SALT: When More Rollouts Don't Help in Group-Based Policy Optimization and How to Make Them Matter
Pith reviewed 2026-06-28 02:49 UTC · model grok-4.3
The pith
SALT reweights group-relative policy updates by amplifying residual gradient channels identified from mini-batch geometry to prevent cancellation when adding more rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
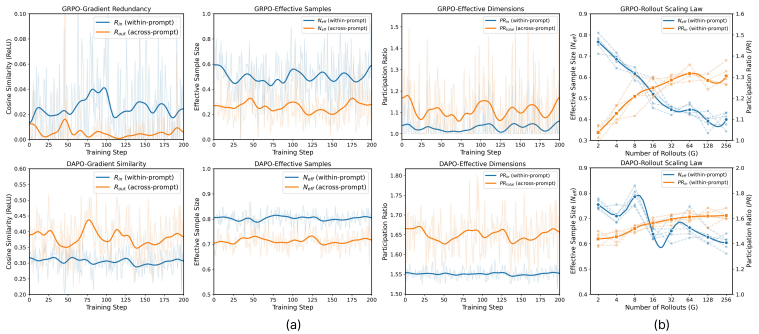
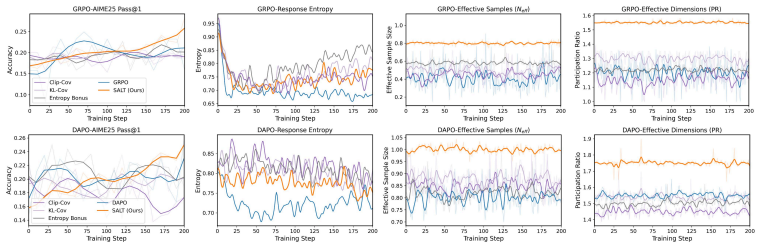
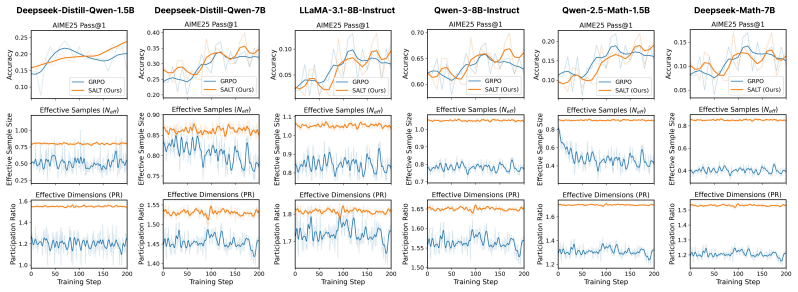
SALT estimates a dominant shared subspace from the mini-batch Gram geometry, decomposes group-relative coefficients into shared and residual channels, and adaptively amplifies the residual channel when signed cancellation is severe, improving effective update geometry and performance across RLVR benchmarks without modifying the reward model or rollout sampling.
What carries the argument
Mini-batch Gram geometry that identifies the dominant shared subspace for decomposing and selectively amplifying residual channels in group-relative coefficients.
If this is right
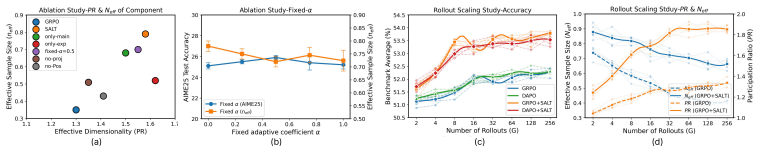
- Increasing rollout count becomes useful once residual-channel amplification is applied rather than relying on raw quantity.
- Effective update strength improves on reasoning-oriented RLVR tasks across multiple model scales.
- No changes to the reward model or sampling distribution are required for the gains.
