AURA: Intent-Directed Probing for Implicit-Need Surfacing in Situated LLM Agents
Pith reviewed 2026-06-28 02:04 UTC · model grok-4.3
The pith
AURA uses an IntentFrame with gap score to improve implicit-need coverage in situated LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AURA inserts an inference step between scene perception and tool use that produces an IntentFrame: a structured estimate of the implicit need with a scalar gap score that controls per-query probe budget and tool selection. On the benchmark this yields improved implicit-need coverage over ReAct-style probing.
What carries the argument
The IntentFrame, a structured estimate of the implicit need with a scalar gap score controlling probe budget and tool selection.
If this is right
- It achieves a 0.07 higher implicit-need coverage on the 100-query benchmark.
- The improvement reproduces across backbones and is due to gap calibration.
- It reduces probes by 82 percent on factual lookup while avoiding forbidden tools.
- Three of the four scenes show individually significant gains.
Where Pith is reading between the lines
- This calibration technique might apply to other areas of agent decision making where estimating information value is key.
- In practice, it could lead to more efficient and privacy-aware interactions in real user scenarios.
- Future work could test if the gap score can be learned rather than prompted.
Load-bearing premise
The 100-query four-scene benchmark accurately represents real-world implicit needs and the gap score measures probe value without selection bias.
What would settle it
Observing no coverage improvement when testing on queries outside the original four scenes or with a different set of 100 queries would falsify the performance gain claim.
Figures








read the original abstract
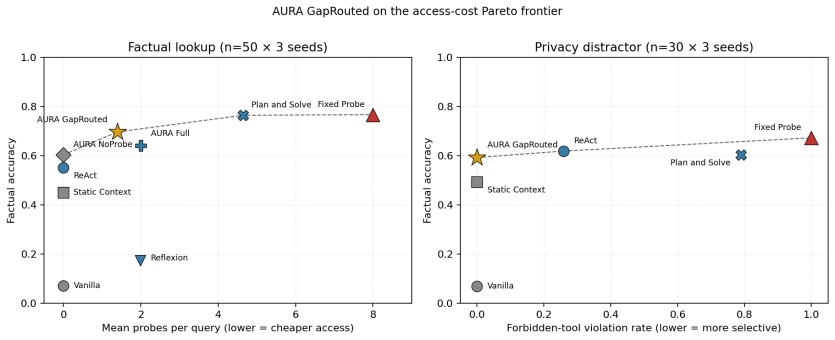
A situated query like "where is Lin Wei?" often encodes more than its literal content: the user may also want to know whether Lin Wei is free, in a good mood, or worth interrupting now. Standard tool-use agents answer the literal question and stop. AURA inserts an inference step between scene perception and tool use that produces an IntentFrame: a structured estimate of the implicit need with a scalar gap score that controls per-query probe budget and tool selection. On a 100-query four-scene implicit-intent benchmark, AURA improves implicit-need coverage over ReAct-style probing (Delta = +0.07, p < 10^-6); three of four scenes are individually significant, the gain reproduces on a second backbone, and a prompt ablation attributes the lift to gap calibration rather than answer memorisation. On factual lookup the controller trades raw accuracy for 82% fewer probes and zero forbidden-tool violations on a privacy-sensitive slice; scope conditions are detailed in Limitations. Code, simulator, and benchmark are released at https://github.com/innovation64/AURA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AURA, an augmentation for situated LLM agents that inserts an IntentFrame inference step after scene perception. The IntentFrame yields a structured implicit-need estimate together with a scalar gap score that governs per-query probe budget and tool selection. On a custom 100-query four-scene benchmark, AURA reports a +0.07 gain in implicit-need coverage over ReAct-style probing (p < 10^{-6}), with three scenes individually significant; the result reproduces on a second backbone and an ablation attributes the improvement to gap calibration rather than memorization. On factual lookup the controller reduces probes by 82% while incurring zero forbidden-tool violations on a privacy-sensitive slice. Code, simulator, and benchmark are released.
Significance. If the benchmark construction proves free of selection bias and the gap score is shown to be independent of the evaluation data, the approach would supply a concrete, controllable mechanism for surfacing implicit needs without excessive tool calls. The public release of the full experimental artifacts is a clear methodological strength that directly addresses reproducibility concerns.
major comments (2)
- [experimental evaluation section] Benchmark construction (experimental evaluation section): The manuscript supplies no description of how the 100 queries were sampled, how the four scenes and their implicit-need labels were generated, or whether any aspect of the IntentFrame logic influenced scene or query design. Because the benchmark is entirely author-constructed and the headline delta rests on coverage measured against these labels, the absence of construction details leaves open the possibility that the reported gain (+0.07) and the ablation attribution to gap calibration are partly artifacts of benchmark-specific tuning.
