The Cascade Log: Reference-Stable Windowing over Tiered Append Sequences
Pith reviewed 2026-06-28 03:11 UTC · model grok-4.3
The pith
The Cascade Log maintains a single coalescing interval map over handles as the sole authority on live versions in tiered append sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
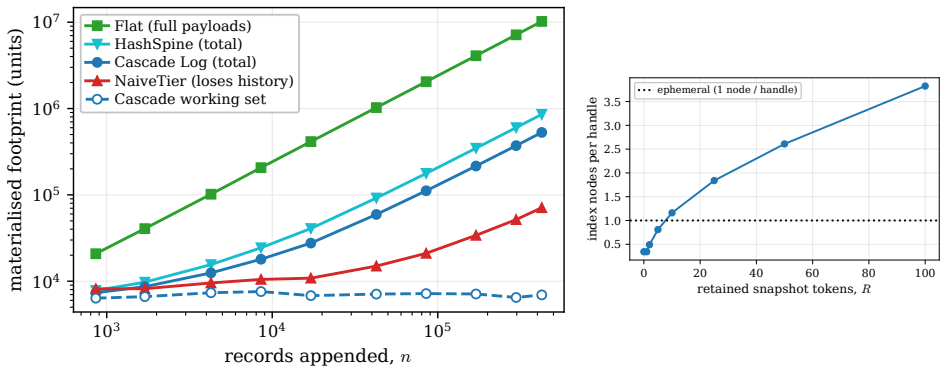
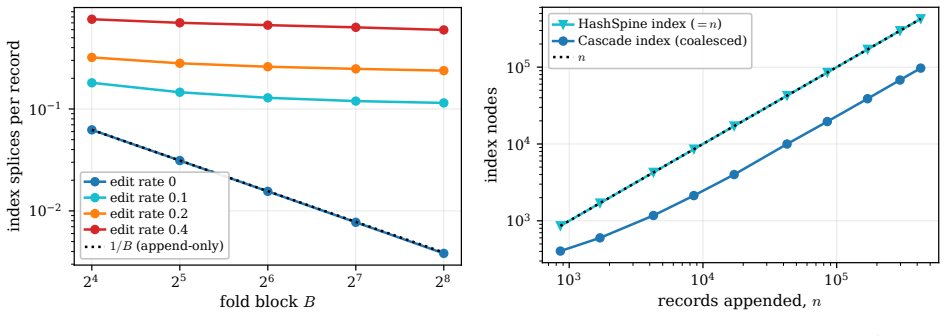
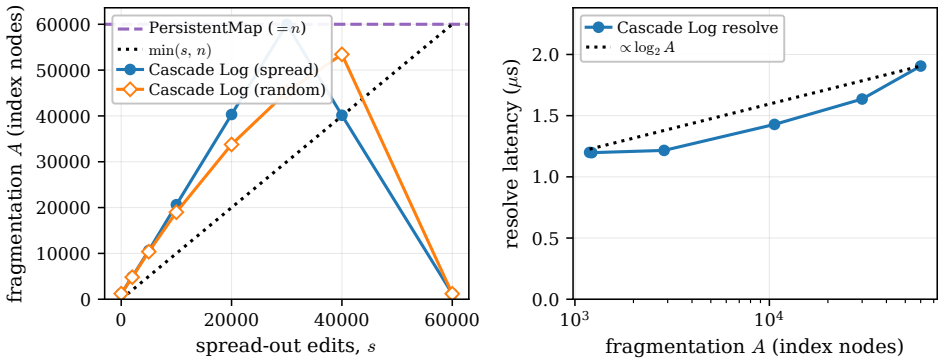
The Cascade Log keeps a single persistent coalescing interval map over handles as the sole authority on each live version; folding a contiguous run replaces many singleton entries by one digest-backed interval node, and immutable roots provide snapshot tokens. Its cost is characterized by the fragmentation A, the number of index pieces, namely live handles plus maximal same-digest runs. The index uses Θ(A) space, resolves a point in O(log A), reports a k-handle range in O(log A+k), and performs a appends and s supersedes in O((a/B+s)log A) update work for fold block size B. Matching lower bounds show that Ω(A) space and Ω(log A+k) ordered range cost are unavoidable, and an adversary can forc
What carries the argument
A single persistent coalescing interval map over handles that serves as the sole authority on live versions, folding contiguous runs into digest-backed interval nodes while immutable roots act as snapshot tokens.
