RH+: Row-Hit-Optimized Scheduling for PIM-based LLM Inference
Pith reviewed 2026-06-28 02:17 UTC · model grok-4.3
The pith
For PIM LLM inference, a stride change that keeps 32 MAC operations in the same DRAM row delivers 8-12x speedup by masking row cycle time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
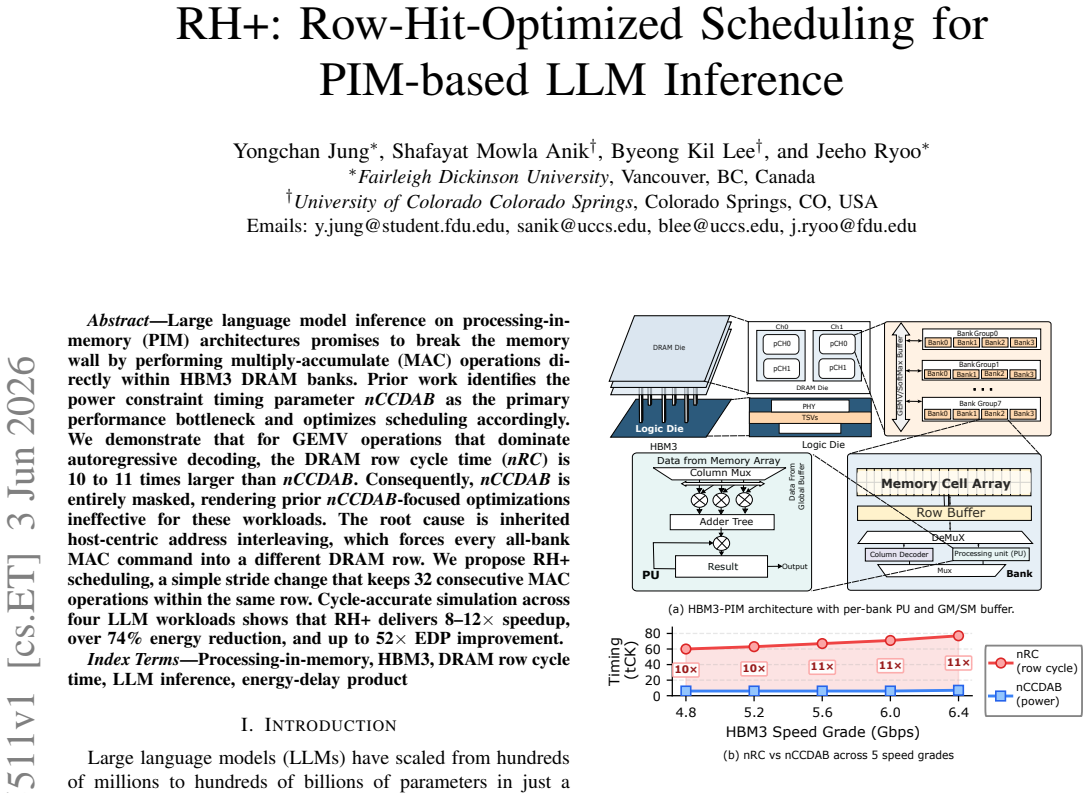
In GEMV operations that dominate autoregressive decoding, nRC is 10 to 11 times larger than nCCDAB, so the latter is masked and prior nCCDAB-focused optimizations are ineffective; the root cause is host-centric interleaving that forces every all-bank MAC into a different row. RH+ scheduling uses a simple stride change to keep 32 consecutive MAC operations within the same row, yielding 8-12x speedup, over 74% energy reduction, and up to 52x EDP improvement in cycle-accurate simulation across four LLM workloads.
What carries the argument
RH+ scheduling, a stride adjustment in address mapping that confines consecutive MAC operations to the same DRAM row instead of spreading them across rows.
If this is right
- nCCDAB-targeted scheduling optimizations provide no benefit for GEMV-dominated autoregressive decoding on PIM.
- Row cycle time becomes the dominant constraint that must be addressed through address mapping or scheduling.
- RH+ achieves 8-12x speedup, over 74% energy reduction, and up to 52x EDP improvement without hardware modifications.