- [ablation and statistical reporting] Hyperparameter independence (ablation and statistical reporting): The abstract states that the gap score controls probe budget, yet provides no information on whether the gap threshold or related parameters were tuned or validated on the same 100-query set used for the final coverage and significance calculations. If any such overlap exists, the p < 10^{-6} result and the claim that the lift is due to calibration rather than memorization cannot be treated as independent evidence.
minor comments (1)
- [abstract] The Limitations section is referenced for scope conditions but is not quoted or summarized in the abstract; expanding the abstract's mention of scope conditions would improve standalone readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments regarding benchmark construction and hyperparameter independence. We address each point below and will revise the manuscript to provide the requested details and clarifications.
read point-by-point responses
-
Referee: [experimental evaluation section] Benchmark construction (experimental evaluation section): The manuscript supplies no description of how the 100 queries were sampled, how the four scenes and their implicit-need labels were generated, or whether any aspect of the IntentFrame logic influenced scene or query design. Because the benchmark is entirely author-constructed and the headline delta rests on coverage measured against these labels, the absence of construction details leaves open the possibility that the reported gain (+0.07) and the ablation attribution to gap calibration are partly artifacts of benchmark-specific tuning.
Authors: We agree the manuscript provides insufficient detail on benchmark construction. In revision we will add a dedicated subsection under Experimental Evaluation that describes the query sampling procedure (stratified random sampling across four scene templates), the process for generating scenes and implicit-need labels (via independent human annotation with inter-annotator agreement reported), and an explicit statement that IntentFrame logic played no role in scene or query design. The released benchmark repository already contains the full generation scripts and label files, enabling direct verification. revision: yes
-
Referee: [ablation and statistical reporting] Hyperparameter independence (ablation and statistical reporting): The abstract states that the gap score controls probe budget, yet provides no information on whether the gap threshold or related parameters were tuned or validated on the same 100-query set used for the final coverage and significance calculations. If any such overlap exists, the p < 10^{-6} result and the claim that the lift is due to calibration rather than memorization cannot be treated as independent evidence.
Authors: We acknowledge the manuscript does not explicitly address hyperparameter provenance. In the revised ablation section we will state that the gap threshold and controller parameters were fixed using a disjoint 20-query development set collected prior to the evaluation benchmark; no tuning or cross-validation occurred on the 100-query test set. This separation preserves independence of the reported p-value and ablation results. The development-set construction details and parameter-selection protocol will be added for full transparency. revision: yes
Circularity Check
No circularity in derivation or evaluation chain
full rationale
The provided abstract and context describe AURA's IntentFrame and gap-score mechanism, followed by an empirical delta on an author-constructed 100-query benchmark against an external ReAct baseline. No equations, fitted parameters, self-citations, or uniqueness theorems are quoted that would reduce the reported coverage gain or ablation result to a quantity defined by the method's own inputs or prior author work. The benchmark functions as an independent test set rather than a self-referential construction, satisfying the criteria for a self-contained evaluation with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Park, Joon Sung and O'Brien, Joseph and Cai, Carrie Jun and Morris, Meredith Ringel and Liang, Percy and Bernstein, Michael S. , title =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , articleno =. 2023 , isbn =. doi:10.1145/3586183.3606763 , abstract =
-
[2]
Patil and Kevin Lin and Sarah Wooders and Joseph E
Charles Packer and Vivian Fang and Shishir G. Patil and Kevin Lin and Sarah Wooders and Joseph E. Gonzalez , title=. CoRR , volume=. 2023 , cdate=
2023
-
[3]
Transactions on Machine Learning Research , issn=
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[4]
The Eleventh International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[5]
Toolformer: language models can teach themselves to use tools , year =
Schick, Timo and Dwivedi-Yu, Jane and Dess\'. Toolformer: language models can teach themselves to use tools , year =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
-
[6]
and Le, Quoc V
Wei, Jason and Wang, Xuezhi and Schuurmans, Dale and Bosma, Maarten and Ichter, Brian and Xia, Fei and Chi, Ed H. and Le, Quoc V. and Zhou, Denny , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[7]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[8]
Transactions on Machine Learning Research , issn=
Cognitive Architectures for Language Agents , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[9]
GPTSwarm: language agents as optimizable graphs , year =
Zhuge, Mingchen and Wang, Wenyi and Kirsch, Louis and Faccio, Francesco and Khizbullin, Dmitrii and Schmidhuber, J\". GPTSwarm: language agents as optimizable graphs , year =. Proceedings of the 41st International Conference on Machine Learning , articleno =
-
[10]
2024 , url=
Xuhui Zhou and Hao Zhu and Leena Mathur and Ruohong Zhang and Haofei Yu and Zhengyang Qi and Louis-Philippe Morency and Yonatan Bisk and Daniel Fried and Graham Neubig and Maarten Sap , booktitle=. 2024 , url=
2024
-
[11]
AgentBench: Evaluating
Xiao Liu and Hao Yu and Hanchen Zhang and Yifan Xu and Xuanyu Lei and Hanyu Lai and Yu Gu and Hangliang Ding and Kaiwen Men and Kejuan Yang and Shudan Zhang and Xiang Deng and Aohan Zeng and Zhengxiao Du and Chenhui Zhang and Sheng Shen and Tianjun Zhang and Yu Su and Huan Sun and Minlie Huang and Yuxiao Dong and Jie Tang , booktitle=. AgentBench: Evaluat...
