Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
Pith reviewed 2026-06-28 03:02 UTC · model grok-4.3
The pith
Post-hoc compression of reasoning traces before distillation yields up to 96% of raw accuracy with up to 18x per-token efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
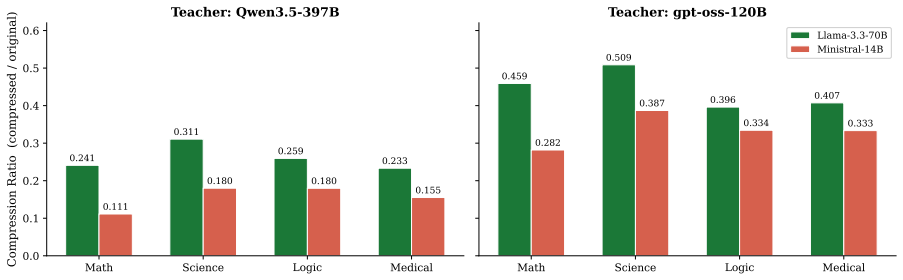
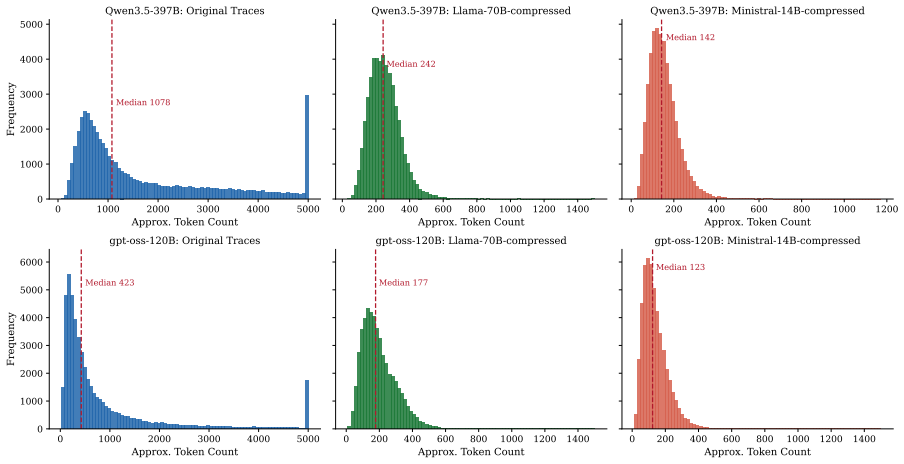
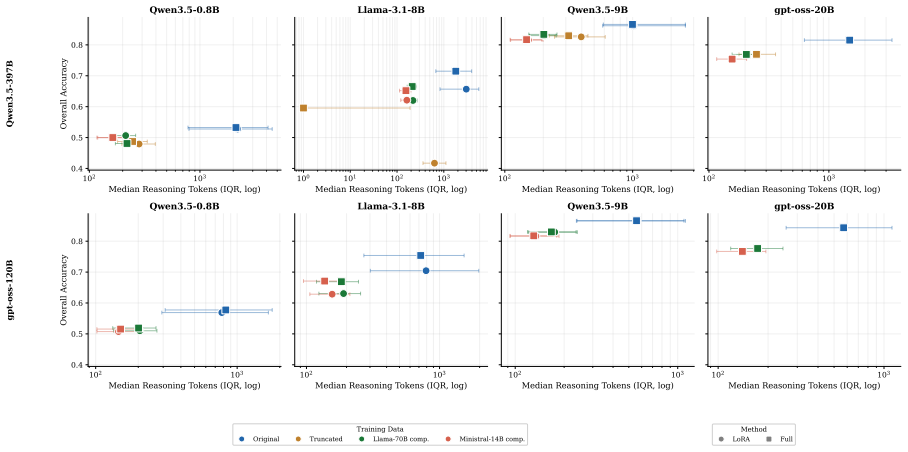
Model-compressed reasoning traces reduce training tokens to 12-30% of raw traces and shorten inference outputs by 3-19x, allowing students to retain up to 96% of the accuracy achieved with uncompressed traces while achieving up to 18x higher per-token efficiency; compressed traces also outperform length-matched truncation especially for smaller students.
What carries the argument
Post-hoc compression of already-correct reasoning traces by separate instruction-tuned models before they are used for distillation.
If this is right
- Training token count drops to 12-30% of the uncompressed baseline, producing 2.0-7.6x faster training runs.
- Student inference outputs become 3-19x shorter while accuracy stays within 4% of the raw-trace ceiling.
