Faithful, Enriched, and Precise: Benchmarking Natural-Science Illustration Generation by T2I models
Pith reviewed 2026-06-28 02:56 UTC · model grok-4.3
The pith
A new benchmark reveals that even leading closed-source text-to-image models still fail at accurate text rendering and balanced reasoning in scientific diagrams.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
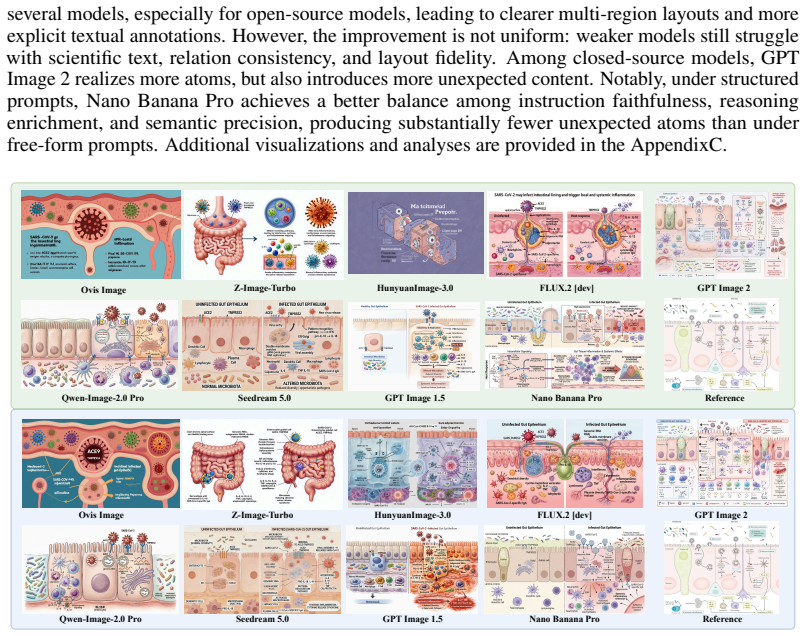
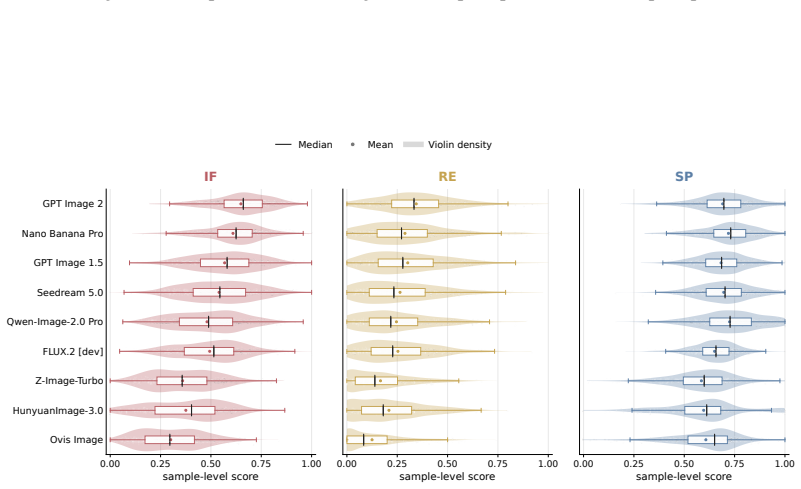
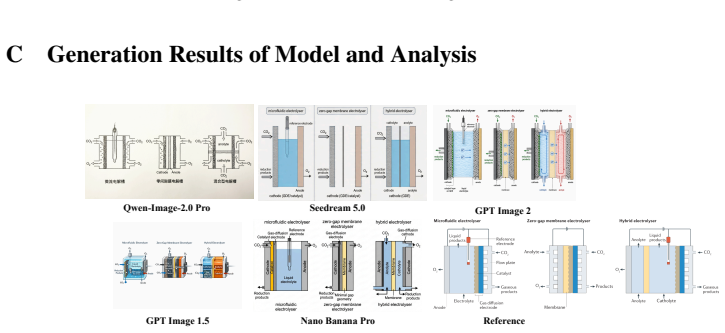
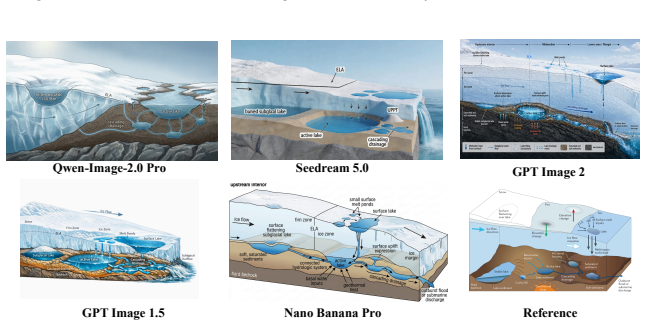
Even state-of-the-art closed-source models such as GPT Image 2 and Nano Banana Pro still suffer from text-rendering bottlenecks, limited reasoning enrichment, and difficulty balancing generation richness with precision when producing scientific illustrations.