If this is right
- Space usage remains Θ(A) where A counts live handles plus maximal same-digest runs.
- Point resolution costs O(log A) and ordered k-handle range reporting costs O(log A + k).
- a appends and s supersedes together cost O((a/B + s) log A) for fold block size B.
- Matching lower bounds establish that Ω(A) space and Ω(log A + k) range cost are required in the worst case.
- An adversary can force A = Θ(s), so cost grows linearly only under fragmenting supersedes.
Where Pith is reading between the lines
- The same map could supply stable iterators for other tiered structures such as LSM trees or versioned key-value stores.
- Tracking A at runtime would give an online signal for when to perform folds or compaction.
- Immutable roots could be extended to support multi-version concurrency control without extra coordination.
Load-bearing premise
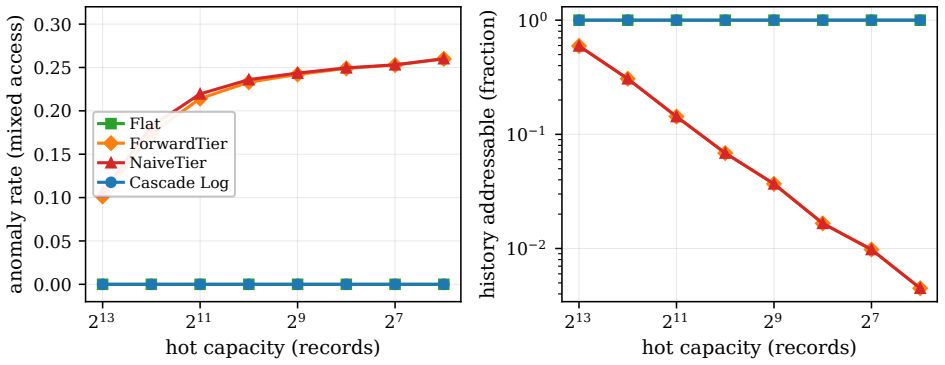
The coalescing interval map eliminates all four cross-tier anomalies and the fragmentation count A captures every operational cost without hidden overheads from the tiering process.
What would settle it
An execution in which a handle minted on hot data returns a dangling, stale, corrupt, or snapshot-skewed result after a fold, or where observed space or update cost exceeds the stated Θ(A) and O((a/B+s)log A) bounds by more than a constant factor.
Figures





read the original abstract
A long-running append-mostly sequence, such as an edit log, event store, or versioned working set, is usually tiered into a bounded hot stratum and colder folded summaries. This saves memory but breaks stable references: a handle minted while a record is hot may later be resolved after the record has moved into a digest, after it has been superseded, or while a fold is in flight. We define the resulting cross-tier anomalies--dangling, stale, corrupt, and snapshot-skewed resolution--and present the Cascade Log, a reference-stable tiered append structure. The structure keeps a single persistent coalescing interval map over handles as the sole authority on each live version; folding a contiguous run replaces many singleton entries by one digest-backed interval node, and immutable roots provide snapshot tokens. Its cost is characterized by the fragmentation $A$, the number of index pieces, namely live handles plus maximal same-digest runs. The index uses $\Theta(A)$ space, resolves a point in $O(\log A)$, reports a $k$-handle range in $O(\log A+k)$, and performs $a$ appends and $s$ supersedes in $O((a/B+s)\log A)$ update work for fold block size $B$. Matching lower bounds show that $\Omega(A)$ space and $\Omega(\log A+k)$ ordered range cost are unavoidable, and an adversary can force $A=\Theta(s)$. Thus the index is sublinear on append-dominated histories and grows linearly only under fragmenting edits. A reference implementation and reproducible experiments to $10^6$ records validate the anomaly-freedom and the fragmentation bounds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the Cascade Log, a reference-stable tiered append structure for long-running append-mostly sequences such as edit logs and event stores. It defines four cross-tier anomalies (dangling, stale, corrupt, and snapshot-skewed resolution) and claims that a single persistent coalescing interval map over handles serves as the sole authority on each live version. Folding a contiguous run replaces many singleton entries with one digest-backed interval node, while immutable roots provide snapshot tokens. Costs are characterized by the fragmentation measure A (live handles plus maximal same-digest runs): the index uses Θ(A) space, resolves a point in O(log A), reports a k-handle range in O(log A + k), and performs a appends and s supersedes in O((a/B + s) log A) for fold block size B. Matching lower bounds establish that Ω(A) space and Ω(log A + k) ordered range cost are unavoidable, with an adversary forcing A = Θ(s). A reference implementation and reproducible experiments to 10^6 records are provided to validate anomaly-freedom and the fragmentation bounds.
