Gender Artifacts from Art History to Text-to-Image Generation
Pith reviewed 2026-06-28 02:14 UTC · model grok-4.3
The pith
Text-to-image models amplify gender patterns embedded in historical artistic styles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that gender representation shapes visual features across artistic styles, that these patterns are carried into text-to-image outputs by style keywords, and that generative models amplify the resulting gender artifacts beyond the levels observed in the historical sources.
What carries the argument
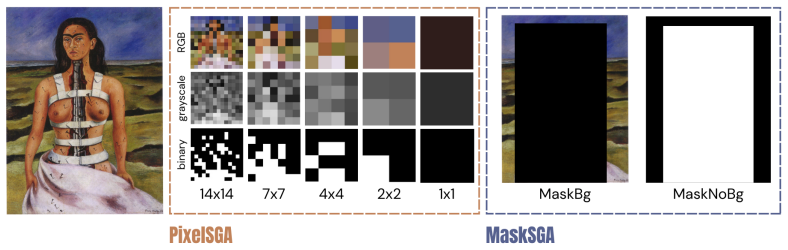
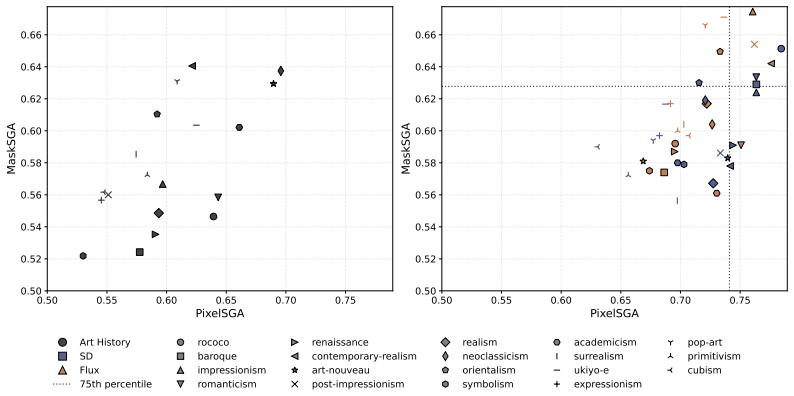
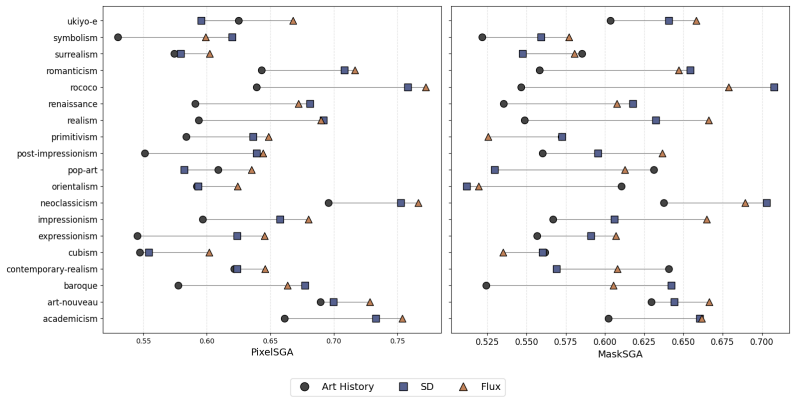
The StyleGender dataset together with the PixelSGA and MaskSGA metrics, which quantify gender signals respectively at the pixel level and through compositional masks while holding style and gender prompts constant.
If this is right
- Gender representation already influences measurable visual features inside each artistic style in the historical record.
- Style keywords alone are sufficient to reproduce and transmit those gender-linked visual patterns into generated images.
- The generative process increases the strength of gender artifacts relative to the historical baseline under the same style and gender specifications.
- Direct art-history-to-generation comparisons become possible once a semantically aligned image set is constructed.
Where Pith is reading between the lines
- If the amplification holds, then interventions that target only content prompts may leave residual bias carried by style descriptors.
- The same measurement approach could be applied to other social categories such as age or ethnicity to test whether amplification is specific to gender.
- Repeated use of historical style prompts in training or inference may create a feedback loop that further entrenches the amplified patterns.
- The dataset enables future work to test whether removing or reweighting particular style keywords reduces the observed amplification.
Load-bearing premise
The controlled style and gender prompts produce generated images whose only systematic difference from the historical set is the generative process itself.
