Video-Rate Streaming Stylization on a Vision-Aware MLLM-Conditioned Edit Diffusion: Asymmetric Batched Inference on a Distilled UNet + MLLM Text Encoder
Pith reviewed 2026-06-28 02:44 UTC · model grok-4.3
The pith
Distilled U-Net with batched MLLM conditioning achieves video-rate streaming stylization at 27 fps on consumer GPUs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
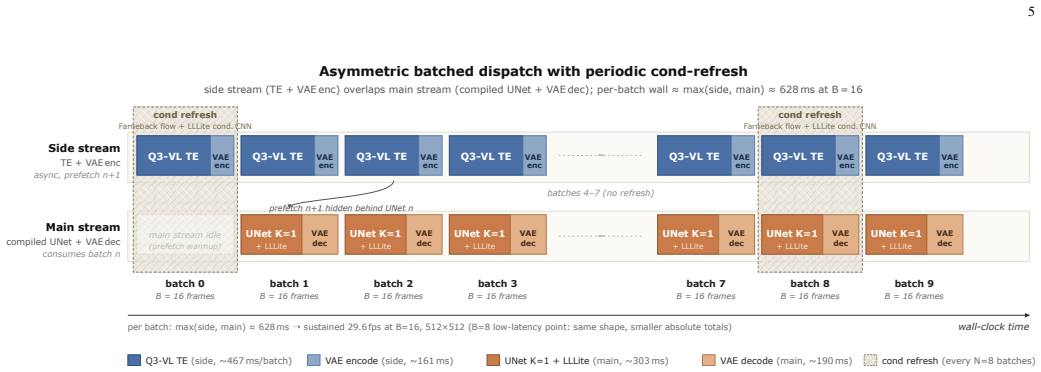
The central claim is that a pipeline using a 0.39B distilled edit U-Net and 2.13B MLLM text encoder, with asymmetric side-stream and main-stream CUDA pipelining, batched text-encoder amortisation, a fused ControlNet-LLLite graph, and periodic conditioning-refresh, sustains 27.4 fps over 480 frames at 512x512 on RTX 3090 Ti at batch size 8, rising to 29.6 fps at batch size 16, and generalizes the temporal adapter to other sequences.
What carries the argument
Asymmetric batched inference combining side-stream/main-stream CUDA pipelining with periodic conditioning-refresh schedule on the distilled UNet and MLLM text encoder.
If this is right
- The same setup measures 54.9 fps on RTX 4090 and 74.1 fps on RTX 5090.
- The temporal adapter generalizes within in-clip noise to 19 unused DAVIS-2017 sequences and 15 non-DAVIS clips.
- Prompt-level generalisation to unseen style families is bounded.
- End-to-end p50 latency is approximately 0.5 seconds at B=8 and 1.0 seconds at B=16.
Where Pith is reading between the lines
- The technique demonstrates how engineering amortisation can restore balance after distillation inverts the usual compute bottlenecks.
- This could apply to other vision-aware diffusion tasks where MLLM conditioning is used.
- Scaling to higher resolutions or longer sequences would depend on maintaining the refresh schedule without drift.
- The comparison to StreamDiffusion re-runs provides context for throughput within the distilled edit-diffusion stack.
Load-bearing premise
The periodic conditioning-refresh schedule and batched text-encoder amortisation preserve acceptable stylization quality across the full video sequence without introducing visible artifacts or drift.
What would settle it
Running the pipeline on a long video sequence and observing visible temporal artifacts, stylization drift, or quality drop compared to full per-frame MLLM conditioning.
