AdaMEM: Test-Time Adaptive Memory for Language Agents
Pith reviewed 2026-06-28 01:34 UTC · model grok-4.3
The pith
Language agents adapt at test time by generating short-term strategy memory dynamically from stored trajectories, without any parameter updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
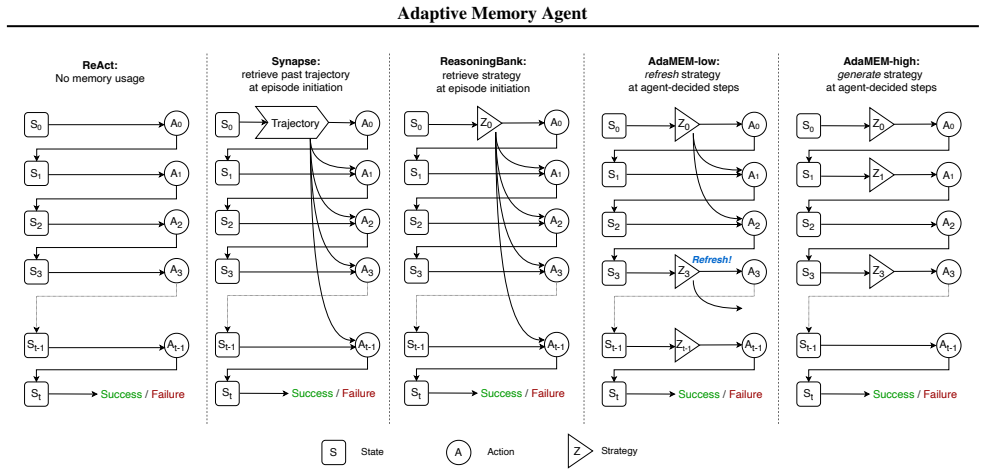
AdaMEM maintains a long-term trajectory memory of offline experiences and, at each step, synthesizes a short-term strategy memory from retrieved items to guide the current action, thereby achieving test-time adaptation solely through memory operations.
What carries the argument
Hybrid memory architecture that pairs static long-term trajectory memory with on-the-fly generated short-term strategy memory.
If this is right
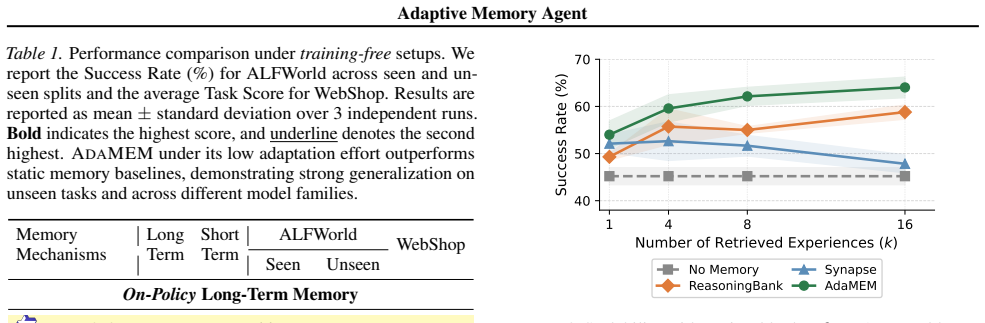
- Agents reach up to 13 percent relative improvement on ALFWorld and 11 percent on WebShop over static baselines.
- Performance leadership extends to agentic search on HotpotQA.
- STEP-MFT training of the policy to synthesize strategies yields additional gains.
- The method supports continuous reasoning and self-evolution after deployment with no online parameter changes.
Where Pith is reading between the lines
- The same memory-generation loop could be applied to other sequential decision domains where environment feedback arrives only after multiple steps.
- Token budgets could be allocated dynamically by deciding how many strategies to generate per step based on observed task complexity.
- The separation of long-term storage and short-term synthesis may reduce the frequency of full model retraining in production agent systems.
Load-bearing premise
Dynamically synthesized short-term strategies drawn from long-term experiences will stay aligned with task needs and improve decisions throughout an unfolding episode.
