Predictable Scaling Laws of Optimal Hyperparameters for LLM Continued Pre-training
Pith reviewed 2026-06-28 01:50 UTC · model grok-4.3
The pith
Optimal hyperparameters for LLM continued pre-training follow stable scaling laws discoverable from small proxy models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
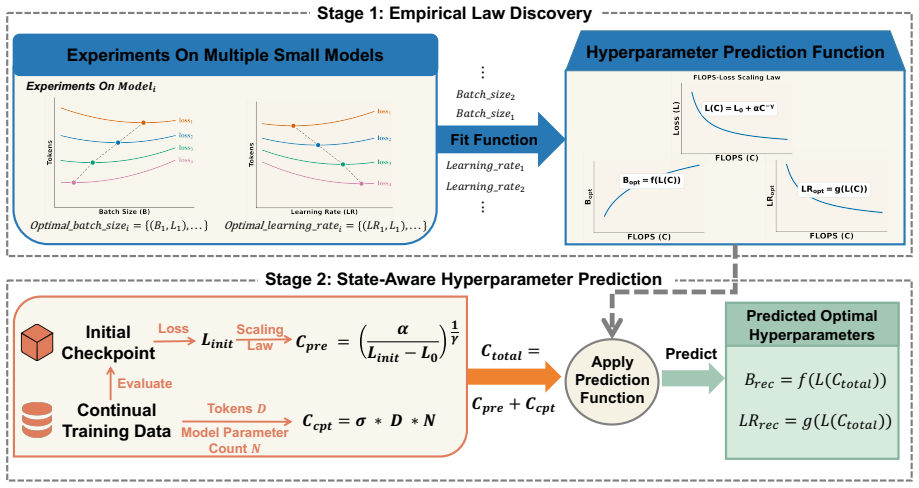
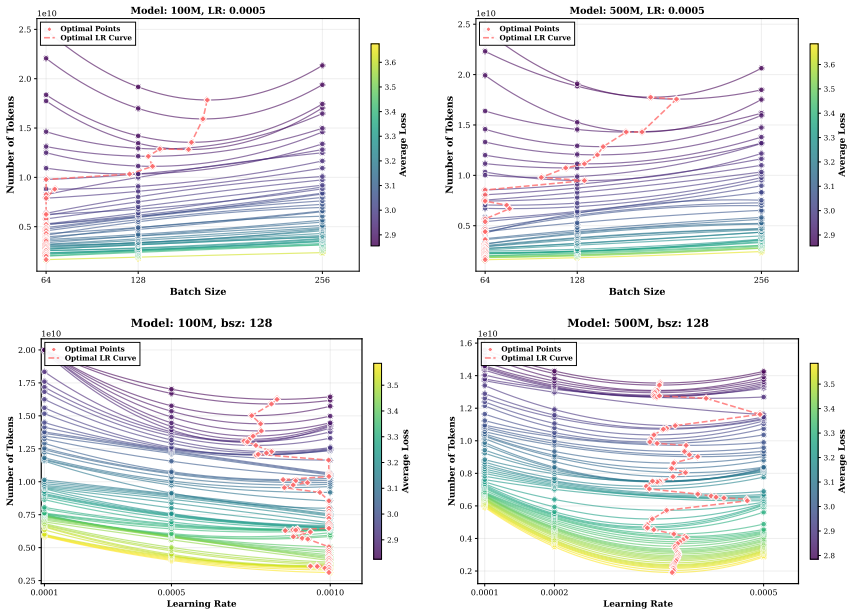
Optimal hyperparameters follow stable and predictable scaling laws throughout the continued pre-training process. The two-stage framework first trains small proxy models to obtain functions mapping compute budget to optimal hyperparameters, then uses the inverse scaling law on a checkpoint's validation loss to estimate its equivalent pre-training compute; the sum of that quantity and the new budget yields the predicted optimal settings for the target model.
What carries the argument
Inverse scaling law that converts a checkpoint's validation loss into an estimate of its equivalent pre-training compute, combined with proxy-derived functions that map total compute to optimal learning rate and batch size.
If this is right
- Hyperparameter search overhead drops by up to 90 percent for continued pre-training runs.
- Performance matches or exceeds that of standard grid-search baselines.
