Beyond Absolute Scores: Relative Edit-induced Difference for Generalizable Image Aesthetic Assessment
Pith reviewed 2026-06-30 11:09 UTC · model grok-4.3
The pith
Learning relative aesthetic differences from edited image pairs lets models capture comparison-based human reasoning instead of fitting absolute scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that controllable image editing can simulate the comparison process in human aesthetic reasoning, and that training solely on the resulting relative differences (via a three-stage strategy and ranking consistency reward) produces models that learn generalizable aesthetic principles rather than dataset-specific score distributions.
What carries the argument
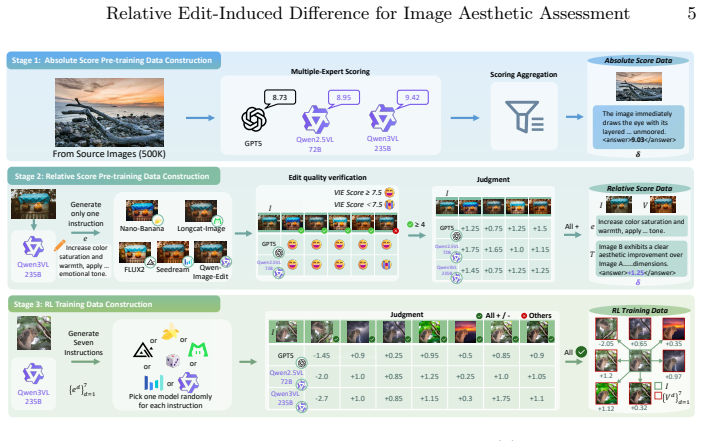
RED-Aes framework, which uses editing-based image pairs and relative ranking supervision to learn the visual factors that cause aesthetic changes.
Load-bearing premise
Controllable image editing models can generate pairs whose aesthetic differences accurately reflect the causal factors humans use when judging aesthetics.
What would settle it
A new benchmark of images whose aesthetic differences arise from factors that editing models cannot simulate, on which the relative method shows no advantage over absolute-score baselines.
Figures













read the original abstract
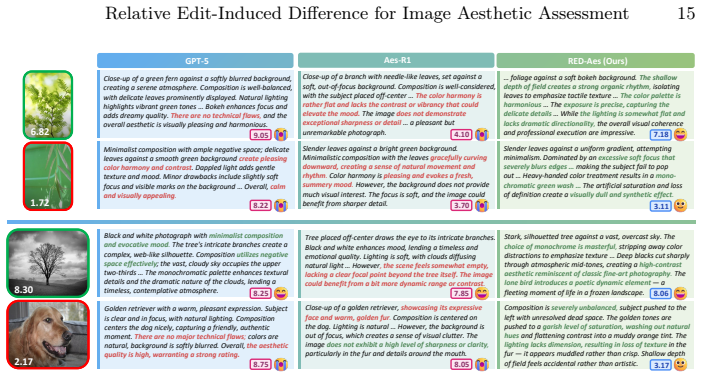
Traditional Image Aesthetic Assessment (IAA) methods mainly rely on regressing absolute Mean Opinion Scores (MOS). However, such a paradigm overlooks the inherently dynamic nature of human aesthetic perception, which relies on subconscious comparison against implicit visual references. Consequently, the lack of causal reasoning regarding aesthetic differences prevents models from learning generalizable aesthetic principles, thus limiting their generalization across diverse scenarios. In this work, we rethink the IAA task and propose Relative Edit-induced Difference Aesthetic learning (RED-Aes), a novel framework that leverages controllable image editing models to simulate the human aesthetic reasoning process. Instead of fitting absolute score distributions, RED-Aes explicitly learns the visual factors that drive aesthetic changes. To support this paradigm, we construct the RED-20k dataset, which comprises editing-based image pairs, quantitative aesthetic differences, and Chain-of-Thought (CoT) reasoning. Furthermore, we introduce a three-stage training strategy guided by a relative ranking consistency reward, optimizing the model solely via relative supervision. Extensive experiments demonstrate that RED-Aes achieves state-of-the-art performance on multiple public benchmarks, exhibiting superior generalization capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RED-Aes, a framework for image aesthetic assessment that replaces absolute MOS regression with relative learning. It uses controllable image editing models to generate image pairs, quantitative aesthetic differences, and Chain-of-Thought reasoning in the new RED-20k dataset, then applies a three-stage training strategy driven by a relative ranking consistency reward. The central claim is that this yields state-of-the-art performance and superior generalization across public benchmarks by learning the visual factors that drive aesthetic changes.