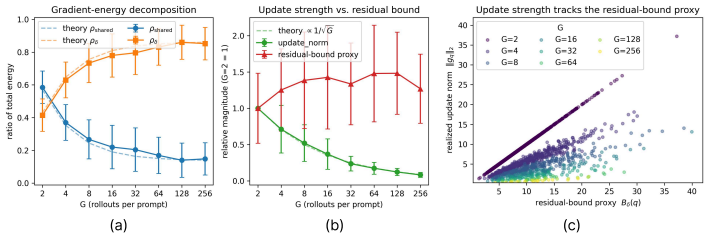
- Signed cancellation in low-rank gradient geometry is the primary bottleneck addressed by the subspace split.
Where Pith is reading between the lines
- The same Gram-based decomposition might apply to other group-normalized objectives outside RLVR.
- If residual amplification consistently reduces required group size, total compute for equivalent performance could drop.
- Low-rank structure in policy gradients may recur in other mini-batch optimization settings and respond to similar channel separation.
Load-bearing premise
The mini-batch Gram geometry reliably identifies a dominant shared subspace whose decomposition into shared and residual channels allows selective amplification to produce net-positive policy updates without introducing instability or bias.
What would settle it
A controlled run on the same RLVR benchmarks where the Gram-derived subspace decomposition either fails to separate a clear residual channel or where amplifying that channel produces equal or worse final performance and higher variance than the unadjusted GRPO baseline.
Figures




read the original abstract
Reinforcement learning with verifiable rewards (RLVR) often adopts GRPO-style group-relative updates, sampling multiple rollouts per prompt to construct normalized learning signals. However, merely increasing the number of rollouts does not reliably strengthen learning: under GRPO-style group normalization, per-rollout policy-gradient features can concentrate into a low-rank, signed geometry, causing substantial cancellation during aggregation and weakening the effective update. We address this failure mode with SALT, a Subspace-Adaptive geometry pLug-in componenT that uses sample-wise gradient geometry to reweight the coefficients of group-relative updates. SALT estimates a dominant shared subspace from the mini-batch Gram geometry, decomposes group-relative coefficients into shared and residual channels, and adaptively amplifies the residual channel when signed cancellation is severe. Across diverse reasoning-oriented RLVR benchmarks and model scales, SALT improves effective update geometry and performance without modifying the reward model or the rollout sampling procedure
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a failure mode in GRPO-style group-relative policy optimization for RLVR where increasing rollouts per prompt fails to strengthen learning because per-rollout policy-gradient features concentrate into a low-rank signed geometry, causing cancellation during aggregation. It proposes SALT, a Subspace-Adaptive geometry pLug-in componenT, that estimates a dominant shared subspace from the mini-batch Gram geometry of policy-gradient features, decomposes group-relative coefficients into shared and residual channels, and adaptively amplifies the residual channel when signed cancellation is severe. The method is claimed to improve effective update geometry and performance across diverse reasoning-oriented RLVR benchmarks and model scales without modifying the reward model or rollout sampling.
Significance. If the mechanism holds, SALT would address a practically relevant inefficiency in group-based RL methods by making additional rollouts contribute positively through geometry-aware reweighting rather than cancellation. The plug-in nature, requiring no changes to reward models or sampling, would make it broadly applicable if the subspace estimation reliably isolates cancellation directions.