- The approach applies to any starting checkpoint and generalizes across model architectures.
Where Pith is reading between the lines
- The same proxy-plus-inversion pattern could be tested on other training phases such as supervised fine-tuning if analogous loss-compute relations exist.
- Training budgets for multi-stage LLM pipelines could be planned in advance with far less repeated search.
- Continued pre-training would behave more like an extension of the original pre-training curve than a separate tuning task.
Load-bearing premise
Scaling laws found on small proxy models will continue to hold for large target models, and a checkpoint's validation loss can be inverted to recover an accurate equivalent pre-training compute value.
What would settle it
Apply the full prediction procedure to a large target model, then train two versions of that model—one with the predicted hyperparameters and one with hyperparameters found by exhaustive search on the identical run—and observe whether the predicted version reaches substantially lower final performance.
Figures


read the original abstract
The efficacy of continued pre-training for Large Language Models (LLMs) hinges upon hyperparameter configurations, such as learning rate and batch size. However, current practices often rely on heuristics or grid searches, leading to training instability and excessive costs. In this work, we first empirically discover that optimal hyperparameters follow stable and predictable scaling laws throughout the continued pre-training process. Leveraging these insights, we propose a novel framework to establish quantitative relationships between compute budget and optimal hyperparameters for a given checkpoint. Our approach has two stages: (1) \textit{Empirical Law Discovery}, where we train small-scale proxy models to derive functions mapping compute budget to optimal hyperparameters via standard loss-compute scaling laws; and (2) \textit{State-Aware Hyperparameter Prediction}, where we evaluate an initial checkpoint's validation loss and use the inverse scaling law to estimate its \textit{equivalent pre-training compute} -- the compute needed to achieve the same loss from scratch. Combining this with the planned compute budget, we predict optimal hyperparameters for the target run. Empirical results demonstrate that our method reduces the hyperparameter search overhead by up to 90\% while achieving comparable or superior performance relative to baselines. This model-agnostic framework generalizes across architectures, providing a principled and efficient methodology for diverse continued pre-training scenarios starting from any given point.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that optimal learning rate and batch size for LLM continued pre-training obey stable scaling laws that can be discovered on small proxy models; it introduces a two-stage framework (Empirical Law Discovery via loss-compute scaling laws, followed by State-Aware Hyperparameter Prediction that inverts the scaling law on a checkpoint's validation loss to recover equivalent pre-training compute) to predict target hyperparameters from a given compute budget, reporting up to 90% reduction in search overhead with comparable or better performance.
Significance. If the proxy-to-target transfer holds, the framework would materially reduce the cost of hyperparameter selection in continued pre-training, a frequent and expensive step in LLM pipelines. The approach is model-agnostic in principle and supplies an explicit quantitative link between compute budget and optimal hyperparameters.
major comments (2)
- [Abstract / Empirical Law Discovery] Abstract, Empirical Law Discovery stage: scaling laws for optimal LR and batch size are fitted exclusively on small-scale proxy models, yet the manuscript contains no direct transfer experiment in which the predicted hyperparameters are applied to a large target model (> few B parameters) and compared against exhaustive search or strong baselines on that same model and data regime. This extrapolation is load-bearing for both the generalization claim and the 90% overhead reduction.
- [Abstract / State-Aware Hyperparameter Prediction] Abstract, State-Aware Hyperparameter Prediction stage: the inverse scaling law used to estimate equivalent pre-training compute from validation loss is derived and tested only at proxy scale; no evidence is provided that the recovered compute value remains accurate for checkpoints originating from larger models or different data mixtures, undermining the quantitative relationship asserted between budget and hyperparameters.
minor comments (2)
- [Abstract] The abstract states the framework is 'model-agnostic' and 'generalizes across architectures,' but the specific model families, sizes, and datasets used for the proxy experiments and any limited target tests are not enumerated.
- [Abstract] Empirical results are summarized without reference to error bars, number of runs, or statistical tests supporting the 'comparable or superior performance' claim.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the key points where the scope of our empirical validation requires clearer articulation. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Empirical Law Discovery] Abstract, Empirical Law Discovery stage: scaling laws for optimal LR and batch size are fitted exclusively on small-scale proxy models, yet the manuscript contains no direct transfer experiment in which the predicted hyperparameters are applied to a large target model (> few B parameters) and compared against exhaustive search or strong baselines on that same model and data regime. This extrapolation is load-bearing for both the generalization claim and the 90% overhead reduction.