Significance. If the generated edits accurately simulate the causal factors in human aesthetic judgments, the shift to relative supervision and the accompanying dataset could meaningfully improve generalization in IAA. The work supplies a concrete alternative to absolute-score fitting and introduces an explicit relative reward, which are positive contributions if the core assumption is supported.
major comments (2)
- [Dataset construction / RED-20k] Dataset construction: the claim that editing-model outputs simulate human aesthetic reasoning is load-bearing, yet the manuscript provides no independent check (human correlation study, ablation on edit realism, or comparison against real reference-based judgments) that the quantitative differences and CoT align with human perceptual factors rather than model-specific artifacts.
- [Experiments] Experiments section: the SOTA and generalization claims are asserted without reported quantitative details on editing validation, baseline comparisons, error bars, or sensitivity to post-hoc editing choices, leaving the central empirical support without visible derivation.
minor comments (2)
- [Training strategy] Clarify the precise mathematical definition of the relative ranking consistency reward and how it is applied across the three training stages.
- [Method overview] Add explicit discussion of the dependence on pre-existing editing models as an external component and any associated limitations.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments point-by-point below, acknowledging where additional evidence or clarification is warranted.
read point-by-point responses
-
Referee: [Dataset construction / RED-20k] Dataset construction: the claim that editing-model outputs simulate human aesthetic reasoning is load-bearing, yet the manuscript provides no independent check (human correlation study, ablation on edit realism, or comparison against real reference-based judgments) that the quantitative differences and CoT align with human perceptual factors rather than model-specific artifacts.
Authors: We agree that the absence of an independent human validation study for the RED-20k pairs constitutes a substantive gap. The current construction relies on the controllability properties of the chosen editing models and the generated CoT to approximate aesthetic factors, but this does not substitute for direct correlation with human judgments. In the revision we will add a human correlation study on a subset of the pairs together with an ablation comparing model-generated differences against real reference-based aesthetic judgments. revision: yes
-
Referee: [Experiments] Experiments section: the SOTA and generalization claims are asserted without reported quantitative details on editing validation, baseline comparisons, error bars, or sensitivity to post-hoc editing choices, leaving the central empirical support without visible derivation.
