FlowPRO: Reward-Free Reinforced Fine-Tuning of Flow-Matching VLAs via Proximalized Preference Optimization
Pith reviewed 2026-06-28 05:36 UTC · model grok-4.3
The pith
FlowPRO fine-tunes flow-matching VLAs on real robots from preference pairs collected via human interventions alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
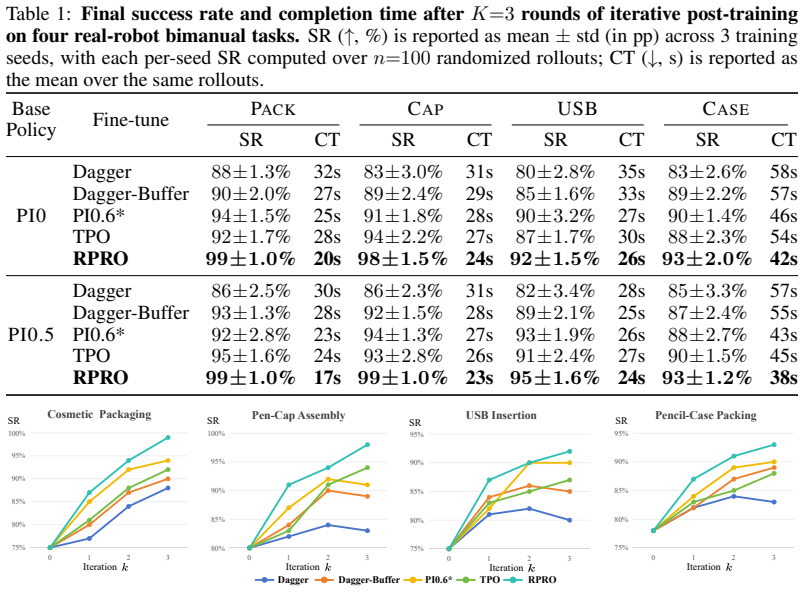
FlowPRO is a reward-free offline framework that applies RPRO (Robotic Flow-matching Proximalized Preference Optimization) to the flow-matching action head of VLA models. RPRO combines a contrastive preference term with an explicit proximal regularizer that fixes the scale of the implicit reward. Paired trajectories are gathered on a physical robot by a single teleoperator who intervenes and rolls back on failure; Smooth Interpolation plus batch mixing converts the sparse pairs into dense per-state supervision without degrading base capabilities. On four long-horizon bimanual tasks the resulting policy records the highest success rate among four representative baselines.
What carries the argument
RPRO objective: a contrastive optimizer paired with an explicit proximal regularizer that anchors the absolute magnitude of the implicit reward inside the flow-matching action head.
If this is right
- Flow-matching VLAs can receive reinforced updates from offline preference data without any hand-crafted reward function.
- A single operator's intervention-and-rollback actions suffice to generate training pairs that improve long-horizon bimanual performance.
- Each component of the RPRO loss (contrastive term, proximal regularizer, and data interpolation) contributes measurably to final success rate.
- The same pipeline outperforms standard SFT, DAgger, and plain Flow-DPO on the reported tasks.
Where Pith is reading between the lines
- The intervention paradigm could be reused with other generative action heads that admit an implicit reward formulation.
- Because the method stays fully offline, it may scale to larger robot fleets where online reward signals remain impractical.
- The proximal anchoring step might generalize to other preference-optimization settings that suffer from reward-scale drift.
Load-bearing premise
The Smooth Interpolation procedure combined with batch mixing converts these sparse corrections into dense per-state supervision while preserving the base policy's capabilities.
What would settle it
Running the same four long-horizon bimanual tasks and finding that FlowPRO does not achieve the highest success rate, or that removing the proximal regularizer produces no measurable difference in performance.
