Minimizing the Hidden Cost of Scales: Graph-Guided Ultra-Low-Bit Quantization for Large Language Models
Pith reviewed 2026-06-28 06:07 UTC · model grok-4.3
The pith
SAGE-PTQ cuts average LLM weight bits to 1.03 and scaling bits to 0.004 by separating salient weights via distributional statistics and modeling unsalient weights as a sparse graph to set group counts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SAGE-PTQ separates salient and unsalient weights using distributional statistics, models subsampled unsalient weights as a sparse graph to estimate the optimal number of groups per layer, applies dual-mode quantization with multi-bit precision on salient weights and binarization on unsalient weights, employs one per-channel scale for salient weights and one scalar per unsalient group, and uses adaptive saliency thresholding; the result is an average of 1.03 weight bits and 0.004 scaling bits per matrix, with 6.74 WikiText2 perplexity on LLaMA-3-8B versus 55.8 for BiLLM and under 50 percent of BiLLM's GPU memory, plus 1.5x faster decoding on LLaMA-2-70B.
What carries the argument
Saliency-aware graph-guided group estimation that models unsalient weights as a sparse graph to determine per-layer group counts while keeping one scalar scale per group.
If this is right
- Models quantized with SAGE-PTQ fit in less than half the GPU memory of BiLLM while maintaining usable perplexity.
- Decoding speed on a single NVIDIA L40 GPU increases by 1.5x for 70B-scale models compared with prior ultra-low-bit methods.
- The per-matrix adaptive threshold removes the need for manual saliency ratio tuning across layers.
- Only one scale factor per unsalient group replaces the multiple scales required by earlier group-wise methods.
Where Pith is reading between the lines
- The graph-modeling step could be replaced by a cheaper heuristic if the optimal group count correlates strongly with simple statistics such as weight variance.
- Extending the same separation logic to activation quantization might further reduce total inference cost without retraining.
- The reported memory savings suggest the method could enable running 70B models on consumer GPUs that previously handled only 7B models.
Load-bearing premise
Distributional statistics can reliably identify which weights are salient versus unsalient and that a sparse graph on the unsalient subset yields group counts that preserve final model quality.
