang and Du, Simon and shen, yelong , booktitle =
-
[48]
Pennino, Federico and Raimondi, Bianca and Rondelli, Massimo and Gurioli, Andrea and Gabbrielli, Maurizio , journal=
-
[49]
2025 , eprint=
Scaling Autonomous Agents via Automatic Reward Modeling And Planning , author=. 2025 , eprint=
2025
-
[50]
Toolformer: Language Models Can Teach Themselves to Use Tools , volume =
Schick, Timo and Dwivedi-Yu, Jane and Dessi, Roberto and Raileanu, Roberta and Lomeli, Maria and Hambro, Eric and Zettlemoyer, Luke and Cancedda, Nicola and Scialom, Thomas , booktitle =. Toolformer: Language Models Can Teach Themselves to Use Tools , volume =
-
[51]
An Yang and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoran Wei and Huan Lin and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and Jingren Zhou and Junyang Lin and Kai Dang and Keming Lu and Keqin Bao and Kexin Yang and Le Yu and Mei Li and Mi...
-
[52]
Aaron Grattafiori and others , journal=
-
[53]
2025 , howpublished=
2025
-
[54]
Proceedings of the 34th International Conference on Machine Learning , pages =
Reinforcement Learning with Deep Energy-Based Policies , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , volume =
2017
-
[55]
Proceedings of the 35th International Conference on Machine Learning , pages =
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , volume =
2018
-
[56]
doi:10.52202/079017-2365 , pages =
Ma, Chang and Zhang, Junlei and Zhu, Zhihao and Yang, Cheng and Yang, Yujiu and Jin, Yaohui and Lan, Zhenzhong and Kong, Lingpeng and He, Junxian , booktitle =. doi:10.52202/079017-2365 , pages =
-
[57]
Statistics and Computing , year =
Arnaud Doucet and Simon Godsill and Christophe Andrieu , title =. Statistics and Computing , year =. doi:10.1023/A:1008935410038 , issn =
-
[58]
2004 , publisher=
Feynman-Kac formulae: genealogical and interacting particle systems with applications , author=. 2004 , publisher=
2004
-
[59]
Signal Processing Group, Department of Engineering, University of Cambridge, Technical Report CUEDIF-INFENGrrR38 , volume=
Convergence of sequential Monte Carlo methods , author=. Signal Processing Group, Department of Engineering, University of Cambridge, Technical Report CUEDIF-INFENGrrR38 , volume=
-
[60]
The Annals of Statistics , volume=
Finite-sample complexity of sequential Monte Carlo estimators , author=. The Annals of Statistics , volume=. 2023 , publisher=
2023
-
[61]
International Conference on Machine Learning , pages=
Is Best-of-N the Best of Them? Coverage, Scaling, and Optimality in Inference-Time Alignment , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.