Significance. If the claims hold, the result is significant for data structures supporting versioned and append-dominated workloads, as it achieves reference stability across hot/cold tiers while remaining sublinear in space and query cost on append-heavy histories and only linear under fragmenting edits. The explicit matching lower bounds and the direct validation via reference implementation plus experiments to 10^6 records are strengths that ground the anomaly-freedom and A-based cost claims. The structural definition of A as live handles plus maximal same-digest runs, together with the adversary argument for tightness, avoids circularity and provides a clean characterization.
minor comments (2)
- [Abstract] Abstract: the fold block size B appears in the update complexity bound without a preceding definition or parenthetical; a brief inline clarification would improve readability for readers encountering the bound for the first time.
- The manuscript would benefit from an illustrative figure or small example showing the coalescing interval map state before and after a fold operation, to make the replacement of singleton entries by digest-backed interval nodes concrete.
Simulated Author's Rebuttal
We thank the referee for the detailed and positive summary of our work on the Cascade Log. The recommendation for minor revision is appreciated, and we note that the report contains no enumerated major comments requiring point-by-point rebuttal.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines fragmentation A directly as the count of live handles plus maximal same-digest runs in its coalescing interval map, then states that the index occupies Θ(A) space and supports the listed query/update bounds in terms of A. Matching lower bounds are presented as information-theoretic necessities on any structure that must track the same live versions and digest runs, with an adversary argument showing A=Θ(s) under supersedes; these are not reductions to fitted parameters or self-referential equations. The central claims rest on the explicit construction, the anomaly definitions, and external validation via reference implementation plus experiments to 10^6 records rather than on self-citation chains or ansatzes imported from prior author work. No load-bearing step equates a derived quantity to its own input by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Append-mostly sequences can be tiered into a bounded hot stratum and colder folded summaries while still requiring stable reference resolution across tiers.
invented entities (1)
-
coalescing interval map
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Alok Aggarwal and Jeffrey Scott Vitter. The input/output complexity of sorting and related problems.Communi- cations of the ACM, 31(9):1116–1127, 1988. doi: 10.1145/48529.48535
-
[2]
RudolfBayerandEdwardM.McCreight. Organizationandmaintenanceoflargeorderedindexes.ActaInformatica, 1(3):173–189, 1972. doi: 10.1007/BF00288683
-
[3]
Paul Beame and Faith E. Fich. Optimal bounds for the predecessor problem and related problems.Journal of Computer and System Sciences, 65(1):38–72, 2002. doi: 10.1006/jcss.2002.1822
-
[4]
An asymptotically optimal multiversion B-tree.The VLDB Journal, 5(4):264–275, 1996
Bruno Becker, Stephan Gschwind, Thomas Ohler, Bernhard Seeger, and Peter Widmayer. An asymptotically optimal multiversion B-tree.The VLDB Journal, 5(4):264–275, 1996. doi: 10.1007/s007780050028. 20 Table 3:Result files and the artifacts they produce. File (anc/results/) Artifact headline.csvTable 1 anomaly_vs_capacity.csvFigure 2 scaling.csvFigure 3, Figu...
