A Conversational Framework for Human-Robot Collaborative Manipulation with Distributed Generative AI models
Pith reviewed 2026-06-28 01:29 UTC · model grok-4.3
The pith
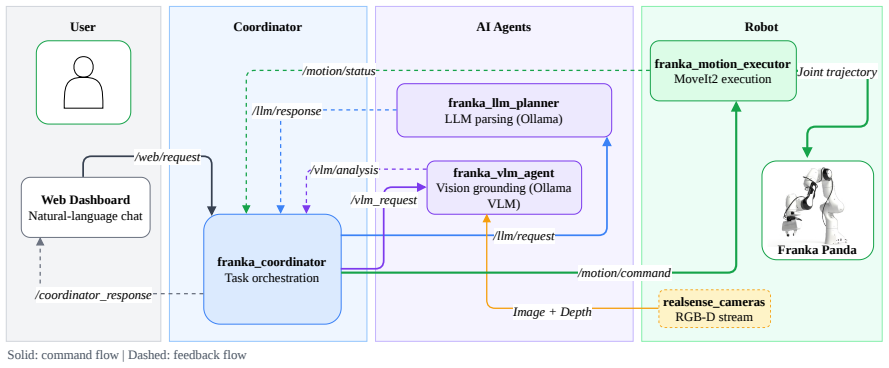
A distributed ROS 2 framework converts free-form user commands into confirmed pick-place-handover robot motions using local LLMs and VLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The framework separates language parsing, visual grounding via VLM, action orchestration, and safe execution into independent ROS 2 nodes that communicate across hardware, allowing free-form commands to produce metric robot goals while a web interface requires operator approval of every proposed motion before execution.
What carries the argument
ROS 2 node pipeline that uses a local LLM to parse intent into structured pick/place/handover requests and a VLM to return image-space targets that are then lifted to robot-frame goals via depth and calibration, with a web dashboard enforcing explicit confirmation.
If this is right
- Structured action requests for pick, place, and handover can be produced directly from free-form user speech.
- VLM image targets are converted into metric robot-frame goals using depth and extrinsic calibration.
- A web dashboard that displays intent and grounding overlays (pixel, depth, robot-frame) allows explicit operator confirmation before motion.
- End-to-end task reliability and latency can be measured while varying scene ambiguity and swapping LLM or VLM back-ends.
- The node-based architecture supports flexible deployment across separate computers while keeping a responsive control loop.
Where Pith is reading between the lines
- The same node separation could support adding new action types or additional sensors without rewriting the core orchestration logic.
- Because confirmation happens after grounding but before motion, the framework could be extended to log every proposed versus executed action for later analysis of model errors.
- If local models improve, the confirmation step might become optional for low-ambiguity scenes while remaining mandatory for high-ambiguity ones.
Load-bearing premise
The local language and vision models will generate targets and action sequences accurate enough that requiring a human to confirm each step on the dashboard is sufficient to keep execution safe and reliable even when scenes become ambiguous.
What would settle it
Run the system on the Franka FR3 with progressively cluttered tables and record whether the fraction of tasks completed without collision or incorrect grasp drops sharply once scene ambiguity exceeds the levels shown in the paper's experiments.
Figures



read the original abstract
This paper presents a distributed conversational framework for human-robot collaborative manipulation that integrates local language and vision-language models (VLMs) with a Robot Operating System 2 (ROS 2)-based execution stack. Language understanding, visual grounding, orchestration, and motion execution run as separate ROS 2 nodes, enabling flexible deployment across distributed hardware while maintaining a responsive control loop. From free-form user commands, the system generates structured action requests for pick, place, and handover. It uses a VLM to return image-space targets, which are converted into metric robot-frame goals using depth and calibration. A web dashboard exposes intermediate intent and grounding overlays (pixel, depth, and robot-frame) and requires explicit operator confirmation before any motion is executed. Experiments on a Franka FR3 platform evaluate end-to-end task reliability and latency under increasing working table scene ambiguity and compare alternative LLM/VLM configurations in the same pipeline. Code and full documentation are available at [github.com/cogrob-tuni/franka-llm](https://github.com/cogrob-tuni/franka-llm).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper presents a distributed conversational framework for human-robot collaborative manipulation that integrates local LLMs and VLMs with a ROS 2 execution stack. From free-form user commands the system generates structured pick/place/handover requests; a VLM supplies image-space targets that are converted to metric robot-frame goals via depth and calibration. A web dashboard displays intermediate results and requires explicit operator confirmation before motion. Experiments on a Franka FR3 platform are described as evaluating end-to-end task reliability and latency under increasing scene ambiguity while comparing alternative LLM/VLM configurations.