What would settle it
Running SAGE-PTQ on LLaMA-3-8B and measuring WikiText2 perplexity above 10 or average scaling bits above 0.01 would show the claimed bit rates and quality cannot be reached simultaneously.
Figures




read the original abstract
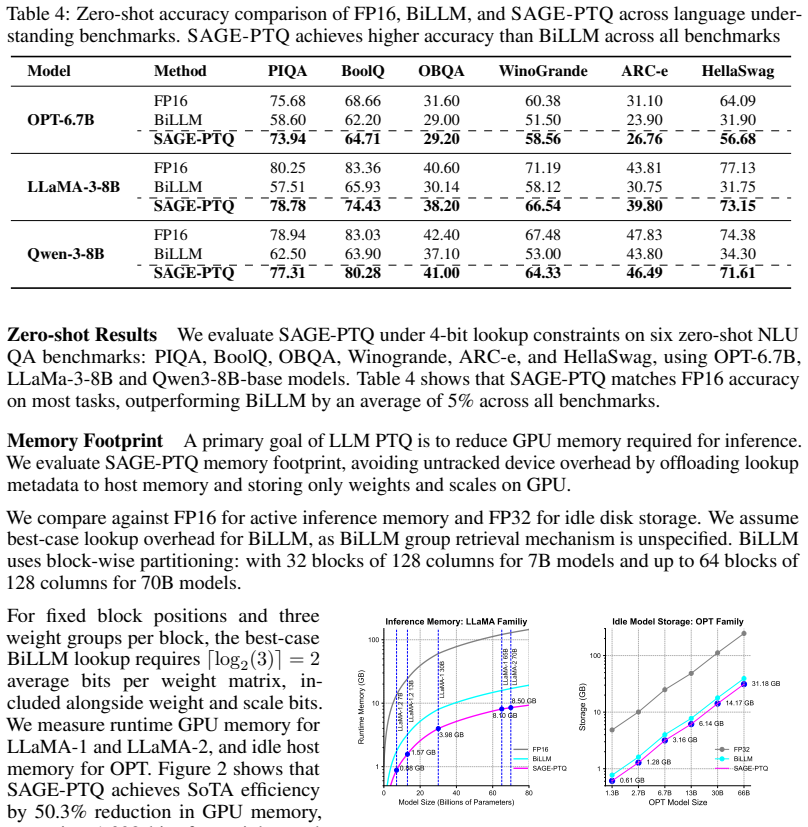
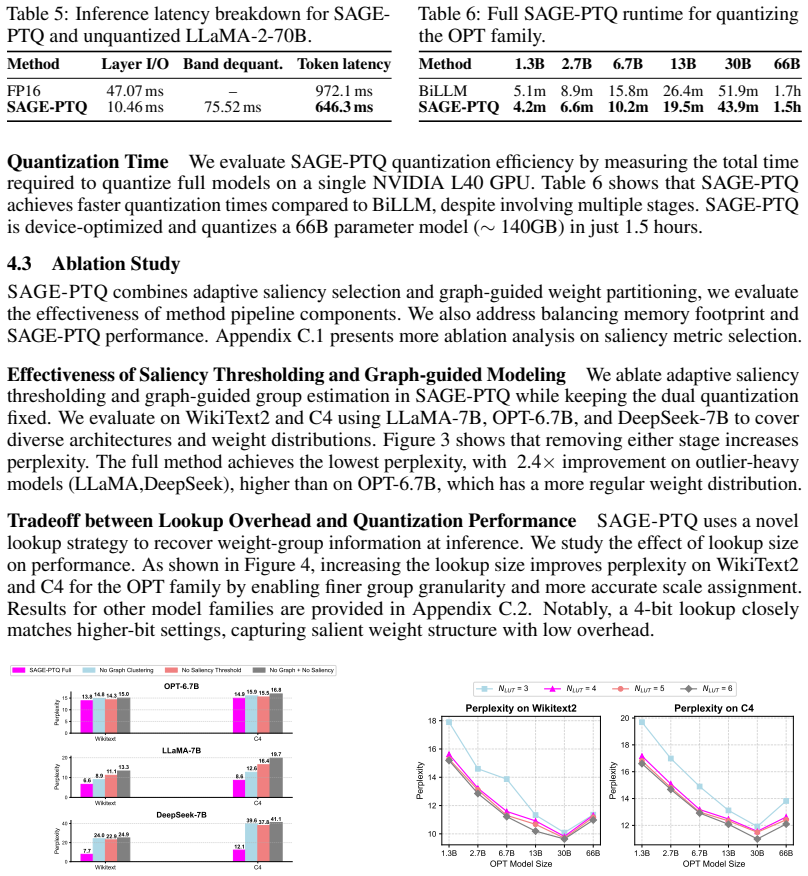
Post-training quantization (PTQ) is critical for the efficient deployment of large language models (LLMs). Recent ultra-low-bit PTQ methods rely on rigid weight-saliency assumptions or position heuristics, introducing substantial hidden scaling overhead. We propose SAGE-PTQ (Saliency-Aware Graph-guided Efficient PTQ), a novel ultra-low-bit quantization framework for LLMs that minimizes hidden scaling cost. SAGE-PTQ separates salient and unsalient weights using distributional statistics, then models subsampled unsalient weights as a sparse graph to estimate the optimal number of groups per layer. SAGE-PTQ applies dual-mode quantization, assigning multi-bit precision to salient weights and binarizing unsalient weights. To reduce scaling overhead, SAGE-PTQ uses one per-channel scale for salient weights and one scalar per unsalient group. Finally, SAGE-PTQ implements adaptive saliency thresholding to select the optimal saliency ratio per matrix. SAGE-PTQ achieves 1.03 weight bits and only 0.004 scaling bits per matrix on average, outperforming state-of-the-art methods such as BiLLM and PB-LLM. On LLaMA-3-8B, SAGE-PTQ achieves 6.74 WikiText2 perplexity, compared to 55.8 for BiLLM, while using less than 50% of BiLLM's GPU memory. On LLaMA-2-70B, SAGE-PTQ provides 1.5x faster decoding on one NVIDIA L40 GPU, demonstrating practical inference efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SAGE-PTQ, a post-training quantization framework for LLMs that separates salient and unsalient weights using distributional statistics, models the unsalient subset as a sparse graph to estimate per-layer group counts, applies dual-mode quantization (multi-bit for salient weights, binary for unsalient), and reduces scaling overhead via one per-channel scale for salient weights and one scalar per unsalient group, plus adaptive saliency thresholding. It reports average 1.03 weight bits and 0.004 scaling bits per matrix, with LLaMA-3-8B achieving 6.74 WikiText2 perplexity (vs. 55.8 for BiLLM) and efficiency gains on LLaMA-2-70B.
