Can We Predict The Human Preference For Text-to-Image Content Prior To Generation And Is It Even Useful To Do So?
Pith reviewed 2026-06-28 06:11 UTC · model grok-4.3
The pith
Scalar human preference scores for text-to-image diffusion outputs can be predicted from the initial noise seed before generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Human preference scores can be predicted prior to generation from the initial random noise seed, and this prediction can be leveraged to improve generated image quality with negligible hardware overhead.
What carries the argument
Direct prediction of scalar HPM scores from the initial random noise seed without running the full diffusion process.
If this is right
- Poor seeds can be rejected before any generation compute is spent.
- Better seeds can be chosen to produce higher-preference images.
- The added cost of prediction remains negligible across tested models.
- Certain HPMs perform better than others when used for this pre-generation filtering.
Where Pith is reading between the lines
- Local deployment of small diffusion models could avoid repeated generation attempts by filtering seeds early.
- The same noise-based prediction idea might extend to other stochastic sampling processes such as video or 3D generation.
- End users might achieve more consistent high-preference results without manual trial-and-error on multiple seeds.
Load-bearing premise
The initial random noise seed contains enough information to allow accurate prediction of final HPM scores across different models and prompts without requiring the full generation process.
What would settle it
Measure the correlation between HPM scores predicted from noise seeds and the actual HPM scores of the generated images across many prompts and models; low correlation would falsify the claim.
Figures

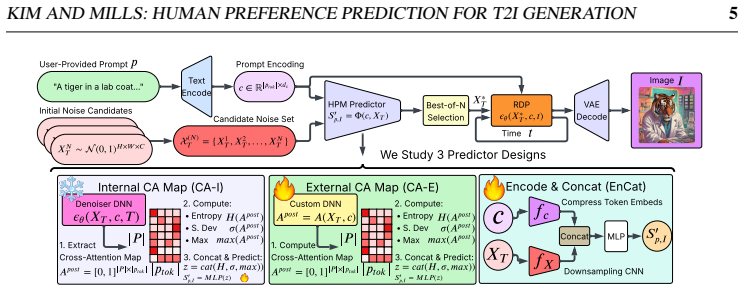

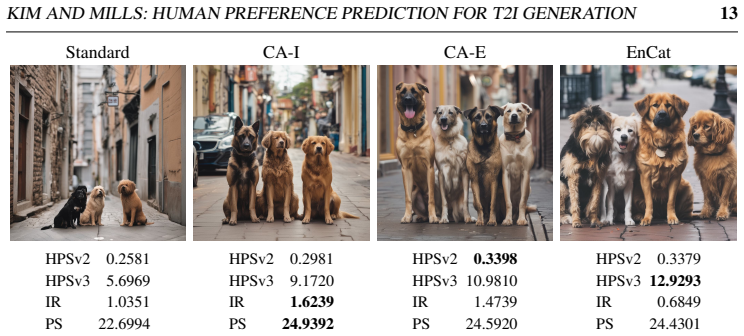

read the original abstract
Diffusion Models (DM) have revolutionized text-driven generation by enabling the synthesis of high-quality, photorealistic visual content from user prompts. Whereas prior advances in visual generation such as VAEs and GANs were primarily evaluated on perceptual or visual similarity metrics such as FID PSNR, DM advances have fostered the development of more advanced Human Preference Metrics (HPM) that model and quantify human judgment as scalar values. However, DMs synthesize content using an inherently stochastic process where random noise seeds generation. The initial random noise directly affects the quality of generated outputs, both qualitatively and quantitatively. This influence is pronounced in smaller models for local deployment scenarios. Given this phenomenon, we first investigate to what extent we can predict scalar HPM scores prior to committing compute resources for generation. Further, we then investigate to what extent we can leverage such prediction to improve the quality of generated images, and also study which HPMs are best suited for this task. Our investigation reveals that not only is this possible, but that it is feasible to achieve negligible hardware overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that scalar Human Preference Metric (HPM) scores for text-to-image diffusion model outputs can be predicted from the initial random noise seed (plus prompt) prior to running the full denoising process, and that such predictions can be used to select better seeds that improve final image quality while incurring only negligible hardware overhead. The work further examines which HPMs are most suitable for this pre-generation selection task and asserts feasibility across models and prompts.
