What's in a Name? Morphological Shortcuts by LLMs in Pharmacology
Pith reviewed 2026-06-28 01:47 UTC · model grok-4.3
The pith
Large language models often determine drug meanings from affixes in their names rather than full context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that LLMs induce drug meaning primarily through affix cues in pharmacology, rarely indicate this reliance explicitly, and sometimes incorrectly conflate properties among affix-sharing drugs. This is evidenced by behavioral experiments with fictitious drugs and confirmed through activation patching that localizes the behavior to early-mid layers.
What carries the argument
The framework for identifying whether drug semantics are driven by the affix, the stem, or the full drug name, which separates morphological shortcut effects from other influences.
If this is right
- Models generate plausible clinical content for fictitious drugs based solely on affixes.
- Affix signals elicit class-level pharmacological responses without full name context.
- The reliance on affixes is not usually stated by the models.
- Conflation of properties occurs among drugs sharing affixes.
- Activation patching shows this behavior originates in early-mid layers.
Where Pith is reading between the lines
- Similar morphological shortcuts could affect LLM performance in other technical fields like chemistry.
- Developers might need to audit training data for affix-pattern biases to reduce such reliance.
- Clinicians using LLMs for drug queries should cross-check outputs against full name semantics.
Load-bearing premise
That responses to fictitious drug names built from real affixes isolate affix-driven semantics without confounding effects from other linguistic patterns or model training data overlaps.
What would settle it
A test where models are prompted with two fictitious drugs sharing an affix but assigned conflicting properties in the prompt, and checking if they still follow the affix cue or adapt to the new information.
Figures

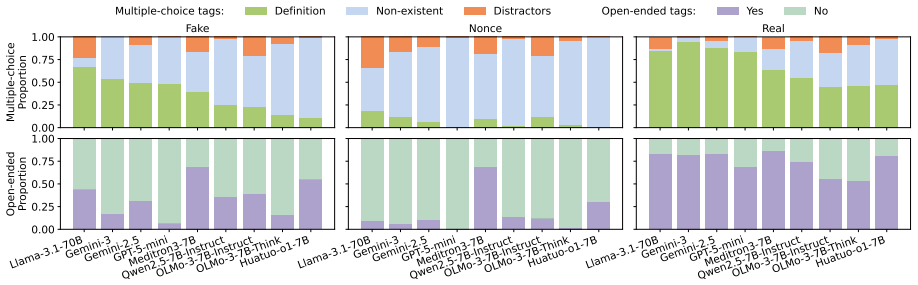
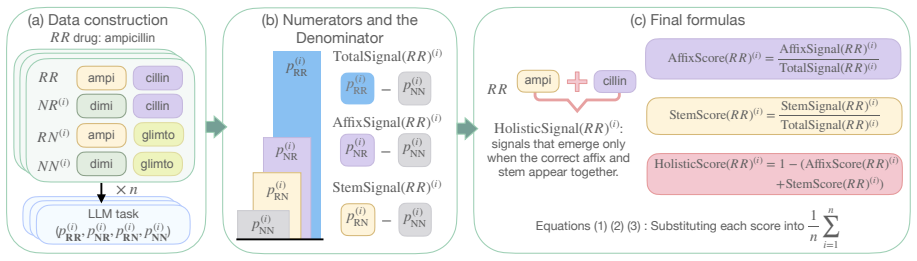