What carries the argument
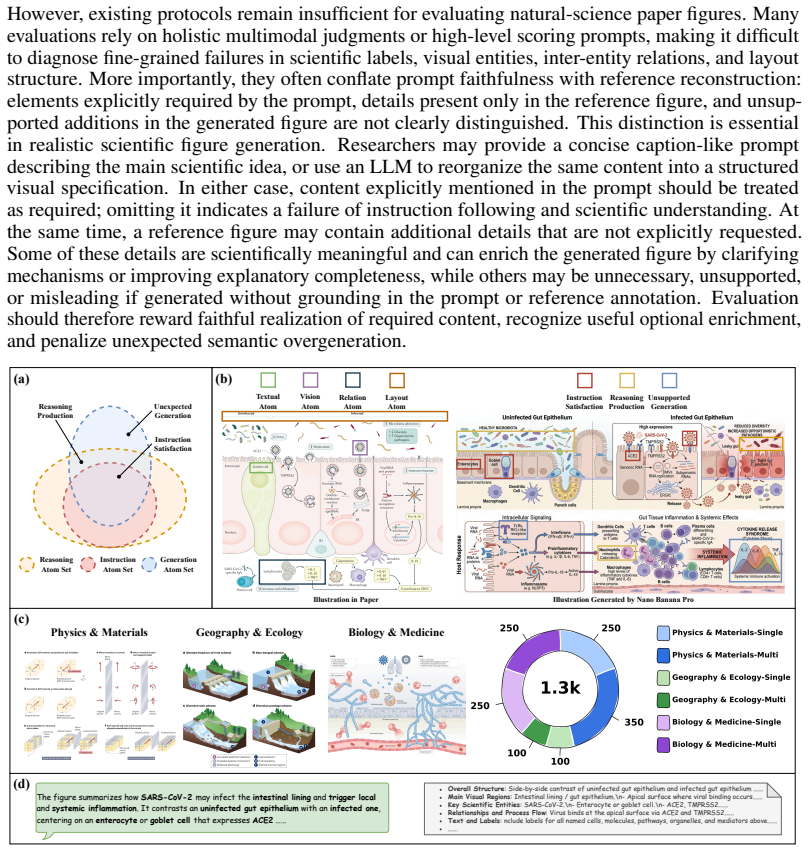
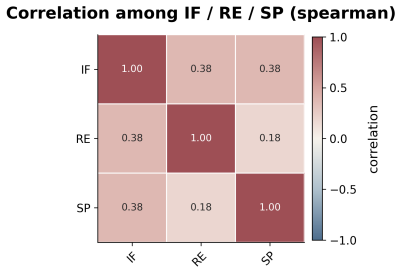
FEPBench benchmark with atom-set annotations that decompose outputs into visual, textual, relation, and layout elements for scoring instruction faithfulness, reasoning enrichment, and semantic precision.