2024
-
[12]
Science China Information Sciences , volume =
The Rise and Potential of Large Language Model Based Agents: A Survey , author =. Science China Information Sciences , volume =. 2025 , doi =
2025
-
[13]
Sirui Hong and Mingchen Zhuge and Jonathan Chen and Xiawu Zheng and Yuheng Cheng and Jinlin Wang and Ceyao Zhang and Zili Wang and Steven Ka Shing Yau and Zijuan Lin and Liyang Zhou and Chenyu Ran and Lingfeng Xiao and Chenglin Wu and J. Meta. The Twelfth International Conference on Learning Representations , year=
-
[14]
Zhang, Ceyao and Yang, Kaijie and Hu, Siyi and Wang, Zihao and Li, Guanghe and Sun, Yihang and Zhang, Cheng and Zhang, Zhaowei and Liu, Anji and Zhu, Song-Chun and Chang, Xiaojun and Zhang, Junge and Yin, Feng and Liang, Yitao and Yang, Yaodong , title =. Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conferen...
-
[15]
arXiv preprint arXiv:2312.10997 , volume=
Retrieval-augmented generation for large language models: A survey , author=. arXiv preprint arXiv:2312.10997 , volume=
-
[16]
Retrieval-augmented generation for knowledge-intensive NLP tasks , year =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-augmented generation for knowledge-intensive NLP tasks , year =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
-
[17]
arXiv preprint arXiv:2205.00445 , year=
MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning , author=. arXiv preprint arXiv:2205.00445 , year=
-
[18]
Frontiers of Computer Science , year=
A survey on large language model based autonomous agents , author=. Frontiers of Computer Science , year=
-
[19]
LLM-powered Autonomous Agents
Weng, Lilian. LLM-powered Autonomous Agents. lilianweng.github.io. 2023
2023
-
[20]
2023 , url=
Guohao Li and Hasan Abed Al Kader Hammoud and Hani Itani and Dmitrii Khizbullin and Bernard Ghanem , booktitle=. 2023 , url=
2023
-
[21]
arXiv preprint arXiv:2310.02172 , year=
Lyfe agents: Generative agents for low-cost real-time social interactions , author=. arXiv preprint arXiv:2310.02172 , year=
-
[22]
C hat D ev: Communicative Agents for Software Development
Qian, Chen and Liu, Wei and Liu, Hongzhang and Chen, Nuo and Dang, Yufan and Li, Jiahao and Yang, Cheng and Chen, Weize and Su, Yusheng and Cong, Xin and Xu, Juyuan and Li, Dahai and Liu, Zhiyuan and Sun, Maosong. C hat D ev: Communicative Agents for Software Development. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguist...
-
[23]
The Twelfth International Conference on Learning Representations , year=
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors , author=. The Twelfth International Conference on Learning Representations , year=
-
[24]
Organization of memory , volume=
Episodic and semantic memory , author=. Organization of memory , volume=. 1972 , publisher=
1972
-
[25]
Psychology of learning and motivation , volume=
Human memory: A proposed system and its control processes , author=. Psychology of learning and motivation , volume=. 1968 , publisher=
1968
-
[26]
Ebbinghaus, Hermann , year=
-
[27]
Zhong, Wanjun and Guo, Lianghong and Gao, Qiqi and Ye, He and Wang, Yanlin , title =. Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence , articleno =. 2024 , isbn =. doi:10....
