PlanBench-V: A Spatial Planning Map Benchmark for Vision-Language Models
Pith reviewed 2026-06-28 02:07 UTC · model grok-4.3
The pith
VLMs show 27% improvement on spatial planning map tasks but still fail at implementation requiring policy judgment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
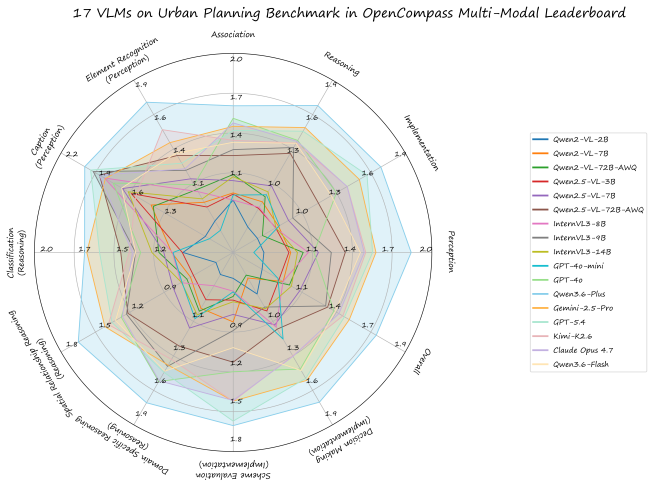
PlanBench-V is introduced as the first comprehensive benchmark for VLMs on spatial planning map interpretation, featuring the Spatial Planning Map Database with expert annotations and a four-stage evaluation framework of Perception, Reasoning, Association, and Implementation. Experiments demonstrate clear progress between model generations but persistent limitations, particularly in implementation tasks that require policy sensitivity and constraint-aware decision-making.
What carries the argument
The theory-informed evaluation framework that breaks down planning map interpretation into four progressive capabilities: Perception, Reasoning, Association, and Implementation.
If this is right
- Current VLMs have made measurable gains in handling spatial planning maps over one year.
- All tested models continue to underperform on tasks needing professional judgment and policy knowledge.
- Domain-specific benchmarks like this expose gaps not visible in general visual understanding tests.
- Future development of VLMs for professional use will require targeted improvements in evaluative and constraint-handling abilities.
Where Pith is reading between the lines
- Applying this benchmark to train models could lead to better AI tools for planners.
- Similar benchmarks might be developed for other specialized visual domains like architecture or environmental science.
- Human performance baselines on the same questions would help calibrate how close models are to expert level.
Load-bearing premise
That the division into four capabilities accurately reflects the real cognitive process of interpreting planning maps and that the expert annotations represent correct answers for model evaluation.
What would settle it
If professional planners achieve significantly lower accuracy than the top models on the implementation questions, or if models match expert performance across all four capability levels.
Figures


read the original abstract
Spatial planning maps are central to territorial governance, translating planning objectives, regulations, and spatial strategies into visual forms for decision-making, public communication, and institutional coordination. Their interpretation, however, requires fine-grained visual perception, spatial reasoning, and policy-informed professional judgment, creating major challenges for both human learners and AI systems. With the rapid progress of Vision-Language Models (VLMs), their use in urban planning analysis is gaining attention, yet existing multimodal benchmarks mainly target general visual understanding and overlook the domain-specific cognitive processes of planning practice. To address this gap, we introduce PlanBench-V, the first comprehensive benchmark for evaluating VLMs in spatial planning map interpretation. We first build the Spatial Planning Map Database (SPMD), an expert-annotated dataset of 223 planning maps and 1629 question-answer pairs curated by professional planners, covering diverse geographic regions and cartographic styles. We then propose a theory-informed evaluation framework assessing four progressive capabilities: Perception, Reasoning, Association, and Implementation, corresponding to the cognitive pipeline of planning map interpretation. Extensive experiments across two generations of VLMs show clear progress but persistent limitations. The best 2026 agentic reasoning model, Qwen3.6-Plus, substantially outperforms the best 2025 model, GPT-4o, by 27%. Nevertheless, all models still struggle with implementation-oriented tasks requiring evaluative judgment, policy sensitivity, and constraint-aware decision-making. These findings reveal fundamental limitations of current VLMs in professional planning contexts and highlight the need for domain-adaptive multimodal reasoning frameworks. Code and data are available at https://plangpt.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PlanBench-V, the first benchmark for VLMs on spatial planning map interpretation. It constructs the SPMD dataset (223 maps, 1629 expert-annotated QA pairs by professional planners across regions and styles), proposes a four-capability framework (Perception, Reasoning, Association, Implementation) aligned to the cognitive pipeline of map interpretation, and reports experiments on two generations of VLMs showing a 27% gain for Qwen3.6-Plus over GPT-4o with persistent failures on implementation tasks requiring evaluative judgment and policy sensitivity.