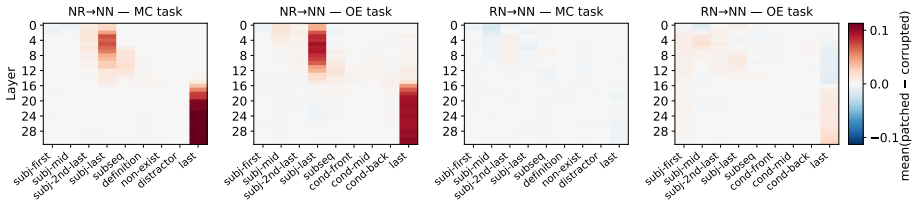
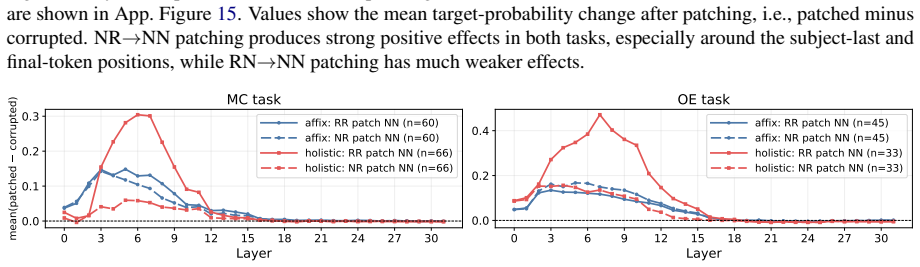



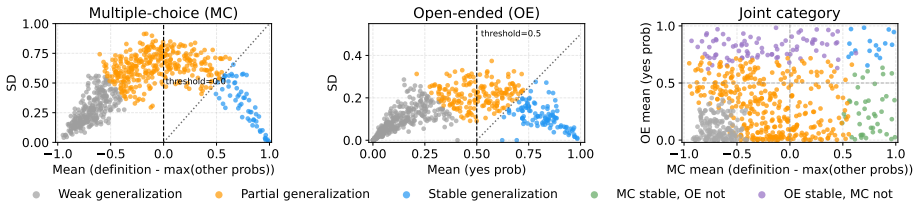
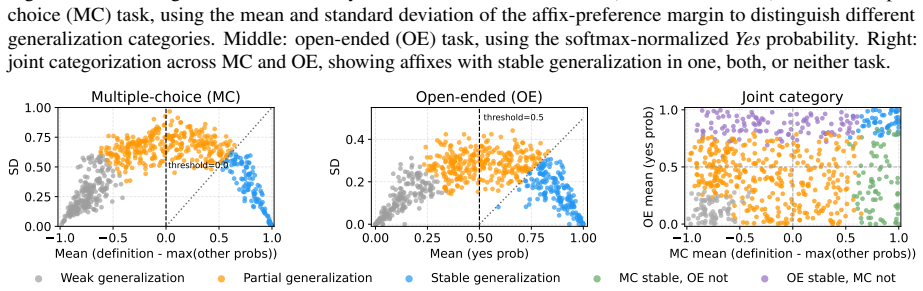








read the original abstract
The morphological form of a word can often give cues to its meaning, but purely relying on these mappings can lead to overgeneralization in high-stakes domains. In the medical domain, for instance, LLMs can confidently reason about fictitious drugs from their affixes alone (e.g., wugcillin) and generate plausible-looking clinical content. We present a behavioral and mechanistic study of LLM "affix heuristics" in pharmacology. Using fictitious drug names built from real affixes, we show that affix signals alone elicit class-level pharmacological responses. We introduce a framework for identifying whether a model's drug semantics are driven mainly by the affix, the stem, or the drug name as a whole. Applied across 653 drugs, our framework reveals that models often induce drug meaning primarily through affix cues, yet rarely explicitly indicate this reliance, and sometimes incorrectly conflate properties among affix-sharing drugs. Activation patching across models further localizes this behavior to early-mid layers. These findings show that morphological shortcuts pose a subtle but measurable risk to safety.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a behavioral and mechanistic investigation of morphological 'affix heuristics' in LLMs applied to pharmacology. Using fictitious drug names constructed from real affixes (e.g., 'wugcillin'), it demonstrates that affix signals alone can elicit class-level pharmacological responses. A framework is introduced to attribute drug semantics primarily to the affix, stem, or full name; when applied to 653 drugs, it finds that models predominantly rely on affix cues, rarely state this reliance explicitly, and sometimes conflate properties across affix-sharing drugs. Activation patching localizes the behavior to early-to-mid layers, with the conclusion that such shortcuts represent a measurable safety risk.