Authors: The referee correctly notes that all reported experiments use proxy models. The manuscript does not contain direct transfer experiments that apply the predicted hyperparameters to models larger than a few billion parameters and compare them against exhaustive search on the same large model and data. Our defense rests on the observation that the scaling laws were recovered consistently across multiple proxy scales and architectures, which we take as evidence that the functional forms are stable. Nevertheless, we agree that this leaves the extrapolation to truly large targets as an assumption rather than a directly verified result. In revision we will (a) state the exact parameter ranges used for the proxy models in the abstract and main text and (b) add an explicit limitations paragraph discussing the untested regime. revision: yes
-
Referee: [Abstract / State-Aware Hyperparameter Prediction] Abstract, State-Aware Hyperparameter Prediction stage: the inverse scaling law used to estimate equivalent pre-training compute from validation loss is derived and tested only at proxy scale; no evidence is provided that the recovered compute value remains accurate for checkpoints originating from larger models or different data mixtures, undermining the quantitative relationship asserted between budget and hyperparameters.
Authors: We agree that the inverse scaling law (mapping validation loss back to equivalent pre-training compute) is derived and validated exclusively on the same proxy-scale checkpoints. No experiments are presented that test whether the recovered compute estimate remains accurate when the checkpoint comes from a larger model or from a different data mixture. This is a genuine limitation of the current evidence. In the revision we will restrict the claims about the State-Aware stage to the proxy regime in which it was tested and add a short discussion of the additional assumptions required for transfer to larger models or shifted data distributions. revision: yes
Circularity Check
No significant circularity; derivation relies on empirical proxy fits for extrapolation
full rationale
The paper's chain consists of training small proxy models to fit scaling laws (loss vs. compute and optimal hyperparameters vs. compute), then applying the inverse of the loss-compute relation to estimate equivalent pre-training compute for a checkpoint and combining it with a target budget to select hyperparameters. This is a standard empirical extrapolation procedure rather than any reduction of the claimed predictions to the fitted inputs by definition or construction. No self-citations, uniqueness theorems, or ansatzes are invoked in the abstract or described stages, and the central performance claims rest on reported empirical results rather than tautological reuse of the same data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[2]
Training Compute-Optimal Large Language Models
Training Compute-Optimal Large Language Models , author=. arXiv preprint arXiv:2203.15556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[4]
arXiv preprint arXiv:2310.02244 , year=
Tensor Programs VI: Feature Learning in Infinite-Depth Neural Networks , author=. arXiv preprint arXiv:2310.02244 , year=
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Scaling Data-Constrained Language Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[6]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[7]
Nature Machine Intelligence , year=
Densing Law of LLMs , author=. Nature Machine Intelligence , year=
-
[8]
arXiv preprint arXiv:2401.00448 , year=
Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws , author=. arXiv preprint arXiv:2401.00448 , year=
-
[9]
arXiv preprint arXiv:2308.04014 , year=
Continual Pre-Training of Large Language Models: How to (re) warm your model? , author=. arXiv preprint arXiv:2308.04014 , year=
-
[10]
International Conference on Learning Representations (ICLR) , year=
Simple and Scalable Strategies to Continually Pre-train Large Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[11]
arXiv preprint arXiv:2404.01230 , year=
Beyond Chinchilla-Optimal: Scaling Laws for Continued Training , author=. arXiv preprint arXiv:2404.01230 , year=
-
[12]
Advances in Neural Information Processing Systems (NeurIPS) , year=
DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[13]
International Conference on Learning Representations (ICLR) , year=
Continual Pre-training of Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[14]
arXiv preprint arXiv:2407.07263 , year=
Reuse, Don't Retrain: A Recipe for Continued Pretraining of Language Models , author=. arXiv preprint arXiv:2407.07263 , year=
-
[15]
arXiv preprint arXiv:2405.12345 , year=
Optimal Hyperparameters for Continued Training of Language Models , author=. arXiv preprint arXiv:2405.12345 , year=
-
