Automatic Labelling of Speech Translation Errors
Pith reviewed 2026-06-28 01:32 UTC · model grok-4.3
The pith
Text-only and multimodal systems label speech translation errors at roughly half the precision of humans, with direct speech processing required.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose Speech Translation Error Labelling (STEL) as a new task, create an annotation protocol and a small authentic end-to-end evaluation dataset, and show that text-only XCOMET and multimodal Qwen2.5-Omni perform the STEL task at roughly half human precision. Direct speech processing is necessary, and the current text-only and speech-processing systems are complementary in labelling translation-only versus speech-processing errors.
What carries the argument
The STEL task, which uses an annotation protocol and small end-to-end dataset to separate translation-only errors from speech-processing errors in speech translations.
If this is right
- Systems combining text-only and direct-speech approaches can cover both translation and speech-processing error types more completely than either alone.
- Quality estimation for speech translation can now be benchmarked against the STEL protocol and dataset.
- Progress toward human-level automatic error labelling will require models that ingest raw audio rather than text transcripts only.
- The complementary strengths observed imply that hybrid pipelines are a direct next step for ST error detection.
Where Pith is reading between the lines
- Expanding the dataset to more language pairs would test whether the observed complementarity holds beyond the current domain.
- If precision approaches human levels, ST systems could incorporate real-time error flagging for live applications.
- The necessity of direct speech input suggests that future ST architectures should prioritize end-to-end audio models over cascaded text pipelines for error analysis.
Load-bearing premise
The small authentic end-to-end evaluation dataset and the annotation protocol produce reliable, generalizable labels that distinguish translation-only from speech-processing errors without significant annotator bias or domain mismatch.
What would settle it
A replication study on a larger, independently collected end-to-end speech translation dataset that finds substantially different error type distributions or inter-annotator agreement below 80 percent would falsify the reliability of the STEL labels.
Figures


read the original abstract
Errors in speech translations reduce trustworthiness of Speech Translation (ST) systems and can have serious consequences. Yet currently there is no established methodology for evaluating confidence and quality estimation of speech translations. To initiate progress in this direction, we propose Speech Translation Error Labelling (STEL). We create an annotation protocol, a small authentic end-to-end evaluation dataset, and we analyse how existing text-only and speech-processing systems perform the STEL task. Our results show that text-only XCOMET and multimodal LLM Qwen2.5-Omni are able to perform the STEL task in roughly half the precision of humans. We also find that direct speech processing is necessary for the STEL task, and that the current text-only and speech-processing systems are complementary in labelling translation-only vs. speech-processing errors in ST.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Speech Translation Error Labelling (STEL) task to assess error labelling in speech translations. It describes an annotation protocol and a small authentic end-to-end evaluation dataset, then evaluates text-only systems (e.g., XCOMET) and multimodal LLMs (e.g., Qwen2.5-Omni) on STEL, claiming these systems achieve roughly half the precision of humans. The paper further concludes that direct speech processing is necessary for the task and that text-only and speech-processing systems are complementary in labelling translation-only versus speech-processing errors.
Significance. If the dataset and annotations prove reliable, the work would be significant for establishing an initial methodology and baselines for ST quality estimation focused on error source attribution rather than aggregate scores. The creation of the annotation protocol and dataset provides a concrete starting point for the community, and the reported complementarity between text-only and speech-aware systems offers a falsifiable direction for future multimodal model development.
major comments (1)
- [Abstract and evaluation section] Abstract and evaluation section: the abstract reports concrete performance numbers (models at roughly half human precision) and claims about necessity of speech processing and complementarity, but provides no dataset cardinality, inter-annotator agreement, statistical tests, or error bars. The reader's weakest assumption (reliable labels cleanly separating error sources) is load-bearing for all quantitative claims; without these statistics the human baseline cannot be assessed and the relative model scores are uninterpretable.
minor comments (1)
- [Abstract] The abstract could more explicitly define the STEL label set and the precise distinction between translation-only and speech-processing errors to improve readability for readers unfamiliar with the task.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater statistical transparency in the abstract and evaluation section. We agree this information is necessary to properly interpret the quantitative claims and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract and evaluation section] Abstract and evaluation section: the abstract reports concrete performance numbers (models at roughly half human precision) and claims about necessity of speech processing and complementarity, but provides no dataset cardinality, inter-annotator agreement, statistical tests, or error bars. The reader's weakest assumption (reliable labels cleanly separating error sources) is load-bearing for all quantitative claims; without these statistics the human baseline cannot be assessed and the relative model scores are uninterpretable.