Authors: The full manuscript reports benchmark results on multiple public IAA datasets with comparisons to prior methods. However, we acknowledge that explicit quantitative validation of the editing pipeline, error bars across runs, and sensitivity analysis to editing hyperparameters are not presented at the level of detail requested. We will expand the experiments section to include these elements, including tables reporting editing validation metrics and sensitivity results. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper constructs an external RED-20k dataset from controllable editing models and applies a three-stage training process with relative ranking consistency reward. Claims of SOTA generalization rest on evaluation against independent public benchmarks rather than any internal fit or self-referential loop. No equations, definitions, or self-citations reduce the reported performance or the learned aesthetic factors to the training inputs by construction. The supervision signal and evaluation data remain distinct from the model outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- training hyperparameters and reward scaling
axioms (1)
- domain assumption Controllable image editing models generate pairs whose differences reflect true aesthetic causal factors
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops
Agustsson, E., Timofte, R.: Ntire 2017 challenge on single image super-resolution: Dataset and study. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops. pp. 126–135 (2017)
2017
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. ArXivabs/2502.13923(2025),https: //api.semanticscholar.org/CorpusID:276449796
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
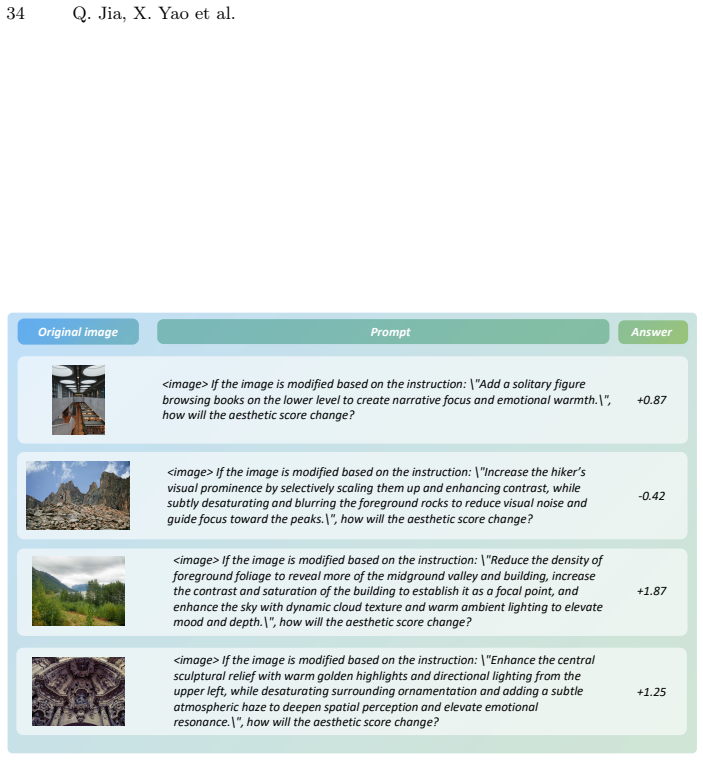
[4]
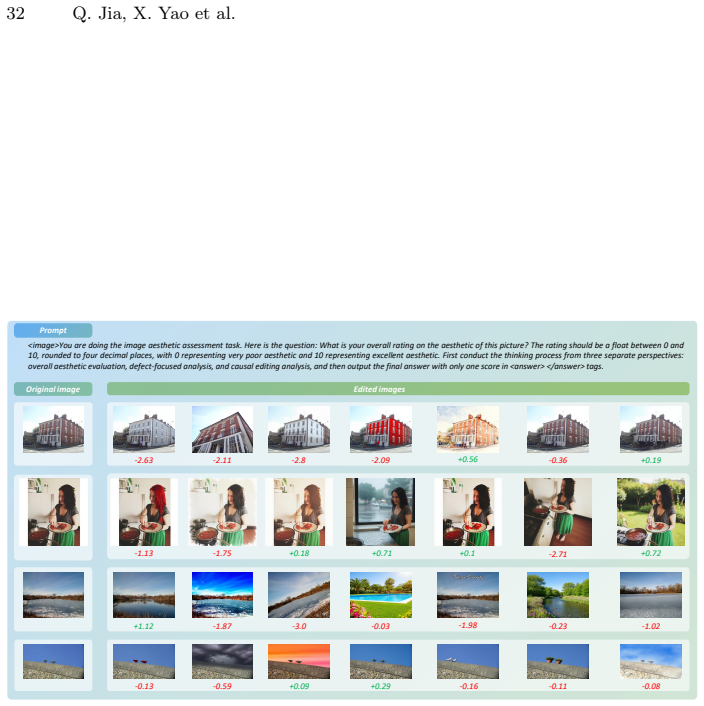
Astronomical Journal (ISSN 0004-6256), vol
Beers, T.C., Flynn, K., Gebhardt, K.: Measures of location and scale for velocities in clusters of galaxies-a robust approach. Astronomical Journal (ISSN 0004-6256), vol. 100, July 1990, p. 32-46.100, 32–46 (1990)
1990
-
[5]
In: Noise reduction in speech processing, pp
Benesty, J., Chen, J., Huang, Y., Cohen, I.: Pearson correlation coefficient. In: Noise reduction in speech processing, pp. 1–4. Springer (2009)
2009
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Brooks, T., Holynski, A., Efros, A.A.: Instructpix2pix: Learning to follow image editing instructions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18392–18402 (2023)
2023
-
[7]
arXiv preprint arXiv:2512.21675 (2025)
Cao, S., Li, J., Li, X., Pu, Y., Zhu, K., Gao, Y., Luo, S., Xin, Y., Qin, Q., Zhou, Y., et al.: Unipercept: Towards unified perceptual-level image understanding across aesthetics, quality, structure, and texture. arXiv preprint arXiv:2512.21675 (2025)
-
[8]
arXiv preprint arXiv:2507.14533 (2025)
Cao, S., Ma, N., Li, J., Li, X., Shao, L., Zhu, K., Zhou, Y., Pu, Y., Wu, J., Wang, J., et al.: Artimuse: Fine-grained image aesthetics assessment with joint scoring and expert-level understanding. arXiv preprint arXiv:2507.14533 (2025)
-
[9]
In: European conference on computer vision