What would settle it
Running the same long-horizon tasks with AdaMEM versus a static memory baseline and finding no accuracy gain or a net loss on ALFWorld or WebShop.
Figures



read the original abstract
A central challenge for language agents is utilizing past experience to adapt to dynamic test-time conditions. While recent work demonstrates the promise of agentic memory mechanisms, most systems restrict retrieval to episode initiation. Consequently, agents are forced to rely on static guidance that becomes increasingly misaligned as long-horizon tasks unfold. To address this rigidity, we propose the Adaptive Memory Agent (AdaMEM), a novel framework for agent test-time adaptation. Without updating model parameters online, AdaMEM adapts agent behavior via a hybrid memory architecture: it maintains a long-term trajectory memory of raw experiences collected offline while generating dynamic short-term strategy memory on-the-fly to guide decision-making. This mechanism enables the trade-off between token efficiency and adaptability across varying inference-time compute levels. Empirically, AdaMEM significantly outperforms static memory baselines, achieving relative gains of up to 13% on ALFWorld and 11% on WebShop, with consistent leading performance extending to agentic search on HotpotQA. To further enhance this adaptation, we develop STEP-MFT, a Step-wise Memory Fine-Tuning technique that trains the policy to synthesize high-quality strategies from retrieved experiences, yielding additional performance gains. Our work establishes a new scaling dimension for agentic memory, supporting continuous reasoning and self-evolution post-deployment in real-world environments. Our code is available at https://github.com/yunx-z/AdaMEM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdaMEM, a hybrid memory framework for language agents that maintains offline long-term trajectory memory while generating short-term strategy memory on-the-fly at test time, without online parameter updates. It claims this enables better adaptation to dynamic conditions in long-horizon tasks, with reported relative gains of up to 13% on ALFWorld and 11% on WebShop over static memory baselines, consistent leading results on HotpotQA agentic search, and further gains from the introduced STEP-MFT fine-tuning method. The work positions this as a new scaling dimension for post-deployment agent self-evolution and releases code.
Significance. If the empirical gains can be cleanly attributed to the adaptive hybrid memory rather than uncontrolled differences in inference compute, the approach would represent a meaningful advance in test-time adaptation for agents, supporting continuous reasoning without retraining. The public code release aids reproducibility and allows direct verification of the claimed trade-off between token efficiency and adaptability.
major comments (2)
- [Experiments] Experiments section: The headline performance claims (up to 13% relative gain on ALFWorld, 11% on WebShop) compare AdaMEM against static memory baselines, but the setup does not equalize total LLM calls or tokens. AdaMEM's on-the-fly short-term strategy generation requires repeated LLM invocations per decision step, while static baselines use only initial retrieval; without this control, the delta cannot be attributed to the hybrid architecture versus extra test-time compute, undermining the central empirical claim.
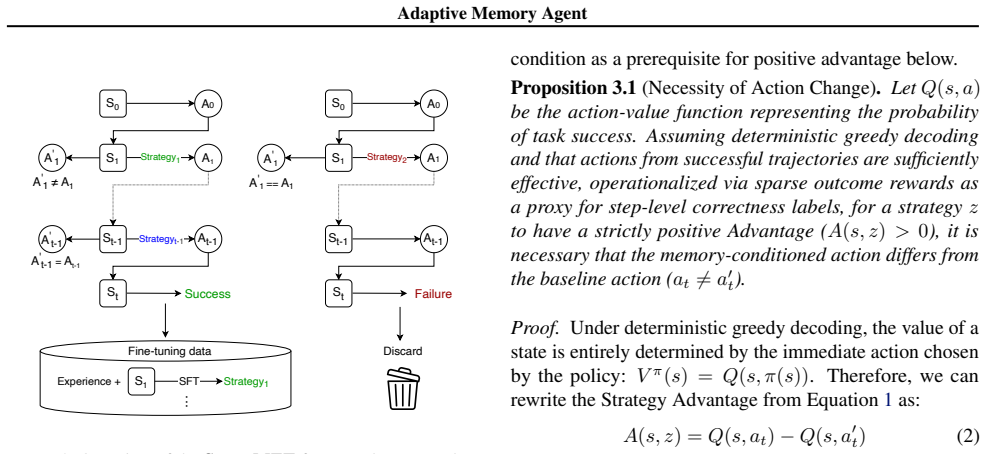
- [Method] Method and Abstract: The core assumption that on-the-fly short-term strategy memory generated from long-term trajectories will reliably improve decision-making lacks discussion of safeguards against misalignment or error propagation in long-horizon tasks; this is load-bearing for the adaptation claims but receives no analysis or ablation.