Authors: We agree that the abstract and evaluation section should explicitly report dataset cardinality, inter-annotator agreement, statistical tests, and error bars to allow assessment of label reliability and interpretability of model vs. human performance. The manuscript already describes the dataset as small and authentic; in revision we will add the exact cardinality, IAA metrics (e.g., Cohen's kappa), appropriate significance tests, and error bars to both the abstract and the evaluation section. This directly addresses the load-bearing assumption about reliable separation of error sources. revision: yes
Circularity Check
No circularity: empirical evaluation on newly created dataset
full rationale
The paper proposes the STEL task, creates an annotation protocol and small end-to-end dataset, then reports empirical performance of existing text-only and multimodal systems. No equations, fitted parameters, or derivations are present that reduce any prediction or result to its own inputs by construction. No self-citation load-bearing steps or uniqueness theorems are invoked. The central claims rest on direct measurement against human annotations on the new data, making the work self-contained as an experimental report rather than a closed definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotations on the created dataset serve as reliable ground truth for STEL labels.
Reference graph
Works this paper leans on
-
[1]
Hearing to translate: The effectiveness of speech modality integration into llms.Preprint, arXiv:2512.16378. Matt Post and Hieu Hoang. 2025. Effects of automatic alignment on speech translation metrics. InProceed- ings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025), pages 84–92, Vienna, Austria (in-person and online). Ass...
Pith/arXiv arXiv 2025
-
[2]
AI-assisted human evaluation of machine translation. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Asso- ciation for Computational Linguistics: Human Lan- guage Technologies (V olume 1: Long Papers), pages 4936–4950, Albuquerque, New Mexico. Association for Computational Linguistics. Vilém Zouhar and Tom Kocmi. 2026. P...
Pith/arXiv arXiv 2025
-
[3]
Cascades of ASR and LLM for MT:We se- lect Whisper-large-v3 (Radford et al., 2023) as ASR and Gemma3:12b-it-qat as MT (Team et al., 2025) for all directions except for En→He where LLama3:70b (Grattafiori et al.,
2023
-
[4]
We used WhisperX (https://github.com /m-bain/whisperX)
scores better. We used WhisperX (https://github.com /m-bain/whisperX). We used Gemma3 on complete WhisperX seg- ments that fit into 3000 characters. Llama3 processed the whole document in one step
-
[5]
We used the script for chunked inference: https: //github.com/NVIDIA-NeMo/NeMo/blob/ main/examples/asr/asr_chunked_infere nce/aed/speech_to_text_aed_chunked_i nfer.py
End-to-end speech-to-text:Canary-v2-1B (Sekoyan et al., 2025) for all language di- rections except for En→He, for which there is no publicly available end-to-end ST. We used the script for chunked inference: https: //github.com/NVIDIA-NeMo/NeMo/blob/ main/examples/asr/asr_chunked_infere nce/aed/speech_to_text_aed_chunked_i nfer.py
2025
-
[6]
Simultaneous systems:We use SimulStream- ing https://github.com/ufal/SimulStr eaming (Macháˇcek and Polák, 2025) that in- tegrates end-to-end speech-to-text Whisper- large-v3 for Cs→En, and Whisper-large-v3 as En ASR and Tower+-9B (Rei et al., 2025) for En→Cs and En→De, and Gemma2-9B-it for En→He. We selected the ST systems as representatives of state of ...