What would settle it
A controlled experiment in which the same prompt set yields generated images whose measured gender signals match or fall below the historical baseline after accounting for any measurable differences in content distribution or annotation quality.
Figures










read the original abstract
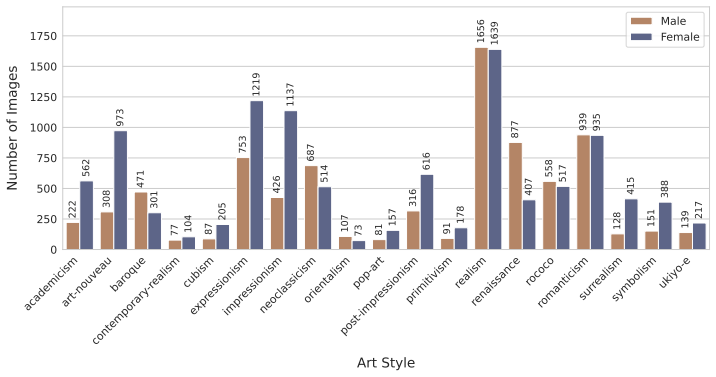
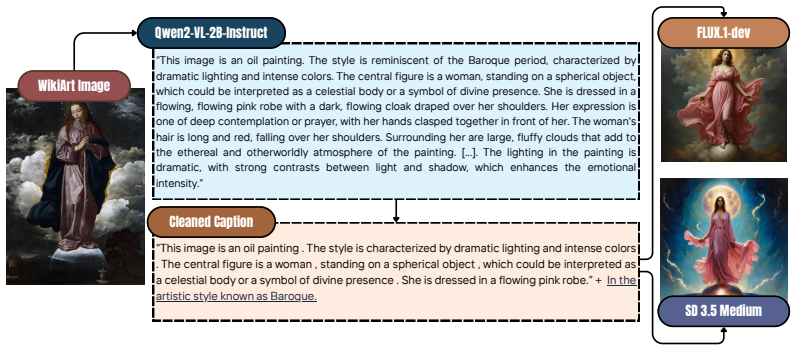
Artistic styles are rooted in specific socio-historical contexts that encode social hierarchies, including distinct constructions of gender. Yet in AI research, style has long been treated as a surface-level visual property: a filter of color, brushstroke, and texture applied to otherwise content-neutral scenes. We introduce the first dataset to investigate the interplay between gender representation and style in both historical and generated images. StyleGender comprises 74k images spanning 19 artistic styles, comprising art historical images with style and gender annotations, T2I-generated images under controlled style and gender prompts, and a semantically aligned set enabling direct art history-to-generation comparison. By proposing two Set Gender Artifact (SGA) metrics (PixelSGA and MaskSGA), capturing gender signals at the pixel level and in compositional structure, we show that (1) gender representation shapes visual features across artistic styles, (2) style keywords carry these patterns into T2I generation, and (3) generative models tend to amplify gender artifacts beyond what is observed in historical sources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the StyleGender dataset of 74k images across 19 artistic styles, consisting of annotated historical art images, T2I-generated images under controlled style+gender prompts, and a semantically aligned set for direct comparison. It defines PixelSGA and MaskSGA metrics to capture gender signals at pixel and compositional levels, and reports three findings: gender representation shapes visual features across styles, style keywords transmit these patterns into T2I outputs, and generative models amplify gender artifacts beyond historical baselines.
Significance. If the central comparison holds, the work supplies a large-scale resource and two quantitative metrics for measuring how socio-historical gender patterns in art are reproduced and intensified by text-to-image models. The dataset construction and the explicit historical-to-generated alignment are strengths that could support follow-on studies on bias propagation in generative vision systems.
major comments (2)
- [Dataset construction and abstract claim (3)] Abstract and § on dataset construction: the amplification claim (generated images exceed historical gender signals on PixelSGA/MaskSGA) requires that the only systematic difference between the historical set and the T2I set is the generative process. The semantically aligned set is built via prompt-based matching, but the manuscript reports no verification of content overlap (object categories, spatial layout, or embedding distances). Uncontrolled differences in how models render scenes or add elements could inflate SGA scores independently of amplification.