Significance. If the central empirical claims were supported by rigorous, reproducible experiments, the result would offer a practical way to mitigate the stochastic variability in diffusion sampling without extra generation cost, which is especially relevant for smaller locally-deployed models. The approach could reduce wasted compute on low-HPM outputs and provide a new axis for generation-quality control. However, the manuscript as presented supplies no quantitative evidence, so its potential impact cannot yet be assessed.
major comments (3)
- [Abstract] Abstract: the feasibility of accurate pre-generation HPM prediction and the claim of negligible overhead are asserted without any description of the predictor architecture, training regime, dataset, or quantitative metrics (e.g., correlation, MAE, or downstream HPM improvement); the central claim therefore cannot be evaluated from the supplied text.
- [(entire manuscript)] No section supplies cross-model or cross-prompt correlation numbers, ablation studies on the information content of the initial Gaussian noise, or error bars that would test the weakest assumption that a cheap function of the seed alone can forecast the outcome of hundreds of conditioned denoising steps.
- [(entire manuscript)] The manuscript contains no equations, algorithms, or experimental protocol detailing how the mapping from noise realization to scalar HPM is learned or validated, leaving the required approximation of the UNet-prompt interaction unexamined.
Simulated Author's Rebuttal
We thank the referee for the detailed review. The comments highlight important gaps in the presentation of our empirical results and methodology. We address each major comment below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the feasibility of accurate pre-generation HPM prediction and the claim of negligible overhead are asserted without any description of the predictor architecture, training regime, dataset, or quantitative metrics (e.g., correlation, MAE, or downstream HPM improvement); the central claim therefore cannot be evaluated from the supplied text.
Authors: We agree the abstract is too high-level. In revision we will add one sentence summarizing the lightweight predictor (MLP on flattened noise + prompt embedding), the training set size, and key metrics (Pearson correlation and downstream HPM lift). revision: yes
-
Referee: [(entire manuscript)] No section supplies cross-model or cross-prompt correlation numbers, ablation studies on the information content of the initial Gaussian noise, or error bars that would test the weakest assumption that a cheap function of the seed alone can forecast the outcome of hundreds of conditioned denoising steps.
Authors: The current draft indeed omits these quantitative elements. We will insert a dedicated experimental subsection reporting cross-model and cross-prompt correlations, noise-only ablations, and error bars with statistical tests. revision: yes
-
Referee: [(entire manuscript)] The manuscript contains no equations, algorithms, or experimental protocol detailing how the mapping from noise realization to scalar HPM is learned or validated, leaving the required approximation of the UNet-prompt interaction unexamined.
Authors: We acknowledge the absence of formal notation and pseudocode. Revision will add an algorithm box, the explicit loss and architecture equations, and a short protocol subsection describing data collection and validation splits. revision: yes
Circularity Check
No circularity; empirical investigation of noise-to-HPM mapping contains no self-referential derivation
full rationale
The provided abstract and context describe an empirical study: the authors train or evaluate a predictor that maps initial noise (plus prompt) to scalar HPM values and then test whether selecting high-predicted seeds improves output quality. No equations, fitted parameters renamed as predictions, self-citation load-bearing uniqueness theorems, or ansatzes are quoted or referenced. The central claim is a factual assertion about feasibility across models, which stands or falls on external validation data rather than reducing to its own inputs by construction. Because the manuscript supplies no derivation chain that collapses to a tautology, the circularity score is 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stable diffusion webui.https://github.com/ AUTOMATIC1111/stable-diffusion-webui, 2022
AUTOMATIC1111. Stable diffusion webui.https://github.com/ AUTOMATIC1111/stable-diffusion-webui, 2022
2022
-
[2]
Flux.https://github.com/black-forest-labs/ flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/ flux, 2024
2024
-
[3]
Fast differen- tiable sorting and ranking
Mathieu Blondel, Olivier Teboul, Quentin Berthet, and Josip Djolonga. Fast differen- tiable sorting and ranking. InInternational Conference on Machine Learning, pages 950–959. PMLR, 2020
2020
-
[4]
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
Pith/arXiv arXiv 2024
-
[5]
Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Zhongdao Wang, James T. Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. InThe Twelfth Inter- national Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024...
