Large Language Models are Perplexed by some Political Parties
Pith reviewed 2026-06-28 02:00 UTC · model grok-4.3
The pith
Large language models assign higher perplexity to texts from far-right and nationalist parties than from social-democratic parties.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
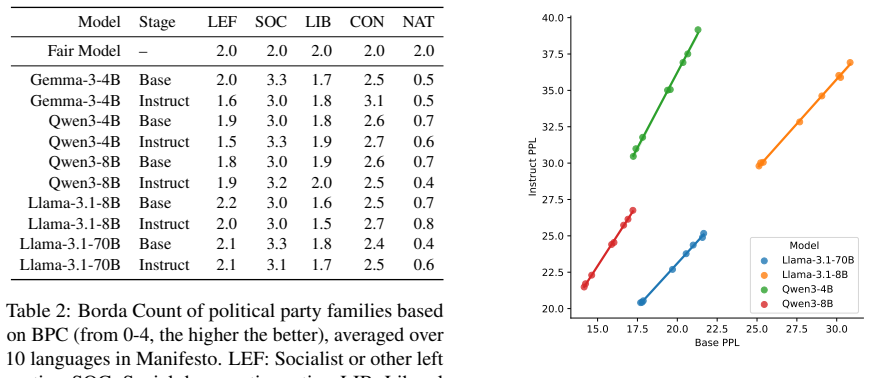
Across ten LLMs and three datasets covering 37 languages, the models exhibit higher perplexity on texts produced by far-right and nationalist parties than on texts from social-democratic parties. The same ordering holds for both base pretrained models and their instruction-tuned versions, with strong correlation between the two. Perplexity on these political texts also correlates with fairness metrics previously measured in machine translation, indicating that the modeling disparity is not limited to one task.
What carries the argument
Perplexity computed on party political texts, treated as a direct indicator of how equally the model assigns probability mass to different political groups.
If this is right
- The political ordering in perplexity is consistent with earlier translation fairness results and correlates with those downstream metrics.
- Instruction tuning leaves the relative perplexity differences between party families largely unchanged.
- The fairness properties observed are therefore attributable to pretraining rather than later tuning stages.
- The disparity appears across many languages and model families rather than being isolated to particular settings.
Where Pith is reading between the lines
- Because the models are already used in political applications, the perplexity gap could translate into uneven performance when those models process or generate content tied to different parties.
- Any attempt to reduce the observed disparity would need to alter the pretraining data distribution rather than rely on post-training adjustments.
- The same perplexity-based test could be applied to other text attributes, such as religious or ethnic affiliation, to check for parallel modeling imbalances.
Load-bearing premise
A fair language model should assign equal probability to texts from all political groups, so that differences in perplexity indicate unfairness.
What would settle it
An evaluation in which one or more LLMs produce equal or lower perplexity on far-right and nationalist texts than on social-democratic texts across the same three datasets.
Figures



read the original abstract
Large Language Models (LLMs) are increasingly used, including in political applications, but their political fairness has been little studied. We assess it using perplexity, posing that a fair model should give equal probability to all political groups. However, we find, across ten LLMs and three datasets covering 37 languages, that LLMs are more perplexed by the texts of far right and nationalist parties than of social-democratic parties. We find this to be consistent with previous work on translation fairness, to the point that perplexity correlates with downstream translation metrics. Our method is applicable to both base LLMs as well as their instruction-tuned counterpart, and we find that both are highly correlated, suggesting that the political fairness of LLMs stems from their pretraining, and is hardly affected by instruction-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs exhibit systematically higher perplexity on manifestos and texts from far-right and nationalist parties than from social-democratic parties. This pattern holds across ten LLMs (base and instruction-tuned), three datasets, and 37 languages; the authors interpret the gap as evidence of political unfairness, note its correlation with translation-quality metrics, and conclude that the bias originates in pretraining rather than instruction tuning.
