SmellBench: Towards Fine-Grained Evaluation of Code Agents on Refactoring Tasks
Pith reviewed 2026-06-28 00:48 UTC · model grok-4.3
The pith
Code agents eliminate only half of injected code smells because they focus locally and miss cross-file issues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
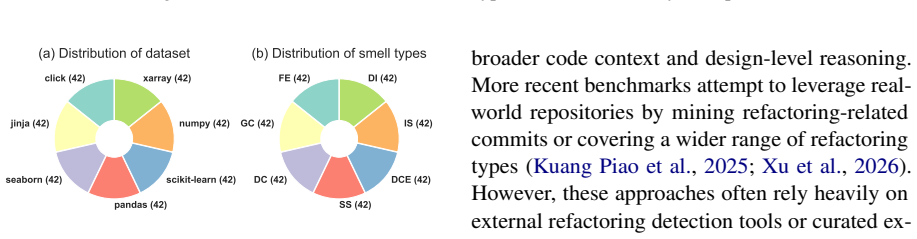
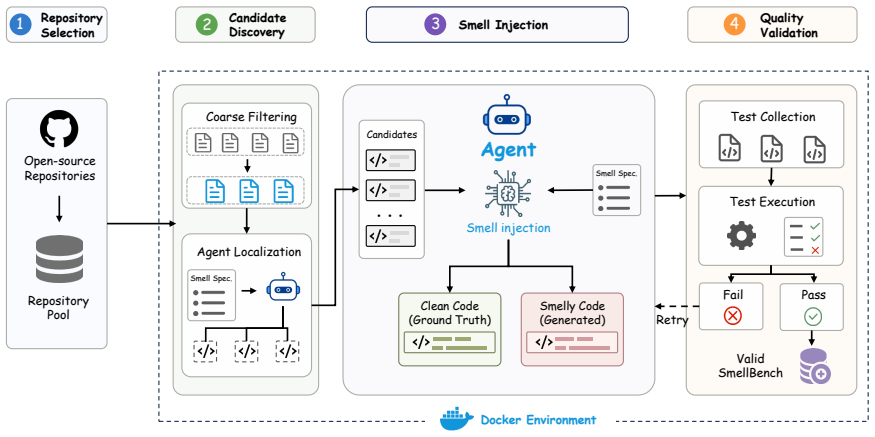
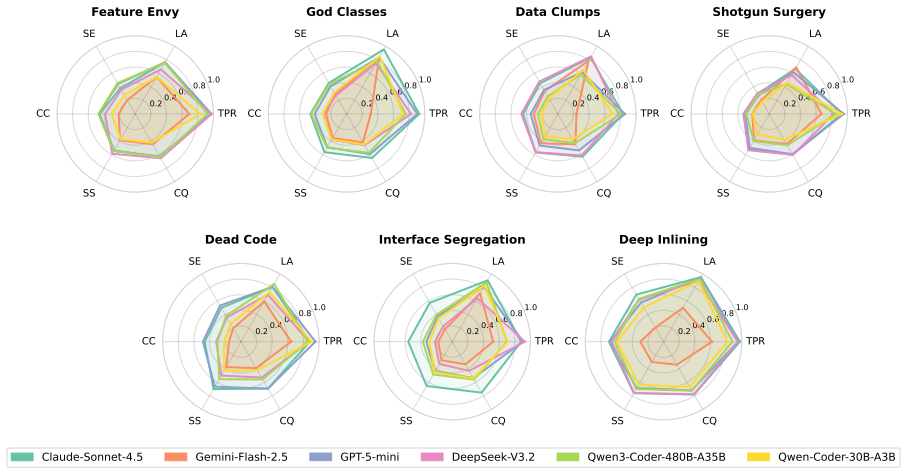
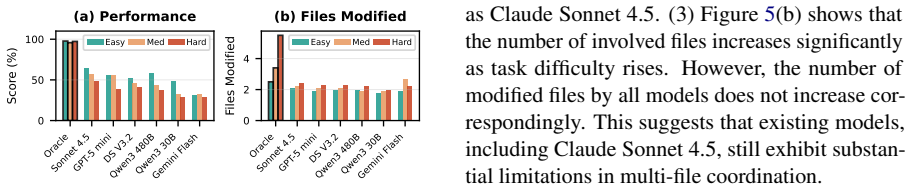
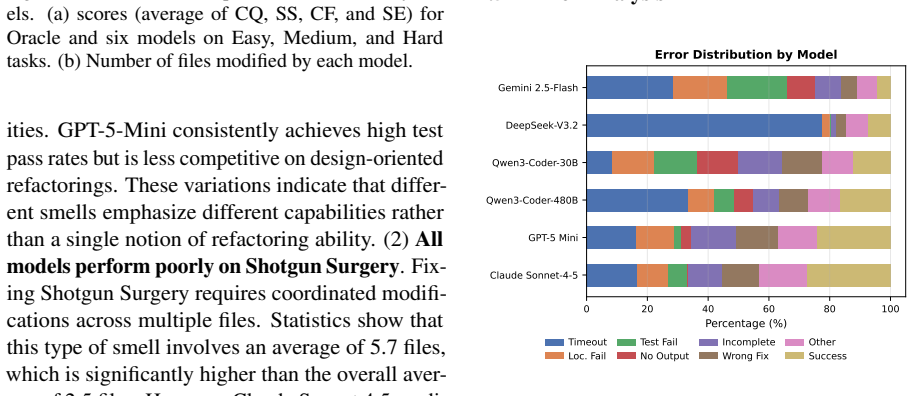
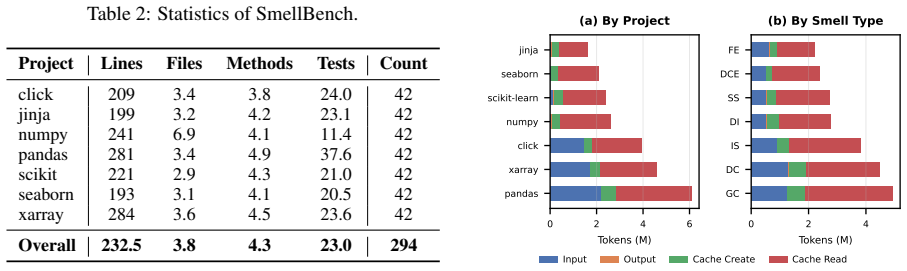
SmellBench generates 294 controlled refactoring cases by injecting seven code smell types into clean snippets drawn from seven real-world repositories, with three difficulty levels and human-written ground truth. The benchmark measures agents on functional correctness, smell localization, and refactoring quality. Tests of two popular agents paired with six LLMs show the top result is a 50.34 smell-elimination score, with the shortfall explained by a tendency to handle only local smells and a corresponding lack of cross-file understanding.
What carries the argument
SmellBench, the benchmark that creates refactoring cases by proactively injecting code smells into clean code snippets from real repositories and supplies human ground truth.
If this is right
- Agents that pass functional tests can still leave many code smells unresolved.
- Performance is lower on cases that require understanding smells across multiple files.
- Fine-grained metrics for localization and quality reveal weaknesses hidden by correctness-only tests.
- The benchmark design supports controlled experiments on specific smell types and difficulty levels.
Where Pith is reading between the lines
- Agents may need explicit multi-file context mechanisms to reach higher smell-elimination scores.
- The same injection method could be applied to other languages or additional smell categories to test generality.
- Teams relying on agents for code changes should add separate maintainability checks that span files.
Load-bearing premise
Injecting code smells into clean snippets taken from real repositories produces cases whose human-written ground truth accurately captures real maintainability problems.
What would settle it