[16]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism , author=. arXiv preprint arXiv:2401.02954 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies , author=. arXiv preprint arXiv:2404.06395 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
arXiv preprint arXiv:2503.04715 , year=
Predictable Scale: Part I, Step Law -- Optimal Hyperparameter Scaling Law in Large Language Model Pretraining , author=. arXiv preprint arXiv:2503.04715 , year=
-
[19]
International Conference on Learning Representations (ICLR) , year=
How Does Critical Batch Size Scale in Pre-training? , author=. International Conference on Learning Representations (ICLR) , year=
-
[20]
arXiv preprint arXiv:2412.01505 , year=
Scaling Law for Language Models Training Considering Batch Size , author=. arXiv preprint arXiv:2412.01505 , year=
-
[21]
arXiv preprint arXiv:2410.05192 , year=
Understanding Warmup-Stable-Decay Learning Rates: A River Valley Loss Landscape Perspective , author=. arXiv preprint arXiv:2410.05192 , year=
-
[22]
arXiv preprint arXiv:2502.15938 , year=
Why Linearly Decaying the Learning Rate to Zero Works Best , author=. arXiv preprint arXiv:2502.15938 , year=
-
[23]
arXiv preprint arXiv:2505.23971 , year=
Critical Batch Size Revisited: A Simple Empirical Approach to Large-Batch Language Model Training , author=. arXiv preprint arXiv:2505.23971 , year=
-
[24]
arXiv preprint arXiv:2408.13359 , year=
Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler , author=. arXiv preprint arXiv:2408.13359 , year=
-
[25]
arXiv preprint arXiv:2405.15682 , year=
The Road Less Scheduled , author=. arXiv preprint arXiv:2405.15682 , year=
-
[26]
arXiv preprint arXiv:2507.17634 , year=
WSM: Decay-Free Learning Rate Schedule via Checkpoint Merging for LLM Pre-training , author=. arXiv preprint arXiv:2507.17634 , year=
-
[27]
International Conference on Learning Representations (ICLR) , year=
SGDR: Stochastic Gradient Descent with Warm Restarts , author=. International Conference on Learning Representations (ICLR) , year=
-
[28]
An Empirical Model of Large-Batch Training
An Empirical Model of Large-Batch Training , author=. arXiv preprint arXiv:1812.06162 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
International Conference on Machine Learning (ICML) , year=
Scaling Exponents Across Parameterizations and Optimizers , author=. International Conference on Machine Learning (ICML) , year=
-
[30]
arXiv preprint arXiv:2304.03208 , year=
Cerebras-GPT: Open Compute-Optimal Language Models Trained on the Cerebras Wafer-Scale Cluster , author=. arXiv preprint arXiv:2304.03208 , year=
-
[31]
arXiv preprint , year=
GQA- P: The Maximal Parameterization Update for Grouped Query Attention and Fully Sharded Data Parallel , author=. arXiv preprint , year=
-
[32]
npj Computational Materials , volume=
Fine-tuning large language models for domain adaptation: Exploration of training strategies, scaling, model merging and synergistic capabilities , author=. npj Computational Materials , volume=
-
[33]
Code Llama: Open Foundation Models for Code
Code Llama: Open Foundation Models for Code , author=. arXiv preprint arXiv:2308.12950 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
International Conference on Learning Representations (ICLR) , year=
Llemma: An Open Language Model For Mathematics , author=. International Conference on Learning Representations (ICLR) , year=
-
[35]
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning , author=. arXiv preprint arXiv:2308.08747 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Advances in neural information processing systems , volume=
Redpajama: an open dataset for training large language models , author=. Advances in neural information processing systems , volume=
-
[37]
arXiv preprint arXiv:2310.06786 , year=
Openwebmath: An open dataset of high-quality mathematical web text , author=. arXiv preprint arXiv:2310.06786 , year=
-
[38]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[39]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Mathqa: Towards interpretable math word problem solving with operation-based formalisms , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
2019
-
[42]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Hellaswag: Can a machine really finish your sentence? , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[43]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[44]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[45]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Scaling laws for transfer , author=. arXiv preprint arXiv:2102.01293 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
Can a suit of armor conduct electricity? a new dataset for open book question answering , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
2018
-
[50]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. arXiv preprint arXiv:2403.07974 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.