Figures


read the original abstract
Aggressive distillation of the diffusion U-Net inverts the per-frame bottleneck of real-time text-to-image pipelines: once the denoiser is a 4-step or 1-step distilled student, the text encoder becomes the critical path. This inversion is most acute in vision-aware edit diffusion, where the encoder is a multimodal large language model (MLLM). We study the case of a 0.39B distilled edit U-Net paired with a 2.13B MLLM text encoder (Qwen3-VL) and present a streaming pipeline targeted at this regime built around three engineering mechanisms: asymmetric side-stream / main-stream CUDA pipelining with batched text-encoder amortisation (and optional static-prompt caching), a compile-friendly ControlNet-LLLite reformulation that folds the entire U-Net + adapter stack into a single fused graph, and a periodic conditioning-refresh schedule with a hook subset that amortises the per-frame conditioning cost. On a single consumer RTX 3090 Ti at 512x512 the pipeline sustains 27.4 fps over a 480-frame run at batch size B=8 and 29.6 fps at B=16, with end-to-end p50 latency of approximately 0.5 and 1.0 seconds respectively; the same operating point measures 54.9 fps on RTX 4090 and 74.1 fps on RTX 5090. We report video-rate streaming throughput rather than interactive low latency, and locate our numbers against same-stack StreamDiffusion re-runs as systems context, not as a benchmark superiority claim. For the trained oil-painting style, the released temporal adapter generalises within in-clip noise to 19 unused DAVIS-2017 sequences and 15 non-DAVIS clips from seven sources; prompt-level generalisation to unseen style families is bounded and reported separately.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that aggressive distillation of the diffusion U-Net inverts the bottleneck to the MLLM text encoder in vision-aware edit diffusion, and that three engineering mechanisms—asymmetric CUDA pipelining with batched text-encoder amortisation, a fused ControlNet-LLLite reformulation, and periodic conditioning-refresh with hook subset—enable video-rate streaming stylization. It reports concrete throughputs of 27.4 fps (B=8) and 29.6 fps (B=16) on an RTX 3090 Ti at 512×512 over 480 frames, with higher numbers on 4090/5090 hardware, while stating that a trained temporal adapter generalises within in-clip noise to 19 DAVIS sequences.
Significance. If the quality-preservation assumption holds, the work supplies a practical engineering recipe for real-time video stylization on consumer GPUs by amortising the MLLM cost; the multi-GPU throughput numbers and explicit comparison to same-stack StreamDiffusion provide usable systems context. The absence of any quantitative quality or consistency metrics, however, leaves the central claim of usable stylization unsupported.
major comments (3)
- [Abstract / Results] Abstract and results: the headline claim is 'video-rate streaming stylization,' yet no perceptual metric (LPIPS, FID, temporal consistency score), side-by-side comparison to per-frame MLLM conditioning, or user study is supplied to show that the periodic conditioning-refresh schedule and batched amortisation avoid visible drift or artifacts across the 480-frame runs.
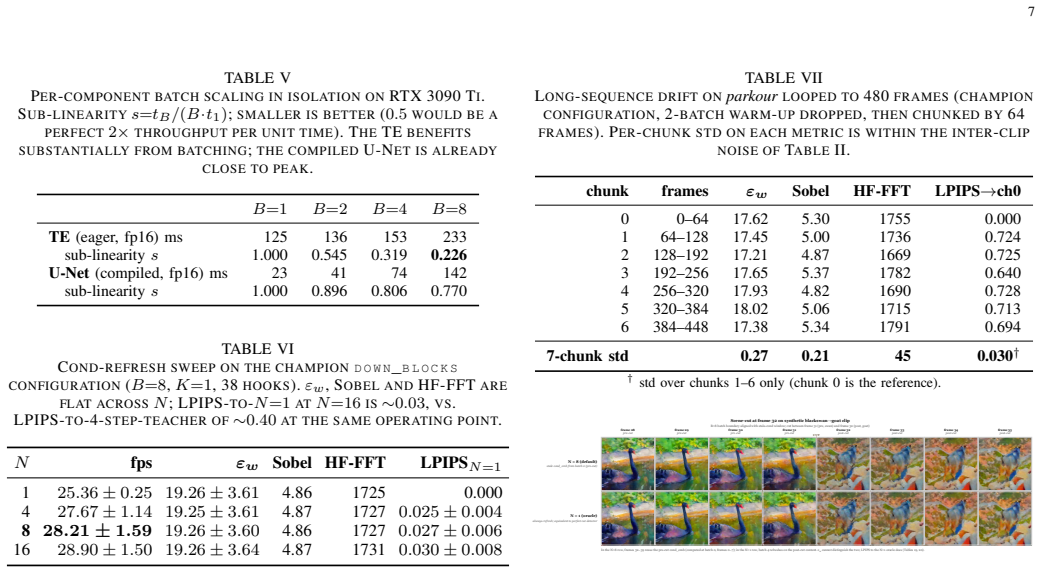
- [Results] Results: the reported FPS figures (27.4 fps at B=8, 29.6 fps at B=16 on 3090 Ti) are given as single point estimates with no error bars, standard deviations across runs, or ablation tables showing the quality-throughput trade-off for different refresh periods or batch sizes.