major comments (1)
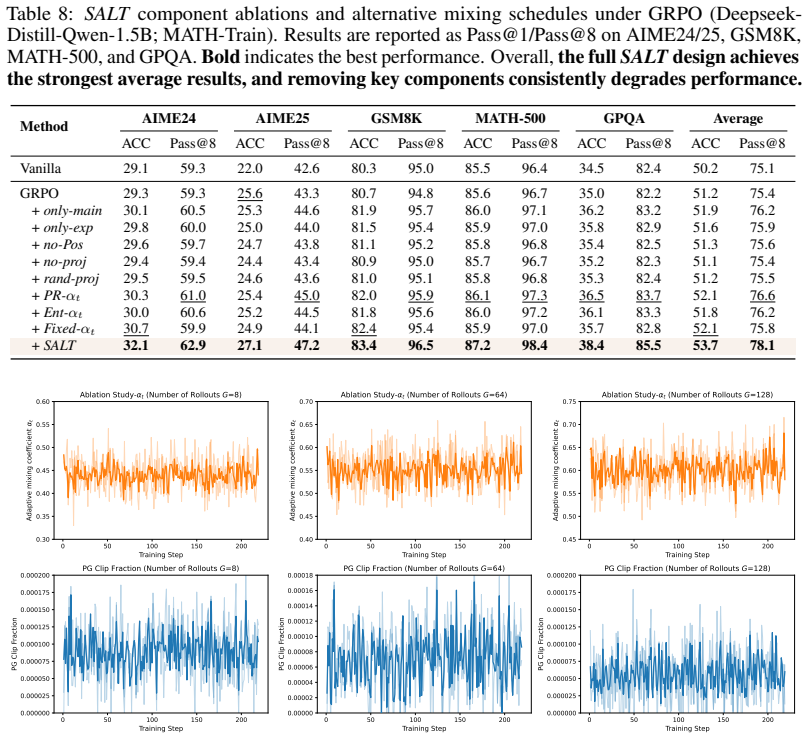
- [Abstract] Abstract: The central claim that SALT produces net-positive policy updates without bias or instability rests on the assumption that the top eigenvectors of the mini-batch Gram matrix align predominantly with low-rank signed cancellation directions (rather than prompt-specific variance or rollout noise). No bound on explained variance, proof that amplification preserves unbiasedness of the group-relative estimator, or derivation showing the decomposition isolates cancellation-specific components is supplied; this premise is load-bearing for the performance claims.
Simulated Author's Rebuttal
We thank the referee for their detailed reading and for identifying the load-bearing assumption in our work. Below we respond directly to the major comment, clarifying the empirical scope of the manuscript while acknowledging where formal analysis is absent.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that SALT produces net-positive policy updates without bias or instability rests on the assumption that the top eigenvectors of the mini-batch Gram matrix align predominantly with low-rank signed cancellation directions (rather than prompt-specific variance or rollout noise). No bound on explained variance, proof that amplification preserves unbiasedness of the group-relative estimator, or derivation showing the decomposition isolates cancellation-specific components is supplied; this premise is load-bearing for the performance claims.
Authors: We agree that the manuscript supplies no theoretical bounds on explained variance, no proof that residual amplification preserves unbiasedness of the group-relative estimator, and no formal derivation isolating cancellation-specific components. The paper is an empirical study: it documents the low-rank signed geometry of per-rollout policy-gradient features under GRPO-style normalization, shows that this geometry produces cancellation when rollouts increase, and demonstrates that a Gram-matrix-based decomposition plus residual amplification yields measurable gains on reasoning benchmarks. The alignment assumption is supported by the mini-batch visualizations and ablation results reported in the main text and appendix, where the top eigenvectors consistently correlate with directions of opposing signs across rollouts of the same prompt. Because the method is presented as a practical plug-in rather than a theoretically guaranteed estimator, we do not claim unbiasedness preservation beyond the original group-relative baseline; any bias introduced by adaptive amplification is treated as an empirical trade-off whose net effect is positive in the reported experiments. We are prepared to add an explicit limitations paragraph stating the absence of these guarantees if the editor requests it. revision: partial
Circularity Check
No circularity; derivation is self-contained plug-in
full rationale