-
[28]
2014 , publisher=
The ecological approach to visual perception: classic edition , author=. 2014 , publisher=
2014
-
[29]
Artificial intelligence , volume=
Intelligence without representation , author=. Artificial intelligence , volume=. 1991 , publisher=
1991
-
[30]
arXiv preprint arXiv:2401.03568 , year=
Agent ai: Surveying the horizons of multimodal interaction , author=. arXiv preprint arXiv:2401.03568 , year=
-
[31]
A gent G ym: Evaluating and Training Large Language Model-based Agents across Diverse Environments
Xi, Zhiheng and Ding, Yiwen and Chen, Wenxiang and Hong, Boyang and Guo, Honglin and Wang, Junzhe and Guo, Xin and Yang, Dingwen and Liao, Chenyang and He, Wei and Gao, Songyang and Chen, Lu and Zheng, Rui and Zou, Yicheng and Gui, Tao and Zhang, Qi and Qiu, Xipeng and Huang, Xuanjing and Wu, Zuxuan and Jiang, Yu-Gang. A gent G ym: Evaluating and Training...
-
[32]
arXiv preprint arXiv:2312.03664 , year=
Generative agent-based modeling with actions grounded in physical, social, or digital space using Concordia , author=. arXiv preprint arXiv:2312.03664 , year=
-
[33]
M ulti A gent B ench : Evaluating the Collaboration and Competition of LLM agents
Zhu, Kunlun and Du, Hongyi and Hong, Zhaochen and Yang, Xiaocheng and Guo, Shuyi and Wang, Zhe and Wang, Zhenhailong and Qian, Cheng and Tang, Xiangru and Ji, Heng and You, Jiaxuan. M ulti A gent B ench : Evaluating the Collaboration and Competition of LLM agents. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol...
-
[34]
Xu, Lin and Hu, Zhiyuan and Zhou, Daquan and Ren, Hongyu and Dong, Zhen and Keutzer, Kurt and Ng, See-Kiong and Feng, Jiashi. MA g IC : Investigation of Large Language Model Powered Multi-Agent in Cognition, Adaptability, Rationality and Collaboration. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.186...
-
[35]
T -Eval: Evaluating the Tool Utilization Capability of Large Language Models Step by Step
Chen, Zehui and Du, Weihua and Zhang, Wenwei and Liu, Kuikun and Liu, Jiangning and Zheng, Miao and Zhuo, Jingming and Zhang, Songyang and Lin, Dahua and Chen, Kai and Zhao, Feng. T -Eval: Evaluating the Tool Utilization Capability of Large Language Models Step by Step. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistic...
-
[36]
Yujia Qin and Shihao Liang and Yining Ye and Kunlun Zhu and Lan Yan and Yaxi Lu and Yankai Lin and Xin Cong and Xiangru Tang and Bill Qian and Sihan Zhao and Lauren Hong and Runchu Tian and Ruobing Xie and Jie Zhou and Mark Gerstein and dahai li and Zhiyuan Liu and Maosong Sun , booktitle=. Tool. 2024 , url=
2024
-
[37]
From Text to Tactic: Evaluating
Jonathan Light and Min Cai and Sheng Shen and Ziniu Hu , booktitle=. From Text to Tactic: Evaluating. 2023 , url=
2023
-
[38]
2024 , url=
Jinhao Duan and Renming Zhang and James Diffenderfer and Bhavya Kailkhura and Lichao Sun and Elias Stengel-Eskin and Mohit Bansal and Tianlong Chen and Kaidi Xu , booktitle=. 2024 , url=
2024
-
[39]
S ocial B ench: Sociality Evaluation of Role-Playing Conversational Agents
Chen, Hongzhan and Chen, Hehong and Yan, Ming and Xu, Wenshen and Xing, Gao and Shen, Weizhou and Quan, Xiaojun and Li, Chenliang and Zhang, Ji and Huang, Fei. S ocial B ench: Sociality Evaluation of Role-Playing Conversational Agents. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.125
-
[40]
URLhttps://aclanthology.org/2024.tacl-1.9/
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00638
-
[41]
The Fourteenth International Conference on Learning Representations , year=
An Information Theoretic Perspective on Agentic System Design , author=. The Fourteenth International Conference on Learning Representations , year=
-
[42]
Found in the middle: Calibrating Positional Attention Bias Improves Long Context Utilization
Hsieh, Cheng-Yu and Chuang, Yung-Sung and Li, Chun-Liang and Wang, Zifeng and Le, Long and Kumar, Abhishek and Glass, James and Ratner, Alexander and Lee, Chen-Yu and Krishna, Ranjay and Pfister, Tomas. Found in the middle: Calibrating Positional Attention Bias Improves Long Context Utilization. Findings of the Association for Computational Linguistics: A...