Significance. If the observed perplexity differences survive controls for non-political text properties, the result would document a measurable ideological skew in LLM pretraining corpora with direct relevance to fairness in political applications. The multi-model, multi-language design and the reported correlation between perplexity and downstream translation metrics are positive features of the empirical approach.
major comments (2)
- [Abstract] Abstract and (presumably) §3–4: the central claim that higher perplexity constitutes political unfairness requires that, conditional on language and dataset, the only systematic difference between the party texts is political orientation. The abstract provides no indication that texts were length-matched, topic-matched, or normalized for surface features (sentence length, lexical rarity, formality, n-gram overlap with pre-training data) before perplexity computation; without such controls the observed gap is expected even for a politically neutral model.
- [Abstract] The weakest assumption—that a fair model must assign equal probability mass to all political groups and that perplexity is the appropriate fairness metric—is not defended against the alternative that perplexity differences track uncontrolled linguistic properties orthogonal to ideology. This assumption is load-bearing for the fairness interpretation but receives no explicit justification or robustness check.
minor comments (2)
- Clarify the exact criteria used for party classification into “far right / nationalist” versus “social-democratic” categories and report inter-annotator agreement or external validation of those labels.
- The correlation with translation metrics is interesting but would be strengthened by reporting the precise statistical test, effect size, and whether the correlation survives the same surface-feature controls recommended above.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We respond to each major comment below and indicate where revisions will be made to address the concerns.
read point-by-point responses
-
Referee: [Abstract] Abstract and (presumably) §3–4: the central claim that higher perplexity constitutes political unfairness requires that, conditional on language and dataset, the only systematic difference between the party texts is political orientation. The abstract provides no indication that texts were length-matched, topic-matched, or normalized for surface features (sentence length, lexical rarity, formality, n-gram overlap with pre-training data) before perplexity computation; without such controls the observed gap is expected even for a politically neutral model.
Authors: We agree that the absence of explicit controls for non-political properties such as length, topic, and surface features limits the strength of the causal attribution to political orientation alone. The manuscript relies on cross-dataset and cross-language consistency for robustness rather than direct matching or normalization. We will add a limitations subsection in the revised version that explicitly discusses these uncontrolled factors, their potential contribution to the observed gaps, and directions for future controlled experiments. revision: yes
-
Referee: [Abstract] The weakest assumption—that a fair model must assign equal probability mass to all political groups and that perplexity is the appropriate fairness metric—is not defended against the alternative that perplexity differences track uncontrolled linguistic properties orthogonal to ideology. This assumption is load-bearing for the fairness interpretation but receives no explicit justification or robustness check.
Authors: The manuscript states the equal-probability assumption upfront but does not provide an extended defense against the possibility that perplexity gaps reflect non-ideological linguistic properties. We will revise the introduction to include a short paragraph that (a) motivates perplexity as a fairness probe in political text settings by reference to prior work on distributional bias, (b) acknowledges the alternative explanation, and (c) notes that the observed correlation with translation metrics offers indirect support for a political component. This addition will make the interpretive step more transparent without altering the empirical results. revision: yes
Circularity Check
No circularity: empirical measurement of observed perplexity differences
full rationale