- [Methods] Methods: the description of the 'periodic conditioning-refresh schedule with a hook subset' and 'batched text-encoder amortisation' lacks any quantitative validation that these amortisations preserve the stylization quality claimed for the oil-painting temporal adapter on the 19 DAVIS sequences.
minor comments (2)
- [Abstract] The abstract states that prompt-level generalisation to unseen style families is 'bounded and reported separately,' but no such bounds or separate section appear in the provided text.
- [Methods] Notation for batch size B, p50 latency, and the exact definition of 'hook subset' should be introduced once in the methods before being used in the results.
Simulated Author's Rebuttal
We thank the referee for the review. The manuscript presents an engineering pipeline for throughput in MLLM-conditioned edit diffusion and assumes quality preservation from the temporal adapter; we address each comment by clarifying scope and planning textual revisions where the manuscript is incomplete.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results: the headline claim is 'video-rate streaming stylization,' yet no perceptual metric (LPIPS, FID, temporal consistency score), side-by-side comparison to per-frame MLLM conditioning, or user study is supplied to show that the periodic conditioning-refresh schedule and batched amortisation avoid visible drift or artifacts across the 480-frame runs.
Authors: We agree the manuscript supplies no perceptual metrics, user studies or side-by-side quality comparisons. The work is scoped as a systems contribution that reports achievable FPS under the quality-preservation assumption already noted by the referee; the periodic refresh and amortisation are engineered to keep conditioning fidelity but are not separately validated for perceptual impact. We will revise the abstract and results to state explicitly that no quantitative quality evaluation is performed and that stylization quality is inherited from the adapter. revision: yes
-
Referee: [Results] Results: the reported FPS figures (27.4 fps at B=8, 29.6 fps at B=16 on 3090 Ti) are given as single point estimates with no error bars, standard deviations across runs, or ablation tables showing the quality-throughput trade-off for different refresh periods or batch sizes.
Authors: The reported FPS are single deterministic executions over 480-frame sequences. We will add a methods/results note describing the measurement protocol and reproducibility on fixed hardware, and state that error bars and refresh-period ablations are omitted because the primary result is end-to-end throughput rather than a quality-throughput Pareto analysis. revision: partial
-
Referee: [Methods] Methods: the description of the 'periodic conditioning-refresh schedule with a hook subset' and 'batched text-encoder amortisation' lacks any quantitative validation that these amortisations preserve the stylization quality claimed for the oil-painting temporal adapter on the 19 DAVIS sequences.
Authors: The manuscript states that the adapter generalises to the 19 DAVIS sequences but does not isolate the effect of the amortisation mechanisms on quality. We will expand the methods section with the design rationale (periodic full refresh resets conditioning; batching amortises without altering per-frame conditioning content) and add an explicit statement that component-wise quantitative quality validation is not provided. revision: yes
Circularity Check
No circularity; claims are empirical runtime measurements with no derivations or fitted predictions
full rationale