Significance. If the ground-truth annotations and capability partitioning hold, the benchmark fills a clear gap in domain-specific multimodal evaluation for professional planning contexts that existing general VLM benchmarks overlook. The public release of data and code is a concrete strength that would enable follow-on work on domain-adaptive reasoning.
major comments (2)
- [Dataset Construction] The curation process for the 1629 QA pairs (described in the abstract and Dataset section) reports expert annotation by professional planners but provides no inter-annotator agreement statistics, disagreement resolution protocol, or post-hoc validation of the four-category assignments. This directly undermines the reliability of the headline 27% performance gap and the subset-specific claims about implementation-task failures.
- [Evaluation Framework] The Evaluation Framework section asserts that the four progressive capabilities correspond to the cognitive pipeline of planning map interpretation, yet reports no validation metrics, expert review of category assignments, or sensitivity analysis showing that mislabeling would not alter the reported model rankings or limitation conclusions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of dataset reliability and framework validation that we will address in the revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Dataset Construction] The curation process for the 1629 QA pairs (described in the abstract and Dataset section) reports expert annotation by professional planners but provides no inter-annotator agreement statistics, disagreement resolution protocol, or post-hoc validation of the four-category assignments. This directly undermines the reliability of the headline 27% performance gap and the subset-specific claims about implementation-task failures.
Authors: We agree that the manuscript lacks quantitative inter-annotator agreement statistics, a detailed disagreement resolution protocol, and explicit post-hoc validation of the four-category assignments. The annotations were performed by professional planners following internal guidelines, but these elements were not reported. In the revised manuscript we will expand the Dataset section with: (i) the annotation guidelines and disagreement resolution process (consensus discussion among annotators), (ii) IAA statistics on the subset of questions annotated by multiple planners, and (iii) confirmation of category assignments via expert review. These additions will directly bolster the reliability of the reported 27% gap and the implementation-task analysis. revision: yes
-
Referee: [Evaluation Framework] The Evaluation Framework section asserts that the four progressive capabilities correspond to the cognitive pipeline of planning map interpretation, yet reports no validation metrics, expert review of category assignments, or sensitivity analysis showing that mislabeling would not alter the reported model rankings or limitation conclusions.
Authors: The referee is correct that the current manuscript does not include validation metrics, documented expert review of the category assignments, or sensitivity analysis for potential mislabeling. The four-capability framework was developed from cognitive models in the planning literature, but these supporting details were omitted. In the revised Evaluation Framework section we will add: (i) a description of the expert review process used to confirm category assignments, (ii) alignment/validation metrics between the assigned categories and expert judgments on a held-out sample, and (iii) a sensitivity analysis showing that moderate rates of mislabeling do not change model rankings or the core conclusion regarding persistent implementation-task failures. These changes will strengthen the framework without altering the experimental findings. revision: yes
Circularity Check
New benchmark dataset with expert annotations; no derivation reduces to inputs by construction
full rationale
The paper introduces SPMD (223 maps, 1629 QA pairs) and a four-capability framework as a new contribution. No equations, fitted parameters, self-citations, or renamings appear in the provided text. The evaluation framework is presented as theory-informed but does not define capabilities in terms of model outputs or reduce any result to prior fitted values. This is a standard independent benchmark paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The cognitive pipeline of planning map interpretation decomposes into Perception, Reasoning, Association, and Implementation stages.
- domain assumption Expert-annotated QA pairs curated by professional planners provide valid ground truth for VLM evaluation.