If this is right
- Text rendering must be treated as a first-class capability rather than an afterthought for scientific use.
- Models need explicit mechanisms to add domain reasoning without drifting from the prompt.
- Generation systems will require tunable controls that let users trade richness for precision on demand.
- Evaluation of future models should report separate scores for visual, textual, relational, and layout atoms.
Where Pith is reading between the lines
- If the benchmark holds, current models are better suited to rough concept sketches than to publication-ready figures.
- The three-dimensional scoring could be applied to non-scientific domains where precise diagrams matter, such as technical manuals.
- Releasing the atom annotations may let other researchers test whether particular architectural choices drive the observed bottlenecks.
Load-bearing premise
The chosen scientific illustrations and their atom annotations accurately capture what counts as faithful, enriched, and precise generation across disciplines.
What would settle it
A new text-to-image model that scores near the top of FEPBench on all three dimensions yet produces diagrams judged unusable by practicing scientists in a blind review.
Figures



read the original abstract
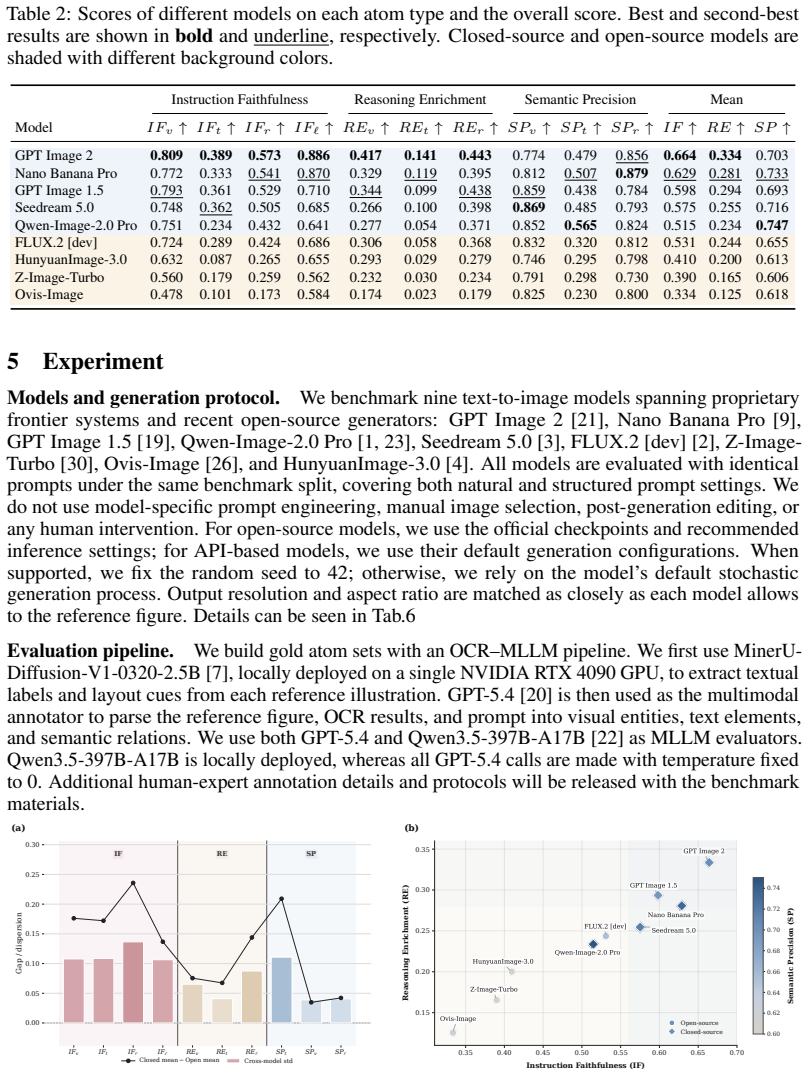
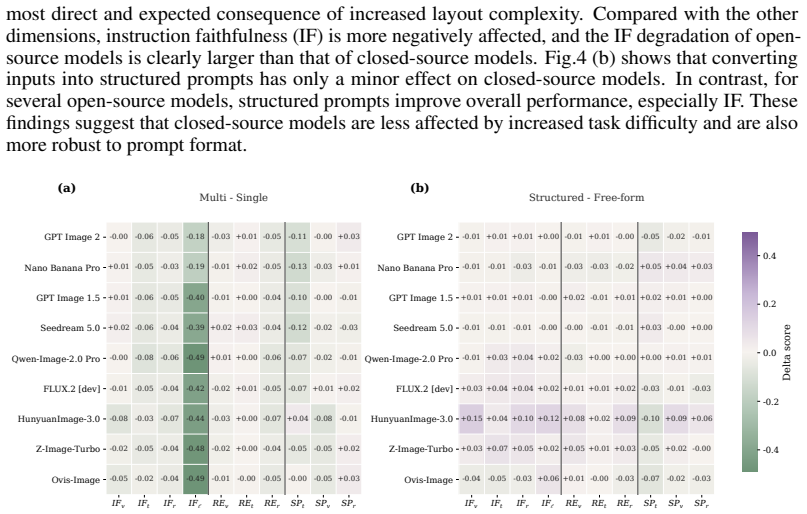
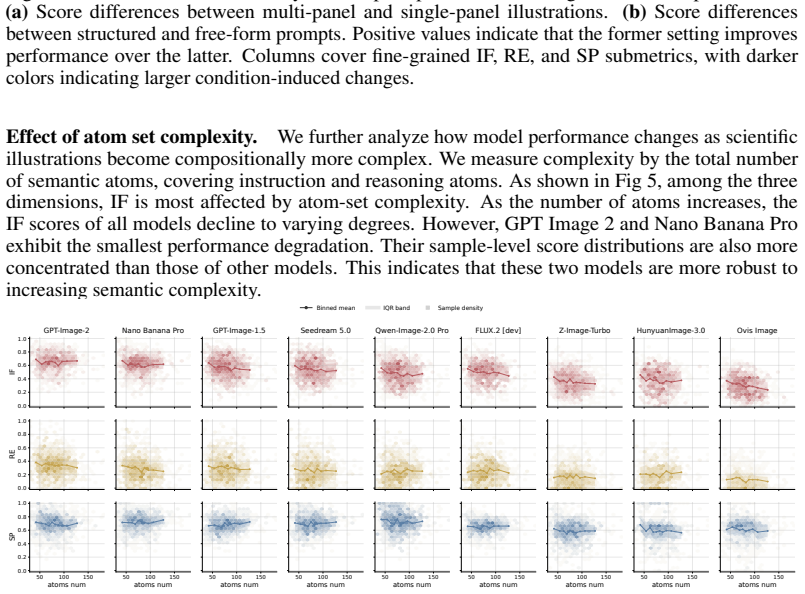
Scientific illustrations are essential tools for communicating research findings, especially in natural science, where they visualize complex concepts and processes. As Text-to-Image (T2I) models become increasingly capable, researchers have started to use them for scientific illustration generation. However, existing benchmarks often assess outputs at a holistic level, overlooking fine-grained elements, while scientific reasoning ability