EMBER: Efficient Memory via Budgeted Evidence Retention for Long-Horizon Agents
Pith reviewed 2026-06-28 01:19 UTC · model grok-4.3
The pith
A learned retention policy preserves answer-relevant evidence under a fixed token budget, raising F1 from 0.1765 to 0.3017 on long-horizon tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EMBER stores evidence capsules consisting of verbatim source excerpts paired with retrieval keys and update metadata. A learned writer policy, trained with post-query feedback, selects what to retain under a token budget. This allows the system to maintain a compact, source-backed state that supports better answer recovery than baselines that either reread more history or use weaker retention.
What carries the argument
Evidence capsules: verbatim source excerpts paired with retrieval keys and update metadata, preserving grounding and read-time access.
If this is right
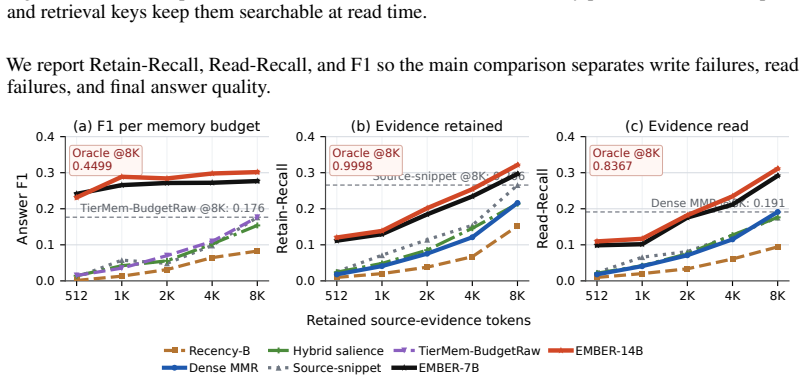
- EMBER reaches 0.3017 F1 at the 8192-token comparison point versus 0.1765 for the strongest non-EMBER budgeted baseline.
- The approach improves F1, Retain-Recall, and Read-Recall across a range of retained source-evidence budgets.
- Long-horizon memory performance depends on retaining evidence within the budget rather than on rereading larger portions of the raw history.
Where Pith is reading between the lines
- The same budgeted retention idea could be tested in non-language sequential tasks that also face history-length limits.
- Different forms of outcome feedback, beyond the current post-query signal, might further improve what the writer keeps.
- The capsule format might allow direct inspection or editing of retained memory in deployed agents.
Load-bearing premise
Post-query outcome feedback can train the writer policy to preserve answer-relevant evidence across the full ingestion-retrieval-answer chain when the system has no access to the raw history at read time.
What would settle it
An experiment in which EMBER-14B F1 at the 8192-token retained-evidence point on LongMemEval-RR falls to or below 0.1765 would falsify the reported performance advantage.
Figures


read the original abstract
Long-horizon agents can archive large histories, but future answers still incur retrieval, rereading, and context costs. When retained memory misses answer-relevant evidence, the system must return to larger portions of the raw history. We study budgeted evidence survival: before the query is known, which source evidence should be retained so that it remains recoverable and usable under a fixed retained source-evidence token budget? We instantiate this setting as Budgeted Pre-Query Retention, where memory is written during ingestion and later read without access to the full raw stream. We introduce EMBER, a learned retention policy that constructs a compact, source-backed evidence state. EMBER stores evidence capsules: verbatim source excerpts paired with retrieval keys and update metadata, preserving both grounding and read-time access. Post-query outcome feedback trains the writer to preserve evidence across the ingestion-retrieval-answer chain. On LongMemEval-RR, our LongMemEval-derived retained-evidence protocol, EMBER-14B reaches 0.3017 F1 at the 8192-token retained-evidence comparison point, compared with 0.1765 for the strongest non-EMBER budgeted baseline. Across retained source-evidence budgets, EMBER improves F1, Retain-Recall, and Read-Recall, indicating that long-horizon memory depends on retaining evidence within the budget rather than rereading larger histories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EMBER, a learned retention policy for budgeted pre-query evidence retention in long-horizon agents. It constructs evidence capsules (verbatim source excerpts paired with retrieval keys and update metadata) and trains the writer policy via post-query outcome feedback to preserve answer-relevant evidence under a fixed retained source-evidence token budget. On the derived LongMemEval-RR benchmark, EMBER-14B reports 0.3017 F1 at the 8192-token comparison point versus 0.1765 for the strongest non-EMBER budgeted baseline, with gains also in Retain-Recall and Read-Recall.