Figures







read the original abstract
Post-training Vision-Language-Action (VLA) models into policies that can be reliably deployed on real robots remains a major bottleneck. SFT and DAgger exploit failure signals only indirectly, and reward-based RL is bottlenecked by the difficulty of real-world reward design and of training reliable critics. We present FlowPRO, a reward-free offline reinforced fine-tuning framework for flow-matching VLAs. Algorithmically, we propose RPRO (Robotic Flow-matching Proximalized Preference Optimization), a preference-optimization objective tailored to the flow-matching action head of VLA models. RPRO pairs a contrastive optimizer with an explicit proximal regularizer that anchors the absolute magnitude of the implicit reward, thereby eliminating the reward-hacking failure mode of plain Flow-DPO. On the data side, a teleoperated intervention-and-rollback paradigm produces naturally paired positive and negative trajectories $(\tau^w, \tau^l)$ on a real robot from a single operator action; a Smooth Interpolation procedure, combined with batch mixing, then converts these sparse corrections into dense per-state supervision while preserving the base policy's capabilities. On four long-horizon bimanual tasks, FlowPRO attains the highest success rate, outperforming four representative baselines, and ablations confirm the contribution of each loss component.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlowPRO, a reward-free offline reinforced fine-tuning framework for flow-matching VLAs. It proposes the RPRO objective, which pairs a contrastive optimizer with an explicit proximal regularizer to anchor implicit reward magnitudes and avoid reward-hacking. Data collection uses a teleoperated intervention-and-rollback paradigm to generate paired positive/negative trajectories, converted to dense per-state supervision via Smooth Interpolation and batch mixing. The central empirical claim is that FlowPRO achieves the highest success rates on four long-horizon bimanual tasks, outperforming four baselines, with ablations confirming each loss component.
Significance. If the quantitative results hold with proper statistical support and baseline details, the work could meaningfully advance post-training of VLAs by offering a practical alternative to reward design and indirect failure exploitation in real-robot settings. The explicit proximal regularizer and intervention-based data pipeline are potentially useful contributions to preference optimization for flow-matching policies.
major comments (1)
- [Abstract] Abstract: The claim that FlowPRO 'attains the highest success rate' on four tasks and that 'ablations confirm the contribution of each loss component' is presented without any numerical success rates, number of evaluation trials, error bars, baseline descriptions, or dataset sizes. This absence makes it impossible to judge whether the data support the central empirical claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract. We agree that the current abstract would be strengthened by including concrete numerical results and evaluation details to better support the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that FlowPRO 'attains the highest success rate' on four tasks and that 'ablations confirm the contribution of each loss component' is presented without any numerical success rates, number of evaluation trials, error bars, baseline descriptions, or dataset sizes. This absence makes it impossible to judge whether the data support the central empirical claim.
Authors: We agree that the abstract would benefit from greater specificity. In the revised manuscript we will update the abstract to report the success rates achieved by FlowPRO and the four baselines on each of the four tasks, the number of evaluation trials per task, and a brief reference to the error bars and ablation outcomes. These quantitative details already appear with full statistical support in the experimental section; adding a concise version to the abstract will make the empirical contribution immediately verifiable. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript presents FlowPRO/RPRO as an explicit algorithmic construction: a contrastive optimizer paired with a stated proximal regularizer term, plus an intervention-and-rollback data pipeline followed by Smooth Interpolation and batch mixing. No equations appear in the supplied text that define a quantity in terms of itself, rename a fitted parameter as a prediction, or reduce the central result to a self-citation chain. The empirical claims rest on reported success rates and ablations rather than any definitional equivalence or imported uniqueness theorem. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. pages 2165–2183, 2023
2023
-
[3]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. RDT-1B: a diffusion foundation model for bimanual manipulation. 2025:29982–30009, 2025
2025
-
[7]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation.arXiv preprint arXiv:2108.03298, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. pages 627–635, 2011
2011
-
[11]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[12]
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences.Advances in neural information processing systems, 30, 2017
2017
-
[13]
Schulman, F
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. 2017
2017
-
[14]