Datta, R., Joshi, D., Li, J., Wang, J.Z.: Studying aesthetics in photographic images using a computational approach. In: European conference on computer vision. pp. 288–301. Springer (2006)
2006
-
[10]
Gao, F., Lin, Y., Shi, J., Qiao, M., Wang, N.: Aesmamba: Universal image aesthetic assessmentwithstatespacemodels.In:Proceedingsofthe32ndACMInternational Conference on Multimedia. pp. 7444–7453 (2024)
2024
-
[11]
https://blog.google/innovation- and- ai/products/nano- banana- pro/(11 2025), accessed: 2026-03-19
Google: Nano Banana Pro: Gemini 3 Pro Image model from Google DeepMind. https://blog.google/innovation- and- ai/products/nano- banana- pro/(11 2025), accessed: 2026-03-19
2025
-
[12]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Guo, D., Wu, F., Zhu, F., Leng, F., Shi, G., Chen, H., Fan, H., Wang, J., Jiang, J., Wang, J., et al.: Seed1. 5-vl technical report. arXiv preprint arXiv:2505.07062 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
In: IJCAI
He, S., Zhang, Y., Xie, R., Jiang, D., Ming, A.: Rethinking image aesthetics as- sessment: Models, datasets and benchmarks. In: IJCAI. vol. 6, p. 22 (2022)
2022
-
[15]
In: European Conference on Computer Vision
Hosu, V., Conde, M.V., Agnolucci, L., Barman, N., Zadtootaghaj, S., Timofte, R., Sun, W., Zhang, W., Cao, Y., Cao, L., et al.: Aim 2024 challenge on uhd blind photo quality assessment. In: European Conference on Computer Vision. pp. 261–286. Springer (2024)
2024
-
[16]
In: Proceedings of the 32nd ACM International Conference on Multi- media
Huang, Y., Sheng, X., Yang, Z., Yuan, Q., Duan, Z., Chen, P., Li, L., Lin, W., Shi, G.: Aesexpert: Towards multi-modality foundation model for image aesthetics Relative Edit-Induced Difference for Image Aesthetic Assessment 17 perception. In: Proceedings of the 32nd ACM International Conference on Multi- media. pp. 5911–5920 (2024)
2024
-
[17]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Quality Press (1993)
Iglewicz, B., Hoaglin, D.C.: Volume 16: how to detect and handle outliers. Quality Press (1993)
1993
-
[19]
In: Proceedings of the IEEE/CVF international conference on computer vision
Ke, J., Wang, Q., Wang, Y., Milanfar, P., Yang, F.: Musiq: Multi-scale image quality transformer. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5148–5157 (2021)
2021
-
[20]
In: European conference on computer vision
Kong, S., Shen, X., Lin, Z., Mech, R., Fowlkes, C.: Photo aesthetics ranking net- work with attributes and content adaptation. In: European conference on computer vision. pp. 662–679. Springer (2016)
2016
-
[21]
Dataset available from https://github
Krasin, I., Duerig, T., Alldrin, N., Ferrari, V., Abu-El-Haija, S., Kuznetsova, A., Rom, H., Uijlings, J., Popov, S., Veit, A., et al.: Openimages: A public dataset for large-scale multi-label and multi-class image classification. Dataset available from https://github. com/openimages2(3), 18 (2017)
2017
-
[22]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Ku, M., Jiang, D., Wei, C., Yue, X., Chen, W.: Viescore: Towards explainable metrics for conditional image synthesis evaluation. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 12268–12290 (2024)
2024
-