2025
-
[8]
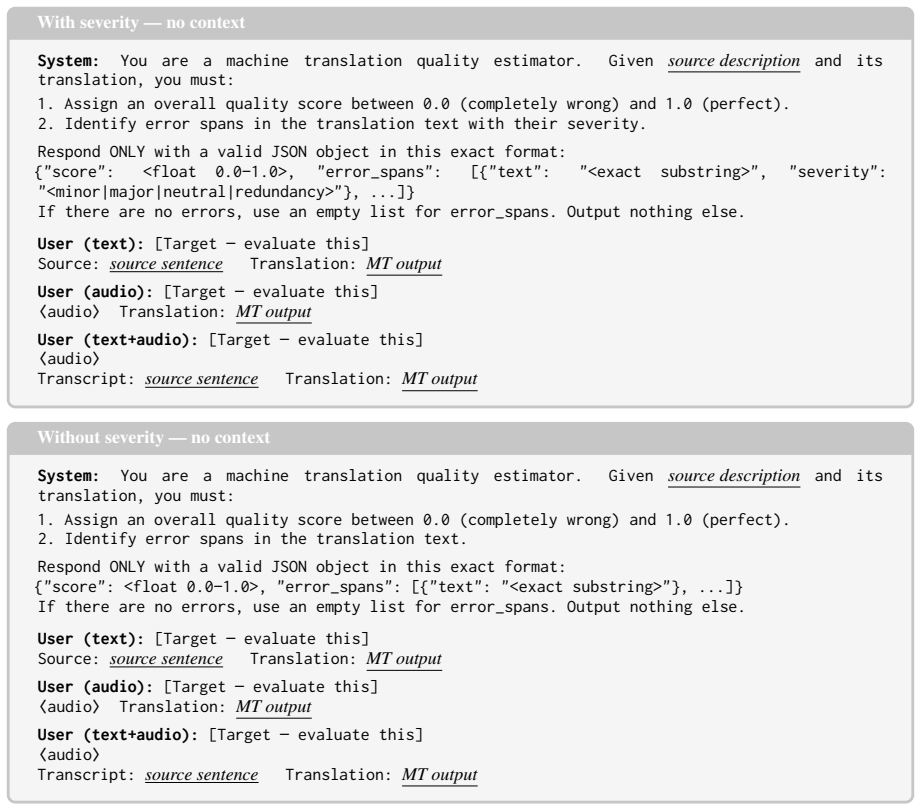
score": <float 0.0–1.0>,
Identify error spans in the translation text with their severity. Respond ONLY with a valid JSON object in this exact format: {"score": <float 0.0–1.0>, "error_spans": [{"text": "<exact substring>", "severity": "<minor|major|neutral|redundancy>"}, ...]} If there are no errors, use an empty list for error_spans. Output nothing else. User (text):[Target — e...
-
[10]
score": <float 0.0–1.0>,
Identify error spans in the translation text. Respond ONLY with a valid JSON object in this exact format: {"score": <float 0.0–1.0>, "error_spans": [{"text": "<exact substring>"}, ...]} If there are no errors, use an empty list for error_spans. Output nothing else. User (text):[Target — evaluate this] Source:source sentence Translation:MT output User (aud...
-
[12]
score": <float 0.0–1.0>,
Evaluate ONLY the target translation (marked [Target]). Identify error spans in the translation text with their severity. Respond ONLY with a valid JSON object in this exact format: {"score": <float 0.0–1.0>, "error_spans": [{"text": "<exact substring>", "severity": "<minor|major|neutral|redundancy>"}, ...]} If there are no errors, use an empty list for e...
-
[13]
Assign an overall quality score between 0.0 (completely wrong) and 1.0 (perfect)
-
[14]
score": <float 0.0–1.0>,
Evaluate ONLY the target translation (marked [Target]). Identify error spans in the translation text. Respond ONLY with a valid JSON object in this exact format: {"score": <float 0.0–1.0>, "error_spans": [{"text": "<exact substring>"}, ...]} If there are no errors, use an empty list for error_spans. Output nothing else. User messages identical to the with...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.