and output conciseness remain under-quantified. We introduce FEPBench, a benchmark built from carefully selected high-quality scientific illustrations across multiple disciplines and layout types. With the assistance of multimodal large language models (MLLMs) and human experts, we provide fine-grained atom set annotations and systematically evaluate T2I models along three dimensions: instruction faithfulness, reasoning enrichment, and semantic precision. Our evaluation further decomposes model performance across visual, textual, relation, and layout elements. Results show that even state-of-the-art (SOTA) closed-source models, such as GPT Image 2 and Nano Banana Pro, still suffer from text-rendering bottlenecks, limited reasoning enrichment, and difficulty balancing generation richness with precision. These findings provide practical guidance for improving and deploying T2I models in scientific illustration generation. Benchmark data, atom set annotations, and evaluation code will be released by us.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FEPBench, a benchmark for Text-to-Image (T2I) models focused on natural-science illustration generation. It is constructed from carefully selected high-quality illustrations across disciplines and layout types, with fine-grained atom set annotations produced via MLLM assistance and human experts. The benchmark evaluates models on three dimensions—instruction faithfulness, reasoning enrichment, and semantic precision—decomposed across visual, textual, relation, and layout elements. Results indicate that even SOTA closed-source models (e.g., GPT Image 2, Nano Banana Pro) exhibit text-rendering bottlenecks, limited reasoning enrichment, and difficulty balancing richness with precision. The authors plan to release the benchmark data, annotations, and evaluation code.