Significance. If the central isolation of affix effects holds, the work provides concrete evidence of a subtle but systematic failure mode in high-stakes medical reasoning, supported by scale (653 drugs) and mechanistic localization via activation patching. This strengthens the case for targeted interpretability interventions in domain-specific LLM applications and offers falsifiable predictions about layer-wise morphological sensitivity.
major comments (2)
- [§3] §3 (Framework for attributing semantics): The claim that responses to fictitious names isolate affix-driven semantics rests on the assumption that novel stems carry no residual distributional signals, n-gram overlaps, or affix-stem co-occurrence statistics from pretraining. Without reported controls (e.g., stem perplexity matching, n-gram frequency audits, or ablation on stem-only baselines), the class-level pharmacological outputs and the 'primarily through affix cues' finding for the 653-drug corpus could reflect confounds rather than pure affix heuristics. This is load-bearing for both the behavioral results and the activation-patching localization.
- [§4.2] §4.2 (Rarely explicitly indicate reliance): The finding that models rarely state affix reliance explicitly is derived from the same fictitious-name probes; if stem confounds are present, the 'rarely explicitly indicate' and 'incorrectly conflate properties' conclusions cannot be cleanly attributed to affix shortcuts versus broader morphological or lexical leakage.
minor comments (2)
- [Abstract, §2] The abstract and §2 should include a brief statement of the statistical tests and validation procedure used to confirm that class-level responses exceed chance baselines.
- [Figure 4] Figure captions for activation-patching results should explicitly state the number of models, layers probed, and the precise patching metric (e.g., logit difference or probability shift).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. The concerns about potential confounds in the fictitious-name probes are well-taken and directly relevant to the load-bearing claims. We respond point-by-point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [§3] §3 (Framework for attributing semantics): The claim that responses to fictitious names isolate affix-driven semantics rests on the assumption that novel stems carry no residual distributional signals, n-gram overlaps, or affix-stem co-occurrence statistics from pretraining. Without reported controls (e.g., stem perplexity matching, n-gram frequency audits, or ablation on stem-only baselines), the class-level pharmacological outputs and the 'primarily through affix cues' finding for the 653-drug corpus could reflect confounds rather than pure affix heuristics. This is load-bearing for both the behavioral results and the activation-patching localization.
Authors: We agree that the isolation of affix effects would be strengthened by explicit controls for residual stem signals. While the fictitious stems were constructed as novel non-words and the attribution framework already compares affix vs. stem contributions (showing affix dominance), we did not report stem perplexity or n-gram audits in the original manuscript. In revision we will add these controls for a representative sample of the fictitious names and include a stem-only baseline ablation; results will be reported in an expanded §3 with a new limitations paragraph. revision: partial
-
Referee: [§4.2] §4.2 (Rarely explicitly indicate reliance): The finding that models rarely state affix reliance explicitly is derived from the same fictitious-name probes; if stem confounds are present, the 'rarely explicitly indicate' and 'incorrectly conflate properties' conclusions cannot be cleanly attributed to affix shortcuts versus broader morphological or lexical leakage.