[23]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Labs, B.F., Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dock- horn, T., English, J., English, Z., Esser, P., et al.: Flux. 1 kontext: Flow match- ing for in-context image generation and editing in latent space. arXiv preprint arXiv:2506.15742 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
British journal of psychology95(4), 489–508 (2004)
Leder, H., Belke, B., Oeberst, A., Augustin, D.: A model of aesthetic appreciation and aesthetic judgments. British journal of psychology95(4), 489–508 (2004)
2004
-
[25]
Journal of experimental social psychology49(4), 764–766 (2013)
Leys, C., Ley, C., Klein, O., Bernard, P., Licata, L.: Detecting outliers: Do not use standard deviation around the mean, use absolute deviation around the median. Journal of experimental social psychology49(4), 764–766 (2013)
2013
-
[26]
arXiv preprint arXiv:2503.22679 (2025)
Li, W., Zhang, X., Zhao, S., Zhang, Y., Li, J., Zhang, L., Zhang, J.: Q-insight: Understanding image quality via visual reinforcement learning. arXiv preprint arXiv:2503.22679 (2025)
-
[27]
arXiv preprint arXiv:2509.21871 (2025)
Liu, B., Hu, Y., Jin, S., Dou, S., Shi, G., Shao, J., Gui, T., Huang, X.: Unlocking the essence of beauty: Advanced aesthetic reasoning with relative-absolute policy optimization. arXiv preprint arXiv:2509.21871 (2025)
-
[28]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[29]
In: Proceedings of the IEEE International Conference on Computer Vision (ICCV) (Oct 2017)
Liu, X., van de Weijer, J., Bagdanov, A.D.: Rankiqa: Learning from rankings for no-reference image quality assessment. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV) (Oct 2017)
2017
-
[30]
In: 2011 international con- ference on computer vision
Marchesotti, L., Perronnin, F., Larlus, D., Csurka, G.: Assessing the aesthetic quality of photographs using generic image descriptors. In: 2011 international con- ference on computer vision. pp. 1784–1791. IEEE (2011)
2011
-
[31]
In: 2012 IEEE conference on computer vision and pattern recognition
Murray, N., Marchesotti, L., Perronnin, F.: Ava: A large-scale database for aes- thetic visual analysis. In: 2012 IEEE conference on computer vision and pattern recognition. pp. 2408–2415. IEEE (2012)
2012
-
[32]
Reber, R., Schwarz, N., Winkielman, P.: Processing fluency and aesthetic plea- sure: Is beauty in the perceiver’s processing experience? Personality and social psychology review8(4), 364–382 (2004) 18 Q. Jia, X. Yao et al
2004
-
[33]
In: Proceedings of the IEEE international conference on computer vision
Ren, J., Shen, X., Lin, Z., Mech, R., Foran, D.J.: Personalized image aesthetics. In: Proceedings of the IEEE international conference on computer vision. pp. 638–647 (2017)
2017
-
[34]
Advances in neural information processing systems35, 25278–25294 (2022)
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large- scale dataset for training next generation image-text models. Advances in neural information processing systems35, 25278–25294 (2022)
2022
-
[35]
Bmj349(2014)
Sedgwick, P.: Spearman’s rank correlation coefficient. Bmj349(2014)
2014
-
[36]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Seedream, T., Chen, Y., Gao, Y., Gong, L., Guo, M., Guo, Q., Guo, Z., Hou, X., Huang, W., Huang, Y., et al.: Seedream 4.0: Toward next-generation multimodal image generation. arXiv preprint arXiv:2509.20427 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