- [PixelSGA and MaskSGA definitions] Metrics section: no inter-annotator agreement, label validation, or statistical controls for prompt content are described for the gender annotations underlying PixelSGA and MaskSGA. Without these, the empirical comparisons rest on unexamined measurement assumptions and cannot reliably support the amplification result.
minor comments (1)
- [Abstract] The abstract states 74k images but does not break down the split between historical, generated, and aligned subsets; a table with exact counts per style would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below with clarifications on our methodology and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: Abstract and § on dataset construction: the amplification claim (generated images exceed historical gender signals on PixelSGA/MaskSGA) requires that the only systematic difference between the historical set and the T2I set is the generative process. The semantically aligned set is built via prompt-based matching, but the manuscript reports no verification of content overlap (object categories, spatial layout, or embedding distances). Uncontrolled differences in how models render scenes or add elements could inflate SGA scores independently of amplification.
Authors: We agree that explicit verification of semantic overlap would strengthen the isolation of generative effects. The aligned set was constructed by extracting style and gender descriptors from historical annotations to form matched prompts, with the goal of holding semantic content constant. In revision we will add quantitative alignment checks, including CLIP embedding cosine similarities between historical and generated pairs plus a sampled review of object categories and layouts, to confirm that SGA differences reflect amplification rather than content drift. revision: yes
-
Referee: Metrics section: no inter-annotator agreement, label validation, or statistical controls for prompt content are described for the gender annotations underlying PixelSGA and MaskSGA. Without these, the empirical comparisons rest on unexamined measurement assumptions and cannot reliably support the amplification result.
Authors: Gender labels on historical images followed standard art-historical visual criteria (e.g., attire, posture, facial features) applied by domain experts; generated-image labels derive directly from the controlled gender prompts. Inter-annotator agreement was not computed originally. We will expand the metrics section to detail the annotation protocol and prompt-template controls (fixed structure varying only style/gender tokens). Because IAA data were not collected, we cannot retroactively report it but will note this limitation and the reliance on established conventions. revision: partial
Circularity Check
No circularity in empirical dataset comparisons and metric definitions
full rationale
The paper introduces a new dataset (StyleGender) and two metrics (PixelSGA, MaskSGA) to perform direct empirical comparisons of gender signals between historical art images and T2I-generated images under controlled prompts. The central claim of amplification is obtained by computing these metrics on independent collections and observing higher values in the generated set; no equations, fitted parameters, or self-citations reduce this comparison to a tautology or to the inputs by construction. The construction of the semantically aligned set via prompts is a methodological step whose validity can be debated on external grounds, but it does not create a self-definitional or fitted-input loop within the reported results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gender labels assigned to images are stable and comparable across historical and generated domains
- domain assumption Style keywords in prompts isolate the transfer of gender artifacts without confounding changes in subject matter or composition
Reference graph
Works this paper leans on
-
[1]
Stable diffusion 3.5 medium
Stability AI. Stable diffusion 3.5 medium. https://huggingface.co/stabilityai/ stable-diffusion-3.5-medium, 2024. Accessed: 2026-05-06
2024
-
[2]
Hritik Bansal, Da Yin, Masoud Monajatipoor, and Kai-Wei Chang. How well can text-to-image generative models understand ethical natural language interventions? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 1358–1370, 2022
2022
-
[3]