The paper reports direct empirical measurements of perplexity on political party texts across ten LLMs, three datasets, and 37 languages. No derivation chain, equations, or fitted parameters exist that reduce to the inputs by construction. The fairness premise (equal probability across groups) is stated as an explicit assumption rather than derived from the data or from self-referential definitions. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The central result is an observed correlation between perplexity and party type, which does not loop back to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A fair model should give equal probability to all political groups
Reference graph
Works this paper leans on
-
[1]
Solon Barocas, Moritz Hardt, and Arvind Narayanan. 2023. Fairness and Machine Learning : Limitations and Opportunities . MIT Press
2023
-
[2]
Su Lin Blodgett, Solon Barocas, Hal Daum \'e III, and Hanna Wallach. 2020. https://doi.org/10.18653/v1/2020.acl-main.485 Language ( Technology ) is Power : A Critical Survey of `` Bias '' in NLP . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages 5454--5476, Online. Association for Computational Linguistics
-
[3]
Julien Boelaert, Samuel Coavoux, Étienne Ollion, Ivaylo Petev, and Patrick Präg. 2025. https://doi.org/10.1177/00491241251330582 Machine bias. how do generative language models answer opinion polls?1 . Sociological Methods & Research, 54(3):1156--1196
-
[4]
Tanise Ceron, Neele Falk, Ana Bari \'c , Dmitry Nikolaev, and Sebastian Pad \'o . 2024. https://doi.org/10.1162/tacl_a_00710 Beyond Prompt Brittleness : Evaluating the Reliability and Consistency of Political Worldviews in LLMs . Transactions of the Association for Computational Linguistics, 12:1378--1400
-
[5]
Tanise Ceron, Dmitry Nikolaev, Dominik Stammbach, and Debora Nozza. 2025. What is the political content in LLMs' pre-and post-training data? arXiv preprint arXiv:2509.22367
Pith/arXiv arXiv 2025
-
[6]
Boxing Chen and Colin Cherry. 2014. https://doi.org/10.3115/v1/W14-3346 A systematic comparison of smoothing techniques for sentence-level BLEU . In Proceedings of the Ninth Workshop on Statistical Machine Translation, pages 362--367, Baltimore, Maryland, USA. Association for Computational Linguistics
-
[7]
The Computational Democracy Project. 2026. https://web.archive.org/web/20260216174419/https://pol.is/home2 Polis 2.0 . Polis. Accessed on March 11th 2026. URL archived from February 21st 2026
arXiv 2026
-
[8]
Ryan Cotterell, Sabrina J. Mielke, Jason Eisner, and Brian Roark. 2018. https://doi.org/10.18653/v1/N18-2085 Are All Languages Equally Hard to Language-Model ? In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics : Human Language Technologies , Volume 2 ( Short Papers ) , pages 536--541, New ...
-
[9]
Paula Czarnowska, Yogarshi Vyas, and Kashif Shah. 2021. https://doi.org/10.1162/tacl_a_00425 Quantifying social biases in NLP : A generalization and empirical comparison of extrinsic fairness metrics . Transactions of the Association for Computational Linguistics, 9:1249--1267. Place: Cambridge, MA Publisher: MIT Press
-
[10]
Esin Durmus, Karina Nguyen, Thomas Liao, Nicholas Schiefer, Amanda Askell, Anton Bakhtin, Carol Chen, Zac Hatfield-Dodds, Danny Hernandez, Nicholas Joseph, Liane Lovitt, Sam McCandlish, Orowa Sikder, Alex Tamkin, Janel Thamkul, Jared Kaplan, Jack Clark, and Deep Ganguli. 2024. https://openreview.net/forum?id=zl16jLb91v Towards measuring the representation...
2024
-
[11]
Toma z Erjavec, Maty \'a s Kopp, Nikola Ljube s i \'c , Taja Kuzman, Paul Rayson, Petya Osenova, Maciej Ogrodniczuk, C a g r C \"o ltekin, Danijel Kor z inek, Katja Meden, Jure Skubic, Peter Rupnik, Tommaso Agnoloni, Jos \'e Aires, Starka ur Barkarson, Roberto Bartolini, N \'u ria Bel, Mar \'i a Calzada P \'e rez, Roberts Dar g is, and 18 others. 2024. ht...
-
[12]
Shangbin Feng, Chan Young Park, Yuhan Liu, and Yulia Tsvetkov. 2023. https://doi.org/10.18653/v1/2023.acl-long.656 From pretraining data to language models to downstream tasks: Tracking the trails of political biases leading to unfair NLP models . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa...
-
[13]
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, and Nesreen K. Ahmed. 2024. https://doi.org/10.1162/coli_a_00524 Bias and Fairness in Large Language Models : A Survey . Computational Linguistics, 50(3):1097--1179
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
Pith/arXiv arXiv 2024
-
[15]
Yanzhu Guo, Simone Conia, Zelin Zhou, Min Li, Saloni Potdar, and Henry Xiao. 2025. https://doi.org/10.18653/v1/2025.acl-long.193 Do large language models have an E nglish accent? evaluating and improving the naturalness of multilingual LLM s . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers...