2024
-
[6]
PixArt-Σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation
Junsong Chen, Chongjian Ge, Enze Xie, Yue Wu, Lewei Yao, Xiaozhe Ren, Zhongdao Wang, Ping Luo, Huchuan Lu, and Zhenguo Li. PixArt-Σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation. InEuropean Conference on Computer Vision, pages 74–91. Springer, 2025. 16KIM AND MILLS: HUMAN PREFERENCE PREDICTION FOR T2I GENERA TION
2025
-
[7]
Sana-sprint: One-step diffusion with continuous-time consistency distillation
Junsong Chen, Shuchen Xue, Yuyang Zhao, Jincheng Yu, Sayak Paul, Junyu Chen, Han Cai, Song Han, and Enze Xie. Sana-sprint: One-step diffusion with continuous-time consistency distillation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16185–16195, 2025
2025
-
[8]
Mills, Liyao Jiang, Chao Gao, and Di Niu
Ruichen Chen, Keith G. Mills, Liyao Jiang, Chao Gao, and Di Niu. Re-ttention: Ultra sparse visual generation via attention statistical reshape. InNeurIPS, 2025
2025
-
[9]
Ruichen Chen, Keith G Mills, and Di Niu. Fp4dit: Towards effective floating point quantization for diffusion transformers.arXiv preprint arXiv:2503.15465, 2025
arXiv 2025
-
[10]
Comfyui: A node-based gui for stable diffusion, 2025
ComfyUI Contributors. Comfyui: A node-based gui for stable diffusion, 2025. URL https://github.com/Comfy-Org/ComfyUI
2025
-
[11]
CyberRealistic Pony - | Stable Diffusion XL Checkpoint | Civitai — civitai.com.https://civitai.com/models/443821/ cyberrealistic-pony, 2026
Cyberdelia. CyberRealistic Pony - | Stable Diffusion XL Checkpoint | Civitai — civitai.com.https://civitai.com/models/443821/ cyberrealistic-pony, 2026. [Accessed 02-03-2026]
2026
-
[12]
A survey on diffusion models for inverse problems.arXiv preprint arXiv:2410.00083, 2024
Giannis Daras, Hyungjin Chung, Chieh-Hsin Lai, Yuki Mitsufuji, Jong Chul Ye, Pey- man Milanfar, Alexandros G Dimakis, and Mauricio Delbracio. A survey on diffusion models for inverse problems.arXiv preprint arXiv:2410.00083, 2024
Pith/arXiv arXiv 2024
-
[13]
Accelerating the super-resolution convolutional neural network
Chao Dong, Chen Change Loy, and Xiaoou Tang. Accelerating the super-resolution convolutional neural network. InEuropean conference on computer vision, pages 391–
-
[14]
An image is worth 16x16 words: Trans- formers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Trans- formers for image recognition at scale. In9th International Conference on Learning Representations, ICLR 202...
2021
-
[15]
URLhttps://openreview.net/forum?id=YicbFdNTTy
-
[16]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first International Conference on Machine Learning, ICML 2024, Vienn...