Pinar Barlas, Kyriakos Kyriakou, Olivia Guest, Styliani Kleanthous, and Jahna Otterbacher. To" see" is to stereotype: Image tagging algorithms, gender recognition, and the accuracy-fairness trade-off.Proceedings of the ACM on Human-Computer Interaction, 4(CSCW3):1–31, 2021
2021
-
[4]
An anthropology of images: Picture, medium, body
Hans Belting. An anthropology of images: Picture, medium, body. 2022
2022
-
[5]
A comprehensive survey on object detection in visual art: taxonomy and challenge.Multimedia Tools and Applications, 83(5):14637–14670, 2024
Siwar Bengamra, Olfa Mzoughi, André Bigand, and Ezzeddine Zagrouba. A comprehensive survey on object detection in visual art: taxonomy and challenge.Multimedia Tools and Applications, 83(5):14637–14670, 2024
2024
-
[6]
Easily accessible text-to- image generation amplifies demographic stereotypes at large scale
Federico Bianchi, Pratyusha Kalluri, Esin Durmus, Faisal Ladhak, Myra Cheng, Debora Nozza, Tatsunori Hashimoto, Dan Jurafsky, James Zou, and Aylin Caliskan. Easily accessible text-to- image generation amplifies demographic stereotypes at large scale. InProceedings of the 2023 ACM conference on fairness, accountability, and transparency, pages 1493–1504, 2023
2023
-
[7]
Into the laion’s den: Investigating hate in multimodal datasets.Advances in neural information processing systems, 36:21268–21284, 2023
Abeba Birhane, Sanghyun Han, Vishnu Boddeti, Sasha Luccioni, et al. Into the laion’s den: Investigating hate in multimodal datasets.Advances in neural information processing systems, 36:21268–21284, 2023
2023
-
[8]
Large image datasets: A pyrrhic win for computer vision? In2021 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1536–1546
Abeba Birhane and Vinay Uday Prabhu. Large image datasets: A pyrrhic win for computer vision? In2021 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1536–1546. IEEE, 2021
2021
-
[9]
Multimodal datasets: misog- yny, pornography, and malignant stereotypes, 2021
Abeba Birhane, Vinay Uday Prabhu, and Emmanuel Kahembwe. Multimodal datasets: misog- yny, pornography, and malignant stereotypes, 2021
2021
-
[10]
Gender shades: Intersectional accuracy disparities in commercial gender classification
Joy Buolamwini and Timnit Gebru. Gender shades: Intersectional accuracy disparities in commercial gender classification. InConference on fairness, accountability and transparency, pages 77–91. PMLR, 2018
2018
-
[11]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergiy Zagoruyko. End-to-end object detection with transformers. InEuropean Conference on Computer Vision (ECCV), pages 213–229. Springer, 2020
2020
-
[12]
Controlstyle: Text-driven stylized image generation using diffusion priors
Jingwen Chen, Yingwei Pan, Ting Yao, and Tao Mei. Controlstyle: Text-driven stylized image generation using diffusion priors. InProceedings of the 31st ACM international conference on multimedia, pages 7540–7548, 2023
2023
-
[13]
Tibet: Identifying and evaluating biases in text-to-image generative models
Aditya Chinchure, Pushkar Shukla, Gaurav Bhatt, Kiri Salij, Kartik Hosanagar, Leonid Sigal, and Matthew Turk. Tibet: Identifying and evaluating biases in text-to-image generative models. InEuropean Conference on Computer Vision, pages 429–446. Springer, 2024
2024
-
[14]
Laurence King Publishing, 2004
Thomas E Crow.The rise of the sixties: American and European art in the era of dissent. Laurence King Publishing, 2004. 10
2004
-
[15]
Oasis uncovers: High-quality t2i models, same old stereotypes
Sepehr Dehdashtian, Gautam Sreekumar, and Vishnu Boddeti. Oasis uncovers: High-quality t2i models, same old stereotypes. InThe Thirteenth International Conference on Learning Representations
-
[16]
Aesthetics as structural harm: Algorithmic lookism across text-to-image generation and classification, 2026
Miriam Doh, Aditya Gulati, Corinna Canali, and Nuria Oliver. Aesthetics as structural harm: Algorithmic lookism across text-to-image generation and classification, 2026
2026
-
[17]
Position: The categorization of race in ml is a flawed premise
Miriam Doh, Benedikt Höltgen, Piera Riccio, and Nuria M Oliver. Position: The categorization of race in ml is a flawed premise. InForty-second International Conference on Machine Learning Position Paper Track, 2025
2025
-
[18]