-
[16]
Jochen Hartmann, Jasper Schwenzow, and Maximilian Witte. 2023. https://doi.org/10.2139/ssrn.4316084 The political ideology of conversational ai: Converging evidence on chatgpt’s pro-environmental, left-libertarian orientation . Available at SSRN 4316084
-
[17]
Chadi Helwe, Oana Balalau, and Davide Ceolin. 2025. https://doi.org/10.18653/v1/2025.findings-acl.883 Navigating the Political Compass : Evaluating Multilingual LLMs across Languages and Nationalities . In Findings of the Association for Computational Linguistics : ACL 2025 , pages 17179--17204, Vienna, Austria. Association for Computational Linguistics
-
[18]
Daniel Jurafsky and James H. Martin. 2026. https://web.stanford.edu/ jurafsky/slp3/ Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, with Language Models , 3rd edition. Online manuscript released January 6, 2026
2026
-
[19]
Junsol Kim, James Evans, and Aaron Schein. 2025. https://openreview.net/forum?id=rwqShzb9li Linear representations of political perspective emerge in large language models . In The Thirteenth International Conference on Learning Representations
2025
-
[20]
William H Kruskal and W Allen Wallis. 1952. Use of ranks in one-criterion variance analysis. Journal of the American statistical Association, 47(260):583--621
1952
-
[21]
Léo Labat, Etienne Ollion, and François Yvon. 2026. https://arxiv.org/abs/2602.05932 Polyglots or multitudes? multilingual llm answers to value-laden multiple-choice questions . Preprint, arXiv:2602.05932
arXiv 2026
-
[22]
Paul Lerner and François Yvon. 2025. https://arxiv.org/abs/2510.20508 Assessing the political fairness of multilingual llms: A case study based on a 21-way multiparallel europarl dataset . Preprint, arXiv:2510.20508
arXiv 2025
-
[23]
I McLean. 2019. Voting, page 121–140. Oxford University Press
2019
-
[24]
Nicolas Merz, Sven Regel, and Jirka Lewandowski. 2016. https://doi.org/10.1177/2053168016643346 The Manifesto Corpus : A new resource for research on political parties and quantitative text analysis . Research & Politics, 3(2):2053168016643346
-
[25]
Dan Milmo and 1 others. 2023. Chatgpt reaches 100 million users two months after launch. The Guardian, 3:1017--1054
2023
-
[26]
Fabio Motoki, Valdemar Pinho Neto, and Victor Rodrigues. 2024. https://doi.org/10.1007/s11127-023-01097-2 More human than human: Measuring ChatGPT political bias . Public Choice, 198(1):3--23
-
[27]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics , pages 311--318
2002
-
[28]
Yujin Potter, Shiyang Lai, Junsol Kim, James Evans, and Dawn Song. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.244 Hidden Persuaders : LLMs ' Political Leaning and Their Influence on Voters . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages 4244--4275, Miami, Florida, USA. Association for Computationa...
-
[29]
Ricardo Rei, Jos \'e G. C. de Souza , Duarte Alves, Chrysoula Zerva, Ana C Farinha, Taisiya Glushkova, Alon Lavie, Luisa Coheur, and Andr \'e F. T. Martins. 2022. COMET-22 : Unbabel-IST 2022 Submission for the Metrics Shared Task . In Proceedings of the Seventh Conference on Machine Translation ( WMT ) , pages 578--585, Abu Dhabi, United Arab Emirates (Hy...
2022
-
[30]
Philip Resnik. 2025. https://doi.org/10.1162/coli_a_00558 Large Language Models Are Biased Because They Are Large Language Models . Computational Linguistics, 51(3):885--906
-
[31]
Manon Revel and Theophile Penigaud. 2025. Ai-facilitated collective judgements. Available at SSRN 5167340
2025
-
[32]
Paul R \"o ttger, Musashi Hinck, Valentin Hofmann, Kobi Hackenburg, Valentina Pyatkin, Faeze Brahman, and Dirk Hovy. 2025. Issuebench: Millions of realistic prompts for measuring issue bias in LLM writing assistance. arXiv preprint arXiv:2502.08395
arXiv 2025
-
[33]
Paul R \"o ttger, Valentin Hofmann, Valentina Pyatkin, Musashi Hinck, Hannah Kirk, Hinrich Schuetze, and Dirk Hovy. 2024. https://doi.org/10.18653/v1/2024.acl-long.816 Political compass or spinning arrow? Towards more meaningful evaluations for values and opinions in large language models . In Proceedings of the 62nd Annual Meeting of the Association for ...