- Model-compressed traces beat or match naive length-matched truncation, with the largest relative gains for the smallest students.
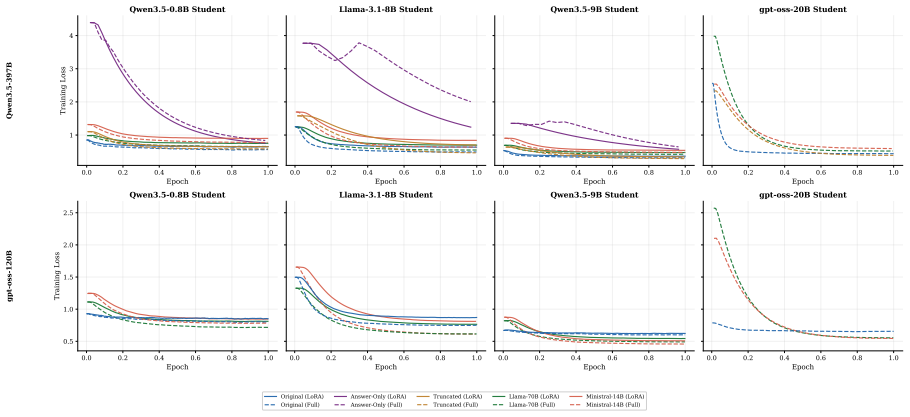
- The raw-versus-compressed accuracy gap narrows under LoRA at the 0.8B scale but does not reverse.
Where Pith is reading between the lines
- The same compression step could be inserted before distilling other long-form reasoning outputs such as mathematical derivations or multi-step code explanations.
- Jointly optimizing the compressor and the student might close more of the remaining accuracy gap than the current sequential pipeline.
- Because smaller students benefit most, the technique could make high-quality reasoning distillation practical on consumer hardware.
Load-bearing premise
That the instruction-tuned compression models preserve the logical structure and correctness of the original reasoning traces sufficiently for the student to learn effective reasoning.
What would settle it
An experiment in which any student trained on compressed traces achieves higher final accuracy than the corresponding student trained on the raw traces at the same scale and compute budget.
Figures
read the original abstract
Reasoning models produce long chain-of-thought traces that are costly to distill and encourage verbose student outputs. We study post-hoc compression of such traces before knowledge distillation. Two teachers, Qwen3.5-397B-A17B and gpt-oss-120B, generate about 283k correct traces each; two instruction-tuned models then compress them to 8.6-21.0% of their original character length. Across a 48-run main grid plus seven Qwen-teacher truncation ablations, compressed traces reduce training tokens to 12-30% of raw, speed up training by 2.0-7.6x, and shorten inference outputs by 3-19x with smaller reductions under the shorter gpt-oss teacher. However, raw traces retain the highest downstream accuracy at every scale and for both teachers. A length-matched raw-trace truncation ablation shows that compression is not merely benefiting from a smaller token budget: model-compressed traces usually beat or match naive truncation, especially for smaller students, while maintaining shorter inference outputs. Overall, reasoning-trace compression offers an accuracy-efficiency trade-off rather than a free improvement: students retain up to 96% of raw-trace accuracy while gaining up to 18x higher per-token efficiency, and at the 0.8B scale under LoRA compressed traces narrow the raw-vs-compressed gap but do not exceed raw.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies post-hoc compression of long chain-of-thought traces generated by two large teachers (Qwen3.5-397B-A17B and gpt-oss-120B, ~283k correct traces each) using instruction-tuned compressors that reduce length to 8.6-21% of original. Across a 48-run main grid plus truncation ablations, it reports that compressed traces cut training tokens to 12-30%, speed training 2.0-7.6x, shorten inference outputs 3-19x, and let students retain up to 96% of raw-trace accuracy while often beating length-matched truncation (especially for smaller students), yielding an accuracy-efficiency trade-off rather than a free lunch.
Significance. If the central results hold, the work supplies a concrete, experimentally grounded method for trading a modest accuracy drop for large gains in training and inference efficiency when distilling reasoning. The 48-run grid, two-teacher design, and explicit length-matched truncation control are strengths that directly support the claim that gains are not merely from shorter token budgets. The per-token efficiency numbers and the observation that compression narrows the gap at the 0.8B LoRA scale are useful for practitioners.
major comments (2)
- [§4] §4 (trace compression and evaluation protocol): No post-compression verification is reported that checks whether a compressed trace, when read in isolation, still produces the original correct final answer or contains valid intermediate reasoning steps. The only correctness signal is the pre-compression teacher trace; this assumption is load-bearing for interpreting the 'up to 96% retention' result as an efficiency trade-off rather than possible degradation of supervision quality.
