Agentic Molecular Recovery via Molecule-Aware Exploration
Pith reviewed 2026-06-28 01:52 UTC · model grok-4.3
The pith
Molecule-aware exploration restores invalid SMILES while preserving molecular identity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
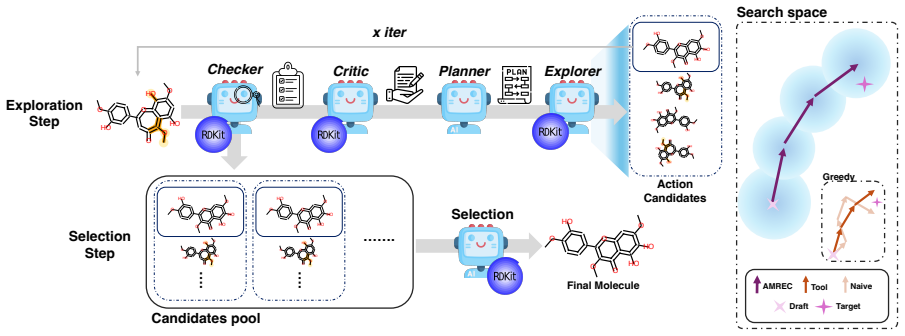
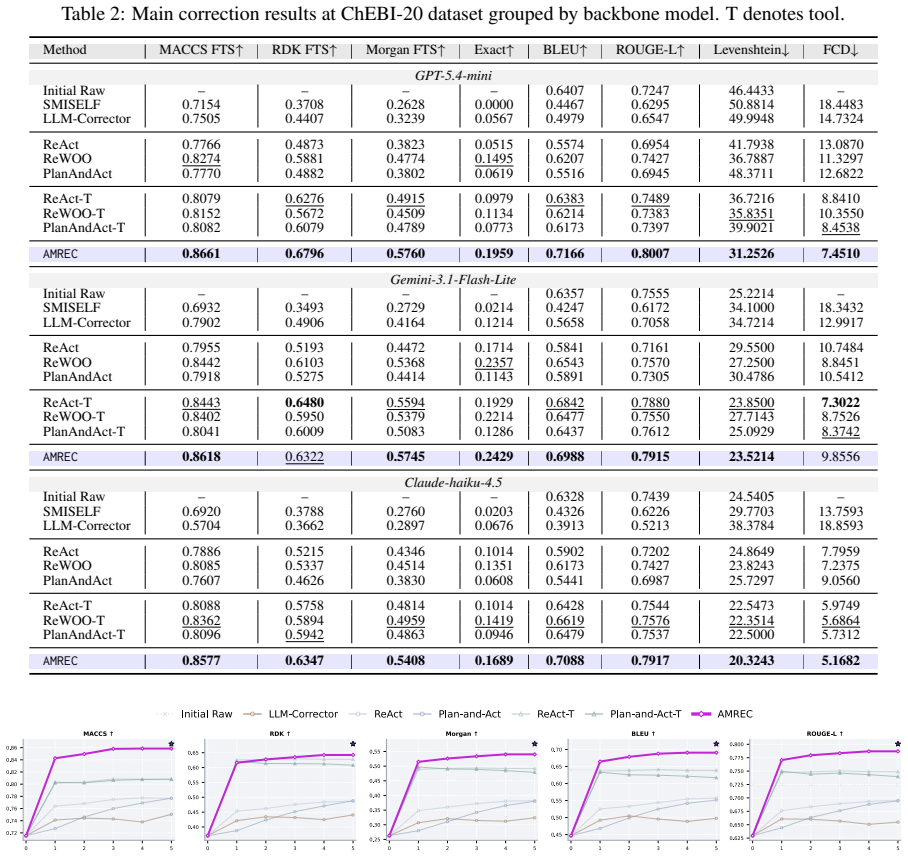
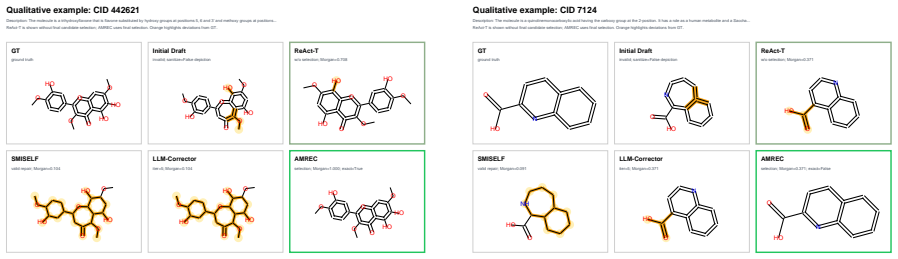
AMREC couples molecule-aware mismatch tracking with expanded candidate exploration and trajectory-level selection to achieve identity-preserving recovery of molecules from invalid SMILES drafts, outperforming validity-oriented repair and generic agentic correction on ChEBI-20 data from multiple backbone models.
