PiL-World: A Chunk-Wise World Model for VLA Policy-in-the-Loop Evaluation
Pith reviewed 2026-06-28 01:28 UTC · model grok-4.3
The pith
PiL-World generates chunk-wise multi-view observations so VLA policies can run closed-loop evaluations that match real-robot success rates within 12 percent error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
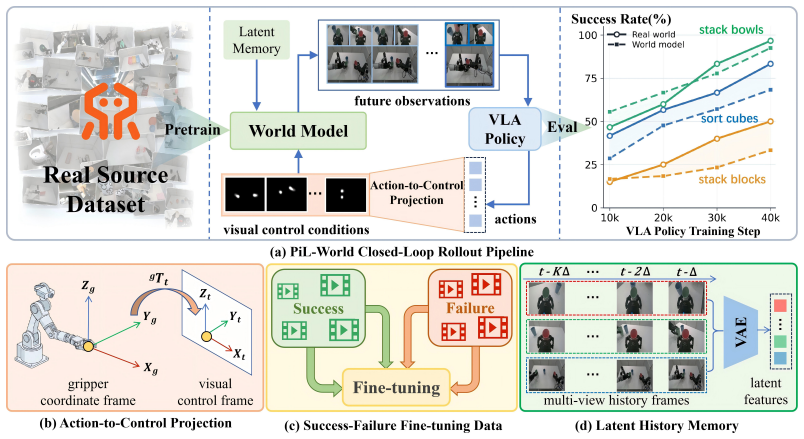
PiL-World is a chunk-wise world model that, given an observation and a VLA policy's action trajectory, produces multi-view future observations consistent with the rollout. By alternating VLA inference with world-model prediction it supports closed-loop evaluation without physical execution at every step. Generation is conditioned on action-derived visual control from head-view robot motion and on latent histories that encode task context; the model is trained on both successful demonstrations and failed executions so that imagined rollouts better match the distribution of real policy behavior.
What carries the argument
Chunk-wise video generation conditioned on action-derived visual control signals and latent task-execution histories, run in alternation with the VLA policy to close the observation-action loop.
If this is right
- VLA policies can be evaluated in closed loop at scale without repeated physical robot resets or human supervision.
- Training on failed trajectories improves the match between simulated and real policy behavior.
- Multi-view consistency is preserved so the generated images remain valid inputs for the original VLA policy.
- The same alternating inference-prediction loop can be applied to any chunked action policy that expects image observations.
Where Pith is reading between the lines
- Faster iteration on VLA policies becomes possible if developers can obtain reliable success-rate estimates from simulation alone.
- Extending the model to longer horizons or additional camera views could further reduce the residual 12 percent discrepancy.
- The approach may transfer to other sequential robotic tasks where action chunks must be evaluated against newly generated observations.
Load-bearing premise
The synthetic multi-view images produced by the world model are close enough to the real camera inputs that the VLA policy makes decisions whose action distributions and success statistics stay close to those observed on the physical robot.
What would settle it
Run the identical VLA policy on each of the three dual-arm tasks for at least 50 real rollouts and 50 PiL-World rollouts; if the absolute difference in success rates exceeds 20 percentage points on any task, the 12 percent error reduction does not hold.
Figures


read the original abstract
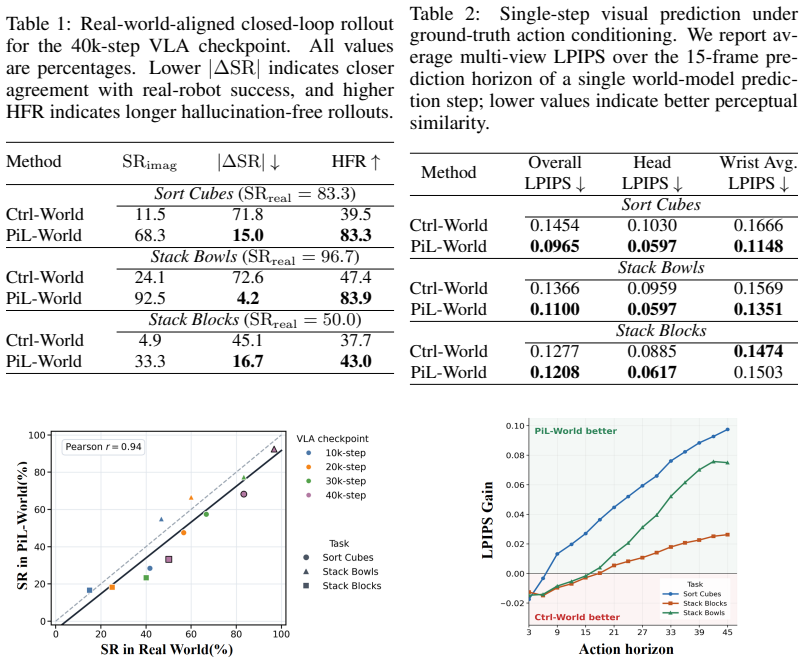
Vision-language-action (VLA) policies operate in a closed loop in real-world robot tasks: a robot observes the scene, executes an action chunk, and conditions its next decision on the resulting observation. However, most existing world models for robot action evaluation are limited to open-loop prediction along pre-collected action trajectories. This prevents them from supporting closed-loop VLA evaluation, where each action chunk must be conditioned on the observation generated by the previous execution. To address this gap, we propose PiL-World, a chunk-wise world model designed for policy-in-the-loop VLA evaluation. Given the current observation and the action trajectory rolled out by a VLA policy, PiL-World generates multi-view future observations that are consistent with the VLA rollout and match the image inputs required by the policy. By alternating between VLA inference and world-model prediction, PiL-World enables closed-loop evaluation without real robot execution at every step. To improve rollout fidelity, PiL-World conditions video generation on action-derived visual control from head-view robot motion and latent histories that encode task execution context, while jointly predicting complementary multi-view observations. Beyond successful teleoperated demonstrations, it also learns from failed execution trajectories, helping the imagined rollouts better match the distribution of real policy executions. We evaluate PiL-World on three real dual-arm manipulation tasks. PiL-World generates imagined rollouts that are highly consistent with real robot executions. More