-
[34]
David Rozado. 2023. https://doi.org/10.3390/socsci12030148 The Political Biases of ChatGPT . Social Sciences, 12(3):148
-
[35]
Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto. 2023. Whose Opinions Do Language Models Reflect ? In Proceedings of the 40th International Conference on Machine Learning , pages 29971--30004. PMLR
2023
-
[36]
Nazanin Shafiabadi and François Yvon. 2026. https://doi.org/10.63317/2pjio9ho8rxg Biases in translation: Assessing opinion distortion in machine translated texts . In Proceedings of the Fifteenth Language Resources and Evaluation Conference (LREC 2026), pages 8596--8614, Palma, Mallorca, Spain. European Language Resources Association (ELRA)
-
[37]
Christopher T. Small, Ivan Vendrov, Esin Durmus, Hadjar Homaei, Elizabeth Barry, Julien Cornebise, Ted Suzman, Deep Ganguli, and Colin Megill. 2023. https://doi.org/10.48550/arXiv.2306.11932 Opportunities and risks of llms for scalable deliberation with polis . CoRR, abs/2306.11932
-
[38]
Ilya Sutskever, James Martens, and Geoffrey Hinton. 2011. Generating text with recurrent neural networks. In Proceedings of the 28th International Conference on International Conference on Machine Learning , ICML '11, pages 1017--1024, Madison, WI, USA. Omnipress
2011
-
[39]
Gemma Team. 2025. https://doi.org/10.48550/arXiv.2503.19786 Gemma 3 Technical Report . Preprint, arXiv:2503.19786
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.19786 2025
-
[40]
Bakker, Daniel Jarrett, Hannah Sheahan, Martin J
Michael Henry Tessler, Michiel A. Bakker, Daniel Jarrett, Hannah Sheahan, Martin J. Chadwick, Raphael Koster, Georgina Evans, Lucy Campbell-Gillingham , Tantum Collins, David C. Parkes, Matthew Botvinick, and Christopher Summerfield. 2024. https://doi.org/10.1126/science.adq2852 AI can help humans find common ground in democratic deliberation . Science, 3...
-
[41]
The Top Websites Ranking. 2025. https://web.archive.org/web/20251010190024/https://www.similarweb.com/top-websites/ The top 50 most visited websites for september 2025 . Similarweb. Accessed on October 13th 2025. URL archived from October 10th 2025
arXiv 2025
-
[42]
Alexandre Verine, Rafael Pinot, and Florian Le Bronnec. 2026. https://arxiv.org/abs/2602.08660 Equalized generative treatment: Matching f-divergences for fairness in generative models . Preprint, arXiv:2602.08660
arXiv 2026
-
[43]
Sahil Verma and Julia Rubin. 2018. https://doi.org/10.1145/3194770.3194776 Fairness definitions explained . In Proceedings of the International Workshop on Software Fairness, FairWare '18, pages 1--7, New York, NY, USA. Association for Computing Machinery
-
[44]
Mingyang Wang, Heike Adel, Lukas Lange, Yihong Liu, Ercong Nie, Jannik Str \"o tgen, and Hinrich Schuetze. 2025. https://doi.org/10.18653/v1/2025.acl-long.253 Lost in multilinguality: Dissecting cross-lingual factual inconsistency in transformer language models . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V...
-
[45]
Franziska Weeber, Tanise Ceron, and Sebastian Pad \'o . 2026. https://doi.org/10.48550/arXiv.2508.05553 Do Political Opinions Transfer Between Western Languages ? An Analysis of Unaligned and Aligned Multilingual LLMs . Preprint, arXiv:2508.05553
-
[46]
Chris Wendler, Veniamin Veselovsky, Giovanni Monea, and Robert West. 2024. https://doi.org/10.18653/v1/2024.acl-long.820 Do Llamas Work in English ? On the Latent Language of Multilingual Transformers . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 15366--15394, Bangkok, Thaila...
-
[47]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.