Significance. If the empirical results and underlying assumptions hold under rigorous validation, the work would be significant for ultra-low-bit LLM quantization by directly targeting hidden scaling costs, a practical bottleneck in prior methods like BiLLM. The graph-guided group estimation offers a potentially parameter-light way to control overhead while preserving quality, which could influence deployment strategies if the separation and estimation steps prove robust across models.
major comments (2)
- [Experimental Results] Experimental Results section: The headline claims (1.03 weight bits, 0.004 scaling bits, 6.74 WikiText2 PPL on LLaMA-3-8B vs. 55.8 for BiLLM) are presented without error bars, run counts, or explicit baseline re-implementation details and ablation tables; this directly affects verifiability of the dual-mode scheme's quality preservation at the reported bit rates.
- [Method] Method section on sparse-graph group estimation: The central claim that distributional statistics cleanly partition weights and that the sparse-graph model on subsampled unsalient weights yields an accurate per-layer group count (enabling the 0.004 scaling-bit overhead) lacks any comparison to exhaustive search or ablation showing that the derived group numbers match those that would minimize quantization error without quality degradation.
minor comments (1)
- [Method] The description of adaptive saliency thresholding would benefit from an explicit equation or pseudocode for how the optimal saliency ratio per matrix is selected, as the current prose leaves the decision criterion implicit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on improving the verifiability of our empirical claims and the validation of the sparse-graph group estimation. We provide point-by-point responses to the major comments below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: The headline claims (1.03 weight bits, 0.004 scaling bits, 6.74 WikiText2 PPL on LLaMA-3-8B vs. 55.8 for BiLLM) are presented without error bars, run counts, or explicit baseline re-implementation details and ablation tables; this directly affects verifiability of the dual-mode scheme's quality preservation at the reported bit rates.
Authors: Post-training quantization is a deterministic process once calibration data and hyperparameters are fixed, which is standard in the field and explains the absence of error bars or multiple run counts. We agree, however, that explicit details on baseline re-implementations and additional ablation tables would strengthen verifiability. In the revised manuscript we will add a dedicated subsection describing how BiLLM and PB-LLM were re-implemented (including calibration settings and code availability) and include new ablation tables on the dual-mode quantization components. The reported numbers remain unchanged as they were obtained under the documented protocol. revision: partial
-
Referee: [Method] Method section on sparse-graph group estimation: The central claim that distributional statistics cleanly partition weights and that the sparse-graph model on subsampled unsalient weights yields an accurate per-layer group count (enabling the 0.004 scaling-bit overhead) lacks any comparison to exhaustive search or ablation showing that the derived group numbers match those that would minimize quantization error without quality degradation.
Authors: Exhaustive search over per-layer group counts is computationally prohibitive for models at the scale of LLaMA-70B. The sparse-graph model is presented as an efficient, structure-aware approximation rather than an exact optimizer. To address the concern we will add an ablation study on smaller models (LLaMA-7B and LLaMA-13B) that compares the group counts produced by the graph estimator against those obtained via grid search minimizing per-layer quantization error. The results of this comparison, together with the corresponding perplexity impact, will be reported in the revised Method and Experiments sections. revision: yes
Circularity Check
No circularity; method is an independent algorithmic construction
full rationale
The provided abstract and description contain no equations, derivations, or self-citations that reduce any claimed result to its own inputs by construction. Separation of salient/unsalient weights via distributional statistics, sparse-graph group estimation, dual-mode quantization, and adaptive thresholding are presented as procedural choices whose outputs are validated empirically on perplexity and bit-rate metrics. No fitted parameter is relabeled as a prediction, no uniqueness theorem is imported from prior self-work, and no ansatz is smuggled via citation. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Kantharaj Dewan, et al. Opt: Open pre-trained transformer language models.arXiv preprint arXiv:2205.01068, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Sergey Bashlykov, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Deepseek-vl: Scaling vision-language models with decoupled pretraining