importantly, compared with the baseline, it reduces the error between VLA success rates measured in real-world rollouts and those estimated through closed-loop world-model evaluation from 63.2% to 12.0%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PiL-World, a chunk-wise world model for policy-in-the-loop (PiL) evaluation of vision-language-action (VLA) policies. Unlike prior open-loop world models, PiL-World generates multi-view future observations conditioned on the VLA's action trajectory, action-derived visual control from head-view motion, and latent histories encoding task context; it is trained on both successful demonstrations and failed trajectories. Closed-loop evaluation is performed by alternating VLA inference on generated observations with world-model prediction. On three real dual-arm manipulation tasks, the model produces rollouts described as highly consistent with real executions and reduces the error between real-world VLA success rates and those estimated via closed-loop world-model evaluation from 63.2% to 12.0%.
Significance. If the central empirical claim holds after verification, PiL-World would address a practical bottleneck in VLA research by enabling scalable closed-loop policy evaluation that approximates real-robot behavior without exhaustive physical rollouts. The explicit use of failed trajectories and joint multi-view prediction are concrete design choices that could improve distribution matching over standard video-prediction baselines.
major comments (2)
- [Abstract] Abstract: The headline quantitative result (error reduced from 63.2% to 12.0%) requires that VLA policies produce statistically similar action distributions and success statistics when conditioned on PiL-World-generated observations versus real images. No metric directly quantifying this (e.g., action-distribution divergence, per-chunk success prediction correlation, or policy output KL divergence between real and generated inputs) is described; qualitative statements of consistency are insufficient to substantiate the closed-loop fidelity claim.
- [Evaluation] Evaluation section (implied by abstract results): The reported 12.0% error figure is presented without accompanying details on trial counts, statistical tests, variance across seeds, or exact baseline implementation. This makes it impossible to determine whether the improvement is robust or sensitive to post-hoc choices in chunking or success labeling.
minor comments (1)
- The abstract states that the model 'matches the image inputs required by the policy,' but the manuscript should include an explicit ablation or table showing policy behavior under real versus generated multi-view inputs to make this claim verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of evaluation rigor. We address each major comment below and will revise the manuscript accordingly to strengthen the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline quantitative result (error reduced from 63.2% to 12.0%) requires that VLA policies produce statistically similar action distributions and success statistics when conditioned on PiL-World-generated observations versus real images. No metric directly quantifying this (e.g., action-distribution divergence, per-chunk success prediction correlation, or policy output KL divergence between real and generated inputs) is described; qualitative statements of consistency are insufficient to substantiate the closed-loop fidelity claim.
Authors: We agree that the closed-loop fidelity claim would benefit from explicit quantitative metrics beyond the success-rate error reduction and qualitative descriptions. In the revised manuscript, we will add policy-output KL divergence between actions generated on real versus PiL-World observations, as well as per-chunk success-prediction correlation and action-distribution divergence metrics. These additions will directly quantify the similarity in VLA behavior under the two input regimes. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by abstract results): The reported 12.0% error figure is presented without accompanying details on trial counts, statistical tests, variance across seeds, or exact baseline implementation. This makes it impossible to determine whether the improvement is robust or sensitive to post-hoc choices in chunking or success labeling.