- [§5.1] §5.1 and Table 2 (student training details): Exact hyperparameters, optimizer settings, full loss formulation, and whether the student is trained with the compressed trace as the sole target or with additional formatting are not provided. These details are required to interpret the 48-run grid and to assess whether the reported accuracy differences could arise from training-protocol variation rather than the compression itself.
minor comments (2)
- [Abstract] Abstract and §1: the phrase 'parameter-free' is not used, but several efficiency ratios are presented without explicit dependence on the compressor model size; a short clarification on whether compressor choice introduces hidden parameters would help.
- [Figures] Figure captions: several figures lack error bars or run counts even though the text mentions a 48-run grid; adding these would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [§4] §4 (trace compression and evaluation protocol): No post-compression verification is reported that checks whether a compressed trace, when read in isolation, still produces the original correct final answer or contains valid intermediate reasoning steps. The only correctness signal is the pre-compression teacher trace; this assumption is load-bearing for interpreting the 'up to 96% retention' result as an efficiency trade-off rather than possible degradation of supervision quality.
Authors: We agree this is a valuable point and that explicit post-compression verification would strengthen the claims. In the revised manuscript we will add a new analysis: we will sample a subset of compressed traces, feed each in isolation to a held-out verifier model (distinct from the teachers), and report the fraction that still elicit the original correct final answer. We will also qualitatively inspect a sample for validity of intermediate steps. This will allow readers to assess whether any accuracy drop is due to degraded supervision quality versus the efficiency trade-off. We note that the compressors were instruction-tuned on pairs of raw and compressed traces with the explicit goal of preserving reasoning, but we acknowledge the need for this additional check. revision: yes
-
Referee: [§5.1] §5.1 and Table 2 (student training details): Exact hyperparameters, optimizer settings, full loss formulation, and whether the student is trained with the compressed trace as the sole target or with additional formatting are not provided. These details are required to interpret the 48-run grid and to assess whether the reported accuracy differences could arise from training-protocol variation rather than the compression itself.
Authors: We apologize for the omission. In the revised version we will expand §5.1 and Table 2 with the complete training configuration: optimizer (AdamW, β1=0.9, β2=0.95, weight decay 0.1), learning rate schedule (cosine with 10% warmup), batch size, number of epochs, and the precise loss (standard autoregressive cross-entropy on the target tokens only). We will also clarify that each student is trained to generate the provided trace (raw or compressed) as its sole target sequence using the standard chat template; no extra formatting tokens or auxiliary objectives are added beyond the initial system prompt that instructs the model to produce a step-by-step solution. revision: yes
Circularity Check
No circularity: empirical measurements against explicit baselines
full rationale
The paper presents an experimental study with 48-run grids and truncation ablations, reporting direct accuracy and efficiency metrics (e.g., 96% retention, 18x efficiency) from training on raw vs. compressed vs. length-matched traces. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; results are measured against independent baselines rather than reducing to internal definitions or prior author work by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Instruction-tuned compression models produce shortenings that retain the reasoning quality of the original correct traces.
Reference graph
Works this paper leans on
-
[1]
Pranjal Aggarwal and Sean Welleck. 2025. https://openreview.net/forum?id=4jdIxXBNve L1: Controlling how long a reasoning model thinks with reinforcement learning . In Second Conference on Language Modeling
2025
-
[2]
Iñigo Alonso, Maite Oronoz, and Rodrigo Agerri. 2024. https://doi.org/10.1016/j.artmed.2024.102938 Medexpqa: Multilingual benchmarking of large language models for medical question answering . Artificial Intelligence in Medicine, 155:102938
-
[3]
Aytes, Jinheon Baek, and Sung Ju Hwang
Simon A. Aytes, Jinheon Baek, and Sung Ju Hwang. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1236 Sketch-of-thought: Efficient LLM reasoning with adaptive cognitive-inspired sketching . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 24296--24320, Suzhou, China. Association for Computational Linguistics
-
[4]
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. 2020. PIQA : Reasoning about Physical Commonsense in Natural Language . In Thirty- Fourth AAAI Conference on Artificial Intelligence
2020
-
[5]
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. 2025. https://openreview.net/forum?id=MSbU3L7V00 Do NOT think that much for 2+3=? on the overthinking of long reasoning models . In Forty-second International Conference on Machine Learning
2025
-
[6]
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. https://doi.org/10.18653/v1/N19-1300 BoolQ : Exploring the Surprising Difficulty of Natural Yes / No Questions . In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics : Human Language...