A direct comparison in which human developers refactor the same 294 injected-smell cases and are scored on smell elimination; a large gap above 50.34 would indicate the benchmark cases do not reflect typical human refactoring difficulty.
Figures












read the original abstract
Code Agents have achieved remarkable advances in recent years, exhibiting strong capabilities across a wide range of software engineering tasks. However, their misuse often produces bloated and disorganized code that impairing readability, extensibility, and robustness. Despite this risk, existing benchmarks largely evaluate functional correctness rather than long-term maintainability of code agents. In this paper, we propose SmellBench, an extensible code refactoring benchmark that proactively injects code smells into clean code snippets from real-world repositories. This design enables the generation of controlled, high-quality, and diverse refactoring cases with human-written ground truth. Specifically, it contains 294 cases spanning 7 popular smell types, 3 difficulty levels, 2 instruction settings across 7 real-world repositories. We further design 3 evaluation aspects covering functional correctness, localization ability, and refactoring quality assessment. Experiments with 2 popular agents and 6 large langauge models (LLMs) show that the best combination - Qwen Code + Claude Sonnet 4.5 - achieved only a 50.34 score of smell elimination. Further analysis reveals that this gap arises from a focus on local code smells and a lack of cross-file understanding, which hinders comprehensive smell elimination.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SmellBench, a benchmark for evaluating code agents on refactoring by proactively injecting 7 code smell types into clean snippets drawn from 7 real-world repositories, yielding 294 cases with 3 difficulty levels, 2 instruction settings, and human-written ground truth. It defines three evaluation aspects (functional correctness, localization, refactoring quality) and reports experiments on 2 agents and 6 LLMs, with the best result (Qwen Code + Claude Sonnet 4.5) reaching a 50.34 smell-elimination score; the performance gap is attributed to agents focusing on local smells and lacking cross-file understanding.