Significance. If the reported F1 gains prove robust and reproducible, the work would provide a concrete demonstration that a learned pre-query retention policy can outperform generic budgeted baselines by focusing retention on recoverable, source-grounded evidence rather than raw history rereading. The fixed-token-budget framing makes the efficiency claim directly testable and relevant to practical agent memory design.
major comments (3)
- [Evaluation] Evaluation section: the manuscript provides no details on the training procedure for the writer policy, data splits used for LongMemEval-RR, number of runs, or statistical significance testing of the 0.3017 vs. 0.1765 F1 difference. These omissions are load-bearing because the central empirical claim rests on the superiority of the learned retention policy.
- [Benchmark] Benchmark construction: LongMemEval-RR is described as a 'LongMemEval-derived retained-evidence protocol' whose construction is not inspectable in the manuscript; no verification is supplied that the protocol avoids leakage between ingestion and query phases. This directly affects the validity of the reported F1, Retain-Recall, and Read-Recall improvements.
- [§4] §4 (method): the post-query feedback loop that trains the writer to preserve evidence across the full ingestion-retrieval-answer chain is stated at a high level but lacks the concrete reward formulation, policy architecture, or optimization details needed to assess whether the reported gains follow from the claimed mechanism rather than from unstated implementation choices.
minor comments (2)
- [Abstract] The abstract and method sections use the term 'evidence capsules' without an early formal definition or diagram; a concise definition box or figure would improve readability.
- [Results] Table or figure presenting the 8192-token point should include error bars or run counts to contextualize the 0.3017 F1 value.
Simulated Author's Rebuttal
We thank the referee for the thorough review and constructive comments on EMBER. We agree that additional details are needed for reproducibility and will revise the manuscript to address each point. Below we respond to the major comments.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the manuscript provides no details on the training procedure for the writer policy, data splits used for LongMemEval-RR, number of runs, or statistical significance testing of the 0.3017 vs. 0.1765 F1 difference. These omissions are load-bearing because the central empirical claim rests on the superiority of the learned retention policy.
Authors: We agree these details are necessary to substantiate the central claim. In the revision we will add a dedicated subsection in the evaluation describing the writer policy training procedure (including reward formulation and optimization), the exact data splits and construction protocol for LongMemEval-RR, the number of independent runs, and statistical significance tests (e.g., paired t-tests or bootstrap) on the F1, Retain-Recall, and Read-Recall differences. revision: yes
-
Referee: [Benchmark] Benchmark construction: LongMemEval-RR is described as a 'LongMemEval-derived retained-evidence protocol' whose construction is not inspectable in the manuscript; no verification is supplied that the protocol avoids leakage between ingestion and query phases. This directly affects the validity of the reported F1, Retain-Recall, and Read-Recall improvements.
Authors: We acknowledge the need for full inspectability. The revision will include an expanded benchmark section with the complete step-by-step construction protocol for LongMemEval-RR, explicit checks for temporal separation between ingestion and query phases, and verification steps confirming no leakage of query-relevant evidence into the retained-evidence state. revision: yes
-
Referee: [§4] §4 (method): the post-query feedback loop that trains the writer to preserve evidence across the full ingestion-retrieval-answer chain is stated at a high level but lacks the concrete reward formulation, policy architecture, or optimization details needed to assess whether the reported gains follow from the claimed mechanism rather than from unstated implementation choices.