What carries the argument
Molecule-aware mismatch tracking with expanded candidate exploration and trajectory-level selection in AMREC, which follows structural differences specific to each molecule and chooses among full correction paths.
If this is right
- Recovered molecules retain target-relevant structural cues more reliably than post-hoc or LLM-only repairs.
- Exact-match rates to the molecular identity implied by the description increase.
- String-level similarity between recovered and target SMILES improves across the board.
- The method overcomes the constraint of greedy single-candidate trajectories even when using executable edit tools.
Where Pith is reading between the lines
- The mismatch-tracking idea could transfer to identity preservation tasks in other generative domains such as code or sequence design.
- Combining the approach with additional backbone models might reveal whether the gains hold beyond the three tested here.
- Trajectory-level selection could reduce reliance on repeated model calls by making exploration more efficient.
Load-bearing premise
The chosen structural, exact-match, and string-level metrics faithfully measure preservation of target-relevant structural cues and molecular identity without post-hoc selection effects or metric gaming.
What would settle it
A side-by-side evaluation in which recovered molecules from AMREC and baselines are tested for actual chemical or biological activity matching the original text description, rather than relying solely on the reported metrics.
Figures

read the original abstract
Text-guided molecular generation with LLMs often yields invalid SMILES. We argue that invalid drafts should be addressed through a shift from validity-oriented repair to identity-preserving molecular recovery: the objective is not only to restore chemical validity, but also to preserve target-relevant structural cues and recover the molecular identity implied by the description. This perspective reveals the limitations of existing correction strategies. Post-hoc repair can recover validity while distorting key structures, LLM-only correction can introduce unintended global drift, and generic agentic correction remains constrained by greedy single-candidate trajectories even when equipped with executable RDKit edit tools. To address these limitations, we propose AMREC, which couples molecule-aware mismatch tracking with expanded candidate exploration and trajectory-level selection. On invalid ChEBI-20 drafts from three backbone models, AMREC achieves the strongest overall recovery profile across structural, exact-match, and string-level metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AMREC, an agentic framework for identity-preserving molecular recovery from invalid SMILES drafts produced by LLMs in text-guided generation tasks. It critiques post-hoc repair, LLM-only correction, and generic agentic methods, instead introducing molecule-aware mismatch tracking, expanded candidate exploration, and trajectory-level selection. The central claim is that AMREC delivers the strongest recovery profile on structural, exact-match, and string-level metrics when tested on invalid ChEBI-20 drafts generated by three backbone models.
Significance. If the empirical results can be substantiated with full experimental details and validation that the metrics track chemical identity, the work could usefully shift focus in LLM-based molecular generation from validity repair to identity preservation, with potential downstream benefits for reliable text-to-molecule pipelines in chemistry.
major comments (2)
- [Abstract] Abstract: The statement that AMREC 'achieves the strongest overall recovery profile across structural, exact-match, and string-level metrics' is presented without error bars, statistical significance tests, dataset details (e.g., split sizes, exclusion criteria), or baseline implementation specifics, so the central empirical claim cannot be evaluated.
- [Results] Results section (or equivalent empirical evaluation): The chosen structural, exact-match, and string-level metrics are used to support the 'identity-preserving' framing, yet no auxiliary validation (e.g., Tanimoto similarity on Morgan fingerprints against ground-truth molecules or property matching on logP/MW) is reported to confirm that metric gains reflect preservation of target-relevant chemical identity rather than superficial edits.
minor comments (1)
- [Methods] Clarify the precise definitions and computation of the structural, exact-match, and string-level metrics in the methods section to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that AMREC 'achieves the strongest overall recovery profile across structural, exact-match, and string-level metrics' is presented without error bars, statistical significance tests, dataset details (e.g., split sizes, exclusion criteria), or baseline implementation specifics, so the central empirical claim cannot be evaluated.