The paper introduces SALT as an external plug-in that estimates a dominant shared subspace from mini-batch Gram geometry of policy-gradient features, decomposes coefficients into shared/residual channels, and amplifies the residual when signed cancellation is detected. No equations, fitted parameters, or predictions are shown that reduce by construction to the method's own inputs (no self-definitional loops, no fitted-input-called-prediction, no load-bearing self-citations). The central mechanism is presented as an independent geometric reweighting step whose validity is claimed to be verified empirically across RLVR benchmarks rather than derived from the target result itself. The derivation chain therefore remains non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Llama 3 model card
AI@Meta. Llama 3 model card. 2024. URL https://github.com/meta-llama/llama3/ blob/main/MODEL_CARD.md
2024
-
[2]
Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agarwal
Jordan T. Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agarwal. Deep batch active learning by diverse, uncertain gradient lower bounds. InInternational Conference on Learning Representations (ICLR), 2020. URL https://openreview.net/ forum?id=ryghZJBKPS
2020
-
[3]
Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
Pith/arXiv arXiv 2021
-
[4]
Junhua Chen, Zixi Zhang, Hantao Zhong, and Rika Antonova. Group policy gradient, 2025. URLhttps://arxiv.org/abs/2510.03679
arXiv 2025
-
[5]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
2021
-
[6]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. Introduces GSM8K
2021
-
[7]
The entropy mechanism of reinforcement learning for reasoning language models, 2025
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. The entropy mechanism of reinforcement learning for reasoning language models, 2025. URLhttps://arxiv.org/abs/2505.22617
Pith/arXiv arXiv 2025
-
[8]
Runpeng Dai, Linfeng Song, Haolin Liu, Zhenwen Liang, Dian Yu, Haitao Mi, Zhaopeng Tu, Rui Liu, Tong Zheng, Hongtu Zhu, and Dong Yu. Cde: Curiosity-driven exploration for efficient reinforcement learning in large language models, 2025. URL https://arxiv.org/ abs/2509.09675
arXiv 2025
-
[10]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. doi: 10.48550/ arXiv.2501.12948. URLhttps://arxiv.org/abs/2501.12948
Pith/arXiv arXiv 2025
-
[11]
Effective dimensionality: A tutorial.Multivariate Behavioral Research, 56(3):527–542, 2021
Marco Del Giudice. Effective dimensionality: A tutorial.Multivariate Behavioral Research, 56(3):527–542, 2021. doi: 10.1080/00273171.2020.1743631. URL https://doi.org/10. 1080/00273171.2020.1743631
-
[12]
Multi-layer grpo: Enhancing reasoning and self-correction in large language models, 2025
Fei Ding, Baiqiao Wang, Zijian Zeng, and Youwei Wang. Multi-layer grpo: Enhancing reasoning and self-correction in large language models, 2025. URL https://arxiv.org/abs/2506. 04746
2025
-
[13]
Group-in-group policy optimization for llm agent training, 2025
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training, 2025. URLhttps://arxiv.org/abs/2505.10978. 10
Pith/arXiv arXiv 2025
-
[14]
The effective number of shared dimen- sions between paired datasets
Hamza Giaffar, Camille Rullán Buxó, and Mikio Aoi. The effective number of shared dimen- sions between paired datasets. In Sanjoy Dasgupta, Stephan Mandt, and Yingzhen Li, editors, Proceedings of The 27th International Conference on Artificial Intelligence and Statistics, volume 238 ofProceedings of Machine Learning Research, pages 4249–4257. PMLR, 02–04 ...
