AdaPLD: Adaptive Retrieval and Reuse for Efficient Model-Free Speculative Decoding
Pith reviewed 2026-06-28 02:10 UTC · model grok-4.3
The pith
AdaPLD recovers extra reuse in speculative decoding by supplementing lexical matches with semantic similarity and replacing single spans with branched hypotheses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AdaPLD is a training-free method that preserves high-precision lexical reuse while using semantic similarity to recover additional reuse opportunities when lexical matching fails; it further constructs branched reuse hypotheses to account for continuation uncertainty rather than relying on a single copied span. Across diverse benchmarks this reduces target-model forward passes and achieves up to 3.10× decoding speedup.
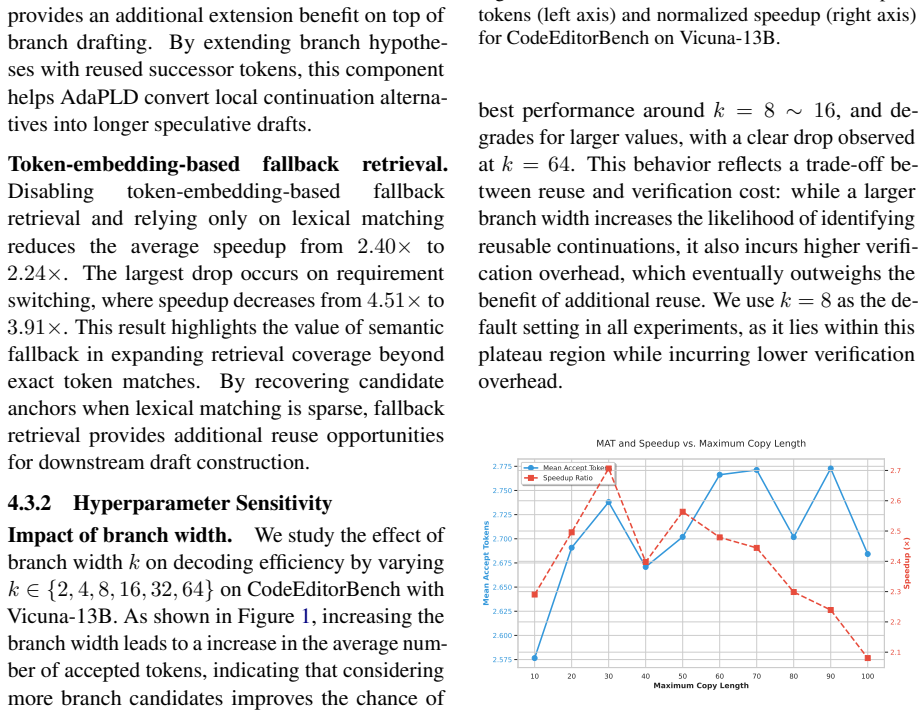
What carries the argument
Adaptive retrieval that switches between lexical and semantic similarity plus construction of branched reuse hypotheses for draft candidates.
If this is right
- Fewer sequential target-model forward passes are required for the same output length.
- Decoding runs up to 3.10 times faster on the tested benchmarks.
- The method remains training-free and works with any existing target model.
- High-precision lexical reuse is retained while recall improves through semantic fallback.
Where Pith is reading between the lines
- The branched-hypothesis idea could be applied to other reuse-based generation settings where context leaves multiple plausible continuations.
- Combining AdaPLD-style retrieval with existing lexical-only methods might produce a simple hybrid that improves both recall and precision without new training.
- If semantic similarity is computed cheaply enough, the approach might extend to very long contexts where pure lexical matching becomes too sparse.
Load-bearing premise
Semantic similarity scores will surface reuse candidates that survive verification and the cost of maintaining and verifying branched hypotheses will stay smaller than the savings from fewer target passes.
What would settle it
A controlled test in which semantic matches rarely pass verification or in which the overhead of branching exceeds the reduction in target passes would falsify the claimed net speedup.
Figures




read the original abstract
Speculative decoding accelerates generation by verifying multiple drafted tokens in a single target-model forward pass, reducing sequential decoding iterations. Model-free variants avoid auxiliary draft models by reusing text and model states already available during generation, but their speedup depends on the reliability of the constructed drafts. We identify two limitations of existing reuse-based methods: lexically anchored retrieval has limited recall under surface-form variation, and deterministic span copying can be brittle when the retrieved context does not uniquely determine the continuation. We propose \emph{AdaPLD}, a training-free method that adaptively improves both retrieval and draft construction. AdaPLD preserves high-precision lexical reuse while using semantic similarity to recover additional reuse opportunities when lexical matching fails. It further constructs branched reuse hypotheses to account for continuation uncertainty, rather than relying on a single copied span. Across diverse benchmarks, AdaPLD reduces target-model forward passes and achieves up to $3.10\times$ decoding speedup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdaPLD, a training-free method for model-free speculative decoding. It preserves lexical reuse while adding semantic similarity retrieval to recover additional candidates when lexical matching fails, and constructs branched reuse hypotheses instead of single deterministic spans to handle continuation uncertainty. The central empirical claim is that this reduces target-model forward passes and yields up to 3.10× decoding speedup across diverse benchmarks.
