Deep reinforcement learning with spatial and temporal awareness for active boundary control of buoyancy-driven convection
Pith reviewed 2026-06-27 23:39 UTC · model grok-4.3
The pith
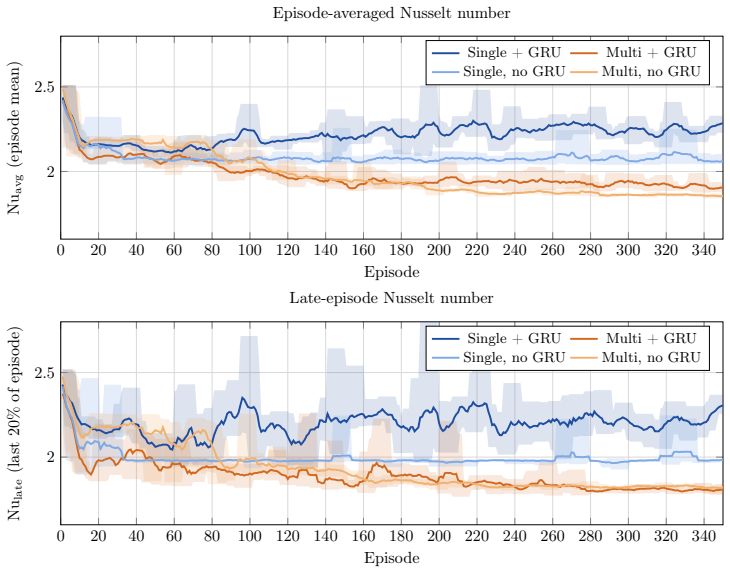
Convolutional recurrent DRL policies achieve convection cell coalescence with single agents, reducing Nu by 26%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
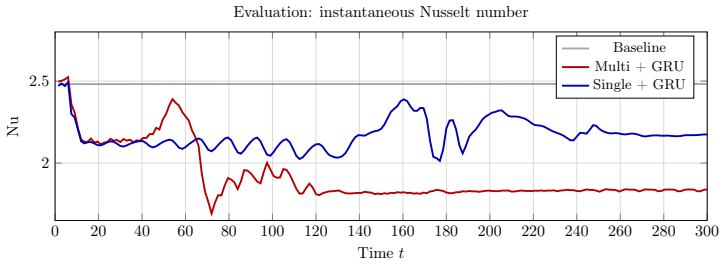
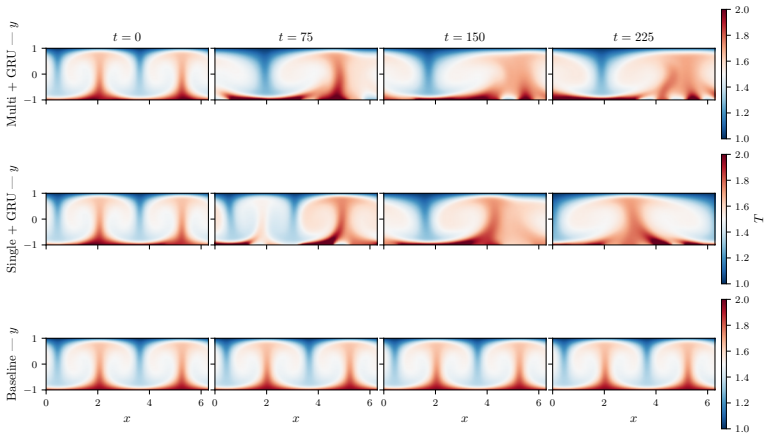
The four design choices—convolutional policy networks, GRU memory, off-policy training, and action-smoothness constraints—enable DRL agents to learn physically meaningful boundary actuation that induces cell coalescence, achieving a 26% reduction in Nu to 1.83, and this holds for single-agent configurations on Rayleigh-Benard convection while also yielding traveling-wave policies in the salt-finger regime.
What carries the argument
Convolutional policy networks combined with GRU memory and action-smoothness constraints, which provide spatial awareness of the flow structure and temporal distinction of self-induced changes.
If this is right
- Cell coalescence occurs across all four tested configurations in 350 episodes.
- Nu is reduced to as low as 1.83, 26% below baseline, without full-field data augmentation.
- Single-agent control suffices once policy architecture includes spatial and temporal awareness.
- The framework discovers phase-adaptive traveling-wave actuation in double-diffusive convection, enhancing heat transfer by 19.1% and reducing salinity variance by 21.0%.
Where Pith is reading between the lines
- Similar design choices may enable effective control in other fluid systems where spatial and temporal flow features matter.
- Testing the policies in experiments or higher Rayleigh number simulations would confirm if the discovered laws generalize beyond the simulated Ra=10000.
- The success of single-agent over multi-agent suggests that expressiveness of the policy network can substitute for distributed agents in some control tasks.
- Action smoothness may be key to avoiding degenerate saturated or random policies in continuous control problems.
Load-bearing premise
The numerical simulation of the flow at Ra=10000 accurately captures the accessible physics of cell coalescence under boundary actuation.
What would settle it
A direct numerical simulation or laboratory experiment at the same Rayleigh number where the learned policies fail to induce observable cell coalescence would falsify the claim.
Figures