-
[7]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. https://arxiv.org/abs/1803.05457 Think you have solved question answering? try arc, the ai2 reasoning challenge . Preprint, arXiv:1803.05457
Pith/arXiv arXiv 2018
-
[8]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. https://arxiv.org/abs/2110.14168 Training verifiers to solve math word problems . Preprint, arXiv:2110.14168
Pith/arXiv arXiv 2021
-
[9]
Tri Dao. 2024. https://openreview.net/forum?id=mZn2Xyh9Ec Flashattention-2: Faster attention with better parallelism and work partitioning . In The Twelfth International Conference on Learning Representations
2024
-
[10]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle , Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, and 516 others. 2024. https://doi.org/10.48550/arXiv.2407.21783 The Llama 3...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[11]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, and 175 others. 2025. https://doi.org/10.1038/s41586-025-09422-z DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement lear...
-
[12]
Tingxu Han, Zhenting Wang, Chunrong Fang, Shiyu Zhao, Shiqing Ma, and Zhenyu Chen. 2025. https://doi.org/10.18653/v1/2025.findings-acl.1274 Token-budget-aware LLM reasoning . In Findings of the Association for Computational Linguistics: ACL 2025, pages 24842--24855, Vienna, Austria. Association for Computational Linguistics
-
[13]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. https://openreview.net/forum?id=d7KBjmI3GmQ Measuring massive multitask language understanding . In International Conference on Learning Representations
2021
-
[14]
Namgyu Ho, Laura Schmid, and Se-Young Yun. 2023. https://doi.org/10.18653/v1/2023.acl-long.830 Large language models are reasoning teachers . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14852--14882, Toronto, Canada. Association for Computational Linguistics
-
[15]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lo RA : Low-rank adaptation of large language models . In International Conference on Learning Representations
2022
-
[16]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. https://doi.org/10.3390/app11146421 What Disease Does This Patient Have ? A Large-Scale Open Domain Question Answering Dataset from Medical Exams . Applied Sciences, 11(14)
-
[17]
Yu Kang, Xianghui Sun, Liangyu Chen, and Wei Zou. 2025. https://doi.org/10.1609/aaai.v39i23.34608 C3ot: generating shorter chain-of-thought without compromising effectiveness . In Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symp...
-
[18]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS '22, Red Hook, NY, USA. Curran Associates Inc
2022
-
[19]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. https://doi.org/10.1145/3600006.3613165 Efficient Memory Management for Large Language Model Serving with PagedAttention . In Proceedings of the 29th Symposium on Operating Systems Principles , SOSP '23, pages 611--626, New Yor...
-
[20]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. https://doi.org/10.18653/v1/2022.acl-long.229 T ruthful QA : Measuring how models mimic human falsehoods . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214--3252, Dublin, Ireland. Association for Computational Linguistics
-
[21]
Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. 2017. https://arxiv.org/abs/1705.04146 Program induction by rationale generation : Learning to solve and explain algebraic word problems . Preprint, arXiv:1705.04146
Pith/arXiv arXiv 2017
-
[22]
Alexander H. Liu, Kartik Khandelwal, Sandeep Subramanian, Victor Jouault, Abhinav Rastogi, Adrien Sadé, Alan Jeffares, Albert Jiang, Alexandre Cahill, Alexandre Gavaudan, Alexandre Sablayrolles, Amélie Héliou, Amos You, Andy Ehrenberg, Andy Lo, Anton Eliseev, Antonia Calvi, Avinash Sooriyarachchi, Baptiste Bout, and 101 others. 2026. https://arxiv.org/abs...
Pith/arXiv arXiv 2026
-
[23]
Haotian Luo, Li Shen, Haiying He, Yibo Wang, Shiwei Liu, Wei Li, Naiqiang Tan, Xiaochun Cao, and Dacheng Tao. 2025. https://doi.org/10.48550/arXiv.2501.12570 O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning . CoRR, abs/2501.12570
-
[24]
Lucie Charlotte Magister, Jonathan Mallinson, Jakub Adamek, Eric Malmi, and Aliaksei Severyn. 2023. https://arxiv.org/abs/2212.08410 Teaching small language models to reason . Preprint, arXiv:2212.08410
arXiv 2023
-
[25]
Tergel Munkhbat, Namgyu Ho, Seo Hyun Kim, Yongjin Yang, Yujin Kim, and Se-Young Yun. 2025. https://doi.org/10.18653/v1/2025.findings-acl.1289 Self-training elicits concise reasoning in large language models . In Findings of the Association for Computational Linguistics: ACL 2025, pages 25127--25152, Vienna, Austria. Association for Computational Linguistics
-
[26]
OpenAI, :, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, and 108 others. 2025. https://arxiv.org/abs/2508.10925 gpt-oss-120b & gpt-oss-20b model card . Preprint, arXiv:...