Significance. If the results hold after proper accounting for retrieval and verification overhead, the work could usefully extend reuse-based speculative decoding by improving recall without auxiliary draft models. The training-free design and explicit handling of surface-form variation and continuation uncertainty are conceptually attractive strengths.
major comments (2)
- [Abstract] Abstract: the claim that AdaPLD 'reduces target-model forward passes' and achieves up to 3.10× speedup is load-bearing, yet the abstract (and the provided description) supplies no acceptance-rate statistics for semantic candidates, no breakdown of extra retrieval or branching compute, and no comparison showing net forward-pass reduction after overhead. This directly affects whether the weakest assumption holds.
- [Method] Method (branched hypotheses): the description states that branched reuse hypotheses are constructed 'to account for continuation uncertainty,' but provides no detail on how many branches are maintained, how they are verified or pruned, or the resulting acceptance/rejection rates. Without these quantities it is impossible to verify that branching overhead remains smaller than the claimed savings in target passes.
minor comments (1)
- [Abstract] The abstract refers to 'diverse benchmarks' without naming them or reporting per-benchmark speedups or variance; adding this information would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the presentation of results and method details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that AdaPLD 'reduces target-model forward passes' and achieves up to 3.10× speedup is load-bearing, yet the abstract (and the provided description) supplies no acceptance-rate statistics for semantic candidates, no breakdown of extra retrieval or branching compute, and no comparison showing net forward-pass reduction after overhead. This directly affects whether the weakest assumption holds.
Authors: We agree that the abstract would benefit from explicit support for the central empirical claim. We will revise the abstract to include summary statistics on semantic candidate acceptance rates and a concise statement on net target forward-pass reduction after retrieval and branching overhead, drawing from the experimental results already reported in the manuscript. revision: yes
-
Referee: [Method] Method (branched hypotheses): the description states that branched reuse hypotheses are constructed 'to account for continuation uncertainty,' but provides no detail on how many branches are maintained, how they are verified or pruned, or the resulting acceptance/rejection rates. Without these quantities it is impossible to verify that branching overhead remains smaller than the claimed savings in target passes.
Authors: We agree that the branched-hypotheses description requires additional specificity. We will expand the method section to state the number of branches maintained, describe the parallel verification and pruning procedure, and report acceptance/rejection rates from the experiments to demonstrate that branching overhead is offset by the observed reduction in target-model passes. revision: yes
Circularity Check
No circularity: method is algorithmic proposal with empirical claims, no derivation chain present
full rationale
The paper presents AdaPLD as a training-free algorithmic method for speculative decoding that combines lexical retrieval, semantic similarity, and branched hypotheses. The abstract and provided text contain no equations, no fitted parameters, no predictions derived from first principles, and no self-citations used to justify core premises. Claims of speedup are empirical performance statements rather than mathematical derivations that could reduce to inputs by construction. No load-bearing steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[2]
Lee and Deming Chen and Tri Dao , booktitle=
Tianle Cai and Yuhong Li and Zhengyang Geng and Hongwu Peng and Jason D. Lee and Deming Chen and Tri Dao , booktitle=. Medusa: Simple. 2024 , url=
2024
-
[3]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =
Zhao, Yao and Xie, Zhitian and Liang, Chen and Zhuang, Chenyi and Gu, Jinjie , title =. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =. 2024 , isbn =. doi:10.1145/3637528.3671614 , abstract =
-
[4]
RASD : Retrieval-Augmented Speculative Decoding
Quan, Guofeng and Feng, Wenfeng and Hao, Chuzhan and Jiang, Guochao and Zhang, Yuewei and Wang, Hao Henry. RASD : Retrieval-Augmented Speculative Decoding. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.320
-
[5]
Accelerated Test-Time Scaling with Model-Free Speculative Sampling
Song, Woomin and Dingliwal, Saket and Jayanthi, Sai Muralidhar and Ganesh, Bhavana and Shin, Jinwoo and Galstyan, Aram and Bodapati, Sravan Babu. Accelerated Test-Time Scaling with Model-Free Speculative Sampling. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1558
-
[6]
REST : Retrieval-Based Speculative Decoding
He, Zhenyu and Zhong, Zexuan and Cai, Tianle and Lee, Jason and He, Di. REST : Retrieval-Based Speculative Decoding. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.88
-
[7]
DR e SD : Dense Retrieval for Speculative Decoding
Gritta, Milan and Xue, Huiyin and Lampouras, Gerasimos. DR e SD : Dense Retrieval for Speculative Decoding. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1017
-
[8]
2023 , eprint=
Accelerating Large Language Model Decoding with Speculative Sampling , author=. 2023 , eprint=
2023
-
[9]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Leviathan, Yaniv and Kalman, Matan and Matias, Yossi , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[10]
2026 , eprint=
LogitSpec: Accelerating Retrieval-based Speculative Decoding via Next Next Token Speculation , author=. 2026 , eprint=
2026
-
[11]
SAM Decoding: Speculative Decoding via Suffix Automaton
Hu, Yuxuan and Wang, Ke and Zhang, Xiaokang and Zhang, Fanjin and Li, Cuiping and Chen, Hong and Zhang, Jing. SAM Decoding: Speculative Decoding via Suffix Automaton. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.595
-
[12]
Turning Trash into Treasure: Accelerating Inference of Large Language Models with Token Recycling
Luo, Xianzhen and Wang, Yixuan and Zhu, Qingfu and Zhang, Zhiming and Zhang, Xuanyu and Yang, Qing and Xu, Dongliang. Turning Trash into Treasure: Accelerating Inference of Large Language Models with Token Recycling. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025....