The manuscript describes an engineering pipeline (asymmetric CUDA pipelining, batched text-encoder amortisation, periodic conditioning-refresh, fused ControlNet-LLLite graph) and reports directly measured throughput (27.4 fps on 3090 Ti at B=8, etc.) plus an empirical generalization statement for the temporal adapter on DAVIS sequences. No equations, first-principles derivations, parameter fitting, or predictions appear in the text. No self-citations are invoked to justify uniqueness or load-bearing premises. The reported fps values are external benchmarks, not quantities that reduce to the described mechanisms by construction. The quality-preservation assumption is noted as unquantified but does not constitute circularity under the defined criteria.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DreamLite: A lightweight on-device unified model for image generation and editing,
K. Feng, Y . Wei, B. Chen, Y . Pan, H. Ye, S. Liu, C. Yan, and Y . Gao, “DreamLite: A lightweight on-device unified model for image generation and editing,”arXiv preprint arXiv:2603.28713, 2026
-
[2]
Qwen Team, “Qwen3-VL technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
ControlNet-LLLite: a lightweight ControlNet-style adapter for SDXL,
kohya-ss, “ControlNet-LLLite: a lightweight ControlNet-style adapter for SDXL,” Software, available at https://github.com/kohya-ss/ sd-scripts, 2023, documentation: https://github.com/kohya-ss/sd-scripts/ blob/main/docs/train lllite README-ja.md, accessed 2026-05-17
2023
-
[4]
StreamD- iffusion: A pipeline-level solution for real-time interactive generation,
A. Kodaira, C. Xu, T. Hazama, T. Yoshimoto, K. Ohno, S. Mitsuhori, S. Sugano, H. Cho, Z. Liu, M. Tomizuka, and K. Keutzer, “StreamD- iffusion: A pipeline-level solution for real-time interactive generation,” inICCV, 2025
2025
-
[5]
Looking backward: Streaming video-to-video translation with feature banks,
F. Liang, A. Kodaira, C. Xu, M. Tomizuka, K. Keutzer, and D. Mar- culescu, “Looking backward: Streaming video-to-video translation with feature banks,” inICLR, 2025
2025
-
[6]
StreamDiffusionV2: A streaming system for dynamic and interactive video generation,
T. Feng, Z. Li, S. Yang, H. Xi, M. Li, X. Li, L. Zhang, K. Yang, K. Peng, S. Han, M. Agrawala, K. Keutzer, A. Kodaira, and C. Xu, “StreamDiffusionV2: A streaming system for dynamic and interactive video generation,”arXiv preprint arXiv:2511.07399, 2025
-
[7]
StreamDiT: Real-time streaming text-to- video generation,
A. Kodaira, T. Hou, J. Hou, M. Georgopoulos, F. Juefei-Xu, M. Tomizuka, and Y . Zhao, “StreamDiT: Real-time streaming text-to- video generation,”arXiv preprint arXiv:2507.03745, 2025
-
[8]
Motionstream: Real-time video generation with interactive motion controls
J. Shin, Z. Li, R. Zhang, J.-Y . Zhu, J. Park, E. Shechtman, and X. Huang, “MotionStream: Real-time video generation with interactive motion controls,” inInternational Conference on Learning Representations (ICLR), Oral, 2026, also available as arXiv:2511.01266
-
[9]
DiT as Real-Time Rerenderer: Streaming Video Stylization with Autoregressive Diffusion Transformer
H. Lyuet al., “DiT as real-time rerenderer: Streaming video styl- ization with autoregressive diffusion transformer,”arXiv preprint arXiv:2604.13509, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Live2Diff: Live stream translation via uni-directional attention in video diffusion models,
Z. Xing, G. Fox, Y . Zeng, X. Pan, M. Elgharib, C. Theobalt, and K. Chen, “Live2Diff: Live stream translation via uni-directional attention in video diffusion models,”arXiv preprint arXiv:2407.08701, 2024
-
[11]
Streaming video dif- fusion: Online video editing with diffusion models,
F. Chen, Z. Yang, B. Zhuang, and Q. Wu, “Streaming video dif- fusion: Online video editing with diffusion models,”arXiv preprint arXiv:2405.19726, 2024
-
[12]
Denoising reuse: Exploiting inter-frame motion con- sistency for efficient video generation,
C. Wanget al., “Denoising reuse: Exploiting inter-frame motion con- sistency for efficient video generation,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[13]
Parallel sampling of diffusion models,
A. Shih, S. Belkhale, S. Ermon, D. Sadigh, and N. Anari, “Parallel sampling of diffusion models,” inNeurIPS, 2023
2023
-
[14]
DistriFusion: Distributed parallel inference for high- resolution diffusion models,