Authors: We concur that the §4.2 conclusions inherit the same potential confounds. The planned addition of stem-perplexity and baseline controls in §3 will therefore be cross-referenced in §4.2, and we will qualify the 'rarely explicitly indicate' and conflation claims accordingly while preserving the core observation that explicit statements of affix reliance remain infrequent even under the controlled probes. revision: partial
Circularity Check
No circularity: empirical framework with no derivations or self-referential reductions
full rationale
The paper describes an empirical behavioral and mechanistic study of LLM affix heuristics using constructed fictitious drug names and a new attribution framework applied to 653 drugs, followed by activation patching. No equations, fitted parameters, predictions derived from inputs, or derivation chains are present in the provided text. The central claims rest on experimental results rather than any self-definitional, fitted-input, or self-citation load-bearing steps. The framework for distinguishing affix/stem/whole-name contributions is a methodological tool, not a reduction to its own outputs. This is a standard non-circular empirical analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Responses to fictitious drug names built from real affixes reflect affix-based heuristics rather than other factors
Reference graph
Works this paper leans on
-
[1]
Vibhor Agarwal, Yiqiao Jin, Mohit Chandra, Munmun De Choudhury, Srijan Kumar, and Nishanth Sastry. 2024. https://doi.org/10.48550/arXiv.2409.19492 Medhalu: Hallucinations in responses to healthcare queries by large language models . arXiv preprint arXiv:2409.19492
-
[5]
Nicola Dawson, Kathleen Rastle, and Jessie Ricketts. 2021. https://doi.org/10.1111/1467-9817.12338 Bridging form and meaning: support from derivational suffixes in word learning . Journal of Research in Reading, 44(1):27--50
-
[6]
Mengnan Du, Fengxiang He, Na Zou, Dacheng Tao, and Xia Hu. 2023. https://doi.org/10.1145/3596490 Shortcut learning of large language models in natural language understanding . Communications of the ACM, 67(1):110--120
-
[7]
Atticus Geiger, Zhengxuan Wu, Christopher Potts, Thomas Icard, and Noah Goodman. 2024. https://proceedings.mlr.press/v236/geiger24a.html Finding alignments between interpretable causal variables and distributed neural representations . In Causal Learning and Reasoning, pages 160--187. PMLR
2024
-
[8]
Robert Geirhos, J \"o rn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. 2020. https://doi.org/10.1038/s42256-020-00257-z Shortcut learning in deep neural networks . Nature Machine Intelligence, 2(11):665--673
-
[9]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
Pith/arXiv arXiv 2024
-
[11]
Kelli Henry, Brian Murray, Xingmeng Zhao, Kaitlin Blotske, Yanjun Gao, Brooke Smith, Khoa Le, Susan E Smith, Erin F Barreto, Seth Bauer, and 1 others. 2026. https://doi.org/10.64898/2026.01.12.26343930 Drug or pok \'e mon? large language model performance in identification of fabricated medications . medRxiv, pages 2026--01
-
[12]
Valentin Hofmann, Leonie Weissweiler, David R Mortensen, Hinrich Sch \"u tze, and Janet B Pierrehumbert. 2025. https://doi.org/10.1073/pnas.2423232122 Derivational morphology reveals analogical generalization in large language models . Proceedings of the National Academy of Sciences, 122(19):e2423232122
-
[13]
Yubin Kim, Hyewon Jeong, Shan Chen, Shuyue Stella Li, Chanwoo Park, Mingyu Lu, Kumail Alhamoud, Jimin Mun, Cristina Grau, Minseok Jung, Rodrigo Gameiro, Lizhou Fan, Eugene Park, Tristan Lin, Joonsik Yoon, Wonjin Yoon, Maarten Sap, Yulia Tsvetkov, Paul Liang, and 8 others. 2025. https://doi.org/10.48550/arXiv.2503.05777 Medical hallucinations in foundation...
-
[15]
Kaijie Mo, Siddhartha Venkatayogi, Chantal Shaib, Ramez Kouzy, Wei Xu, Byron C. Wallace, and Junyi Jessy Li. 2026. https://arxiv.org/abs/2601.11886 Faithfulness vs. safety: Evaluating llm behavior under counterfactual medical evidence . Preprint, arXiv:2601.11886
Pith/arXiv arXiv 2026
-
[16]
Mahmud Omar, Vera Sorin, Jeremy D Collins, David Reich, Robert Freeman, Nicholas Gavin, Alexander Charney, Lisa Stump, Nicola Luigi Bragazzi, Girish N Nadkarni, and 1 others. 2025. https://doi.org/10.1038/s43856-025-01021-3 Multi-model assurance analysis showing large language models are highly vulnerable to adversarial hallucination attacks during clinic...