Significance. If the reported experiments demonstrate reliable performance independent of operator oversight, the work would provide a practical, deployable example of distributed generative models in collaborative robotics with built-in safety via confirmation. The open-source code and documentation are positive attributes that could aid reproducibility.
major comments (2)
- [Abstract] Abstract: the statement that experiments 'evaluate end-to-end task reliability and latency under increasing working table scene ambiguity' is unsupported by any quantitative results, success criteria, error rates, or statistical details in the manuscript, so the central empirical claim remains unevidenced.
- [Experiments] Experiments description: reliability is assessed only on executions that pass the dashboard confirmation step; this conflates VLM/LLM grounding accuracy with human oversight and does not isolate model error frequency, false-positive action requests, or confirmation rejection rates, leaving the weakest assumption (that model outputs are sufficiently accurate for confirmation to suffice) untested.
minor comments (1)
- [System description] The conversion from image-space targets to robot-frame goals via depth and calibration is described but not analyzed for sensitivity to calibration drift or depth noise under the ambiguity conditions claimed in the experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the empirical claims and experimental design. We address each major comment below and will revise the manuscript accordingly to ensure accuracy and clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that experiments 'evaluate end-to-end task reliability and latency under increasing working table scene ambiguity' is unsupported by any quantitative results, success criteria, error rates, or statistical details in the manuscript, so the central empirical claim remains unevidenced.
Authors: We agree that the abstract overstates the quantitative support for the evaluation. The manuscript describes the experimental setup, task variations with scene ambiguity, and comparisons across LLM/VLM configurations, but does not present the specific success rates, latency statistics, error metrics, or success criteria referenced in the abstract. We will revise the abstract to accurately describe the experiments as a qualitative and comparative demonstration of the framework under varying conditions, without claiming unsupported quantitative evaluation of reliability. revision: yes
-
Referee: [Experiments] Experiments description: reliability is assessed only on executions that pass the dashboard confirmation step; this conflates VLM/LLM grounding accuracy with human oversight and does not isolate model error frequency, false-positive action requests, or confirmation rejection rates, leaving the weakest assumption (that model outputs are sufficiently accurate for confirmation to suffice) untested.
Authors: The referee correctly notes that the reported reliability figures apply only to tasks that received operator confirmation via the dashboard. This is an intentional safety feature of the framework, but it does mean the evaluation measures combined system-plus-human performance rather than isolating model grounding accuracy, false-positive rates, or rejection statistics. We will revise the experiments section to explicitly state this scope, clarify that the results do not claim standalone model reliability, and add a discussion of this limitation. If raw logs of confirmation rejections were recorded during the trials, we will include summary statistics; otherwise the text will note the absence of such isolated metrics. revision: yes
Circularity Check
No circularity: system description with external experimental evaluation
full rationale
The paper presents a distributed ROS 2 framework for human-robot collaboration using local LLMs and VLMs. Claims concern end-to-end task reliability and latency measured on a Franka FR3 platform under varying scene ambiguity, with explicit operator confirmation via dashboard. No mathematical derivations, fitted parameters renamed as predictions, self-citations as load-bearing uniqueness theorems, or ansatzes appear in the provided text. Evaluation relies on physical experiments rather than construction from inputs, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
TiPToP: A Modular Open-V ocabulary Planning System for Robotic Manipulation,
W. Shenet al., “TiPToP: A Modular Open-V ocabulary Planning System for Robotic Manipulation,”arXiv preprint arXiv:2603.09971, 2026
arXiv 2026
-
[2]
An LLM-based approach for enabling seamless Human-Robot collaboration in assembly,
C. Gkournelos, C. Konstantinou, and S. Makris, “An LLM-based approach for enabling seamless Human-Robot collaboration in assembly,”CIRP Annals, vol. 73, no. 1, pp. 9–12, 2024. [Online]. Available: https://doi.org/10.1016/j.cirp.2024.04.002