Authors: We will expand §4 with the precise reward function (outcome-based post-query feedback), the policy network architecture (including input/output formats for evidence capsules), and the optimization algorithm and hyperparameters. This will allow readers to verify that performance gains derive from the budgeted retention mechanism. revision: yes
Circularity Check
No significant circularity; empirical benchmark comparison only
full rationale
The paper describes an empirical system (EMBER) that trains a retention policy via post-query outcome feedback and reports F1/Recall gains on the LongMemEval-RR benchmark against external baselines at fixed token budgets. No equations, derivations, uniqueness theorems, or self-citations are invoked as load-bearing steps in the provided abstract or high-level description. The central claim reduces to measured performance differences rather than any reduction of outputs to fitted inputs or self-referential definitions by construction. The result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Memory is written during ingestion and later read without access to the full raw stream.
invented entities (1)
-
evidence capsules
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttps://openreview.net/forum?id=k5nIOvYGCL. Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z. Pan, Hinrich Schütze, V olker Tresp, and Yunpu Ma. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning. arXiv preprint arXiv:2508.19828,
-
[2]
Mem- α: Learning memory construction via reinforcement learning.arXiv preprint arXiv:2509.25911,
Yu Wang, Ryuichi Takanobu, Zhiqi Liang, Yuzhen Mao, Yuanzhe Hu, Julian McAuley, and Xiao- jian Wu. Mem- α: Learning memory construction via reinforcement learning.arXiv preprint arXiv:2509.25911,
-
[4]
URLhttps://arxiv.org/abs/2412.15115
doi: 10.48550/ arXiv.2412.15115. URLhttps://arxiv.org/abs/2412.15115. Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models? InConference on Language Modeling,
-
[5]
Document expansion by query prediction.arXiv preprint arXiv:1904.08375,
Rodrigo Nogueira, Wei Yang, Jimmy Lin, and Kyunghyun Cho. Document expansion by query prediction.arXiv preprint arXiv:1904.08375,
arXiv 1904
-
[6]
Memorybank: Enhancing large language models with long-term memory.arXiv preprint arXiv:2305.10250,
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory.arXiv preprint arXiv:2305.10250,
-
[7]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems.arXiv preprint arXiv:2310.08560,
-
[8]
Augmenting language models with long-term memory.arXiv preprint arXiv:2306.07174,
Weizhi Wang, Li Dong, Hao Cheng, Xiaodong Liu, Xifeng Yan, Jianfeng Gao, and Furu Wei. Augmenting language models with long-term memory.arXiv preprint arXiv:2306.07174,
-
[9]
Memoryllm: Towards self-updatable large language models.arXiv preprint arXiv:2402.04624,
Yu Wang, Yifan Gao, Xiusi Chen, Haoming Jiang, Shiyang Li, Jingfeng Yang, Qingyu Yin, Zheng Li, Xian Li, Bing Yin, Jingbo Shang, and Julian McAuley. Memoryllm: Towards self-updatable large language models.arXiv preprint arXiv:2402.04624,
-
[10]
10 Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413,
-
[11]
Petr Anokhin, Nikita Semenov, Artyom Sorokin, Dmitry Evseev, Andrey Kravchenko, Mikhail Burtsev, and Evgeny Burnaev. Arigraph: Learning knowledge graph world models with episodic memory for llm agents.arXiv preprint arXiv:2407.04363,
-
[12]
A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110,
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110,
-
[14]
Yaorui Shi, Yuxin Chen, Siyuan Wang, Sihang Li, Hengxing Cai, Qi Gu, Xiang Wang, and An Zhang