Pith/arXiv arXiv 2025
-
[27]
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. 2022. MedMCQA : A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering . In Proceedings of the Conference on Health , Inference , and Learning , volume 174 of Proceedings of Machine Learning Research , pages 248--260. PMLR
2022
-
[28]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. 2021. https://doi.org/10.18653/v1/2021.naacl-main.168 Are NLP models really able to solve simple math word problems? In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2080--2094, Online. Association for ...
work page internal anchor Pith review doi:10.18653/v1/2021.naacl-main.168 2021
-
[29]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. 2024. https://openreview.net/forum?id=Ti67584b98 GPQA : A graduate-level google-proof q&a benchmark . In First Conference on Language Modeling
2024
-
[30]
Subhro Roy and Dan Roth. 2015. https://doi.org/10.18653/v1/D15-1202 Solving general arithmetic word problems . In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1743--1752, Lisbon, Portugal. Association for Computational Linguistics
-
[31]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. https://doi.org/10.1145/3474381 WinoGrande : An Adversarial Winograd Schema Challenge at Scale . Commun. ACM, 64(9):99--106
-
[32]
Yi Shen, Jian Zhang, Jieyun Huang, Shuming Shi, Wenjing Zhang, Jiangze Yan, Ning Wang, Kai Wang, Zhaoxiang Liu, and Shiguo Lian. 2025. https://doi.org/10.18653/v1/2025.emnlp-industry.160 DAST : Difficulty-adaptive slow-thinking for large reasoning models . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry ...
-
[33]
Kumar Shridhar, Alessandro Stolfo, and Mrinmaya Sachan. 2023. https://doi.org/10.18653/v1/2023.findings-acl.441 Distilling reasoning capabilities into smaller language models . In Findings of the Association for Computational Linguistics: ACL 2023, pages 7059--7073, Toronto, Canada. Association for Computational Linguistics
-
[34]
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. https://doi.org/10.18653/v1/N19-1421 C ommonsense QA : A question answering challenge targeting commonsense knowledge . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long ...
-
[35]
Qwen Team. 2025. QwQ-32B : Embracing the Power of Reinforcement Learning . https://qwen.ai/blog?id=qwq-32b
2025
-
[36]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS '22, Red Hook, NY, USA. Curran Associates Inc
2022
-
[37]
Erik Wijmans, Brody Huval, Alexander Hertzberg, Vladlen Koltun, and Philipp Kraehenbuehl. 2025. https://openreview.net/forum?id=E4Fk3YuG56 Cut your losses in large-vocabulary language models . In The Thirteenth International Conference on Learning Representations
2025
-
[38]
Heming Xia, Chak Tou Leong, Wenjie Wang, Yongqi Li, and Wenjie Li. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.165 T oken S kip: Controllable chain-of-thought compression in LLM s . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 3351--3363, Suzhou, China. Association for Computational Linguistics
-
[39]
Silei Xu, Wenhao Xie, Lingxiao Zhao, and Pengcheng He. 2025. https://arxiv.org/abs/2502.18600 Chain of draft: Thinking faster by writing less . Preprint, arXiv:2502.18600
arXiv 2025
-
[40]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025 a . Qwen3 Technical Report . https://arxiv.org/abs/2505.09388v1
Pith/arXiv arXiv 2025
-
[41]
Junjie Yang, Ke Lin, and Xing Yu. 2025 b . https://arxiv.org/abs/2504.03234 Think when you need: Self-adaptive chain-of-thought learning . Preprint, arXiv:2504.03234
arXiv 2025
-
[42]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. https://doi.org/10.18653/v1/P19-1472 HellaSwag : Can a Machine Really Finish Your Sentence ? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 4791--4800, Florence, Italy. Association for Computational Linguistics
-
[43]
Yuxiang Zhang, Zhengxu Yu, Weihang Pan, Zhongming Jin, Qiang Fu, Deng Cai, Binbin Lin, and Jieping Ye. 2026. https://openreview.net/forum?id=Wc1VZ2bVJn Tokensqueeze: Performance-preserving compression for reasoning LLM s . In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.