2024
-
[15]
Reinforcement learning with deep energy-based policies, 2017
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies, 2017. URLhttps://arxiv.org/abs/1702.08165
Pith/arXiv arXiv 2017
-
[16]
James Hazelden. Fast neural tangent kernel alignment, norm and effective rank via trace estimation.arXiv:2511.10796, 2025. doi: 10.48550/arXiv.2511.10796. URL https://www. arxiv.org/abs/2511.10796
-
[17]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021
2021
-
[18]
Does rlhf scale? exploring the impacts from data, model, and method, 2024
Zhenyu Hou, Pengfan Du, Yilin Niu, Zhengxiao Du, Aohan Zeng, Xiao Liu, Minlie Huang, Hongning Wang, Jie Tang, and Yuxiao Dong. Does rlhf scale? exploring the impacts from data, model, and method, 2024. URLhttps://arxiv.org/abs/2412.06000
arXiv 2024
-
[19]
Huggingfaceh4/aime_2024
Hugging Face H4. Huggingfaceh4/aime_2024. https://huggingface.co/datasets/ HuggingFaceH4/aime_2024, 2024. Accessed: 2026-01-16
2024
-
[20]
John Wiley & Sons, 1965
Leslie Kish.Survey Sampling. John Wiley & Sons, 1965
1965
-
[21]
Math-verify, 2026
Hynek Kydlí ˇcek and Hugging Face. Math-verify, 2026. URL https://github.com/ huggingface/Math-Verify. GitHub repository. Accessed 2026-01-16
2026
-
[22]
Scrpo: From errors to insights,
Lianrui Li, Dakuan Lu, Jiawei Shao, Chi Zhang, and Xuelong Li. Scrpo: From errors to insights,
-
[23]
URLhttps://arxiv.org/abs/2511.06065
-
[24]
Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023
Pith/arXiv arXiv 2023
-
[25]
Is your code generated by chatGPT really correct? rigorous evaluation of large language models for code generation
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatGPT really correct? rigorous evaluation of large language models for code generation. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https: //openreview.net/forum?id=1qvx610Cu7
2023
-
[26]
Lill- icrap, Tim Harley, David Silver, and Koray Kavukcuoglu
V olodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lill- icrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning, 2016. URLhttps://arxiv.org/abs/1602.01783
Pith/arXiv arXiv 2016
-
[27]
opencompass/aime2025
OpenCompass. opencompass/aime2025. https://huggingface.co/datasets/ opencompass/AIME2025, 2025. Accessed: 2026-01-16
2025
-
[28]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback,...
Pith/arXiv arXiv 2022
-
[29]
TRAK: Attributing model behavior at scale
Sung Min Park, Kristian Georgiev, Andrew Ilyas, Guillaume Leclerc, and Aleksander Madry. TRAK: Attributing model behavior at scale. InProceedings of the 40th International Conference on Machine Learning (ICML), volume 202 ofProceedings of Machine Learning Research,
-
[30]
URLhttps://proceedings.mlr.press/v202/park23c.html
-
[31]
Estimating training data influence by tracing gradient descent
Garima Pruthi, Frederick Liu, Satyen Kale, and Mukund Sundararajan. Estimating training data influence by tracing gradient descent. InAdvances in Neural Information Processing Systems (NeurIPS), 2020. URLhttps://arxiv.org/abs/2002.08484. 11
arXiv 2020
-
[32]
Steinmetz, and Eric Shea-Brown
Stefano Recanatesi, Serena Bradde, Vijay Balasubramanian, Nicholas A. Steinmetz, and Eric Shea-Brown. A scale-dependent measure of system dimensionality.Patterns, 3(8):100555, 2022. doi: 10.1016/j.patter.2022.100555. URL https://www.sciencedirect.com/science/ article/pii/S266638992200160X
-
[33]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark, 2023
2023
-
[34]
Approximating kl divergence
John Schulman. Approximating kl divergence. Blog post, 2016. URL http://joschu.net/ blog/kl-approx.html. Accessed 2026-01-16. Some secondary sources cite the post as 2020
2016
-
[35]
John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation, 2016. URL https: //arxiv.org/abs/1506.02438
Pith/arXiv arXiv 2016
-
[36]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. doi: 10.48550/arXiv. 1707.06347. URLhttps://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2017
-
[37]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/abs/ 2402.03300