-
[3]
Copilot: A framework for integrating LLM and BMI to enhance human–robot interaction,
S. Liuet al., “Copilot: A framework for integrating LLM and BMI to enhance human–robot interaction,”Robotics and Computer-Integrated Manufacturing, vol. 101, p. 103291, 2026. [Online]. Available: https://doi.org/10.1016/j.rcim.2026.103291
-
[4]
Vision AI-based human-robot collaborative assembly driven by autonomous robots,
S. Liu, J. Zhang, L. Wang, and R. X. Gao, “Vision AI-based human-robot collaborative assembly driven by autonomous robots,” CIRP Annals, vol. 73, no. 1, pp. 13–16, 2024. [Online]. Available: https://doi.org/10.1016/j.cirp.2024.03.004
-
[5]
Steerable Vision-Language-Action Policies for Embodied Reasoning and Hierarchical Control,
W. Chenet al., “Steerable Vision-Language-Action Policies for Embodied Reasoning and Hierarchical Control,” 2026. [Online]. Available: https://arxiv.org/abs/2602.13193
Pith/arXiv arXiv 2026
-
[6]
Robot operating system 2: Design, architecture, and uses in the wild,
S. Macenski, T. Foote, B. Gerkey, C. Lalancette, and W. Woodall, “Robot operating system 2: Design, architecture, and uses in the wild,” Science Robotics, vol. 7, no. 66, 2022
2022
-
[7]
Impact of ROS 2 node composition in robotic systems,
S. Macenski, A. Soragna, M. Carroll, and Z. Ge, “Impact of ROS 2 node composition in robotic systems,”IEEE Robotics and Automation Letters, vol. 8, no. 7, pp. 3996–4003, 2023
2023
-
[8]
Empowering edge intelligence: A comprehensive survey on on-device AI models,
X. Wanget al., “Empowering edge intelligence: A comprehensive survey on on-device AI models,”ACM Comput. Surv., vol. 57, no. 9, 2025
2025
-
[9]
Survey of hallucination in natural language generation,
Z. Jiet al., “Survey of Hallucination in Natural Language Generation,” ACM Computing Surveys, vol. 55, no. 12, 2023. [Online]. Available: https://doi.org/10.1145/3571730
-
[10]
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions,
L. Huanget al., “A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions,” ACM Transactions on Information Systems, vol. 43, no. 2, 2025
2025
-
[11]
P. Maithani, A. Arab, F. Khorrami, and P. Krishnamurthy, “Proactive hierarchical control barrier function-based constraint prioritization to enhance safety in human-robot interaction,”Control Engineering Practice, vol. 166, p. 106624, 2025. [Online]. Available: https://doi.org/10.1016/j.conengprac.2025.106624
-
[12]
MARVL: Multi-Stage Guidance for Robotic Manipulation via Vision-Language Models,
X. Zhouet al., “MARVL: Multi-Stage Guidance for Robotic Manipulation via Vision-Language Models,” 2026. [Online]. Available: https://arxiv.org/abs/2602.15872
Pith/arXiv arXiv 2026
-
[13]
A. Sharma, D. Sharma, J. Rebeiro, P. Thakur, N. Dhar, and L. Behera, “Instruct2Act: From Human Instruction to Actions Sequencing and Execution via Robot Action Network for Robotic Manipulation,”arXiv preprint arXiv:2602.09940, 2026
arXiv 2026
-
[14]
You only look once: Uni- fied, real-time object detection
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 779–788. [Online]. Available: https://doi.org/10.1109/CVPR.2016.91
-
[15]
Franka research robots,
Franka Robotics GmbH, “Franka research robots,” https://franka.de/, 2026
2026
-
[16]
PickNik Robotics, “Moveit,” https://moveit.picknik.ai/, 2026
2026
-
[17]
Ollama, “Ollama,” https://ollama.com/, 2026
2026
-
[18]
ministral-3:8b,
Mistral AI, “ministral-3:8b,” https://ollama.com/library/ministral-3:8b, 2026
2026
-
[19]
Qwen2.5-VL 32B,
Alibaba Cloud, “Qwen2.5-VL 32B,” https://ollama.com/library/qwe n2.5vl:32b, 2026
2026
-
[20]
Intel realsense depth cameras,
Intel, “Intel realsense depth cameras,” https://realsenseai.com/, 2026
2026
-
[21]
The OpenCV Library,
G. Bradski, “The OpenCV Library,”Dr . Dobb’s Journal of Software Tools, 2000
2000
-
[22]
Szeliski,Computer Vision: Algorithms and Applications, 2nd ed
R. Szeliski,Computer Vision: Algorithms and Applications, 2nd ed. Springer, 2022. [Online]. Available: https://link.springer.com/book/1 0.1007/978-3-030-34372-9
2022
-
[23]
ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras,
R. Mur-Artal and J. D. Tard ´os, “ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras,”IEEE Transactions on Robotics, vol. 33, no. 5, pp. 1255–1262, 2017. [Online]. Available: https://doi.org/10.1109/TRO.2017.2705103
-
[24]
Llama 3 8B,
Meta AI, “Llama 3 8B,” https://ollama.com/library/llama3:8b, 2026
2026
-
[25]
Qwen2.5 7B,
Alibaba Cloud, “Qwen2.5 7B,” https://ollama.com/library/qwen2.5:7b, 2026
2026
-
[26]
Llama 3.2 Vision 90B,
Meta AI, “Llama 3.2 Vision 90B,” https://ollama.com/library/llama3. 2-vision:90b, 2026
2026
-
[27]
DeepSeek-R1 7B,
DeepSeek AI, “DeepSeek-R1 7B,” https://ollama.com/library/deepsee k-r1:7b, 2026
2026
-
[28]
LLaV A 7B,
Haotian Liu and others, “LLaV A 7B,” https://ollama.com/library/llava: 7b, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.