Authors: We concur that the evaluation reporting is currently insufficient for assessing robustness. The revised version will expand the evaluation section to include: the exact number of trials per task and condition, results of appropriate statistical tests (e.g., paired t-tests or bootstrap confidence intervals), standard deviations or variance across random seeds, and a precise description of the baseline implementation together with the chunking procedure and success-labeling criteria used for both real and simulated rollouts. revision: yes
Circularity Check
No circularity: empirical comparison uses independent real-robot rollouts as benchmark
full rationale
The paper's central claim is an empirical reduction in error (63.2% to 12.0%) between VLA success rates from physical robot executions and those obtained via closed-loop simulation. Real-world rollouts provide an external ground truth measured separately from the world-model training and inference process. No equations, fitted parameters, or self-citations are presented that would make the reported success-rate match reduce to a definitional equivalence or to quantities fitted on the same evaluation data. The evaluation loop is closed only in the simulated path; the reference measurements remain independent.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Video generation conditioned on action-derived visual control and latent histories can produce observations that the downstream VLA policy treats as valid inputs
- domain assumption Training on failed execution trajectories improves the match between imagined rollouts and the distribution of real policy executions
invented entities (1)
-
PiL-World
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[2]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[3]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models. InICRA, pages 6892–6903. IEEE, 2024
2024
-
[4]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[5]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
- [6]
-
[7]
T. Su, J. Zhu, Y . Li, C. Ma, J. Zhang, Z. Huang, H. Wang, and Y . Xu. Towards high-consistency embodied world model with multi-view trajectory videos.arXiv preprint arXiv:2511.12882, 2025
arXiv 2025
-
[8]
RealSource World: A large-scale real-world dual-arm manipulation dataset
RealSource. RealSource World: A large-scale real-world dual-arm manipulation dataset. https://huggingface.co/datasets/RealSourceData/RealSource-World, 2025
2025
-
[9]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kir- mani, et al. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
Pith/arXiv arXiv 2024
-
[10]
Y . Li, Y . Zhu, J. Wen, C. Shen, and Y . Xu. Worldeval: World model as real-world robot policies evaluator.arXiv preprint arXiv:2505.19017, 2025
arXiv 2025
-
[11]
Y . Li, Z. Zhou, Y . Chen, Y . Xue, and Y . Zhu. dworldeval: Scalable robotic policy evaluation via discrete diffusion world model.arXiv preprint arXiv:2604.22152, 2026
Pith/arXiv arXiv 2026
-
[12]
J. Quevedo, A. K. Sharma, Y . Sun, V . Suryavanshi, P. Liang, and S. Yang. Worldgym: World model as an environment for policy evaluation.arXiv preprint arXiv:2506.00613, 2025
arXiv 2025
-
[13]
P. Wu, A. Escontrela, D. Hafner, P. Abbeel, and K. Goldberg. Daydreamer: World models for physical robot learning. InCoRL, pages 2226–2240. PMLR, 2023
2023
-
[14]
F. Zhu, H. Wu, S. Guo, Y . Liu, C. Cheang, and T. Kong. Irasim: Learning interactive real-robot action simulators.arXiv preprint arXiv:2406.14540, 1(2):3, 2024
arXiv 2024
-
[15]
Y . Guo, L. X. Shi, J. Chen, and C. Finn. Ctrl-world: A controllable generative world model for robot manipulation.arXiv preprint arXiv:2510.10125, 2025
Pith/arXiv arXiv 2025
-
[16]
Y . Li, Z. Zhou, Y . Chen, Y . Guo, J. Liu, S. Zhang, J. Chen, and Y . Zhu. Hi-wm: Human-in- the-world-model for scalable robot post-training.arXiv preprint arXiv:2604.21741, 2026. 9
Pith/arXiv arXiv 2026
-
[17]
J. Oh, X. Guo, H. Lee, R. L. Lewis, and S. Singh. Action-conditional video prediction using deep networks in atari games.NeurIPS, 28, 2015
2015
-
[18]
A. Xie, F. Ebert, S. Levine, and C. Finn. Improvisation through physical understanding: Using novel objects as tools with visual foresight.arXiv preprint arXiv:1904.05538, 2019
Pith/arXiv arXiv 1904
-
[19]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.NeurIPS, 33:6840– 6851, 2020
2020
-
[20]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, pages 10684–10695, 2022
2022
-
[21]
A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y . Levi, Z. En- glish, V . V oleti, A. Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
Pith/arXiv arXiv 2023
-
[22]
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
Pith/arXiv arXiv 2025
-
[23]
Y . Guo, T. Lee, L. X. Shi, J. Chen, P. Liang, and C. Finn. Vlaw: Iterative co-improvement of vision-language-action policy and world model.arXiv preprint arXiv:2602.12063, 2026
arXiv 2026
-
[24]
Y . Chen, R. Chen, D. Huo, Y . Yang, D. Qi, H. Liu, T. Lin, S. Zeng, J. Xiao, X. Chang, et al. Abot-physworld: Interactive world foundation model for robotic manipulation with physics alignment.arXiv preprint arXiv:2603.23376, 2026
arXiv 2026
-
[25]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[26]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
2022
-
[27]
sort the cubes by size
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, pages 586–595, 2018. A Supplementary Materials A.1 Target-Task Descriptions PiL-World is evaluated on three real dual-arm manipulation tasks. Figure A.1 provides visual exam- ples of the target tasks and their subtask...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.