- The performance gap between prior methods and RH+ widens as model size increases because GEMV remains the bottleneck.
Where Pith is reading between the lines
- The same row-hit principle could be applied to other memory-bound workloads whose access patterns resemble GEMV.
- Future DRAM address mappings for AI accelerators might be designed around row locality rather than bank parallelism from the start.
- Combining RH+ with software-level tiling or model compression could produce additional gains beyond the reported numbers.
- Real hardware validation would need to check whether the new stride pattern introduces unexpected refresh or power-delivery side effects not captured in simulation.
Load-bearing premise
The cycle-accurate simulator faithfully reproduces real HBM3 DRAM timing behavior, including any effects of the altered interleaving on power delivery or thermal limits.
What would settle it
Running the same four LLM workloads on physical HBM3-based PIM hardware with the RH+ stride change versus the baseline address mapping and measuring whether the observed speedup falls outside the simulated 8-12x range.
Figures





read the original abstract
Large language model inference on processing-in-memory (PIM) architectures promises to break the memory wall by performing multiply-accumulate (MAC) operations directly within HBM3 DRAM banks. Prior work identifies the power constraint timing parameter nCCDAB as the primary performance bottleneck and optimizes scheduling accordingly. We demonstrate that for GEMV operations that dominate autoregressive decoding, the DRAM row cycle time (nRC) is 10 to 11 times larger than nCCDAB. Consequently, nCCDAB is entirely masked, rendering prior nCCDAB-focused optimizations ineffective for these workloads. The root cause is inherited host-centric address interleaving, which forces every all-bank MAC command into a different DRAM row. We propose RH+ scheduling, a simple stride change that keeps 32 consecutive MAC operations within the same row. Cycle-accurate simulation across four LLM workloads shows that RH+ delivers 8-12x speedup, over 74% energy reduction, and up to 52x EDP improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that GEMV operations dominating autoregressive LLM decoding on PIM architectures with HBM3 exhibit nRC 10-11x larger than nCCDAB due to host-centric address interleaving that forces each all-bank MAC into a different row; prior nCCDAB-focused optimizations are thus ineffective. It proposes RH+ as a simple stride change to keep 32 consecutive MACs in the same row and reports 8-12x speedup, >74% energy reduction, and up to 52x EDP improvement from cycle-accurate simulation on four LLM workloads.
Significance. If the simulation results hold under real HBM3 behavior with the modified interleaving, the work would be significant for PIM-based LLM inference by shifting focus from nCCDAB to row-hit optimization and demonstrating large, practical gains from a minimal scheduling change. The quantitative speedups, energy, and EDP numbers would directly inform PIM scheduler design for memory-bound workloads.
major comments (1)
- [Abstract] Abstract (and implied simulation methodology): the central claims that nRC is 10-11x nCCDAB (masking prior optimizations) and that RH+ yields 8-12x speedup rest entirely on cycle-accurate simulation fidelity for the new address mapping. No real-silicon validation, error bars, or sensitivity analysis to unmodeled effects (power delivery, thermal constraints, or effective nRC under the stride change) is provided; this is load-bearing because any deviation in modeled row-hit behavior would invalidate both the masking conclusion and the reported gains.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of simulation fidelity. We address the major comment below, noting that our evaluation follows standard practice for architecture proposals using cycle-accurate DRAM models.
read point-by-point responses
-
Referee: [Abstract] Abstract (and implied simulation methodology): the central claims that nRC is 10-11x nCCDAB (masking prior optimizations) and that RH+ yields 8-12x speedup rest entirely on cycle-accurate simulation fidelity for the new address mapping. No real-silicon validation, error bars, or sensitivity analysis to unmodeled effects (power delivery, thermal constraints, or effective nRC under the stride change) is provided; this is load-bearing because any deviation in modeled row-hit behavior would invalidate both the masking conclusion and the reported gains.