Significance. If the benchmark construction proves robust and representative, this work offers a fine-grained, domain-specific evaluation framework that addresses limitations of holistic T2I benchmarks. It identifies concrete, actionable weaknesses in current models relevant to scientific communication and provides a template for decomposed assessment. The commitment to releasing data and code supports reproducibility and extension by the community.
major comments (2)
- [Benchmark construction] Benchmark construction section: The manuscript refers to 'carefully selected high-quality scientific illustrations' and atom set annotations created 'with the assistance of MLLMs and human experts' but supplies no explicit, reproducible selection criteria, sampling strategy across disciplines, or detailed annotation protocol (including how MLLM outputs were validated by experts and any inter-annotator agreement metrics). This is load-bearing for the central claims, because the representativeness of the atom sets directly determines whether the decomposed results reliably demonstrate text-rendering bottlenecks, limited reasoning enrichment, and richness-precision imbalance.
- [Evaluation and results] Evaluation and results section: The quantitative definitions and aggregation rules for the three core metrics (instruction faithfulness, reasoning enrichment, semantic precision) and their element-wise decomposition are not provided. Without these, it is impossible to determine whether the reported model shortcomings are robust to annotation choices or sensitive to the MLLM-assisted process, undermining the strength of the performance conclusions.
minor comments (2)
- [Introduction] The abstract and introduction would benefit from a brief table or paragraph explicitly contrasting FEPBench with prior T2I benchmarks (e.g., on granularity and scientific focus) to strengthen the novelty claim.
- Figure captions for generated examples should consistently include the input prompt, the specific atom-set elements being evaluated, and the observed failure mode to aid reader interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving reproducibility and clarity. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: The manuscript refers to 'carefully selected high-quality scientific illustrations' and atom set annotations created 'with the assistance of MLLMs and human experts' but supplies no explicit, reproducible selection criteria, sampling strategy across disciplines, or detailed annotation protocol (including how MLLM outputs were validated by experts and any inter-annotator agreement metrics). This is load-bearing for the central claims, because the representativeness of the atom sets directly determines whether the decomposed results reliably demonstrate text-rendering bottlenecks, limited reasoning enrichment, and richness-precision imbalance.
Authors: We agree that the current manuscript provides only high-level descriptions and lacks the requested explicit details. In the revised version, we will add a dedicated subsection with: (1) explicit selection criteria for illustrations (e.g., requirements for scientific accuracy, visual clarity, and disciplinary diversity), (2) the sampling strategy used to cover disciplines and layout types, and (3) the full annotation protocol, including MLLM prompting details, expert validation steps, and inter-annotator agreement metrics. These additions will directly support claims about representativeness. revision: yes
-
Referee: [Evaluation and results] Evaluation and results section: The quantitative definitions and aggregation rules for the three core metrics (instruction faithfulness, reasoning enrichment, semantic precision) and their element-wise decomposition are not provided. Without these, it is impossible to determine whether the reported model shortcomings are robust to annotation choices or sensitive to the MLLM-assisted process, undermining the strength of the performance conclusions.