URL https://arxiv.org/abs/2601.08323. Yaorui Shi, Yuxin Chen, Siyuan Wang, Sihang Li, Hengxing Cai, Qi Gu, Xiang Wang, and An Zhang. Look back to reason forward: Revisitable memory for long-context llm agents. InInterna- tional Conference on Learning Representations (ICLR),
-
[16]
URL https://arxiv.org/ abs/2602.06025. Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Huajun Chen, and Ningyu Zhang. Lightmem: Lightweight and efficient memory-augmented generation.arXiv preprint arXiv:2510.18866,
-
[18]
Chengyuan Yang, Zequn Sun, Wei Wei, and Wei Hu
URL https://arxiv.org/abs/2602.17913. Chengyuan Yang, Zequn Sun, Wei Wei, and Wei Hu. Beyond static summarization: Proactive memory extraction for llm agents.arXiv preprint arXiv:2601.04463,
-
[19]
URL https://arxiv. org/abs/2601.04463. Wenquan Ma, Jiayan Nan, Wenlong Wu, and Yize Chen. What deserves memory: Adaptive memory distillation for llm agents.arXiv preprint arXiv:2508.03341,
-
[20]
Cue-r: Beyond the final answer in retrieval-augmented generation.arXiv preprint arXiv:2604.05467,
Siddharth Jain and Venkat Narayan Vedam. Cue-r: Beyond the final answer in retrieval-augmented generation.arXiv preprint arXiv:2604.05467,
-
[21]
URL https://arxiv.org/abs/2604. 05467. Yang Liu. Fine-tune bert for extractive summarization.arXiv preprint arXiv:1903.10318,
arXiv 1903
-
[22]
Banditsum: Extractive summarization as a contextual bandit.arXiv preprint arXiv:1809.09672,
Yue Dong, Yikang Shen, Eric Crawford, Herke van Hoof, and Jackie Chi Kit Cheung. Banditsum: Extractive summarization as a contextual bandit.arXiv preprint arXiv:1809.09672,
-
[23]
DUC 2005: Evaluation of question-focused summarization systems
Hoa Trang Dang. DUC 2005: Evaluation of question-focused summarization systems. InProceedings of the Workshop on Task-F ocused Summarization and Question Answering, pages 48–55, Sydney, Australia,
2005
-
[24]
Association for Computational Linguistics. Daya Guo et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948,
-
[25]
Bowen Jin et al. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
-
[26]
memory_items
11 A Prompt Templates (Schema-Constrained JSON) A.1 Memory Writer Prompt SYSTEM: You are a memory writer. Output ONLY valid JSON. GOAL: Convert the current stream chunk into source-evidence capsule actions and a compact residual context. CONSTRAINTS: - produce source-evidence capsule actions when the chunk contains durable evidence - emit a skip action wh...
2023
-
[27]
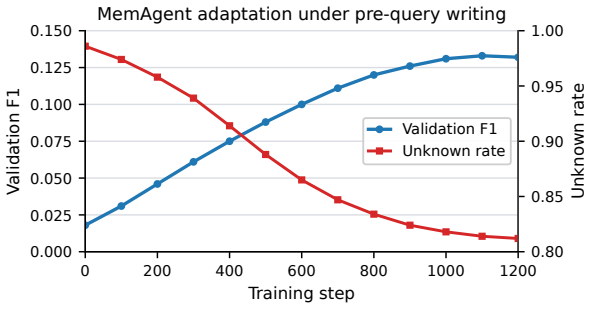
During memory-writing turns, the model receives the stream chunk and its current in-context memory state, but not the downstream question
74.84 Qwen2.5-7B + extractive read-select 76.95 C.3 MemAgent Retraining for Pre-Query Writing For the MemAgent baseline, we follow the MemAgent in-context memory algorithm but train and evaluate it under the same pre-query protocol used for EMBER. During memory-writing turns, the model receives the stream chunk and its current in-context memory state, but...
2025
-
[28]
This stricter check charges serialized index text against an 8192-token serialized-token envelope. The EMBER rows use the existing B= 4096 reader runs and charge the larger B= 8192 metadata overhead from Table 10 as a conservative upper bound; their total serialized footprints remain below 8192 tokens. Method Source-evidence cap Metadata charge Serialized...
arXiv 2026
-
[29]
0.8017 0.7712 0.7542 0.7765 0.7514 0.7556 0.7125 0.7245 0.6225 0.4914 MemAgent-7B retrained for pre-query writing 0.2929 0.2796 0.2606 0.2249 0.2597 0.2665 0.2520 0.2363 0.1500 0.2125 MemAgent-14B retrained for pre-query writing 0.2981 0.2814 0.2069 0.2396 0.2208 0.2494 0.2476 0.2181 0.1631 0.1169 EMBER-7B Learned memory policy0.8342 0.8343 0.81950.82490....