DeepSeek AI. Deepseek-vl: Scaling vision-language models with decoupled pretraining. https:// github.com/deepseek-ai, 2024. Accessed: 2024-07-25
2024
-
[6]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique de Oliveira Pinto, Jared Kaplan, Harri Edwards, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.arXiv preprint arXiv:2201.11903, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
OpenAI. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Abq-llm: Arbitrary-bit quantized inference acceleration for large language models
Chao Zeng, Songwei Liu, Yusheng Xie, Hong Liu, Xiaojian Wang, Miao Wei, Shu Yang, Fangmin Chen, and Xing Mei. Abq-llm: Arbitrary-bit quantized inference acceleration for large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 22299–22307, 2025
2025
-
[10]
Post-training quantization for vision transformer.arXiv preprint arXiv:2208.13555, 2022
Xing Liu, Zhenhua Zhang, Qinghao Ye, Yiren Lin, Xiangyu Zhang, and Jian Sun. Post-training quantization for vision transformer.arXiv preprint arXiv:2208.13555, 2022
-
[11]
arXiv preprint arXiv:1909.10351 , year=
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. Tinybert: Distilling bert for natural language understanding.arXiv preprint arXiv:1909.10351, 2019
-
[13]
Dynamic sparse attention for scalable transformer acceleration.arXiv preprint arXiv:2301.11270, 2023
Zhuohan Ma and et al. Dynamic sparse attention for scalable transformer acceleration.arXiv preprint arXiv:2301.11270, 2023
-
[14]
Knowledge distillation: A survey
Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. Knowledge distillation: A survey. International Journal of Computer Vision, 129:1789–1819, 2021
2021
-
[15]
Lewis Tunstall, Leandro von Werra, and Thomas Wolf. Efficient language model distillation using hugging face transformers.arXiv preprint arXiv:2301.11734, 2023
-
[16]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Llm.int8(): 8-bit matrix multiplication for transformers at scale.arXiv preprint arXiv:2208.07339, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Ziheng Xiao, Ren Yan, Shaohuai Wang, Zhe Wei, Ang Li, Mingyu Zhang, Xiaowei Li, and Yiying Wang. Smoothquant: Accurate and efficient post-training quantization for large language models.arXiv preprint arXiv:2211.10438, 2023
-
[18]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
2024
-
[20]
Pb-llm: Partially binarized large language models.arXiv preprint arXiv:2310.00034, 2023
Yuzhang Shang, Zhihang Yuan, Qiang Wu, and Zhen Dong. Pb-llm: Partially binarized large language models.arXiv preprint arXiv:2310.00034, 2023. 10
-
[21]
Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, and Xi- aojuan Qi. Billm: Pushing the limit of post-training quantization for llms.arXiv preprint arXiv:2402.04291, 2024
-
[22]
Up or down? adaptive rounding for post-training quantization
Markus Nagel, Rana Ali Amjad, Mart Van Baalen, Christos Louizos, and Tijmen Blankevoort. Up or down? adaptive rounding for post-training quantization. InInternational conference on machine learning, pages 7197–7206. PMLR, 2020
2020
-
[23]
Yuhang Li, Ruihao Gong, Xu Tan, Yang Yang, Peng Hu, Qi Zhang, Fengwei Yu, Wei Wang, and Shi Gu. Brecq: Pushing the limit of post-training quantization by block reconstruction.arXiv preprint arXiv:2102.05426, 2021
-
[24]
Zeroquant: Efficient and affordable post-training quantization for large-scale transformers.Advances in neural information processing systems, 35:27168–27183, 2022
Zhewei Yao, Reza Yazdani Aminabadi, Minjia Zhang, Xiaoxia Wu, Conglong Li, and Yuxiong He. Zeroquant: Efficient and affordable post-training quantization for large-scale transformers.Advances in neural information processing systems, 35:27168–27183, 2022
2022
-
[25]
Albert Tseng, Jerry Chee, Qingyao Sun, V olodymyr Kuleshov, and Christopher De Sa. Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks.arXiv preprint arXiv:2402.04396, 2024
-
[26]
Sqpr: Stream query planning with reuse
Evangelia Kalyvianaki, Wolfram Wiesemann, Quang Hieu Vu, Daniel Kuhn, and Peter Pietzuch. Sqpr: Stream query planning with reuse. In2011 IEEE 27th International Conference on Data Engineering, pages 840–851. IEEE, 2011
2011
-
[27]
arXiv preprint arXiv:2306.07629 , year=
Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W Mahoney, and Kurt Keutzer. Squeezellm: Dense-and-sparse quantization.arXiv preprint arXiv:2306.07629, 2023
-
[28]
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. Omniquant: Omnidirectionally calibrated quantization for large language models.arXiv preprint arXiv:2308.13137, 2023
-
[29]
Reena Elangovan, Charbel Sakr, Anand Raghunathan, and Brucek Khailany. Bcq: Block clustered quantization for 4-bit (w4a4) llm inference.arXiv preprint arXiv:2502.05376, 2025
-
[30]
Hawq: Hessian aware quantization of neural networks with mixed-precision