minor comments (2)
- [Abstract] Abstract: Performance numbers are stated without any mention of number of runs, variance, or specific baselines, making initial soundness assessment difficult even before full experimental details.
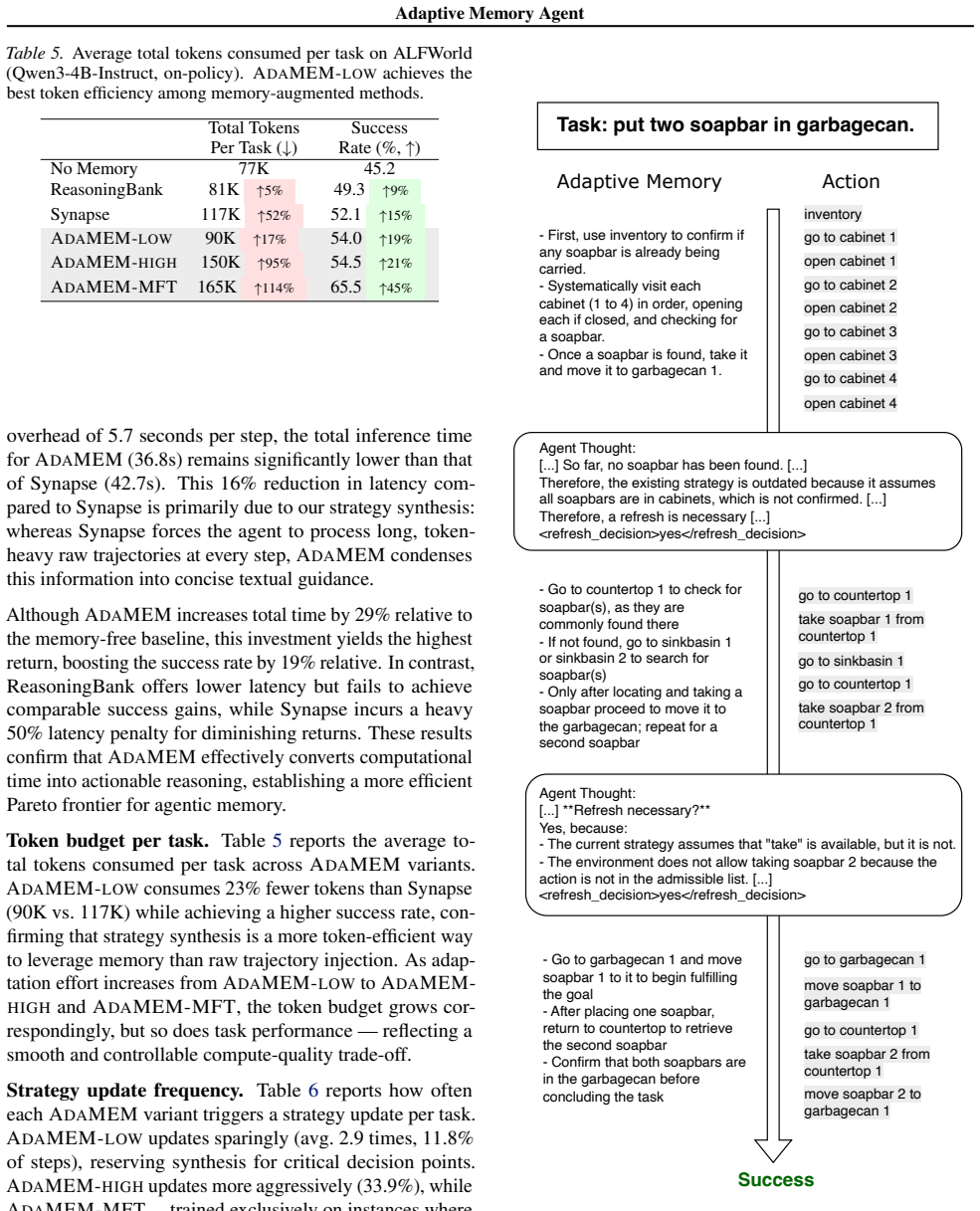
- [Abstract] The trade-off between token efficiency and adaptability is noted but not quantified with concrete token or latency measurements across the reported tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The headline performance claims (up to 13% relative gain on ALFWorld, 11% on WebShop) compare AdaMEM against static memory baselines, but the setup does not equalize total LLM calls or tokens. AdaMEM's on-the-fly short-term strategy generation requires repeated LLM invocations per decision step, while static baselines use only initial retrieval; without this control, the delta cannot be attributed to the hybrid architecture versus extra test-time compute, undermining the central empirical claim.
Authors: We agree that the current experiments do not explicitly control for total LLM calls or tokens, and that AdaMEM's repeated invocations for short-term strategy generation constitute additional test-time compute. This is an inherent feature of the proposed adaptation mechanism rather than an uncontrolled variable. To address the concern directly, we will revise the experiments section to report average token usage and LLM call counts across methods, add compute-matched ablations (e.g., limiting strategy generation frequency or comparing against static baselines augmented with equivalent extra retrieval steps), and qualify the performance claims accordingly while preserving the core comparison to standard static baselines. revision: yes
-
Referee: [Method] Method and Abstract: The core assumption that on-the-fly short-term strategy memory generated from long-term trajectories will reliably improve decision-making lacks discussion of safeguards against misalignment or error propagation in long-horizon tasks; this is load-bearing for the adaptation claims but receives no analysis or ablation.