Authors: We acknowledge that the manuscript does not include the formal quantitative definitions or aggregation rules. In the revision, we will add precise mathematical formulations for each metric, the element-wise decomposition (visual, textual, relation, layout), and the aggregation procedures. We will also specify how MLLM-assisted annotations are handled in scoring to allow assessment of robustness. revision: yes
Circularity Check
No circularity; benchmark is externally grounded evaluation framework
full rationale
The paper constructs FEPBench from external high-quality scientific illustrations selected across disciplines, with atom-set annotations produced via MLLM assistance plus human experts. Evaluation metrics for faithfulness, enrichment, and precision are defined independently of any model outputs or fitted parameters. No equations, self-referential definitions, fitted-input predictions, or load-bearing self-citations appear in the derivation of the central claims. The reported model limitations follow directly from applying these external annotations to T2I outputs, making the evaluation self-contained against the benchmark inputs rather than reducing to them by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-quality scientific illustrations can be curated across disciplines and annotated at the atom level to serve as reliable ground truth for faithfulness, enrichment, and precision.
Reference graph
Works this paper leans on
-
[1]
Supported Models and Capabilities Overview: Qwen Image Models
Alibaba Cloud. Supported Models and Capabilities Overview: Qwen Image Models. https://www. alibabacloud.com/help/en/model-studio/models, 2026. Accessed: 2026-05-06
2026
-
[2]
FLUX.2: Next Generation Image Generation
Black Forest Labs. FLUX.2: Next Generation Image Generation. https://bfl.ai/models/flux-2,
-
[4]
Seedream 5.0 Lite
ByteDance Seed Team. Seedream 5.0 Lite. https://seed.bytedance.com/en/seedream5_0_lite,
-
[6]
HunyuanImage 3.0 Technical Report
Siyu Cao, Hangting Chen, Peng Chen, Yiji Cheng, Yutao Cui, et al. HunyuanImage 3.0 Technical Report. arXiv preprint arXiv:2509.23951, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Yifan Chang, Yukang Feng, Jianwen Sun, Jiaxin Ai, Chuanhao Li, S. Kevin Zhou, and Kaipeng Zhang. Sridbench: Benchmark of scientific research illustration drawing of image generation model.arXiv preprint arXiv:2505.22126, 2025
-
[8]
Davidsonian scene graph: Improving reliability in fine-grained evaluation for text-to-image generation
Jaemin Cho, Yushi Hu, Jason Baldridge, Roopal Garg, Peter Anderson, Ranjay Krishna, Mohit Bansal, Jordi Pont-Tuset, and Su Wang. Davidsonian scene graph: Improving reliability in fine-grained evaluation for text-to-image generation. InInternational Conference on Learning Representations, 2024
2024
-
[9]
Hejun Dong, Junbo Niu, Bin Wang, Weijun Zeng, Wentao Zhang, and Conghui He. MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding.arXiv preprint arXiv:2603.22458, 2026
-
[10]
Introducing nano banana pro
Google DeepMind. Introducing nano banana pro. Google Blog, 2025. URL https://blog.google/ technology/google-deepmind/nano-banana-pro/. Accessed 2026-04-27
2025
-
[11]
Gemini 3 Pro Image – Nano Banana Pro
Google DeepMind. Gemini 3 Pro Image – Nano Banana Pro. https://deepmind.google/models/ gemini-image/pro/, 2026. Accessed: 2026-05-06
2026
-
[12]
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, and Noah A. Smith. Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 20406–20417, 2023
2023
-
[13]
T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[14]
Evaluating numerical reasoning in text-to-image models