-
[43]
ContextAgent: Context-Aware Proactive
Bufang Yang and Lilin Xu and Liekang Zeng and Kaiwei Liu and Siyang Jiang and Wenrui Lu and Hongkai Chen and Xiaofan Jiang and Guoliang Xing and Zhenyu Yan , booktitle=. ContextAgent: Context-Aware Proactive. 2026 , url=
2026
-
[44]
arXiv preprint arXiv:2512.06721 , year=
ProAgent: Harnessing On-Demand Sensory Contexts for Proactive LLM Agent Systems , author=. arXiv preprint arXiv:2512.06721 , year=
-
[45]
arXiv preprint arXiv:2506.12508 , year=
AgentOrchestra: Orchestrating Multi-Agent Intelligence with the Tool-Environment-Agent (TEA) Protocol , author=. arXiv preprint arXiv:2506.12508 , year=
-
[46]
arXiv e-prints , pages=
ProAgentBench: Evaluating llm agents for proactive assistance with real-world data , author=. arXiv e-prints , pages=
-
[47]
arXiv preprint arXiv:2603.25723 , year=
Natural-language agent harnesses , author=. arXiv preprint arXiv:2603.25723 , year=
-
[48]
arXiv preprint arXiv:2510.04618 , year=
Agentic context engineering: Evolving contexts for self-improving language models , author=. arXiv preprint arXiv:2510.04618 , year=
-
[49]
arXiv preprint arXiv:2510.19771 , year=
Beyond reactivity: Measuring proactive problem solving in llm agents , author=. arXiv preprint arXiv:2510.19771 , year=
-
[50]
Gonzalez and Ion Stoica , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging. 2023 , url=
2023
-
[51]
Proactive Agent: Shifting
Yaxi Lu and Shenzhi Yang and Cheng Qian and Guirong Chen and Qinyu Luo and Yesai Wu and Huadong Wang and Xin Cong and Zhong Zhang and Yankai Lin and Weiwen Liu and Yasheng Wang and Zhiyuan Liu and Fangming Liu and Maosong Sun , booktitle=. Proactive Agent: Shifting. 2025 , url=
2025
-
[52]
arXiv preprint arXiv:2302.02083 , volume=
Theory of mind may have spontaneously emerged in large language models , author=. arXiv preprint arXiv:2302.02083 , volume=
-
[53]
Neural Theory-of-Mind? On the Limits of Social Intelligence in Large LM s
Sap, Maarten and Le Bras, Ronan and Fried, Daniel and Choi, Yejin. Neural Theory-of-Mind? On the Limits of Social Intelligence in Large LM s. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.248
-
[54]
Minding Language Models' (Lack of) Theory of Mind: A Plug-and-Play Multi-Character Belief Tracker
Sclar, Melanie and Kumar, Sachin and West, Peter and Suhr, Alane and Choi, Yejin and Tsvetkov, Yulia. Minding Language Models' (Lack of) Theory of Mind: A Plug-and-Play Multi-Character Belief Tracker. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.780
-
[55]
arXiv preprint arXiv:2302.08399 , year=
Large language models fail on trivial alterations to theory-of-mind tasks , author=. arXiv preprint arXiv:2302.08399 , year=
-
[56]
FANT o M : A Benchmark for Stress-testing Machine Theory of Mind in Interactions
Kim, Hyunwoo and Sclar, Melanie and Zhou, Xuhui and Bras, Ronan and Kim, Gunhee and Choi, Yejin and Sap, Maarten. FANT o M : A Benchmark for Stress-testing Machine Theory of Mind in Interactions. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.890
-
[57]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei. Evaluating Very Long-Term Conversational Memory of LLM Agents. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.747
-
[58]
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
Wang, Lei and Xu, Wanyu and Lan, Yihuai and Hu, Zhiqiang and Lan, Yunshi and Lee, Roy Ka-Wei and Lim, Ee-Peng. Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.147
-
[59]
arXiv preprint arXiv:2601.20465 , year=
BMAM: Brain-inspired Multi-Agent Memory Framework , author=. arXiv preprint arXiv:2601.20465 , year=
-
[60]
2024 , note=
Building Effective Agents , author=. 2024 , note=
2024
-
[61]
2026 , month =
Interaction Models: A Scalable Approach to. 2026 , month =
2026
-
[62]
Joe Qin , booktitle=
Zongxi Li and Yang Li and Haoran Xie and S. Joe Qin , booktitle=. CondAmbig. 2025 , url=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.