Zhen Dong, Zhewei Yao, Amir Gholami, Michael W Mahoney, and Kurt Keutzer. Hawq: Hessian aware quantization of neural networks with mixed-precision. InProceedings of the IEEE/CVF international conference on computer vision, pages 293–302, 2019
2019
-
[31]
Xiuying Wei, Ruihao Gong, Yuhang Li, Xianglong Liu, and Fengwei Yu. Qdrop: Randomly dropping quantization for extremely low-bit post-training quantization.arXiv preprint arXiv:2203.05740, 2022
-
[32]
Self-tuning spectral clustering.Advances in neural information processing systems, 17:1601–1608, 2005
Lihi Zelnik-Manor and Pietro Perona. Self-tuning spectral clustering.Advances in neural information processing systems, 17:1601–1608, 2005
2005
-
[33]
On spectral clustering: Analysis and an algorithm
Andrew Y Ng, Michael I Jordan, and Yair Weiss. On spectral clustering: Analysis and an algorithm. Advances in neural information processing systems, 14:849–856, 2002
2002
-
[34]
A tutorial on spectral clustering.Statistics and computing, 17(4):395–416, 2007
Ulrike von Luxburg. A tutorial on spectral clustering.Statistics and computing, 17(4):395–416, 2007
2007
-
[35]
Silhouettes: a graphical aid to the interpretation and validation of cluster analysis
Peter J Rousseeuw. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Journal of computational and applied mathematics, 20:53–65, 1987
1987
-
[36]
Compressing deep convolutional networks using vector quantization
Yunchao Gong, Liu Liu, Ming Yang, and Lubomir Bourdev. Compressing deep convolutional networks using vector quantization. InInternational Conference on Learning Representations (ICLR), 2014
2014
-
[37]
Clip-q: Deep network compression learning by in-parallel pruning- quantization
Frederick Tung and Greg Mori. Clip-q: Deep network compression learning by in-parallel pruning- quantization. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7873–7882, 2018
2018
-
[38]
Bi-vlm: Pushing ultra-low precision post-training quantization boundaries in vision-language models
Xijun Wang, Junyun Huang, Rayyan Abdalla, Chengyuan Zhang, Ruiqi Xian, and Dinesh Manocha. Bi-vlm: Pushing ultra-low precision post-training quantization boundaries in vision-language models. arXiv preprint arXiv:2509.18763, 2025
-
[39]
Towards superior quantization accuracy: A layer-sensitive approach.arXiv e-prints, pages arXiv–2503, 2025
Feng Zhang, Yanbin Liu, Weihua Li, Jie Lv, Xiaodan Wang, and Quan Bai. Towards superior quantization accuracy: A layer-sensitive approach.arXiv e-prints, pages arXiv–2503, 2025
2025
-
[40]
Courier Corporation, 2013
Richard P Brent.Algorithms for minimization without derivatives. Courier Corporation, 2013. 11
2013
-
[41]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[42]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Huggingface’s transformers: State-of-the-art natural language processing.arXiv preprint arXiv:1910.03771, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[43]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
2024
-
[44]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna
Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023
2023
-
[45]
Qwen2.5: A party of foundation models
Qwen Team. Qwen2.5: A party of foundation models. https://qwenlm.github.io/blog/qwen2.5/,
-
[46]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. In arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[48]
Exploring the limits of transfer learning with a unified text-to-text transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 2020
2020
-
[49]
Piqa: Reasoning about physi- cal commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physi- cal commonsense in natural language. InProceedings of the AAAI Conference on Artificial Intelligence, 2020
2020
-
[50]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark and Kenton Lee. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, 2019
2019
-
[51]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018
2018
-
[52]
Winogrande: An adversarial winograd schema challenge at scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. InProceedings of the AAAI Conference on Artificial Intelligence, 2021
2021
-
[53]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark and Oren Etzioni. Think you have solved question answering? try arc, the ai2 reasoning challenge. InarXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[54]
Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
2019
-
[55]
The penn treebank: Annotating predicate argument structure
Mitchell P Marcus, Mary Ann Marcinkiewicz, and Beatrice Santorini. The penn treebank: Annotating predicate argument structure. InHuman Language Technology, 1994. 12 A Statistical Analysis of Weight Matrices and Outlier Pattern Detection Efficient post-training quantization for large language models (LLMs) demands careful modeling of weight matrix statisti...
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.