Reference graph
Works this paper leans on
-
[1]
VQA: Visual Question Answering. October. ArXiv:1505.00468 [cs], Available from: http://arxiv.org/abs/1505.00468. Albrechts, L., Healey, P., and Kunzmann, K.R.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Alexander, C., 1977.A pattern language: Towns, buildings, construction
Strategic spatial planning and regional governance in europe.Journal of the American Planning Association, 69 (2), 113–129. Alexander, C., 1977.A pattern language: Towns, buildings, construction. Oxford University Press. Arnheim, R., 1969.Visual thinking. University of California Press. Bai, J.,et al.,
1977
-
[3]
Bertin, J., 1983.Semiology of graphics: Diagrams, networks, maps
Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. Bertin, J., 1983.Semiology of graphics: Diagrams, networks, maps. University of Wisconsin Press. Burgess, R. and Carmona, M.I.,
1983
-
[4]
Available from: https://arxiv.org/abs/2211.08545
Mapqa: A dataset for question answering on choropleth maps. Available from: https://arxiv.org/abs/2211.08545. Chen, S.,et al.,
-
[5]
Bring reason to vision: Understanding perception and reasoning through model merging.arXiv preprint arXiv:2505.05464. Chen, Z.,et al.,
-
[6]
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks.arXiv preprint arXiv:2312.14238. DeepMind, G.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
DesignQA: A Multimodal Benchmark for Evaluating Large Language Models’ Understanding of Engineering Documentation. August. D¨ uhr, S., 2007.The visual language of spatial planning: Exploring cartographic repre- sentations for spatial planning in europe. 1st ed. London: Routledge. Available from: https://doi.org/10.4324/9780203965818. D¨ uhr, S.,
-
[8]
Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062. Harley, J.B.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Harley, J.B., 2002.The new nature of maps: Essays in the history of cartography
Deconstructing the map.Cartographica: The International Journal for Geographic Information and Geovisualization, 26 (2), 1–20. Harley, J.B., 2002.The new nature of maps: Essays in the history of cartography. Baltimore: Johns Hopkins University Press. Healey, P., 1997.Collaborative planning: Shaping places in fragmented societies. UBC Press. Huang, Y.,et al.,
2002
-
[10]
Aesbench: An expert benchmark for multimodal large language models on image aesthetics perception.arXiv preprint arXiv:2401.08276. Hurst, A.,et al.,
-
[11]
Gpt-4o system card.arXiv preprint arXiv:2410.21276. Koffka, K., 1935.Principles of gestalt psychology. Harcourt, Brace and Company. Kress, G. and van Leeuwen, T., 2006.Reading images: The grammar of visual design. 2nd ed. Routledge. Krishna, R.,et al.,
work page internal anchor Pith review Pith/arXiv arXiv 1935
-
[12]
Available from: https://doi.org/10.1007/s11263-016-0981-7. Lai, Y.,et al.,
-
[13]
Med-r1: Reinforcement learning for generalizable medical reasoning in vision-language models,
Med-r1: Reinforcement learning for generalizable medical reasoning in vision-language models.arXiv preprint arXiv:2503.13939. Li, C.,et al.,
-
[14]
Scigraphqa: A large-scale synthetic multi-turn question- answering dataset for scientific graphs. Available from: https://arxiv.org/abs/2308.03349. Li, Z.,et al.,
-
[15]
Designprobe: A graphic design benchmark for multimodal large language models.arXiv preprint arXiv:2404.14801. Lin, T.Y.,et al.,
-
[16]
Microsoft COCO: Common Objects in Context
Microsoft COCO: Common Objects in Context. February. ArXiv:1405.0312 [cs], Available from: http://arxiv.org/abs/1405.0312. Liu, H.,et al.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Visual instruction tuning. Available from: https://arxiv.org/abs/2304.08485. Lynch, K., 1984.Good city form. MIT press. Mathew, M.,et al.,
work page internal anchor Pith review Pith/arXiv arXiv 1984
-
[18]
Mayer, R.E., 2005.The cambridge handbook of multimedia learning
Available from: https://arxiv.org/abs/2008.08899. Mayer, R.E., 2005.The cambridge handbook of multimedia learning. Cambridge University Press. Moroni, S. and Lorini, G.,
-
[19]
MIT Press
Palmer, S.E., 1999.Vision science: Photons to phenomenology. MIT Press. Pan, J.,et al.,
1999
-
[20]
Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning.arXiv preprint arXiv:2502.19634. Qian, T.,et al.,
-
[21]
Available from: https://arxiv.org/abs/2405.08807
Scifibench: Benchmarking large multimodal models for scientific figure interpretation. Available from: https://arxiv.org/abs/2405.08807. Roberts, J.,et al.,
-
[22]
Charting New Territories: Exploring the geographic and geospatial capabilities of multimodal LLMs.arXiv preprint arXiv:2311.14656. Shen, H.,et al.,
-
[23]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Vlm-r1: A stable and generalizable r1-style large vision-language model. arXiv preprint arXiv:2504.07615. Sima, C.,et al.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
A framework for theory and practice in landscape planning.Process archi- tecture, 127, 12–31. Wang, P.,et al., 2024a. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. Available from: https://arxiv.org/abs/2409.12191. Wang, W.,et al., 2024b. Needle In A Multimodal Haystack. October. ArXiv:2406.07230 [cs], Available fro...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Zhu, H., Chen, G., and Zhang, W., 2025a
Uniaa: A unified multi-modal image aesthetic assessment baseline and benchmark.arXiv preprint arXiv:2404.09619. Zhu, H., Chen, G., and Zhang, W., 2025a. PlanGPT: Enhancing urban planning with a tailored agent framework.In: G. Rehm and Y. Li, eds.Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Tra...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.