Ivana Kaji´c, Olivia Wiles, Isabela Albuquerque, Matthias Bauer, Su Wang, Jordi Pont-Tuset, and Aida Nematzadeh. Evaluating numerical reasoning in text-to-image models. InAdvances in Neural Information Processing Systems, Datasets and Benchmarks Track, 2024
2024
-
[15]
Easier painting than thinking: Can text-to-image models set the stage, but not direct the play? InInternational Conference on Learning Representations, 2026
Ouxiang Li, Yuan Wang, Xinting Hu, Huijuan Huang, Rui Chen, Jiarong Ou, Xin Tao, Pengfei Wan, Xiaojuan Qi, and Fuli Feng. Easier painting than thinking: Can text-to-image models set the stage, but not direct the play? InInternational Conference on Learning Representations, 2026
2026
-
[16]
Yan Li, Zezi Zeng, Ziwei Zhou, Xin Gao, Muzhao Tian, Yifan Yang, Mingxi Cheng, Qi Dai, Yuqing Yang, Lili Qiu, Zhendong Wang, Zhengyuan Yang, Xue Yang, Lijuan Wang, Ji Li, and Chong Luo. Bizgeneval: A systematic benchmark for commercial visual content generation.arXiv preprint arXiv:2603.25732, 2026
-
[17]
Scientific image synthesis: Benchmarking, methodologies, and downstream utility
Honglin Lin et al. Scientific image synthesis: Benchmarking, methodologies, and downstream utility. arXiv preprint arXiv:2601.17027, 2026
-
[18]
Evaluating text-to-visual generation with image-to-text generation
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text generation. InEuropean Conference on Computer Vision, pages 366–384, 2024. 10
2024
-
[19]
Yuxuan Luo, Yuhui Yuan, Junwen Chen, Haonan Cai, Ziyi Yue, Yuwei Yang, Fatima Zohra Daha, Ji Li, and Zhouhui Lian. Mmmg: A massive, multidisciplinary, multi-tier generation benchmark for text-to-image reasoning.arXiv preprint arXiv:2506.10963, 2025
-
[20]
David Marr.Vision: A Computational Investigation into the Human Representation and Processing of Visual Information. W. H. Freeman, San Francisco, 1982
1982
-
[21]
GPT Image 1.5 Model
OpenAI. GPT Image 1.5 Model. https://developers.openai.com/api/docs/models/ gpt-image-1.5, 2025. Accessed: 2026-05-06
2025
-
[22]
GPT-5.4 Model
OpenAI. GPT-5.4 Model. https://developers.openai.com/api/docs/models/gpt-5.4, 2026. Accessed: 2026-05-06
2026
-
[23]
Gpt image 2 model
OpenAI. Gpt image 2 model. OpenAI API Documentation, 2026. URL https://developers.openai. com/api/docs/models/gpt-image-2. Accessed 2026-04-27
2026
-
[24]
Qwen3.5: Towards Native Multimodal Agents
Qwen Team. Qwen3.5: Towards Native Multimodal Agents. https://qwen.ai/blog?id=qwen3.5,
-
[25]
Accessed: 2026-05-06
2026
-
[26]
Qwen-Image-2.0: Professional Infographics, Exquisite Text, and More
Qwen Team. Qwen-Image-2.0: Professional Infographics, Exquisite Text, and More. https://qwen.ai/ blog?id=qwen-image-2.0, 2026. Accessed: 2026-05-06
2026
-
[27]
Kaiyue Sun, Rongyao Fang, Chengqi Duan, Xian Liu, and Xihui Liu. T2i-reasonbench: Benchmarking reasoning-informed text-to-image generation.arXiv preprint arXiv:2508.17472, 2025
-
[28]
Tufte.The Visual Display of Quantitative Information
Edward R. Tufte.The Visual Display of Quantitative Information. Graphics Press, Cheshire, CT, 1983
1983
-
[29]
Ovis-Image Technical Report.arXiv preprint arXiv:2511.22982, 2025
Guo-Hua Wang, Liangfu Cao, Tianyu Cui, Minghao Fu, Xiaohao Chen, Pengxin Zhan, Jianshan Zhao, Lan Li, Bowen Fu, Jiaqi Liu, and Qing-Guo Chen. Ovis-Image Technical Report.arXiv preprint arXiv:2511.22982, 2025
-
[30]
From words to structured visuals: A benchmark and framework for text-to-diagram generation and editing
Jingxuan Wei, Cheng Tan, Qi Chen, Gaowei Wu, Siyuan Li, Zhangyang Gao, Linzhuang Sun, Bihui Yu, and Ruifeng Guo. From words to structured visuals: A benchmark and framework for text-to-diagram generation and editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13315–13325, 2025
2025
-
[31]