-
[5]
Jon Louis Bentley and James B. Saxe. Decomposable searching problems I: Static-to-dynamic transformation. Journal of Algorithms, 1(4):301–358, 1980. doi: 10.1016/0196-6774(80)90015-2
-
[6]
Philip A. Bernstein and Nathan Goodman. Multiversion concurrency control—theory and algorithms.ACM Transactions on Database Systems, 8(4):465–483, 1983. doi: 10.1145/319996.319998
-
[7]
Burton H. Bloom. Space/time trade-offs in hash coding with allowable errors.Communications of the ACM, 13 (7):422–426, 1970. doi: 10.1145/362686.362692
-
[8]
Boehm, Russ Atkinson, and Michael Plass
Hans-J. Boehm, Russ Atkinson, and Michael Plass. Ropes: An alternative to strings.Software: Practice and Experience, 25(12):1315–1330, 1995. doi: 10.1002/spe.4380251203
-
[9]
Sergey Brin and Lawrence Page. The anatomy of a large-scale hypertextual Web search engine.Computer Networks and ISDN Systems, 30(1–7):107–117, 1998. doi: 10.1016/S0169-7552(98)00110-X
-
[10]
Lower bounds for external memory dictionaries
Gerth Stølting Brodal and Rolf Fagerberg. Lower bounds for external memory dictionaries. InProceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 546–554, 2003
2003
-
[11]
Bernard Chazelle and Leonidas J. Guibas. Fractional cascading: I. a data structuring technique.Algorithmica, 1 (2):133–162, 1986. doi: 10.1007/BF01840440
-
[12]
The ubiquitous B-tree.ACM Computing Surveys, 11(2):121–137, 1979
Douglas Comer. The ubiquitous B-tree.ACM Computing Surveys, 11(2):121–137, 1979. doi: 10.1145/356770. 356776
-
[13]
Makingdatastructurespersistent.Journal of Computer and System Sciences, 38(1):86–124, 1989
JamesR.Driscoll,NeilSarnak,DanielD.Sleator,andRobertE.Tarjan. Makingdatastructurespersistent.Journal of Computer and System Sciences, 38(1):86–124, 1989. doi: 10.1016/0022-0000(89)90034-2
-
[14]
Taher H. Haveliwala. Topic-sensitive PageRank: A context-sensitive ranking algorithm for Web search.IEEE Transactions on Knowledge and Data Engineering, 15(4):784–796, 2003. doi: 10.1109/TKDE.2003.1208999
-
[15]
Linearizability: a correctness condition for concurrent objects,
Maurice P. Herlihy and Jeannette M. Wing. Linearizability: A correctness condition for concurrent objects.ACM Transactions on Programming Languages and Systems, 12(3):463–492, 1990. doi: 10.1145/78969.78972
-
[16]
The budgeted maximum coverage problem.Information Processing Letters, 70(1):39–45, 1999
Samir Khuller, Anna Moss, and Joseph (Seffi) Naor. The budgeted maximum coverage problem.Information Processing Letters, 70(1):39–45, 1999. doi: 10.1016/S0020-0190(99)00031-9
-
[17]
Eugene W. Myers. An O(ND) difference algorithm and its variations.Algorithmica, 1(1–4):251–266, 1986. doi: 10.1007/BF01840446
-
[18]
GeorgeL.Nemhauser,LaurenceA.Wolsey,andMarshallL.Fisher. Ananalysisofapproximationsformaximizing submodular set functions—I.Mathematical Programming, 14(1):265–294, 1978. doi: 10.1007/BF01588971. 21
-
[19]
The log-structured merge-tree (LSM-tree)
Patrick O’Neil, Edward Cheng, Dieter Gawlick, and Elizabeth O’Neil. The log-structured merge-tree (LSM-tree). Acta Informatica, 33(4):351–385, 1996. doi: 10.1007/s002360050048
-
[20]
William Pugh. Skip lists: A probabilistic alternative to balanced trees.Communications of the ACM, 33(6): 668–676, 1990. doi: 10.1145/78973.78977
-
[21]
Time-space trade-offs for predecessor search
Mihai Pˇatraşcu and Mikkel Thorup. Time-space trade-offs for predecessor search. InProceedings of the Thirty-Eighth Annual ACM Symposium on Theory of Computing (STOC), pages 232–240, 2006. doi: 10.1145/ 1132516.1132551
arXiv 2006
-
[22]
Betty Salzberg and Vassilis J. Tsotras. Comparison of access methods for time-evolving data.ACM Computing Surveys, 31(2):158–221, 1999. doi: 10.1145/319806.319816
-
[23]
Neil Sarnak and Robert E. Tarjan. Planar point location using persistent search trees.Communications of the ACM, 29(7):669–679, 1986. doi: 10.1145/6138.6151
-
[24]
Raimund Seidel and Cecilia R. Aragon. Randomized search trees.Algorithmica, 16(4–5):464–497, 1996. doi: 10.1007/BF01940876
-
[25]
Daniel D. Sleator and Robert E. Tarjan. Amortized efficiency of list update and paging rules.Communications of the ACM, 28(2):202–208, 1985. doi: 10.1145/2786.2793
-
[26]
Sleator and Robert E
Daniel D. Sleator and Robert E. Tarjan. Self-adjusting binary search trees.Journal of the ACM, 32(3):652–686,
-
[27]
doi: 10.1145/3828.3835
-
[28]
Robert E. Tarjan. Amortized computational complexity.SIAM Journal on Algebraic and Discrete Methods, 6(2): 306–318, 1985. doi: 10.1137/0606031. 22
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.