2024
-
[17]
Reno: Enhancing one-step text-to-image models through reward-based noise optimization.Advances in Neural Information Processing Systems, 37:125487– 125519, 2024
Luca Eyring, Shyamgopal Karthik, Karsten Roth, Alexey Dosovitskiy, and Zeynep Akata. Reno: Enhancing one-step text-to-image models through reward-based noise optimization.Advances in Neural Information Processing Systems, 37:125487– 125519, 2024
2024
-
[18]
Luca Eyring, Shyamgopal Karthik, Alexey Dosovitskiy, Nataniel Ruiz, and Zeynep Akata. Noise hypernetworks: Amortizing test-time compute in diffusion models.arXiv preprint arXiv:2508.09968, 2025
arXiv 2025
-
[19]
Amirhosein Ghasemabadi, Keith G Mills, Baochun Li, and Di Niu. Guided by gut: Efficient test-time scaling with reinforced intrinsic confidence.arXiv preprint arXiv:2505.20325, 2025. KIM AND MILLS: HUMAN PREFERENCE PREDICTION FOR T2I GENERA TION17
arXiv 2025
-
[20]
Generative adversarial nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014
2014
-
[21]
Initno: Boosting text-to-image diffusion models via initial noise optimization
Xiefan Guo, Jinlin Liu, Miaomiao Cui, Jiankai Li, Hongyu Yang, and Di Huang. Initno: Boosting text-to-image diffusion models via initial noise optimization. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9380–9389, 2024
2024
-
[22]
Fred X. Han, Keith G. Mills, Fabian Chudak, Parsa Riahi, Mohammad Salameh, Jialin Zhang, Wei Lu, Shangling Jui, and Di Niu.A General-Purpose Transferable Predictor for Neural Architecture Search, pages 721–729. Society for Industrial and Applied Mathematics, 2023. doi: 10.1137/1.9781611977653.ch81. URLhttps://epubs. siam.org/doi/abs/10.1137/1.9781611977653.ch81
-
[23]
Identity mappings in deep residual networks
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. InEuropean Conference on Computer Vision, pages 630–645. Springer, 2016
2016
-
[24]
CLIPS core: A Reference-free Evaluation Metric for Image Captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. CLIP- Score: A reference-free evaluation metric for image captioning. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors,Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7514–7528, Online and Punta Cana,...
-
[25]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[26]
Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Pith/arXiv arXiv 2022
-
[27]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[28]
Video diffusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022
2022
-
[29]
Make-an-audio: Text-to-audio genera- tion with prompt-enhanced diffusion models
Rongjie Huang, Jiawei Huang, Dongchao Yang, Yi Ren, Luping Liu, Mingze Li, Zhen- hui Ye, Jinglin Liu, Xiang Yin, and Zhou Zhao. Make-an-audio: Text-to-audio genera- tion with prompt-enhanced diffusion models. InInternational Conference on Machine Learning, pages 13916–13932. PMLR, 2023
2023
-
[30]
Raise: Requirement-adaptive evolutionary refinement for training-free text-to-image alignment, 2026
Liyao Jiang, Ruichen Chen, Chao Gao, and Di Niu. Raise: Requirement-adaptive evolutionary refinement for training-free text-to-image alignment, 2026. URLhttps: //arxiv.org/abs/2603.00483. 18KIM AND MILLS: HUMAN PREFERENCE PREDICTION FOR T2I GENERA TION
arXiv 2026
-
[31]
Adhithyan Kalaivanan, Zheng Zhao, Jens Sjölund, and Fredrik Lindsten. Ess-flow: Training-free guidance of flow-based models as inference in source space.arXiv preprint arXiv:2510.05849, 2025
arXiv 2025
-
[32]
Juggernaut XL - Ragnarok_by_RunDiffusion | Stable Diffusion XL Check- point | Civitai — civitai.com.https://civitai.com/models/133005/ juggernaut-xl, 2025
KandooAI. Juggernaut XL - Ragnarok_by_RunDiffusion | Stable Diffusion XL Check- point | Civitai — civitai.com.https://civitai.com/models/133005/ juggernaut-xl, 2025. [Accessed 27-01-2026]