Authors: We agree that the abstract claim requires supporting context for proper evaluation. In the revised manuscript we will add a concise 'Experimental Setup' paragraph in the Results section that reports error bars on all metrics, notes any statistical significance tests performed, specifies ChEBI-20 split sizes and exclusion criteria, and details baseline implementations. The abstract will be lightly revised to qualify the claim and point readers to these details. revision: yes
-
Referee: [Results] Results section (or equivalent empirical evaluation): The chosen structural, exact-match, and string-level metrics are used to support the 'identity-preserving' framing, yet no auxiliary validation (e.g., Tanimoto similarity on Morgan fingerprints against ground-truth molecules or property matching on logP/MW) is reported to confirm that metric gains reflect preservation of target-relevant chemical identity rather than superficial edits.
Authors: We accept this observation. Although the primary metrics directly quantify recovery of the target structure, auxiliary chemical validations would provide stronger support for the identity-preserving interpretation. In the revision we will add Tanimoto similarity (Morgan fingerprints) and property-matching results (logP, MW) comparing recovered molecules to ground-truth targets, presenting them alongside the existing metrics and discussing their implications. revision: yes
Circularity Check
No significant circularity; empirical comparison is self-contained
full rationale
The paper presents an empirical method (AMREC) for molecular recovery and reports performance on structural, exact-match, and string-level metrics across backbone models on ChEBI-20. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the provided text. The central claim reduces to comparative results on chosen metrics rather than any derivation that collapses to its own definitions or prior author work by construction. This is the expected non-finding for a purely empirical agentic-systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Text2mol: Cross-modal molecule retrieval with natural language queries , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[2]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Translation between molecules and natural language , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[3]
IEEE transactions on knowledge and data engineering , volume=
Empowering molecule discovery for molecule-caption translation with large language models: A chatgpt perspective , author=. IEEE transactions on knowledge and data engineering , volume=. 2024 , publisher=
2024
-
[4]
Current Opinion in Structural Biology , volume=
Chemical language models for de novo drug design: Challenges and opportunities , author=. Current Opinion in Structural Biology , volume=. 2023 , publisher=
2023
-
[5]
Nature machine intelligence , volume=
Augmenting large language models with chemistry tools , author=. Nature machine intelligence , volume=. 2024 , publisher=
2024
-
[6]
Nature Machine Intelligence , volume=
Invalid SMILES are beneficial rather than detrimental to chemical language models , author=. Nature Machine Intelligence , volume=. 2024 , publisher=
2024
-
[7]
Machine Learning: Science and Technology , volume=
Self-referencing embedded strings (SELFIES): A 100\ author=. Machine Learning: Science and Technology , volume=. 2020 , publisher=
2020
-
[8]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
How to Make Large Language Models Generate 100\ author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[9]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models
Rewoo: Decoupling reasoning from observations for efficient augmented language models , author=. arXiv preprint arXiv:2305.18323 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks
Plan-and-act: Improving planning of agents for long-horizon tasks , author=. arXiv preprint arXiv:2503.09572 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
2013 , howpublished=
RDKit: Open-source cheminformatics , author=. 2013 , howpublished=
2013
-
[13]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Molxpt: Wrapping molecules with text for generative pre-training , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Text-guided molecule generation with diffusion language model , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[15]
Nature Machine Intelligence , volume=
Multi-modal molecule structure--text model for text-based retrieval and editing , author=. Nature Machine Intelligence , volume=. 2023 , publisher=
2023
-
[16]
SMILES, a chemical language and information system. 1. Introduction to methodology and encoding rules , author=. Journal of chemical information and computer sciences , volume=. 1988 , publisher=
1988
-
[17]
2018 , publisher=
DeepSMILES: an adaptation of SMILES for use in machine-learning of chemical structures , author=. 2018 , publisher=
2018
-
[18]
International conference on machine learning , pages=
Grammar variational autoencoder , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[19]
Syntax-Directed Variational Autoencoder for Structured Data
Syntax-directed variational autoencoder for structured data , author=. arXiv preprint arXiv:1802.08786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Digital Discovery , volume=
Group SELFIES: a robust fragment-based molecular string representation , author=. Digital Discovery , volume=. 2023 , publisher=
2023
-
[21]