IEEE transactions on image processing27(8), 3998–4011 (2018)
Talebi, H., Milanfar, P.: Nima: Neural image assessment. IEEE transactions on image processing27(8), 3998–4011 (2018)
2018
-
[40]
LongCat-Image Technical Report
Team, M.L., Ma, H., Tan, H., Huang, J., Wu, J., He, J.Y., Gao, L., Xiao, S., Wei, X., Ma, X., et al.: Longcat-image technical report. arXiv preprint arXiv:2512.07584 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Unsplash: Unsplash lite dataset 1.3.0.https://unsplash.com/data(2020)
2020
-
[42]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wu, H., Zhang, Z., Zhang, E., Chen, C., Liao, L., Wang, A., Xu, K., Li, C., Hou, J., Zhai, G., et al.: Q-instruct: Improving low-level visual abilities for multi-modality foundation models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 25490–25500 (2024)
2024
-
[44]
Q-Align: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels
Wu, H., Zhang, Z., Zhang, W., Chen, C., Liao, L., Li, C., Gao, Y., Wang, A., Zhang, E., Sun, W., et al.: Q-align: Teaching lmms for visual scoring via discrete text-defined levels. arXiv preprint arXiv:2312.17090 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
arXiv preprint arXiv:2505.14460 (2025)
Wu, T., Zou, J., Liang, J., Zhang, L., Ma, K.: Visualquality-r1: Reasoning-induced image quality assessment via reinforcement learning to rank. arXiv preprint arXiv:2505.14460 (2025)
-
[46]
Advances in Neural Information Processing Systems36, 15903–15935 (2023)
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36, 15903–15935 (2023)
2023
-
[47]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, Y., Xu, L., Li, L., Qie, N., Li, Y., Zhang, P., Guo, Y.: Personalized im- age aesthetics assessment with rich attributes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19861–19869 (2022)
2022
-
[48]
arXiv e-prints pp
You, Z., Gu, J., Li, Z., Cai, X., Zhu, K., Dong, C., Xue, T.: Descriptive image quality assessment in the wild. arXiv e-prints pp. arXiv–2405 (2024)
2024
-
[49]
Advances in Neural Information Pro- cessing Systems36, 31428–31449 (2023)
Zhang, K., Mo, L., Chen, W., Sun, H., Su, Y.: Magicbrush: A manually annotated dataset for instruction-guided image editing. Advances in Neural Information Pro- cessing Systems36, 31428–31449 (2023)
2023
-
[50]
Advances in Neural Information Processing Systems37, 3058–3093 (2024) Relative Edit-Induced Difference for Image Aesthetic Assessment 19
Zhao,H., Ma,X.,Chen,L.,Si,S.,Wu,R.,An,K.,Yu,P.,Zhang,M.,Li,Q.,Chang, B.: Ultraedit: Instruction-based fine-grained image editing at scale. Advances in Neural Information Processing Systems37, 3058–3093 (2024) Relative Edit-Induced Difference for Image Aesthetic Assessment 19
2024
-
[51]
Zhou, Z., Wang, Q., Lin, B., Su, Y., Chen, R., Tao, X., Zheng, A., Yuan, L., Wan, P., Zhang, D.: Uniaa: A unified multi-modal image aesthetic assessment baseline and benchmark. arXiv preprint arXiv:2404.09619 (2024) A Multi-expert Voting Protocol We employ a multi-expert voting protocol to produce consensus aesthetic scores for the source poolO. GivenNexp...