Significance. If the injected-smell cases and ground truth are shown to be faithful proxies for real maintainability issues, the benchmark would fill a gap by shifting evaluation from functional correctness to long-term code quality, offering a controlled testbed for refactoring capabilities in code agents.
major comments (3)
- [Benchmark construction] Benchmark construction (abstract and § on SmellBench design): the claim that proactive smell injection 'enables the generation of controlled, high-quality, and diverse refactoring cases with human-written ground truth' lacks any described validation that (a) the 7 injected smell types match smells that developers actually refactor in practice, (b) the human ground truth represents the minimal or correct fix, or (c) the resulting cases exhibit the claimed diversity in maintainability impact.
- [Experiments and analysis] Experiments and analysis (abstract and results section): the attribution of the 50.34 score gap to 'a lack of cross-file understanding' is unsupported because the paper does not report what fraction of the 294 cases actually require cross-file context (snippets are drawn from repositories, but no statistics on multi-file dependencies or cross-file smell interactions are provided).
- [Evaluation metrics] Evaluation metrics (abstract): the headline '50.34 score of smell elimination' is presented without details on its exact definition, aggregation across the three evaluation aspects, variance across runs, or statistical significance, making it impossible to assess whether the reported performance difference is robust.
minor comments (2)
- [Abstract] Abstract contains a typo: 'large langauge models' should be 'large language models'.
- [Abstract] Abstract sentence 'their misuse often produces bloated and disorganized code that impairing readability' has a grammatical error ('that impairing' should be 'that impairs').
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, with clear indications of planned revisions.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction (abstract and § on SmellBench design): the claim that proactive smell injection 'enables the generation of controlled, high-quality, and diverse refactoring cases with human-written ground truth' lacks any described validation that (a) the 7 injected smell types match smells that developers actually refactor in practice, (b) the human ground truth represents the minimal or correct fix, or (c) the resulting cases exhibit the claimed diversity in maintainability impact.
Authors: The seven smell types were selected from well-established sources in the literature, including Fowler's refactoring catalog and empirical studies on smell prevalence in open-source projects. We will add explicit citations and a short justification subsection in the revised SmellBench design section. The ground-truth refactorings were authored by experienced developers following standard practices to eliminate the injected smell while preserving original behavior; we will clarify that these represent one valid (not necessarily the unique minimal) fix. For diversity and maintainability impact, the current design varies repositories, difficulty levels, and instruction settings; we will augment the manuscript with quantitative indicators such as changes in cyclomatic complexity and code size to better support the diversity claim. revision: partial
-
Referee: [Experiments and analysis] Experiments and analysis (abstract and results section): the attribution of the 50.34 score gap to 'a lack of cross-file understanding' is unsupported because the paper does not report what fraction of the 294 cases actually require cross-file context (snippets are drawn from repositories, but no statistics on multi-file dependencies or cross-file smell interactions are provided).
Authors: We agree that quantitative support would strengthen the attribution. Although each benchmark case is a single-file snippet, the snippets originate from multi-file repositories. In the revised manuscript we will add an analysis subsection reporting the fraction of cases that involve cross-file dependencies (measured via import graphs and potential smell propagation) and will tie these statistics directly to the observed agent behavior. revision: yes
-
Referee: [Evaluation metrics] Evaluation metrics (abstract): the headline '50.34 score of smell elimination' is presented without details on its exact definition, aggregation across the three evaluation aspects, variance across runs, or statistical significance, making it impossible to assess whether the reported performance difference is robust.
Authors: The smell-elimination score is defined in the Evaluation Metrics section as the unweighted average of the three aspects (functional correctness, localization accuracy, and refactoring quality). We will revise the abstract to include a concise definition of the aggregate score. In addition, the results section will be expanded to report run-to-run variance and to include statistical significance tests (e.g., paired t-tests) comparing agent-LLM combinations. revision: yes
Circularity Check
No circularity: empirical benchmark scores are direct measurements
full rationale
The paper constructs SmellBench by injecting 7 smell types into clean snippets from 7 repositories to create 294 cases with human-written ground truth, then directly measures agent performance (e.g., 50.34 smell-elimination score for Qwen Code + Claude Sonnet 4.5) across functional correctness, localization, and refactoring quality. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the derivation; the reported scores and analysis of local vs. cross-file focus are straightforward empirical outcomes on the constructed cases rather than quantities forced by definition or prior self-referential results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Code smells can be injected into clean real-world code while preserving original functionality and allowing human-written ground-truth refactors.
Reference graph
Works this paper leans on
-
[1]
Refactorbench: Evaluating stateful reason- ing in language agents through code.arXiv preprint arXiv:2503.07832. Harbor Framework Team. 2026. Harbor: A framework for evaluating and optimizing agents and models in container environments. Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar- Lezama, Koushik Sen, and...