Ahmed Elgammal, Bingchen Liu, Mohamed Elhoseiny, and Marian Mazzone. Can: Creative adversarial networks, generating" art" by learning about styles and deviating from style norms. arXiv preprint arXiv:1706.07068, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Cultural bias in text-to-image models: a systematic review of bias identification, evaluation and mitigation strategies.IEEE Access, 2025
Wala Elsharif, Mahmood Alzubaidi, and Marco Agus. Cultural bias in text-to-image models: a systematic review of bias identification, evaluation and mitigation strategies.IEEE Access, 2025
2025
-
[20]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[21]
Art nouveau: A universal style
Europeana. Art nouveau: A universal style. https://www.europeana.eu/en/ exhibitions/art-nouveau-a-universal-style, 2017. Last Access: 04.03.2026
2017
-
[22]
A survey on bias in visual datasets.Computer Vision and Image Understanding, 223:103552, 2022
Simone Fabbrizzi, Symeon Papadopoulos, Eirini Ntoutsi, and Ioannis Kompatsiaris. A survey on bias in visual datasets.Computer Vision and Image Understanding, 223:103552, 2022
2022
-
[23]
Fraser, Svetlana Kiritchenko, and Isar Nejadgholi
Kathleen C. Fraser, Svetlana Kiritchenko, and Isar Nejadgholi. A friendly face: Do text-to-image systems rely on stereotypes when the input is under-specified?, 2023
2023
-
[24]
Uncurated image-text datasets: Shedding light on demographic bias
Noa Garcia, Yusuke Hirota, Yankun Wu, and Yuta Nakashima. Uncurated image-text datasets: Shedding light on demographic bias. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6957–6966, 2023
2023
-
[25]
Harm amplification in text-to-image models
Susan Hao, Renee Shelby, Yuchi Liu, Hansa Srinivasan, Mukul Bhutani, Burcu Karagol Ayan, Ryan Poplin, Shivani Poddar, and Sarah Laszlo. Harm amplification in text-to-image models. arXiv preprint arXiv:2402.01787, 2024
-
[26]
Bias in gender bias benchmarks: How spurious features distort evaluation
Yusuke Hirota, Ryo Hachiuma, Boyi Li, Ximing Lu, Michael Ross Boone, Boris Ivanovic, Yejin Choi, Marco Pavone, Yu-Chiang Frank Wang, Noa Garcia, et al. Bias in gender bias benchmarks: How spurious features distort evaluation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8634–8644, 2025
2025
-
[27]
Quantifying societal bias amplification in image captioning
Yusuke Hirota, Yuta Nakashima, and Noa Garcia. Quantifying societal bias amplification in image captioning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13450–13459, 2022
2022
-
[28]
Midjourney.https://www.midjourney.com, 2022
David Holz. Midjourney.https://www.midjourney.com, 2022
2022
-
[29]
Neu- ral style transfer: A review.IEEE transactions on visualization and computer graphics, 26(11):3365–3385, 2019
Yongcheng Jing, Yezhou Yang, Zunlei Feng, Jingwen Ye, Yizhou Yu, and Mingli Song. Neu- ral style transfer: A review.IEEE transactions on visualization and computer graphics, 26(11):3365–3385, 2019
2019
-
[30]
Ultralytics YOLO, 2023
Glenn Jocher, Jing Qiu, and Ayush Chaurasia. Ultralytics YOLO, 2023
2023
-
[31]
Gender representations in Neoclassical art
Knowledge.Deck.no. Gender representations in Neoclassical art. https://knowledge.deck. no/art-and-literature/art-history/neoclassicism/gender-representations ,
-
[32]
Last Access: 04.03.2026
2026
-
[33]
Content and style disentanglement for artistic style transfer
Dmytro Kotovenko, Artsiom Sanakoyeu, Sabine Lang, and Bjorn Ommer. Content and style disentanglement for artistic style transfer. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2019. 11
2019
-
[34]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
2024
-
[35]
Flux.1-dev
Black Forest Labs. Flux.1-dev. https://huggingface.co/black-forest-labs/FLUX. 1-dev, 2024. Accessed: 2026-05-06
2024
-
[36]
Stable bias: Evaluat- ing societal representations in diffusion models.Advances in Neural Information Processing Systems, 36:56338–56351, 2023
Sasha Luccioni, Christopher Akiki, Margaret Mitchell, and Yacine Jernite. Stable bias: Evaluat- ing societal representations in diffusion models.Advances in Neural Information Processing Systems, 36:56338–56351, 2023
2023
-
[37]
Hanjun Luo, Haoyu Huang, Ziye Deng, Xinfeng Li, Hewei Wang, Yingbin Jin, Yang Liu, Wenyuan Xu, and Zuozhu Liu. Bigbench: A unified benchmark for evaluating multi-dimensional social biases in text-to-image models.arXiv preprint arXiv:2407.15240, 2024
-
[38]
Representing medieval genders and sexualities in europe: Construction, transformation, and subversion, 600–1530