2025
-
[33]
Elucidating the design space of diffusion-based generative models.Advances in neural information processing sys- tems, 35:26565–26577, 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing sys- tems, 35:26565–26577, 2022
2022
-
[34]
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. In Yoshua Bengio and Yann LeCun, editors,2nd International Conference on Learning Repre- sentations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Pro- ceedings, 2014. URLhttp://arxiv.org/abs/1312.6114
Pith/arXiv arXiv 2014
-
[35]
Panoptic feature pyramid networks
Alexander Kirillov, Ross Girshick, Kaiming He, and Piotr Dollár. Panoptic feature pyramid networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6399–6408, 2019
2019
-
[36]
Pick-a-pic: An open dataset of user preferences for text-to-image generation
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation. Advances in neural information processing systems, 36:36652–36663, 2023
2023
-
[37]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
Pith/arXiv arXiv 2024
-
[38]
Zeming Li, Xiangyue Liu, Xiangyu Zhang, Ping Tan, and Heung-Yeung Shum. Noisear: Autoregressing initial noise prior for diffusion models.arXiv preprint arXiv:2506.01337, 2025
arXiv 2025
-
[39]
Hunyuan-dit: A powerful multi-resolution diffusion transformer with fine-grained chinese understanding, 2024
Zhimin Li, Jianwei Zhang, Qin Lin, Jiangfeng Xiong, Yanxin Long, Xinchi Deng, Yingfang Zhang, Xingchao Liu, Minbin Huang, Zedong Xiao, Dayou Chen, Jiajun He, Jiahao Li, Wenyue Li, Chen Zhang, Rongwei Quan, Jianxiang Lu, Jiabin Huang, Xiaoyan Yuan, Xiaoxiao Zheng, Yixuan Li, Jihong Zhang, Chao Zhang, Meng Chen, Jie Liu, Zheng Fang, Weiyan Wang, Jinbao Xue,...
2024
-
[40]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019. URLhttps://openreview.net/ forum?id=Bkg6RiCqY7
2019
-
[41]
Pinat: A permutation invariance augmented transformer for nas predictor
Shun Lu, Yu Hu, Peihao Wang, Yan Han, Jianchao Tan, Jixiang Li, Sen Yang, and Ji Liu. Pinat: A permutation invariance augmented transformer for nas predictor. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2023. KIM AND MILLS: HUMAN PREFERENCE PREDICTION FOR T2I GENERA TION19
2023
-
[42]
Dreamshaper - stable diffusion fine-tune.https://civitai.com/ models/4384/dreamshaper, 2023
Lykon. Dreamshaper - stable diffusion fine-tune.https://civitai.com/ models/4384/dreamshaper, 2023
2023
-
[43]
Hpsv3: Towards wide- spectrum human preference score
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide- spectrum human preference score. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 15086–15095, 2025
2025
-
[44]
Mills, Mohammad Salameh, Ruichen Chen, Wei Hassanpour, Negar Lu, and Di Niu
Keith G. Mills, Mohammad Salameh, Ruichen Chen, Wei Hassanpour, Negar Lu, and Di Niu. Qua 2sedimo: Quantifiable quantization sensitivity of diffusion models. In AAAI, 2025
2025
-
[45]
Kiyoung Om, Kyuil Sim, Taeyoung Yun, Hyeongyu Kang, and Jinkyoo Park. Poste- rior inference in latent space for scalable constrained black-box optimization.arXiv preprint arXiv:2507.00480, 2025
Pith/arXiv arXiv 2025
-
[46]
Illustrious XL 2.0 - v2.0 | Illustrious Checkpoint | Civitai — civitai.com
ONOMAAI. Illustrious XL 2.0 - v2.0 | Illustrious Checkpoint | Civitai — civitai.com. https://civitai.com/models/1369089/illustrious-xl-20, 2025. [Accessed 27-01-2026]
arXiv 2025
-
[47]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023
2023
-
[48]
SDXL: improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. SDXL: improving latent diffusion models for high-resolution image synthesis. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URLhttps://openreview.net/fo...