M. Li, T. Cai, J. Cao, Q. Zhang, H. Cai, J. Bai, Y . Jia, M.-Y . Liu, K. Li, and S. Han, “DistriFusion: Distributed parallel inference for high- resolution diffusion models,” inCVPR, 2024
2024
-
[15]
PipeFusion: Patch-level pipeline parallelism for diffusion transformers inference,
J. Fang, J. Pan, A. Li, X. Sun, and J. Wang, “PipeFusion: Patch-level pipeline parallelism for diffusion transformers inference,” inNeurIPS, 2025
2025
-
[16]
VLCache: Computing 2% vision tokens and reusing 98% for vision-language inference,
Y . Qinet al., “VLCache: Computing 2% vision tokens and reusing 98% for vision-language inference,”arXiv preprint arXiv:2512.12977, 2025
-
[17]
Skip-Vision: Efficient and scalable acceleration of vision-language models via adaptive token skipping,
W. Zeng, Z. Huang, K. Ji, and Y . Yan, “Skip-Vision: Efficient and scalable acceleration of vision-language models via adaptive token skipping,” inInternational Conference on Computer Vision (ICCV), 2025
2025
-
[18]
InfiniPot-V: Memory- constrained kv cache compression for streaming video understanding,
M. Kim, K. Shim, J. Choi, and S. Chang, “InfiniPot-V: Memory- constrained kv cache compression for streaming video understanding,” arXiv preprint arXiv:2506.15745, 2025
-
[19]
Adaptive caching for faster video generation with diffusion transformers,
K. Kahatapitiya, H. Liu, S. He, D. Liu, M. Jia, C. Zhang, M. S. Ryoo, and T. Xie, “Adaptive caching for faster video generation with diffusion transformers,” inInternational Conference on Computer Vision (ICCV), 2025, also available as arXiv:2411.02397
-
[20]
Attention is all you need for KV cache in diffusion LLMs,
Q. Nguyen-Tri, M. Ranjan, and Z. Shen, “Attention is all you need for KV cache in diffusion LLMs,”arXiv preprint arXiv:2510.14973, 2025
-
[21]
GPT4Video: A unified multimodal large language model for instruction-followed understanding and safety-aware gener- ation,
Z. Wang, L. Wang, Z. Zhao, M. Wu, C. Lyu, H. Li, D. Cai, L. Zhou, S. Shi, and Z. Tu, “GPT4Video: A unified multimodal large language model for instruction-followed understanding and safety-aware gener- ation,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 3907–3916
2024
-
[22]
MoTrans: Customized motion transfer with text-driven video diffusion models,
X. Li, X. Jia, Q. Wang, H. Diao, M. Ge, P. Li, Y . He, and H. Lu, “MoTrans: Customized motion transfer with text-driven video diffusion models,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 3421–3430
2024
-
[23]
Emerging Properties in Unified Multimodal Pretraining
C. Denget al., “Emerging properties in unified multimodal pretraining,” arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
C. Wuet al., “OmniGen2: Exploration to advanced multimodal gener- ation,”arXiv preprint arXiv:2506.18871, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
AnimateDiff: Animate your personalized text-to- image diffusion models without specific tuning,
Y . Guo, C. Yang, A. Rao, Z. Liang, Y . Wang, Y . Qiao, M. Agrawala, D. Lin, and B. Dai, “AnimateDiff: Animate your personalized text-to- image diffusion models without specific tuning,” inICLR, 2024
2024
-
[26]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y . Levi, Z. English, V . V oleti, A. Lettset al., “Stable video diffusion: Scaling latent video diffusion models to large datasets,”arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Rerender a video: Zero-shot text-guided video-to-video translation,
S. Yang, Y . Zhou, Z. Liu, and C. C. Loy, “Rerender a video: Zero-shot text-guided video-to-video translation,” inSIGGRAPH Asia, 2023
2023
-
[28]
FlowVid: Taming imperfect optical flows for consistent video-to-video synthesis,
F. Liang, B. Wu, J. Wang, L. Yu, K. Li, Y . Zhao, I. Misra, J.-B. Huang, P. Zhang, P. Vajda, and D. Marculescu, “FlowVid: Taming imperfect optical flows for consistent video-to-video synthesis,” inCVPR, 2024
2024
-
[29]
Edit temporal-consistent videos with image diffusion model,