Journal of Cheminformatics , volume=
UnCorrupt SMILES: a novel approach to de novo design , author=. Journal of Cheminformatics , volume=. 2023 , publisher=
2023
-
[22]
Nature , volume=
Autonomous chemical research with large language models , author=. Nature , volume=. 2023 , publisher=
2023
-
[23]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Tooling or not tooling? the impact of tools on language agents for chemistry problem solving , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[24]
arXiv preprint arXiv:2410.03963 , year=
dziner: Rational inverse design of materials with ai agents , author=. arXiv preprint arXiv:2410.03963 , year=
-
[25]
Journal of cheminformatics , volume=
Why is Tanimoto index an appropriate choice for fingerprint-based similarity calculations? , author=. Journal of cheminformatics , volume=. 2015 , publisher=
2015
-
[26]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[27]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[28]
Soviet physics doklady , volume=
Binary codes capable of correcting deletions, insertions, and reversals , author=. Soviet physics doklady , volume=. 1966 , organization=
1966
-
[29]
Preuer, Kristina and Renz, Philipp and Unterthiner, Thomas and Hochreiter, Sepp and Klambauer, Gunter , journal=. Fr. 2018 , publisher=
2018
-
[30]
ToolMol: Evolutionary Agentic Framework for Multi-objective Drug Discovery
ToolMol: Evolutionary Agentic Framework for Multi-objective Drug Discovery , author=. arXiv preprint arXiv:2605.12784 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Nature Machine Intelligence , volume=
A quantitative analysis of knowledge-learning preferences in large language models in molecular science , author=. Nature Machine Intelligence , volume=. 2025 , publisher=
2025
-
[32]
Journal of chemical information and computer sciences , volume=
Reoptimization of MDL keys for use in drug discovery , author=. Journal of chemical information and computer sciences , volume=. 2002 , publisher=
2002
-
[33]
Journal of chemical information and modeling , volume=
Get Your Atoms in Order--- An Open-Source Implementation of a Novel and Robust Molecular Canonicalization Algorithm , author=. Journal of chemical information and modeling , volume=. 2015 , publisher=
2015
-
[34]
Journal of chemical information and modeling , volume=
Extended-connectivity fingerprints , author=. Journal of chemical information and modeling , volume=. 2010 , publisher=
2010
-
[35]
Chemical science , volume=
Large-scale comparison of machine learning methods for drug target prediction on ChEMBL , author=. Chemical science , volume=. 2018 , publisher=
2018
-
[36]
Advances in neural information processing systems , volume=
What can large language models do in chemistry? a comprehensive benchmark on eight tasks , author=. Advances in neural information processing systems , volume=
-
[37]
IEEE Transactions on Knowledge and Data Engineering , year=
Large language models are in-context molecule learners , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[38]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Biot5: Enriching cross-modal integration in biology with chemical knowledge and natural language associations , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[39]
arXiv preprint arXiv:2410.13147 , year=
AgentDrug: Utilizing Large Language Models in An Agentic Workflow for Zero-Shot Molecular Optimization , author=. arXiv preprint arXiv:2410.13147 , year=
-
[40]
2009 , publisher=
The probabilistic relevance framework: BM25 and beyond , author=. 2009 , publisher=
2009
-
[41]
2024 , eprint=
Text-guided Diffusion Model for 3D Molecule Generation , author=. 2024 , eprint=
2024
-
[42]
3D-MolT5: Leveraging Discrete Structural Information for Molecule-Text Modeling , author=
-
[43]
ArXiv , year=
Junction Tree Variational Autoencoder for Molecular Graph Generation , author=. ArXiv , year=
-
[44]
International Conference on Machine Learning , year=
GraphRNN: Generating Realistic Graphs with Deep Auto-regressive Models , author=. International Conference on Machine Learning , year=
-
[45]
Scientific Reports , year=
Optimization of Molecules via Deep Reinforcement Learning , author=. Scientific Reports , year=
-
[46]
ArXiv , year=
Hierarchical Generation of Molecular Graphs using Structural Motifs , author=. ArXiv , year=
-
[47]
ArXiv , year=
GraphAF: a Flow-based Autoregressive Model for Molecular Graph Generation , author=. ArXiv , year=
-
[48]
Nature Machine Intelligence , year=
Leveraging language model for advanced multiproperty molecular optimization via prompt engineering , author=. Nature Machine Intelligence , year=
-
[49]
ArXiv , year=
MT-Mol:Multi Agent System with Tool-based Reasoning for Molecular Optimization , author=. ArXiv , year=
-
[50]
ArXiv , year=
ChemAgent: Self-updating Library in Large Language Models Improves Chemical Reasoning , author=. ArXiv , year=
-
[51]
Briefings in Bioinformatics , year=
DrugAssist: a large language model for molecule optimization , author=. Briefings in Bioinformatics , year=
-
[52]
ArXiv , year=
LICO: Large Language Models for In-Context Molecular Optimization , author=. ArXiv , year=
-
[53]
ReMol: LLM-guided Molecular Optimization with Reinforcement Learning , author=
-
[54]
Neural Information Processing Systems , year=
Graph Convolutional Policy Network for Goal-Directed Molecular Graph Generation , author=. Neural Information Processing Systems , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.