-
[17]
Nikoleta Pantelidou, Evelina Leivada, Raquel Montero, and Paolo Morosi. 2026. https://doi.org/10.1371/journal.pone.0343164 Community size rather than grammatical complexity better predicts large language model accuracy in a novel wug test . PLOS ONE, 21(3):e0343164
-
[18]
Walter Quattrociocchi, Valerio Capraro, and Matjaž Perc. 2025. https://arxiv.org/abs/2512.19466 Epistemological fault lines between human and artificial intelligence . Preprint, arXiv:2512.19466
arXiv 2025
-
[19]
Marta Serafini, Sarah Cargnin, Alberto Massarotti, Gian Cesare Tron, Tracey Pirali, and Armando A Genazzani. 2021. https://pubs.acs.org/doi/10.1021/acs.jmedchem.1c00181 What’s in a name? drug nomenclature and medicinal chemistry trends using inn publications . Journal of Medicinal Chemistry, 64(8):4410--4429
-
[20]
Olga Solaja and Davide Crepaldi. 2024. https://doi.org/10.1098/rsos.230094 The role of morphology in novel word learning: a registered report . Royal Society Open Science, 11(6):230094
-
[21]
Jakke Tamminen, Matthew H Davis, and Kathleen Rastle. 2015. https://doi.org/10.1016/j.cogpsych.2015.03.003 From specific examples to general knowledge in language learning . Cognitive psychology, 79:1--39
-
[22]
Marion Weller-Di Marco and Alexander Fraser. 2024. https://aclanthology.org/2024.lrec-main.90/ Analyzing the understanding of morphologically complex words in large language models . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 1009--1020, Torino, Italia...
2024
-
[23]
World Health Organization . 2017. Guidance on the use of international nonproprietary names (inns) for pharmaceutical substances. https://www.who.int/publications/m/item/guidance-on-the-use-of-inns. Accessed: 2026-05-04
2017
-
[24]
Zhengxuan Wu, Aryaman Arora, Zheng Wang, Atticus Geiger, Dan Jurafsky, Christopher D Manning, and Christopher Potts. 2024. https://doi.org/10.52202/079017-2041 Reft: Representation finetuning for language models . Advances in Neural Information Processing Systems, 37:63908--63962
-
[25]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, and 23 others. 2025. https://arxiv.org/abs/2412.15115 Qwen2.5 technical report . Preprint, arXiv:2412.15115
Pith/arXiv arXiv 2025
-
[27]
Cognitive psychology , volume=
From specific examples to general knowledge in language learning , author=. Cognitive psychology , volume=. 2015 , publisher=
2015
-
[28]
Causal Learning and Reasoning , pages=
Finding alignments between interpretable causal variables and distributed neural representations , author=. Causal Learning and Reasoning , pages=. 2024 , organization=
2024
-
[29]
Proceedings of the National Academy of Sciences , volume=
Derivational morphology reveals analogical generalization in large language models , author=. Proceedings of the National Academy of Sciences , volume=. 2025 , publisher=
2025
-
[30]
and Koller, Alexander , title =
Bender, Emily M. and Koller, Alexander. Climbing towards NLU : On Meaning, Form, and Understanding in the Age of Data. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.463
-
[31]
Melanie Mitchell and David C. Krakauer , title =. Proceedings of the National Academy of Sciences , volume =. 2023 , doi =. https://www.pnas.org/doi/pdf/10.1073/pnas.2215907120 , abstract =
-
[32]
Journal of Medicinal Chemistry , volume=
What’s in a name? Drug nomenclature and medicinal chemistry trends using INN publications , author=. Journal of Medicinal Chemistry , volume=. 2021 , url=
2021
-
[33]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , url=
2020
-
[34]
Communications of the ACM , volume=
Shortcut learning of large language models in natural language understanding , author=. Communications of the ACM , volume=. 2023 , publisher=
2023
-
[35]
Do LLM s Overcome Shortcut Learning? An Evaluation of Shortcut Challenges in Large Language Models
Yuan, Yu and Zhao, Lili and Zhang, Kai and Zheng, Guangting and Liu, Qi. Do LLM s Overcome Shortcut Learning? An Evaluation of Shortcut Challenges in Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.679
-
[36]
2025 , eprint=
Epistemological Fault Lines Between Human and Artificial Intelligence , author=. 2025 , eprint=
2025
-
[37]
Analyzing the Understanding of Morphologically Complex Words in Large Language Models
Weller-Di Marco, Marion and Fraser, Alexander. Analyzing the Understanding of Morphologically Complex Words in Large Language Models. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[38]
Anh, Dang and Raviv, Limor and Galke, Lukas. Morphology Matters: Probing the Cross-linguistic Morphological Generalization Abilities of Large Language Models through a Wug Test. Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics. 2024. doi:10.18653/v1/2024.cmcl-1.15 , pages = "177--188", abstract = "We develop a multilingual v...