arXiv 2069
-
[30]
This points to write quality and read-side selection; retrieval capacity alone is not the bottleneck
75.64 74.34 75.14 74.12 69.53 69.67 71.74 68.54 66.32 67.79 QwenLong-L1-32B Long-context RL model 72.66 75.00 72.66 60.94 31.25 17.19 13.28 11.72 N/A N/A MemAgent-7B RL in-context memory 81.63 80.42 79.23 78.16 79.73 73.84 74.56 75.18 74.97 70.58 MemAgent-14B RL in-context memory 83.69 83.23 84.54 80.86 77.68 80.73 74.90 78.03 76.4377.09 EMBER-7B Learned ...
arXiv 2048
-
[31]
stream": [ {
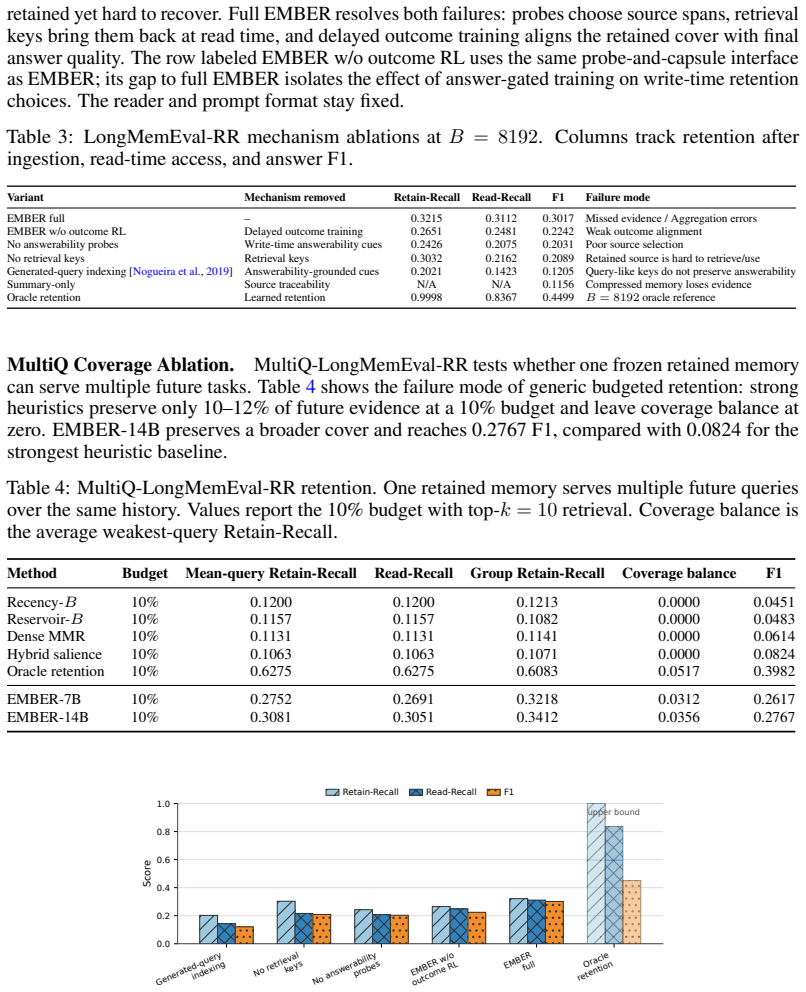
The remaining rows remove retained-evidence coverage E, lookup/readability score L, and selection purityP. Reward Retain-Recall↑Read-Recall↑F1↑ Default 0.2966 0.2915 0.2768 Answer-only RL reward 0.2666 0.2415 0.2361 w/o E 0.2556 0.2416 0.2354 w/o L 0.2712 0.2448 0.2322 w/o P 0.2759 0.2571 0.2425 Validation and checkpoint selection.Checkpoint selection use...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.