Elizabeth L’Estrange and Alison More. Representing medieval genders and sexualities in europe: Construction, transformation, and subversion, 600–1530. InRepresenting Medieval Genders and Sexualities in Europe, pages 1–13. Routledge, 2016
2016
-
[39]
Abhishek Mandal, Susan Leavy, and Suzanne Little. Multimodal composite association score: Measuring gender bias in generative multimodal models.arXiv preprint arXiv:2304.13855, 2023
-
[40]
Analysing gender bias in text-to-image models using object detection
Harvey Mannering. Analysing gender bias in text-to-image models using object detection. arXiv preprint arXiv:2307.08025, 2023
-
[41]
Gender artifacts in visual datasets
Nicole Meister, Dora Zhao, Angelina Wang, Vikram V Ramaswamy, Ruth Fong, and Olga Russakovsky. Gender artifacts in visual datasets. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4837–4848, 2023
2023
-
[42]
Maria-Teresa De Rosa Palmini, Laura Wagner, and Eva Cetinic. Civiverse: A dataset for analyz- ing user engagement with open-source text-to-image models.arXiv preprint arXiv:2408.15261, 2024
-
[43]
Styleforge: Enhancing text-to- image synthesis for any artistic styles with dual binding.Applied Sciences, 15(19), 2025
Junseo Park, Beomseok Ko, Minji Kang, and Hyeryung Jang. Styleforge: Enhancing text-to- image synthesis for any artistic styles with dual binding.Applied Sciences, 15(19), 2025
2025
-
[44]
Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models
Yiting Qu, Xinyue Shen, Xinlei He, Michael Backes, Savvas Zannettou, and Yang Zhang. Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models. InProceedings of the 2023 ACM SIGSAC conference on computer and communications security, pages 3403–3417, 2023
2023
-
[45]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InInternational conference on machine learning, pages 8821–8831. Pmlr, 2021
2021
-
[46]
No annota- tions for object detection in art through stable diffusion
Patrick Ramos, Nicolas Gonthier, Selina Khan, Yuta Nakashima, and Noa Garcia. No annota- tions for object detection in art through stable diffusion. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 6228–6237. IEEE, 2025
2025
-
[47]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[48]
Brill, 2015
Marice E Rose and Alison C Poe.Receptions of antiquity, constructions of gender in European art, 1300-1600. Brill, 2015
2015
-
[49]
Ludovica Schaerf, Andrea Alfarano, Fabrizio Silvestri, and Leonardo Impett. Training-free style and content transfer by leveraging u-net skip connections in stable diffusion.arXiv preprint arXiv:2501.14524, 2025
-
[50]
Theory and philosophy of art: Style, artist, and society
Meyer Schapiro. Theory and philosophy of art: Style, artist, and society. 1994
1994
-
[51]
Smiling women pitching down: auditing representational and presentational gender biases in image-generative ai.Journal of Computer-Mediated Communication, 29(1):zmad045, 2024
Luhang Sun, Mian Wei, Yibing Sun, Yoo Ji Suh, Liwei Shen, and Sijia Yang. Smiling women pitching down: auditing representational and presentational gender biases in image-generative ai.Journal of Computer-Mediated Communication, 29(1):zmad045, 2024. 12
2024
-
[52]
PhD thesis, 2016
Laura Elizabeth Thiel.The Gentleman-Scholar at Home: Domesticity, Masculinity, and Civility in Dutch Seventeenth-Century Genre Painting. PhD thesis, 2016
2016
-
[53]
How many pixels make an image?Visual neuroscience, 26(1):123–131, 2009
Antonio Torralba. How many pixels make an image?Visual neuroscience, 26(1):123–131, 2009
2009
-
[54]
Unbiased look at dataset bias
Antonio Torralba and Alexei A Efros. Unbiased look at dataset bias. InCVPR 2011, pages 1521–1528. IEEE, 2011
2011
-
[55]
Stereotypes and smut: The (mis) representa- tion of non-cisgender identities by text-to-image models
Eddie Ungless, Björn Ross, and Anne Lauscher. Stereotypes and smut: The (mis) representa- tion of non-cisgender identities by text-to-image models. InFindings of the Association for Computational Linguistics: ACL 2023, pages 7919–7942, 2023
2023
-
[56]
Yixin Wan, Arjun Subramonian, Anaelia Ovalle, Zongyu Lin, Ashima Suvarna, Christina Chance, Hritik Bansal, Rebecca Pattichis, and Kai-Wei Chang. Survey of bias in text-to-image generation: Definition, evaluation, and mitigation.arXiv preprint arXiv:2404.01030, 2024
-
[57]
T2iat: Measuring valence and stereotypical biases in text-to-image generation