2024
-
[49]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Om- mer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
2022
-
[50]
Mills, Negar Hassanpour, Fred Han, Shuting Zhang, Wei Lu, Shangling Jui, Chunhua Zhou, Fengyu Sun, and Di Niu
Mohammad Salameh, Keith G. Mills, Negar Hassanpour, Fred Han, Shuting Zhang, Wei Lu, Shangling Jui, Chunhua Zhou, Fengyu Sun, and Di Niu. Autogo: Automated computation graph optimization for neural network evolution. InAdvances in Neural Information Processing Systems, 2023
2023
-
[51]
The surprising effectiveness of diffusion models for op- tical flow and monocular depth estimation.Advances in Neural Information Processing Systems, 36:39443–39469, 2023
Saurabh Saxena, Charles Herrmann, Junhwa Hur, Abhishek Kar, Mohammad Norouzi, Deqing Sun, and David J Fleet. The surprising effectiveness of diffusion models for op- tical flow and monocular depth estimation.Advances in Neural Information Processing Systems, 36:39443–39469, 2023
2023
-
[52]
A mathematical theory of communication.The Bell system technical journal, 27(3):379–423, 1948
Claude Elwood Shannon. A mathematical theory of communication.The Bell system technical journal, 27(3):379–423, 1948
1948
-
[53]
Calibrating generative models.arXiv preprint arXiv:2510.10020, 2025
Henry D Smith, Nathaniel L Diamant, and Brian L Trippe. Calibrating generative models.arXiv preprint arXiv:2510.10020, 2025
Pith/arXiv arXiv 2025
-
[54]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational confer- ence on machine learning, pages 2256–2265. PMLR, 2015. 20KIM AND MILLS: HUMAN PREFERENCE PREDICTION FOR T2I GENERA TION
2015
-
[55]
Denoising diffusion implicit mod- els.arXiv preprint arXiv:2010.02502, 2020
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit mod- els.arXiv preprint arXiv:2010.02502, 2020
Pith/arXiv arXiv 2010
-
[56]
Diffusion-based neural network weights generation.arXiv preprint arXiv:2402.18153, 2024
Bedionita Soro, Bruno Andreis, Hayeon Lee, Wonyong Jeong, Song Chong, Frank Hutter, and Sung Ju Hwang. Diffusion-based neural network weights generation.arXiv preprint arXiv:2402.18153, 2024
arXiv 2024
-
[57]
Pixart-alpha prompt list.https://github.com/ PixArt-alpha/PixArt-alpha/blob/master/asset/samples.txt,
PixArt-Alpha Team. Pixart-alpha prompt list.https://github.com/ PixArt-alpha/PixArt-alpha/blob/master/asset/samples.txt,
-
[58]
Accessed: 2026-01-15
2026
-
[59]
Deep learning and the information bottleneck principle
Naftali Tishby and Noga Zaslavsky. Deep learning and the information bottleneck principle. In2015 ieee information theory workshop (itw), pages 1–5. Ieee, 2015
2015
-
[60]
The information bottleneck method.arXiv preprint physics/0004057, 2000
Naftali Tishby, Fernando C Pereira, and William Bialek. The information bottleneck method.arXiv preprint physics/0004057, 2000
Pith/arXiv arXiv 2000
-
[61]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wal- lach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.,
-
[62]
URLhttps://proceedings.neurips.cc/paper_files/paper/ 2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
2017
-
[63]
Siddarth Venkatraman, Mohsin Hasan, Minsu Kim, Luca Scimeca, Marcin Sendera, Yoshua Bengio, Glen Berseth, and Nikolay Malkin. Outsourced diffusion sampling: Efficient posterior inference in latent spaces of generative models.arXiv preprint arXiv:2502.06999, 2025
arXiv 2025
-
[64]
Diffusers: State-of-the-art diffusion models
Patrick von Platen, Suraj Patil, Anton Lozhkov, Pedro Cuenca, Nathan Lambert, Kashif Rasul, Mishig Davaadorj, Dhruv Nair, Sayak Paul, William Berman, Yiyi Xu, Steven Liu, and Thomas Wolf. Diffusers: State-of-the-art diffusion models. https://github.com/huggingface/diffusers, 2022
2022
-
[65]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Pu- rushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8228–8238, June 2024
2024
-
[66]
Chaoqi Wang, Guodong Zhang, and Roger Grosse. Picking winning tickets before training by preserving gradient flow.arXiv preprint arXiv:2002.07376, 2020