Authors: The referee is correct that the manuscript provides no explicit analysis or ablation of misalignment or error propagation risks in the generated short-term strategies. We will add a new subsection discussing these issues, including potential safeguards such as cross-verification of generated strategies against the long-term memory or confidence thresholding, and include a targeted ablation examining performance degradation under simulated noisy or misaligned memory retrieval. revision: yes
Circularity Check
No circularity; purely empirical claims
full rationale
The paper advances an empirical agent framework (AdaMEM with hybrid long-term/short-term memory and optional STEP-MFT) whose central claims are relative performance gains on ALFWorld, WebShop, and HotpotQA versus static baselines. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. All reported results rest on external benchmark comparisons rather than any self-referential construction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language agents can synthesize effective short-term strategies from retrieved long-term experiences at inference time.
Reference graph
Works this paper leans on
-
[1]
URL https://openreview.net/forum? id=nZeVKeeFYf9. Hu, Y ., Liu, S., Yue, Y ., Zhang, G., Liu, B., Zhu, F., Lin, J., Guo, H., Dou, S., Xi, Z., Jin, S., Tan, J., Yin, Y ., Liu, J., Zhang, Z., Sun, Z., Zhu, Y ., Sun, H., Peng, B., Cheng, Z., Fan, X., Guo, J., Yu, X., Zhou, Z., Hu, Z., Huo, J., Wang, J., Niu, Y ., Wang, Y ., Yin, Z., Hu, X., Liao, Y ., Li, Q....
Pith/arXiv arXiv 2026
-
[2]
On the Reliability of Large Language Models for Causal Discovery
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long
-
[3]
acl-long.1464/
URL https://aclanthology.org/2025. acl-long.1464/. Jansen, P., C ˆot´e, M.-A., Khot, T., Bransom, E., Mishra, B. D., Majumder, B. P., Tafjord, O., and Clark, P. Discoveryworld: A virtual environment for developing and evaluating automated scientific discovery agents. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Bench...