-
[52]
Analyze the image from an aesthetic perspective and identify the key factors that affect its visual quality. Focus on high−level aesthetic aspects such as: − Composition and visual balance − Subject prominence and depth relationships − Semantic clarity and narrative coherence − Mood, emotion, and visual tension Avoid limiting the analysis to low−level par...
-
[53]
Based on your analysis, assign an overall aesthetic score to the image. − Score range: 0 to 10 − Rounded to two decimal places − No explanation or text allowed Output only the numeric score inside the following tags: <answer1> X.XX </answer1> ==================== Part 3: Aesthetic−Oriented Image Editing Proposals (Outside Tags) ====================
-
[54]
Propose image editing strategies that directly address the aesthetic issues identified in Part 1. 22 Q. Jia, X. Yao et al. The goal is to improve the image by correcting or mitigating these specific deficiencies
-
[55]
When proposing editing strategies, follow these principles: − Prioritize structural, semantic, and perceptual edits over simple parameter tuning − Treat image editing as explicit action decisions (e.g., add, remove, replace, restructure, emphasize, suppress) − Encourage diversity and avoid redundancy − Propose new, reasonable editing operations if necessary
-
[56]
==================== Part 4: Generate a Single Executable Editing Instruction ====================
You may consider (but are not limited to) the following image editing action space: − Object−level editing: add, remove, replace, move, scale, rearrange objects − Attribute−level editing: modify color, material, shape, pose, or expression − Background and scene editing: background replacement, scene transformation, environment restructuring − Composition ...
-
[57]
score" : [...],
Based on the editing strategies proposed in Part 3, generate ONE concise , executable image editing instruction. The instruction must: − Describe only the editing action − Contain no explanation, analysis, or evaluation − Be directly usable by an image editing model or system Output only this single−sentence editing instruction inside the following tags: ...
-
[58]
The instruction must describe an image EDIT operation (modifying an existing image, not generating a new image from scratch)
-
[59]
The instruction must clearly and substantially involve the given edit category
-
[60]
The edit can be free−form and creative, including adding or removing objects, changing layout or composition, or altering style and environment
-
[61]
Output rules: − Output ONLY the instruction text
The edit must be feasible for modern image editing models. Output rules: − Output ONLY the instruction text. − No explanations. − No formatting. Training Stage Prompts.This section details the prompt templates designed forthequestionpartofthetrainingdatausedinourmethod.Thesetemplatesare employed across different stages to construct the Q&A pairs for model...
-
[62]
as judges to determine the direction of aesthetic change (δ). A strict consensus mechanism was adopted, requiringunanimous agreementamong all three judges to filter out ambiguous or noisy pairs. Tab. 10 reports the pairwise agreement rates calculated on the candidate poolpriorto consensus filtering. The moderate Relative Edit-Induced Difference for Image ...
-
[63]
The overhead structure dominates the top half, which may feel heavy or obstructive
Composition and framing: - Image A is framed from under a large structure (hangar or bridge), which creates a dramatic, slightly constrained perspective. The overhead structure dominates the top half, which may feel heavy or obstructive. - Image B removes the overhead structure, offering a cleaner, more open composition. The aircraft is centered and fully...