arXiv 2002
-
[67]
Liang Wang, Chao Song, Zhiyuan Liu, Yu Rong, Qiang Liu, and Shu Wu. Dif- fusion models for molecules: A survey of methods and tasks.arXiv preprint arXiv:2502.09511, 2025
arXiv 2025
-
[68]
The silent as- sistant: Noisequery as implicit guidance for goal-driven image generation
Ruoyu Wang, Huayang Huang, Ye Zhu, Olga Russakovsky, and Yu Wu. The silent as- sistant: Noisequery as implicit guidance for goal-driven image generation. InProceed- ings of the IEEE/CVF International Conference on Computer Vision, pages 17618– 17628, 2025. KIM AND MILLS: HUMAN PREFERENCE PREDICTION FOR T2I GENERA TION21
2025
-
[69]
The lambdaloss framework for ranking metric optimization
Xuanhui Wang, Cheng Li, Nadav Golbandi, Michael Bendersky, and Marc Najork. The lambdaloss framework for ranking metric optimization. InProceedings of the 27th ACM international conference on information and knowledge management, pages 1313–1322, 2018
2018
-
[70]
Source-guided flow matching.arXiv preprint arXiv:2508.14807, 2025
Zifan Wang, Alice Harting, Matthieu Barreau, Michael M Zavlanos, and Karl H Jo- hansson. Source-guided flow matching.arXiv preprint arXiv:2508.14807, 2025
arXiv 2025
-
[71]
How powerful are performance predictors in neural architecture search?NeurIPS, 2021
Colin White, Arber Zela, Robin Ru, Yang Liu, and Frank Hutter. How powerful are performance predictors in neural architecture search?NeurIPS, 2021
2021
-
[72]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341, 2023
Pith/arXiv arXiv 2023
-
[73]
Densedpo: Fine-grained temporal preference optimization for video diffusion models.Advances in Neural In- formation Processing Systems, 38:171632–171668, 2026
Ziyi Wu, Anil Kag, Ivan Skorokhodov, Willi Menapace, Ashkan Mirzaei, Igor Gilitschenski, Sergey Tulyakov, and Aliaksandr Siarohin. Densedpo: Fine-grained temporal preference optimization for video diffusion models.Advances in Neural In- formation Processing Systems, 38:171632–171668, 2026
2026
-
[74]
SANA: efficient high- resolution text-to-image synthesis with linear diffusion transformers
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, and Song Han. SANA: efficient high- resolution text-to-image synthesis with linear diffusion transformers. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. U...
2025
-
[75]
Imagereward: Learning and evaluating human preferences for text- to-image generation.Advances in Neural Information Processing Systems, 36:15903– 15935, 2023
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text- to-image generation.Advances in Neural Information Processing Systems, 36:15903– 15935, 2023
2023
-
[76]
Cogvideox: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. Cogvideox: Text-to-video diffusion models with an expert transformer. 2025. URL https://openreview.net/forum?id=LQzN6TRFg9
2025
-
[77]
Neural meth- ods for amortized inference.Annual Review of Statistics and Its Application, 12(1): 311–335, 2025
Andrew Zammit-Mangion, Matthew Sainsbury-Dale, and Raphaël Huser. Neural meth- ods for amortized inference.Annual Review of Statistics and Its Application, 12(1): 311–335, 2025
2025
-
[78]
Learning multi-dimensional human preference for text-to-image generation
Sixian Zhang, Bohan Wang, Junqiang Wu, Yan Li, Tingting Gao, Di Zhang, and Zhongyuan Wang. Learning multi-dimensional human preference for text-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 8018–8027, June 2024
2024
-
[79]
A photo of a male android, half robot and half humanoid, resembling actor Liam Hemsworth, posing stoically on display at a museum
Zikai Zhou, Shitong Shao, Lichen Bai, Shufei Zhang, Zhiqiang Xu, Bo Han, and Zeke Xie. Golden noise for diffusion models: A learning framework. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17688–17697, 2025. 22KIM AND MILLS: HUMAN PREFERENCE PREDICTION FOR T2I GENERA TION Supplementary Materials We provide additional im...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.