-
[2]
Repobench: Benchmarking repository-level code auto-completion systems.arXiv preprint arXiv:2306.03091. Mike A. Merrill, Alexander G. Shaw, Nicholas Car- lini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Je- nia Jitsev,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Table 2: Statistics of SmellBench. Project Lines Files Methods Tests Count click 209 3.4 3.8 24.0 42 jinja 199 3.2 4.2 23.1 42 numpy 241 6.9 4.1 11.4 42 pandas 281 3.4 4.9 37.6 42 scikit 221 2.9 4.3 21.0 42 seaborn 193 3.1 4.1 20.5 42 xarray 284 3.6 4.5 23.6 42 Overall 232.5 3.8 4.3 23.0 294 John Yan...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
instance_id
Calling Chain Overview . . . if cmd is not None and cmd_name != original_cmd_name: alt_cmd = self.get_command(ctx, original_cmd_name) if alt_cmd is not None and alt_cmd is not cmd: resolved_name = _check_command_alias_conflict( cmd_name, original_cmd_name, self.list_commands(ctx) ) if resolved_name is not None: cmd_name = resolved_name cmd = self.get_comm...
-
[5]
instance_id
Calling Chain Overview . . . if resolution_mode is None: resolution = _RESOLUTION_MODE . . . policy: _ContextResolutionPolicy | None = None if resolution_mode is not ResolutionMode.STANDARD: policy = _ContextResolutionPolicy(resolution_mode) . . . if policy is not None: policy.enter_content(ctx) . . . return _validator_context_resolution(ctx, policy, args...
-
[6]
instance_id
Calling Chain Overview resolvers = _command_resolver.get_resolvers(_command_resolver.active_mode) . . . if resolvers: metadata = get_resolution_metadata() for resolver in resolvers: resolved_name, resolved_cmd = resolver( cmd_name, self, ctx, metadata ) if resolved_cmd is not None: return resolved_name, resolved_cmd, args[1:] . . . “instance_id”: “click-d...
-
[7]
Based on file names and module structure, pick the 3-5 most promising files
-
[8]
Use ‘grep‘ to quickly locate class definitions, large methods, and cross-module interactions
-
[9]
Only read specific sections of files (use line ranges) to verify candidates
-
[10]
[ SMELL_TYPE ]
Prioritize files with core business logic (e.g., core.py, models.py, engine.py) over peripherals ## Requirements Find exactly 5 candidates. Each candidate should be a method/class where injecting ‘[SMELL_TYPE]‘ would be **easy and natural** — meaning the surrounding code structure supports the injection without breaking functionality. Each candidate needs...
-
[11]
**Fix the failing tests while preserving the code smell injection** — the smell pattern must remain
-
[12]
The code must compile/run correctly
-
[13]
**DO NOT remove or refactor the smell** — you are fixing test failures, not improving code quality
-
[14]
DO NOT create new files
-
[15]
DO NOT run any test commands (pytest, unittest, etc.)
-
[16]
smell_type
Make **minimal changes** — only fix what’s broken, keep the smell as you originally injected it After making your fixes, output the same JSON format as before: { " smell_type " : " Type name " , " hint_targeted " : " ..." , " hint_guided " : " ..." , " smell_function " : [ " absolute / path / to / file " , " ClassName " , " methodName " ] , " test_functio...
-
[17]
smell_type
**Overall smell pattern**: Summarize how these changes work together to create the "smell_type" smell. What design principle is violated?
-
[18]
Which changes are the **root cause** of the smell, and which are just supporting noise?
**Severity ranking**: Rank the changes from most to least important. Which changes are the **root cause** of the smell, and which are just supporting noise?
-
[19]
**What was degraded overall**: What concrete qualities of the codebase were harmed? Be specific about the impact on maintainability, coupling, cohesion, etc
-
[20]
Do NOT wrap the output in a code block
**Key evaluation signals**: When judging whether a candidate fix truly addresses this smell, what should matter most? What would distinguish a thorough fix from a superficial one? ## Output Format Return your result using XML tags. Do NOT wrap the output in a code block. <analysis> Your full analysis text as described above. Write freely — no escaping nee...
-
[21]
Read and understand the relevant code in the project
-
[22]
Identify the code smell and understand why it is problematic
-
[23]
Refactor the code to eliminate the smell while preserving all existing behavior
-
[24]
[smell_type]
Ensure all tests continue to pass after your changes. ### Constraints - Do not change the original program behavior. - Preserve the original control flow, inputs, and outputs. ### IMPORTANT You are allowed to perform any operations, such as checking or modifying related files, without prior approval from me. ### Response Figure 17: Task instruction prompt...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.