-
[39]
Advances in Neural Information Processing Systems , volume=
Reft: Representation finetuning for language models , author=. Advances in Neural Information Processing Systems , volume=. 2024 , doi=
2024
-
[40]
Guidance on the Use of International Nonproprietary Names (INNs) for Pharmaceutical Substances , year=
-
[41]
PLOS ONE , volume=
Community size rather than grammatical complexity better predicts Large Language Model accuracy in a novel Wug Test , author=. PLOS ONE , volume=. 2026 , doi=
2026
-
[42]
arXiv preprint arXiv:2503.05777 , year=
Medical Hallucinations in Foundation Models and Their Impact on Healthcare , author =. arXiv preprint arXiv:2503.05777 , year=. 2503.05777 , archivePrefix=
-
[43]
arXiv preprint arXiv:2409.19492 , year=
MedHalu: Hallucinations in Responses to Healthcare Queries by Large Language Models , author =. arXiv preprint arXiv:2409.19492 , year=. 2409.19492 , archivePrefix=
-
[44]
Drug or Pok
Henry, Kelli and Murray, Brian and Zhao, Xingmeng and Blotske, Kaitlin and Gao, Yanjun and Smith, Brooke and Le, Khoa and Smith, Susan E and Barreto, Erin F and Bauer, Seth and others , journal=. Drug or Pok. 2026 , publisher=
2026
-
[45]
2026 , journal=
Rethinking Medical LLM Hallucinations: A System-Level Survey , author =. 2026 , journal=
2026
-
[46]
and Rust, Paul and Pearcy, Pauline and Nasir, Khurram and Mossialos, Elias , title =
van Kessel, Robin and Anderson, Michael and McMillan, Brian and Matthews, Marc R. and Rust, Paul and Pearcy, Pauline and Nasir, Khurram and Mossialos, Elias , title =. BMJ Health Care Informatics , year =
-
[47]
and Pierrehumbert, Janet B
Needle, Jeremy M. and Pierrehumbert, Janet B. and Hay, Jennifer B. , title =. Morphological Diversity and Linguistic Cognition , chapter =. 2022 , month = may, doi =
2022
-
[48]
Safety: Evaluating LLM Behavior Under Counterfactual Medical Evidence , author =
Faithfulness vs. Safety: Evaluating LLM Behavior Under Counterfactual Medical Evidence , author =. 2026 , eprint=
2026
-
[49]
Communications Medicine , volume=
Multi-model assurance analysis showing large language models are highly vulnerable to adversarial hallucination attacks during clinical decision support , author=. Communications Medicine , volume=. 2025 , publisher=
2025
-
[50]
Royal Society Open Science , volume=
The role of morphology in novel word learning: a registered report , author=. Royal Society Open Science , volume=. 2024 , url=
2024
-
[51]
Journal of Research in Reading , volume=
Bridging form and meaning: support from derivational suffixes in word learning , author=. Journal of Research in Reading , volume=. 2021 , publisher=
2021
-
[52]
Groeneveld, Dirk and Beltagy, Iz and Walsh, Evan and Bhagia, Akshita and Kinney, Rodney and Tafjord, Oyvind and Jha, Ananya and Ivison, Hamish and Magnusson, Ian and Wang, Yizhong and Arora, Shane and Atkinson, David and Authur, Russell and Chandu, Khyathi and Cohan, Arman and Dumas, Jennifer and Elazar, Yanai and Gu, Yuling and Hessel, Jack and Khot, Tus...
-
[53]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[54]
Towards Medical Complex Reasoning with LLM s through Medical Verifiable Problems
Chen, Junying and Cai, Zhenyang and Ji, Ke and Wang, Xidong and Liu, Wanlong and Wang, Rongsheng and Wang, Benyou. Towards Medical Complex Reasoning with LLM s through Medical Verifiable Problems. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.751
-
[55]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.