Revisiting text-to-image evaluation with gecko
Olivia Wiles, Isabela Albuquerque, Ivana Kajic, Jordi Pont-Tuset, Matthias Bauer, Su Wang, and Aida Nematzadeh. Revisiting text-to-image evaluation with gecko. InInternational Conference on Learning Representations, 2025
2025
-
[32]
Conceptmix: A com- positional image generation benchmark with controllable difficulty
Xindi Wu, Dingli Yu, Yangsibo Huang, Olga Russakovsky, and Sanjeev Arora. Conceptmix: A com- positional image generation benchmark with controllable difficulty. InAdvances in Neural Information Processing Systems, Datasets and Benchmarks Track, 2024
2024
-
[33]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Z-Image Team, Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Shijie Huang, et al. Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer.arXiv preprint arXiv:2511.22699, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
With more and more customers opting out of cookies, the amount of data for wisdom of crowd declines
Dawei Zhu, Rui Meng, Yale Song, Xiyu Wei, Sujian Li, Tomas Pfister, and Jinsung Yoon. Paperbanana: Automating academic illustration for ai scientists.arXiv preprint arXiv:2601.23265, 2026
-
[35]
Autofigure: Generating and refining publication-ready scientific illustrations
Minjun Zhu, Zhen Lin, Yixuan Weng, Panzhong Lu, Qiujie Xie, Yifan Wei, Sifan Liu, Qiyao Sun, and Yue Zhang. Autofigure: Generating and refining publication-ready scientific illustrations. InInternational Conference on Learning Representations, 2026. A Prompt used in MLLM Here, we provide the prompts used for atom-set scoring and unexpected-atom detection ...
2026
-
[37]
present" |
compact gold graph atoms from final_annotation_json: - text entities - visual entities - relations - layout constraints Your task is to verify the whole gold graph against the generated image in ONE pass. For each gold text entity, output only: - entity_id - presence_status: "present" | "absent" - exact_match: 1 | 0 - readable: 1 | 0 - attachment_match: 1...
-
[38]
a generated scientific figure image
-
[39]
compact allowed atoms from the gold graph: - required/optional allowed texts - allowed visual entities - allowed relations - gold visual entity count limits Inspect the generated image directly and identify unsupported scientific content in ONE pass. Output:
-
[40]
supported_texts: realized scientific texts that align to required or optional gold text atoms
-
[41]
unsupported_texts: realized scientific texts that align to neither required nor optional gold text atoms
-
[42]
unsupported_visual_entities: salient generated visual entities with scientific meaning that are not allowed by goldatoms
-
[43]
unsupported_relations: generated scientific relations that are not allowed by gold relations
-
[44]
supported_texts
generated_visual_entity_counts: generated counts for supported visual entity kinds Rules: - Do not use or infer anything from the original generation prompt. - Report only content with clear scientific meaning. - Ignore harmless decoration, layout fillers, watermark-like noise, and unreadable artifacts. - Do not output importance, confidence, notes, or ex...
-
[45]
Key Scientific Entities
-
[46]
Relationships and Process Flow
-
[47]
Legend and Visual Encoding
-
[48]
Keep each section compact
Style Only include sections that are supported by the input. Keep each section compact. Use short bullet points inside sections if useful. Emphasize: core topic and research object key visual and textual entities logical relations, mechanisms, and process flow layout and panel structure color palette and visual style Output quality target: The result shou...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.