-
[13]
2023 , month =
Prompt Lookup Decoding , author =. 2023 , month =
2023
-
[14]
2024 , url=
Yubo Wang and Xueguang Ma and Ge Zhang and Yuansheng Ni and Abhranil Chandra and Shiguang Guo and Weiming Ren and Aaran Arulraj and Xuan He and Ziyan Jiang and Tianle Li and Max Ku and Kai Wang and Alex Zhuang and Rongqi Fan and Xiang Yue and Wenhu Chen , booktitle=. 2024 , url=
2024
-
[15]
The Twelfth International Conference on Learning Representations , year=
Let's Verify Step by Step , author=. The Twelfth International Conference on Learning Representations , year=
-
[16]
InFindings of the Conference on Empirical Methods in Natural Language Processing (EMNLP)
Karpukhin, Vladimir and Oguz, Barlas and Min, Sewon and Lewis, Patrick and Wu, Ledell and Edunov, Sergey and Chen, Danqi and Yih, Wen-tau. Dense Passage Retrieval for Open-Domain Question Answering. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.550
-
[17]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav , title...
-
[18]
Gonzalez and Ion Stoica , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging. 2023 , url=
2023
-
[19]
Nallapati, Ramesh and Zhou, Bowen and dos Santos, Cicero and Gu l c ehre, C a g lar and Xiang, Bing. Abstractive Text Summarization using Sequence-to-sequence RNN s and Beyond. Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning. 2016. doi:10.18653/v1/K16-1028
-
[20]
Xia, Heming and Yang, Zhe and Dong, Qingxiu and Wang, Peiyi and Li, Yongqi and Ge, Tao and Liu, Tianyu and Li, Wenjie and Sui, Zhifang. Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.456
-
[21]
2025 , eprint=
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models , author=. 2025 , eprint=
2025
-
[22]
Aly, Beidi Chen, and Carole-Jean Wu
Elhoushi, Mostafa and Shrivastava, Akshat and Liskovich, Diana and Hosmer, Basil and Wasti, Bram and Lai, Liangzhen and Mahmoud, Anas and Acun, Bilge and Agarwal, Saurabh and Roman, Ahmed and Aly, Ahmed and Chen, Beidi and Wu, Carole-Jean. L ayer S kip: Enabling Early Exit Inference and Self-Speculative Decoding. Proceedings of the 62nd Annual Meeting of ...
-
[23]
2025 , url=
Heming Xia and Yongqi Li and Jun Zhang and Cunxiao Du and Wenjie Li , booktitle=. 2025 , url=
2025
-
[24]
Draft&verify: Lossless large language model acceleration via self- speculative decoding,
Zhang, Jun and Wang, Jue and Li, Huan and Shou, Lidan and Chen, Ke and Chen, Gang and Mehrotra, Sharad. Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.607
-
[25]
2023 , eprint=
Fast Inference from Transformers via Speculative Decoding , author=. 2023 , eprint=
2023
-
[26]
Break the Sequential Dependency of
Yichao Fu and Peter Bailis and Ion Stoica and Hao Zhang , booktitle=. Break the Sequential Dependency of. 2024 , url=
2024
-
[27]
Cacheback: Speculative Decoding With Nothing But Cache
Ma, Zhiyao and Gim, In and Zhong, Lin. Cacheback: Speculative Decoding With Nothing But Cache. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1581
-
[28]
PLD +: Accelerating LLM Inference by Leveraging Language Model Artifacts
Somasundaram, Shwetha and Phukan, Anirudh and Saxena, Apoorv. PLD +: Accelerating LLM Inference by Leveraging Language Model Artifacts. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.338
-
[29]
SuffixDecoding: Extreme Speculative Decoding for Emerging
Gabriele Oliaro and Zhihao Jia and Daniel F Campos and Aurick Qiao , booktitle=. SuffixDecoding: Extreme Speculative Decoding for Emerging. 2025 , url=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.