Y . Wang, Y . Li, X. Zhang, X. Liu, A. Dai, A. B. Chan, and Z. Cui, “Edit temporal-consistent videos with image diffusion model,”ACM Trans- actions on Multimedia Computing, Communications, and Applications, vol. 20, no. 12, pp. 1–16, 2024
2024
-
[30]
Spatio- temporal energy-guided diffusion model for zero-shot video synthesis and editing,
L. Yang, Y . Zhao, Z. Yu, B. Zeng, M. Xu, S. Hong, and B. Cui, “Spatio- temporal energy-guided diffusion model for zero-shot video synthesis and editing,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 6, pp. 6034–6046, 2025
2025
-
[31]
UniVST: A unified framework for training-free localized video style transfer,
Q. Song, M. Lin, W. Zhan, S. Yan, L. Cao, and R. Ji, “UniVST: A unified framework for training-free localized video style transfer,”arXiv preprint arXiv:2410.20084, 2024
-
[32]
TVG: A training-free transition video generation method with diffusion models,
R. Zhang, Y . Chen, Y . Liu, W. Wang, X. Wen, and H. Wang, “TVG: A training-free transition video generation method with diffusion models,” IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[33]
FluencyVE: Marrying temporal- aware mamba with bypass attention for video editing,
M. Cai, Y . Li, O. Yoshie, and Y . Ieiri, “FluencyVE: Marrying temporal- aware mamba with bypass attention for video editing,”IEEE Transac- tions on Multimedia, 2026, also available as arXiv:2512.21015
-
[34]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” inICCV, 2023
2023
-
[35]
LCM-LoRA: A universal stable-diffusion acceleration module,
S. Luo, Y . Tan, S. Patil, D. Gu, P. von Platen, A. Passos, L. Huang, J. Li, and H. Zhao, “LCM-LoRA: A universal stable-diffusion acceleration module,”arXiv preprint arXiv:2311.05556, 2023
-
[36]
Adversarial diffusion distillation,
A. Sauer, D. Lorenz, A. Blattmann, and R. Rombach, “Adversarial diffusion distillation,” inECCV, 2024
2024
-
[37]
SDXL-Lightning: Progressive Adversarial Diffusion Distillation
S. Lin, A. Wang, and X. Yang, “SDXL-Lightning: Progressive adver- sarial diffusion distillation,”arXiv preprint arXiv:2402.13929, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boeselet al., “Scaling rectified flow transformers for high-resolution image synthesis,” inICML, 2024
2024
-
[39]
Two-frame motion estimation based on polynomial expansion,
G. Farneb ¨ack, “Two-frame motion estimation based on polynomial expansion,” inScandinavian Conference on Image Analysis (SCIA), 2003
2003
-
[40]
PyTorch 2: Faster machine learning through dynamic Python bytecode transformation and graph compilation,
J. Ansel, E. Yang, H. He, N. Gimelshein, A. Jain, M. V oznesensky, B. Bao, P. Bell, D. Berard, E. Burovskiet al., “PyTorch 2: Faster machine learning through dynamic Python bytecode transformation and graph compilation,” inASPLOS, 2024
2024
-
[41]
The 2017 DAVIS Challenge on Video Object Segmentation
J. Pont-Tuset, F. Perazzi, S. Caelles, P. Arbel ´aez, A. Sorkine-Hornung, and L. Van Gool, “The 2017 DA VIS challenge on video object segmen- tation,”arXiv preprint arXiv:1704.00675, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Learning blind video temporal consistency,
W.-S. Lai, J.-B. Huang, O. Wang, E. Shechtman, E. Yumer, and M.-H. Yang, “Learning blind video temporal consistency,” inECCV, 2018
2018
-
[43]
RAFT: Recurrent all-pairs field transforms for optical flow,
Z. Teed and J. Deng, “RAFT: Recurrent all-pairs field transforms for optical flow,” inEuropean Conference on Computer Vision (ECCV), 2020. 12
2020
-
[44]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in CVPR, 2018
2018
-
[45]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inICML, 2021
2021
-
[46]
Fast inference from trans- formers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast inference from trans- formers via speculative decoding,” inICML, 2023
2023
-
[47]
H. Chen, C. Xu, X. Yang, X. Chen, and C. Deng, “Past- and future- informed KV cache policy with salience estimation in autoregressive video diffusion,”arXiv preprint arXiv:2601.21896, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.