G. Lu, W. Guo, C. Zhang, Y . Zhou, H. Jiang, Z. Gao, Y . Tang, and Z. Wang. VLA-RL: To- wards masterful and general robotic manipulation with scalable reinforcement learning.arXiv preprint arXiv:2505.18719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Y . Guo, J. Zhang, X. Chen, X. Ji, Y .-J. Wang, Y . Hu, and J. Chen. Improving vision-language- action model with online reinforcement learning. pages 15665–15672, 2025
2025
-
[16]
A. Ren, J. Lidard, L. Ankile, A. Simeonov, P. Agrawal, A. Majumdar, B. Burchfiel, H. Dai, and M. Simchowitz. Diffusion policy policy optimization. 2025:77288–77329, 2025. 9
2025
-
[17]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al.π ∗ 0.6: a VLA that learns from experience.arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Y . Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
S. Levine, A. Kumar, G. Tucker, and J. Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
- [20]
-
[21]
Rafailov, A
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[22]
K. Guo, Y . Li, and Z. Chen. Proximalized preference optimization for diverse feedback types: A decomposed perspective on dpo.Advances in Neural Information Processing Systems, 38: 94533–94576, 2026
2026
-
[23]
Kelly, C
M. Kelly, C. Sidrane, K. Driggs-Campbell, and M. J. Kochenderfer. HG-DAgger: Interactive imitation learning with human experts. In2019 International Conference on Robotics and Automation (ICRA), pages 8077–8083. IEEE, 2019
2019
-
[24]
Kostrikov, A
I. Kostrikov, A. Nair, and S. Levine. Offline reinforcement learning with implicit Q-learning. 2021
2021
-
[25]
Nakamoto, S
M. Nakamoto, S. Zhai, A. Singh, M. Sobol Mark, Y . Ma, C. Finn, A. Kumar, and S. Levine. Cal-QL: Calibrated offline RL pre-training for efficient online fine-tuning. volume 36, pages 62244–62269, 2023
2023
-
[26]
Black, M
K. Black, M. Janner, Y . Du, I. Kostrikov, and S. Levine. Training diffusion models with reinforcement learning. InInternational Conference on Learning Representations, volume 2024, pages 4965–4987, 2024
2024
-
[27]
Zhang, Y
B. Zhang, Y . Zhang, J. Ji, Y . Lei, J. Dai, Y . Chen, and Y . Yang. SafeVLA: Towards safety alignment of vision-language-action model via constrained learning.Advances in Neural In- formation Processing Systems, 38:153335–153373, 2026
2026
-
[28]
KTO: Model Alignment as Prospect Theoretic Optimization
K. Ethayarajh, W. Xu, N. Muennighoff, D. Jurafsky, and D. Kiela. KTO: Model alignment as prospect theoretic optimization.arXiv preprint arXiv:2402.01306, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [29]
-
[30]
Y . Meng, M. Xia, and D. Chen. SimPO: Simple preference optimization with a reference-free reward. volume 37, pages 124198–124235, 2024
2024
-
[31]
Xiong, H
W. Xiong, H. Dong, C. Ye, Z. Wang, H. Zhong, H. Ji, N. Jiang, and T. Zhang. Iterative preference learning from human feedback: Bridging theory and practice for RLHF under KL- constraint. 2023
2023
-
[32]
Hejna, R
J. Hejna, R. Rafailov, H. Sikchi, C. Finn, S. Niekum, W. B. Knox, and D. Sadigh. Contrastive preference learning: Learning from human feedback without reinforcement learning. InInter- national Conference on Learning Representations, volume 2024, pages 18770–18798, 2024. 10
2024
-
[33]
Wallace, M
B. Wallace, M. Dang, R. Rafailov, L. Zhou, A. Lou, S. Purushwalkam, S. Ermon, C. Xiong, S. Joty, and N. Naik. Diffusion model alignment using direct preference optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
2024
-
[34]
K. Yang, J. Tao, J. Lyu, C. Ge, J. Chen, W. Shen, X. Zhu, and X. Li. Using human feedback to fine-tune diffusion models without any reward model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8941–8951, 2024
2024
-
[35]
J. Liu, G. Liu, J. Liang, Z. Yuan, X. Liu, M. Zheng, X. Wu, Q. Wang, W. Qin, M. Xia, et al. Improving video generation with human feedback.arXiv preprint arXiv:2501.13918, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
R. A. Bradley and M. E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[37]
Robins, S
J. Robins, S. Greenland, and N. E. BRESLOW. A general estimator for the variance of the Mantel–Haenszel odds ratio.American journal of epidemiology, 124(5):719–723, 1986
1986
-
[38]
W. G. Cochran. Some methods for strengthening the commonχ 2 tests.Biometrics, 10(4): 417–451, 1954
1954
-
[39]
Mantel and W
N. Mantel and W. Haenszel. Statistical aspects of the analysis of data from retrospective studies of disease.Journal of the national cancer institute, 22(4):719–748, 1959. 11 A Asymptotic Vanishing of the Hyper-Response Reward in Continuous Action Spaces This appendix provides the formal asymptotic argument supporting the simplificationr θ(s,H)≈0 used in ...
1959
-
[40]
the left arm picks up the closed soft-fabric pencil case from a marker region on the table
-
[41]
the right arm grasps the zipper slider, and the two arms cooperate tounzipthe case
-
[42]
the left arm places the now-open case at the table center
-
[43]
the right arm reaches inside the case and holds it open from within
-
[44]
the right arm picks a pen lying on the table and drops it into the case
-
[45]
correct-then-retrain
the right arm grasps the pencil case again and the two arms cooperate tozip the case closedand return it to the table center. Object positions are fixed at marker regions with per-episode randomization. Three properties to- gether make this task uniquely challenging:(a) length and chaining—a single early-stage error (e.g., a slipped grasp at stage 1 or an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.