Jialu Wang, Xinyue Liu, Zonglin Di, Yang Liu, and Xin Wang. T2iat: Measuring valence and stereotypical biases in text-to-image generation. InFindings of the Association for Computa- tional Linguistics: ACL 2023, pages 2560–2574, 2023
2023
-
[58]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
New job, new gender? measuring the social bias in image generation models
Wenxuan Wang, Haonan Bai, Jen-tse Huang, Yuxuan Wan, Youliang Yuan, Haoyi Qiu, Nanyun Peng, and Michael Lyu. New job, new gender? measuring the social bias in image generation models. InProceedings of the 32nd ACM International Conference on Multimedia, pages 3781–3789, 2024
2024
-
[60]
Zijie J Wang, Evan Montoya, David Munechika, Haoyang Yang, Benjamin Hoover, and Duen Horng Chau. Diffusiondb: A large-scale prompt gallery dataset for text-to-image genera- tive models.arXiv preprint arXiv:2210.14896, 2022
-
[61]
Beyond the universal art dataset: Issues and mitigations of western bias in computational art analysis
Amanda Wasielewski. Beyond the universal art dataset: Issues and mitigations of western bias in computational art analysis. InProceedings of the ECCV 2022 Workshop on Computer VISion on ART analysis, number 4, pages 1–6, 2022
2022
-
[62]
The reification of style in ai image generation
Amanda Wasielewski. The reification of style in ai image generation. 2024
2024
-
[63]
Bias amplification in stable diffusion’s representation of stigma through skin tones and their homogeneity
Kyra Wilson, Sourojit Ghosh, and Aylin Caliskan. Bias amplification in stable diffusion’s representation of stigma through skin tones and their homogeneity. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 8, pages 2705–2717, 2025
2025
-
[64]
Artfid: Quantitative evaluation of neural style transfer
Matthias Wright and Björn Ommer. Artfid: Quantitative evaluation of neural style transfer. In DAGM German Conference on Pattern Recognition, pages 560–576. Springer, 2022
2022
-
[65]
Goya: leveraging generative art for content-style disentanglement.Journal of Imaging, 10(7):156, 2024
Yankun Wu, Yuta Nakashima, and Noa Garcia. Goya: leveraging generative art for content-style disentanglement.Journal of Imaging, 10(7):156, 2024
2024
-
[66]
Stable diffusion exposed: Gender bias from prompt to image
Yankun Wu, Yuta Nakashima, and Noa Garcia. Stable diffusion exposed: Gender bias from prompt to image. InProceedings of the AAAI/ACM conference on AI, ethics, and society, volume 7, pages 1648–1659, 2024
2024
-
[67]
Towards fairer datasets: Filtering and balancing the distribution of the people subtree in the imagenet hierarchy
Kaiyu Yang, Klint Qinami, Li Fei-Fei, Jia Deng, and Olga Russakovsky. Towards fairer datasets: Filtering and balancing the distribution of the people subtree in the imagenet hierarchy. InProceedings of the 2020 conference on fairness, accountability, and transparency, pages 547–558, 2020
2020
-
[68]
Enhancing fairness in face detection in computer vision systems by demographic bias mitigation
Yu Yang, Aayush Gupta, Jianwei Feng, Prateek Singhal, Vivek Yadav, Yue Wu, Pradeep Natara- jan, Varsha Hedau, and Jungseock Joo. Enhancing fairness in face detection in computer vision systems by demographic bias mitigation. InProceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society, pages 813–822, 2022. 13
2022
-
[69]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[70]
Iti-gen: Inclusive text-to-image generation
Cheng Zhang, Xuanbai Chen, Siqi Chai, Chen Henry Wu, Dmitry Lagun, Thabo Beeler, and Fernando De la Torre. Iti-gen: Inclusive text-to-image generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3969–3980, 2023
2023
-
[71]
Dino: Detr with improved denoising anchor boxes for end-to-end object detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. In The Eleventh International Conference on Learning Representations, 2023
2023
-
[72]
Bias in generative ai, 2024
Mi Zhou, Vibhanshu Abhishek, Timothy Derdenger, Jaymo Kim, and Kannan Srinivasan. Bias in generative ai, 2024
2024
-
[73]
A painting of 〈gender〉, 〈viewpoint〉, 〈pose〉[〈modifier〉], in the artistic style known as〈style〉
Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. InProceedings of the IEEE international conference on computer vision, pages 2223–2232, 2017. 14 A The STYLEGENDERDataset In this section we provide additional information on how the dataset STYLEGENDERis construct...
2017
-
[74]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.