Pith/arXiv arXiv 2024
-
[38]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Yu Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. doi: 10.48550/arXiv.2402.03300. URLhttps://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[39]
On entropy control in llm-rl algorithms, 2025
Han Shen. On entropy control in llm-rl algorithms, 2025. URL https://arxiv.org/abs/ 2509.03493
arXiv 2025
-
[40]
Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
Pith/arXiv arXiv 2024
-
[41]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. MIT Press, Cambridge, MA, 2 edition, 2018
2018
-
[42]
Qwen Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
-
[43]
Chaoqi Wang, Yibo Jiang, Chenghao Yang, Han Liu, and Yuxin Chen. Beyond reverse kl: Generalizing direct preference optimization with diverse divergence constraints, 2023. URL https://arxiv.org/abs/2309.16240
arXiv 2023
-
[44]
Zico Kolter
Yixuan Even Xu, Yash Savani, Fei Fang, and J. Zico Kolter. Not all rollouts are useful: Down- sampling rollouts in llm reinforcement learning, 2025. URL https://arxiv.org/abs/2504. 13818
2025
-
[45]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024
Pith/arXiv arXiv 2024
-
[46]
Yaning Yang, Elaine F. Remmers, Chukwuma B. Ogunwole, Daniel L. Kastner, Peter K. Gregersen, and Wentian Li. Effective sample size: Quick estimation of the effect of related samples in genetic case-control association analyses.arXiv: q-bio/0611093, 2006. URL https://arxiv.org/abs/q-bio/0611093
Pith/arXiv arXiv 2006
-
[47]
Diversity-aware policy optimization for large language model reasoning
Jian Yao, Ran Cheng, Xingyu Wu, Jibin Wu, and Kay Chen Tan. Diversity-aware policy optimization for large language model reasoning. InAdvances in Neural Information Process- ing Systems (NeurIPS), 2025. URL https://openreview.net/forum?id=5eZ0iykpDU. Spotlight. 12
2025
-
[48]
Gradient diversity: a key ingredient for scalable distributed learning
Dong Yin, Ashwin Pananjady, Max Lam, Dimitris Papailiopoulos, Kannan Ramchandran, and Peter Bartlett. Gradient diversity: a key ingredient for scalable distributed learning. In Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, volume 84 ofProceedings of Machine Learning Research, pages 1998–2007. PMLR, 201...
1998
-
[49]
Dapo: An open-source llm reinforcement learning system at scale, 2025
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
Pith/arXiv arXiv 2025
-
[50]
Gradient surgery for multi-task learning, 2020
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning, 2020. URL https://arxiv.org/abs/2001.06782
arXiv 2020
-
[51]
Edge-grpo: Entropy-driven grpo with guided error correction for advantage diversity, 2025
Xingjian Zhang, Siwei Wen, Wenjun Wu, and Lei Huang. Edge-grpo: Entropy-driven grpo with guided error correction for advantage diversity, 2025. URL https://arxiv.org/abs/2507. 21848
2025
-
[52]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. doi: 10.48550/arXiv.2507.18071. URL https://arxiv.org/abs/2507.18071
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.18071 2025
-
[53]
Zhestyatsky at SemEval-2021 task 2: ReLU over cosine similarity for BERT fine-tuning
Boris Zhestiankin and Maria Ponomareva. Zhestyatsky at SemEval-2021 task 2: ReLU over cosine similarity for BERT fine-tuning. In Alexis Palmer, Nathan Schneider, Natalie Schluter, Guy Emerson, Aurelie Herbelot, and Xiaodan Zhu, editors,Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021), pages 163–168, Online, August 2021....
-
[54]
Evolving language models without labels: Majority drives selection, novelty promotes variation, 2025
Yujun Zhou, Zhenwen Liang, Haolin Liu, Wenhao Yu, Kishan Panaganti, Linfeng Song, Dian Yu, Xiangliang Zhang, Haitao Mi, and Dong Yu. Evolving language models without labels: Majority drives selection, novelty promotes variation, 2025. URL https://arxiv.org/abs/ 2509.15194. 13 Appendix A Proof of the residual-gradient norm bound This appendix provides a de...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.