2025
-
[4]
URL https://openreview.net/forum? id=cDYqckEt6d. Jia, Z., Li, J., Kang, Y ., Wang, Y ., Wu, T., Wang, Q., Wang, X., Zhang, S., Shen, J., Li, Q., Qi, S., Liang, Y ., He, D., Zheng, Z., and Zhu, S.-C. The ai hippocampus: How far are we from human memory?, 2026. URL https: //arxiv.org/abs/2601.09113. 10 Adaptive Memory Agent Jiang, Y ., Jiang, L., Teney, D.,...
arXiv 2026
-
[7]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y
URL https://openreview.net/forum? id=oVKEAFjEqv. Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y . K., Wu, Y ., and Guo, D. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models, 2024. URL https://arxiv.org/abs/2402.03300. Shridhar, M., Yuan, X., Cˆot´e, M., Bisk, Y ., Trischler, A., and Ha...
Pith/arXiv arXiv 2024
-
[9]
Wang, P., Li, L., Shao, Z., Xu, R
URL https://openreview.net/forum? id=ehfRiF0R3a. Wang, P., Li, L., Shao, Z., Xu, R. X., Dai, D., Li, Y ., Chen, D., Wu, Y ., and Sui, Z. Math-shepherd: Ver- ify and reinforce llms step-by-step without human an- notations, 2024b. URL https://arxiv.org/abs/ 2312.08935. Wang, Z. Z., Mao, J., Fried, D., and Neubig, G. Agent workflow memory. InForty-second Int...
Pith/arXiv arXiv 2025
-
[11]
Ye, S., Yu, C., Ke, K., Xu, C., and Wei, Y
URL https://openreview.net/forum? id=WE_vluYUL-X. Ye, S., Yu, C., Ke, K., Xu, C., and Wei, Y . H2r: Hierarchical hindsight reflection for multi-task llm agents, 2025. URL https://arxiv.org/abs/2509.12810. Yu, Y ., Yao, L., Xie, Y ., Tan, Q., Feng, J., Li, Y ., and Wu, L. Agentic memory: Learning unified long-term and short-term memory management for large...
arXiv 2025
-
[12]
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models
doi: 10.48550/ARXIV .2308.01825. URL https: //doi.org/10.48550/arXiv.2308.01825. Zhang, S., Wang, J., Zhou, R., Liao, J., Feng, Y ., Zhang, W., Wen, Y ., Li, Z., Xiong, F., Qi, Y ., Tang, B., and Wen, M. Memrl: Self-evolving agents via runtime reinforcement learning on episodic memory, 2026a. URL https:// arxiv.org/abs/2601.03192. Zhang, Y ., Khalifa, M.,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2026
-
[13]
Generate a **proposed action** based on the *current* strategy
-
[14]
success” or “failure
Decide if a refresh is strictly necessary based on the criteria above. **Output format:** <think>...reasoning...</think> <action>...your proposed action...</action> <refresh decision>yes or no</refresh decision> Prompt for the ADAMEM Agent: Strategy Mem- ory Synthesis You need to synthesize contextualized, non-generic strategies from retrieved past experi...
-
[15]
go to cabinet 1 open cabinet 1
Systematically explorecabinets and drawers inorder (starting from cabinet1) to locate the butterknife,opening closed containersas needed. go to cabinet 1 open cabinet 1 ... go to cabinet 13 open cabinet 13 Agent Thought: [...] I have already completed the systematic exploration ofcabinets 1-17 and drawers 1-7. The next logical step would be tocontinue exp...
-
[16]
Once found, pick up thebutterknife and clean it usingthe sinkbasin
-
[17]
put a clean butterknife in countertop
After cleaning, move thebutterknife to a countertop(e.g., countertop 1, 2, 3, or 4)to fulfill the goal. Figure 8.Failure case study on ALFWorld. The agent attempts the task “put a clean butterknife in countertop”. After an exhaustive but unsuccessful search of all cabinets and drawers, the agent suf- fers fromstrategy inertia: it incorrectly assesses that ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.