-
[64]
While dramatic, this creates harsh transitions and potentially lost detail in shadows
Lighting and exposure: - Image A has strong contrast due to the shadowed foreground and bright sky. While dramatic, this creates harsh transitions and potentially lost detail in shadows. - Image B has more even lighting. The sky is brighter and more evenly exposed, with softer shadows on the aircraft. This enhances detail visibility and reduces harshness
-
[65]
However, Image B’s sky appears more vibrant and saturated without being oversaturated, enhancing the overall color harmony and visual richness
Color quality: - Both images have similar color palettes (silver aircraft, blue sky, white clouds). However, Image B’s sky appears more vibrant and saturated without being oversaturated, enhancing the overall color harmony and visual richness
-
[66]
No loss of detail is observed
Sharpness and clarity: - Both images are sharp, but Image B’s removal of the overhead structure eliminates potential visual clutter and allows the viewer’s eye to focus more directly on the aircraft. No loss of detail is observed
-
[67]
The subject is clearer and more immediately recognizable
Subject emphasis and visual clarity: - Image B places the aircraft more prominently in the frame, with no competing overhead elements. The subject is clearer and more immediately recognizable
-
[68]
- Image B’s background is cleaner, with unobstructed sky and distant buildings that provide context without competing for attention
Background cleanliness and distraction level: - Image A’s overhead structure is a significant distraction, pulling attention away from the aircraft and creating a visually busy upper frame. - Image B’s background is cleaner, with unobstructed sky and distant buildings that provide context without competing for attention
-
[69]
- Image B feels more open, airy, and celebratory of the aircraft’s design, enhancing its visual appeal and emotional resonance
Emotional impact and visual appeal: - Image A feels more industrial and moody due to the shadowed framing. - Image B feels more open, airy, and celebratory of the aircraft’s design, enhancing its visual appeal and emotional resonance
-
[70]
The removal of the distracting overhead structure and the improved lighting balance contribute to a more cohesive and professional aesthetic
Overall coherence and professional quality:- Image B presents a more polished, gallery-ready image. The removal of the distracting overhead structure and the improved lighting balance contribute to a more cohesive and professional aesthetic. Conclusion: Image B improves upon Image A in nearly every aesthetic dimension: composition, lighting, color vibranc...
-
[71]
No significant change
Composition and framing: Both images are nearly identical in framing and subject placement. No significant change
-
[72]
The shadows are deeper, which adds drama but may slightly reduce detail in dark areas
Lighting and exposure: Image B exhibits slightly higher contrast and more pronounced highlights on the subjects’ faces and clothing. The shadows are deeper, which adds drama but may slightly reduce detail in dark areas. This is a subtle enhancement in mood but a slight regression in tonal balance
-
[73]
However, the overall color temperature feels marginally cooler, which may reduce the warmth and intimacy conveyed
Color quality: Image B has marginally more saturated colors — the purple shirt and red lipstick appear slightly richer. However, the overall color temperature feels marginally cooler, which may reduce the warmth and intimacy conveyed. Net effect is a slight improvement in vibrancy but a slight loss in tonal harmony
-
[74]
There is no noticeable increase in noise or artifacts
Sharpness and clarity: Image B appears marginally sharper, especially in the hair strands and fabric textures. There is no noticeable increase in noise or artifacts. This is a clear improvement
-
[75]
The emotional connection between the couple feels more intense due to the heightened visual clarity
Subject emphasis and visual clarity: The increased contrast and sharpness in Image B make the subjects “pop” more against the background. The emotional connection between the couple feels more intense due to the heightened visual clarity. This is a positive change
-
[76]
No change
Background cleanliness and distraction level: The background (Ferris wheel) is equally clean and blurred in both images. No change
-
[77]
The subjects’ expressions and pose feel more impactful
Emotional impact and visual appeal: The slight increase in contrast and sharpness in Image B enhances the romantic, cinematic mood. The subjects’ expressions and pose feel more impactful. This is a clear improvement in emotional resonance
-
[78]
finished
Overall coherence and professional quality: Image B feels slightly more polished — the enhancements in sharpness and contrast contribute to a more “finished” look. There is no loss in coherence; if anything, it’s slightly more refined. Holistic assessment: While Image B has a minor regression in tonal harmony due to increased contrast and cooler temperatu...
-
[79]
The foreground cocktail, which is the focal point in Image A, loses texture and detail in Image B
Sharpness and clarity: Image B is significantly blurrier than Image A. The foreground cocktail, which is the focal point in Image A, loses texture and detail in Image B. This is a major regression
-
[80]
In Image B, the blur reduces its visual dominance and makes the scene feel less intentional or polished
Subject emphasis: In Image A, the cocktail is crisp and draws the eye immediately. In Image B, the blur reduces its visual dominance and makes the scene feel less intentional or polished
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.