Authors: The nRC/nCCDAB ratio (10-11x) is taken directly from the JEDEC HBM3 specification and is independent of our simulator; it is a fixed timing parameter that masks nCCDAB-focused optimizations for GEMV regardless of address mapping. The RH+ speedup numbers derive from cycle-accurate simulation that models the DRAM command state machine, row activation, and the stride change in address interleaving. We model row hits by tracking per-bank row buffers under the new mapping, using publicly documented HBM3 timing values. Real-silicon validation of a modified controller interleaving is outside the scope of this simulation study, as is sensitivity analysis to secondary effects such as thermal throttling or power delivery noise. The core row-hit behavior under RH+ follows directly from the command sequence and does not alter the underlying DRAM timing parameters. revision: no
- Real-silicon validation of RH+ under modified HBM3 interleaving, including sensitivity to unmodeled effects such as thermal constraints and power delivery
Circularity Check
No circularity; claims rest on external cycle-accurate simulation of standard HBM3 parameters
full rationale
The paper derives its core claims (nRC being 10-11x nCCDAB for GEMV, masking of prior optimizations, and 8-12x speedup from RH+ stride change) from cycle-accurate simulation using published HBM3 timing parameters and a proposed address mapping. No equations or results reduce to inputs by construction, no fitted parameters are relabeled as predictions, and no load-bearing self-citations or uniqueness theorems from the same authors appear. The simulation methodology is presented as independent of the target performance numbers, satisfying the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard HBM3 timing parameters (nRC = 10-11x nCCDAB) apply unchanged under the new address mapping.
Reference graph
Works this paper leans on
-
[1]
Brown et al
T. Brown et al. Language models are few-shot learners.Advances Neural Inf. Process. Syst. (NeurIPS), 33, 2020
2020
-
[2]
Chandrasekar et al
K. Chandrasekar et al. DRAMPower: Open-source DRAM power & energy estimation tool. InURL: http://www.drampower .info, 2012
2012
-
[3]
Hwang et al
G. Hwang et al. NeuPIMs: NPU-PIM heterogeneous acceleration for batched LLM inference. InProc. ACM Int. Conf. Archit. Support Program. Lang. Oper . Syst. (ASPLOS), 2024
2024
-
[4]
JESD238A: High bandwidth memory (HBM3) DRAM, 2023
JEDEC. JESD238A: High bandwidth memory (HBM3) DRAM, 2023
2023
-
[5]
Jeong et al
Y . Jeong et al. AttAcc: Unleashing the power of PIM for batched transformer-based generative model inference. InProc. ACM Int. Conf. Archit. Support Program. Lang. Oper . Syst. (ASPLOS), 2024
2024
-
[6]
Kim et al
H. Kim et al. Newton: A DRAM-maker’s accelerator-in-memory (AiM) architecture for machine learning. InProc. IEEE/ACM Int. Symp. Microarchit. (MICRO), 2020
2020
-
[7]
Lee et al
S. Lee et al. AIM: Energy-efficient aggregation inside the memory hierarchy.ACM Trans. Archit. Code Optim. (TACO), 13(1), 2016
2016
-
[8]
Lee et al
S. Lee et al. Hardware architecture and software stack for PIM based on commercial DRAM technology: Industrial product. InProc. ACM/IEEE Int. Symp. Comput. Archit. (ISCA), 2021
2021
-
[9]
Lee et al
S. Lee et al. A 1ynm 1.25v 8gb 16gb/s/pin GDDR6-based accelerator- in-memory supporting 1tflops MAC operation and various activation functions. InProc. IEEE Int. Solid-State Circuits Conf. (ISSCC), 2022
2022
-
[10]
Luo et al
H. Luo et al. Ramulator 2.0: A modern, modular, and extensible DRAM simulator.IEEE Comput. Archit. Lett., 22(2), 2023
2023
-
[11]
M. Shoeybi et al. Megatron-LM: Training multi-billion param- eter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
Pith/arXiv arXiv 1909
-
[12]
H. Touvron et al. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[13]
S. Zhang et al. OPT: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022
Pith/arXiv arXiv 2022
-
[14]
Zhou et al
C. Zhou et al. TransPIM: A memory-based acceleration via software- hardware co-design for transformers. InProc. IEEE Int. Symp. High- Perform. Comput. Archit. (HPCA), 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.