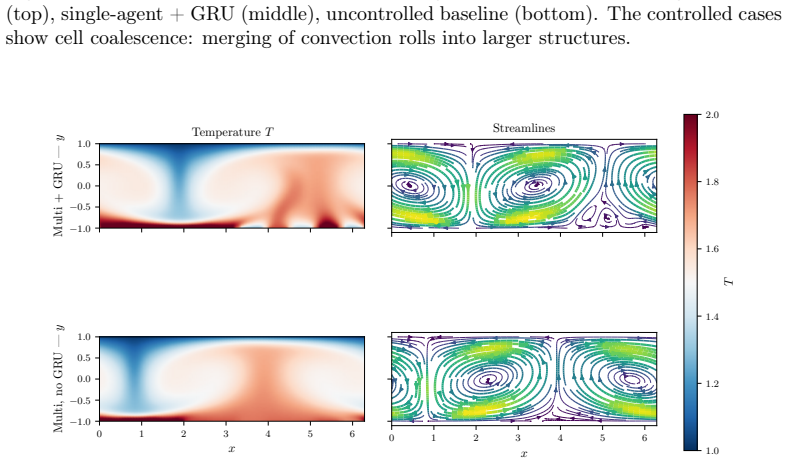
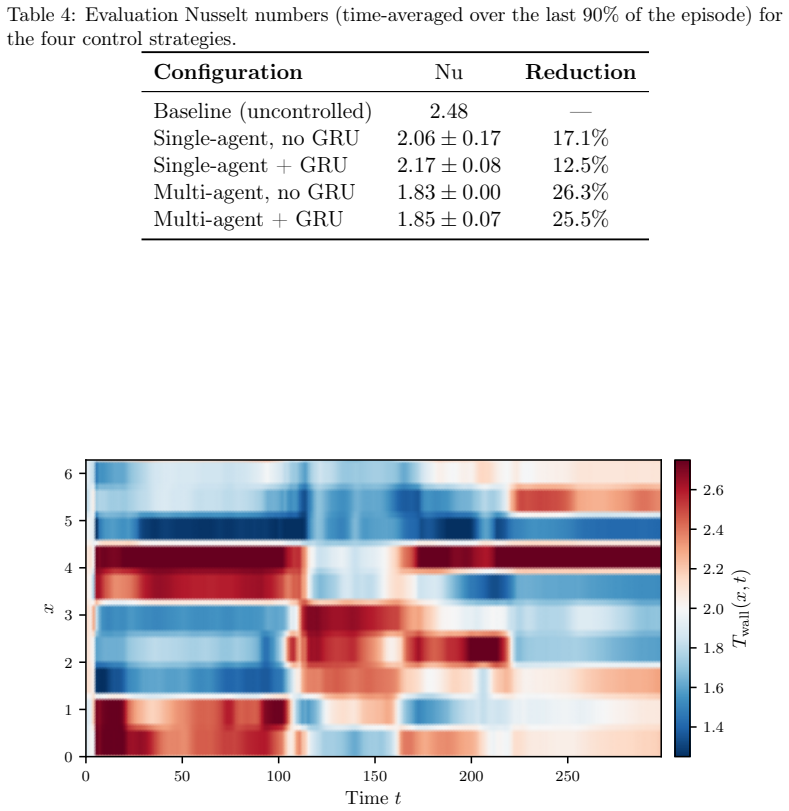


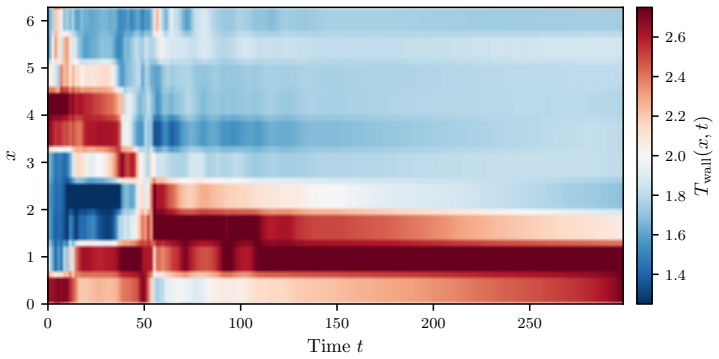


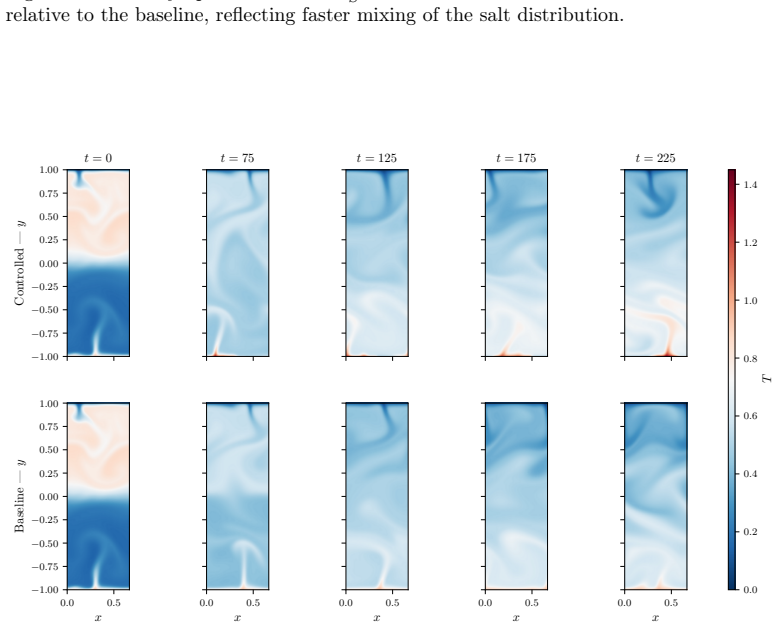
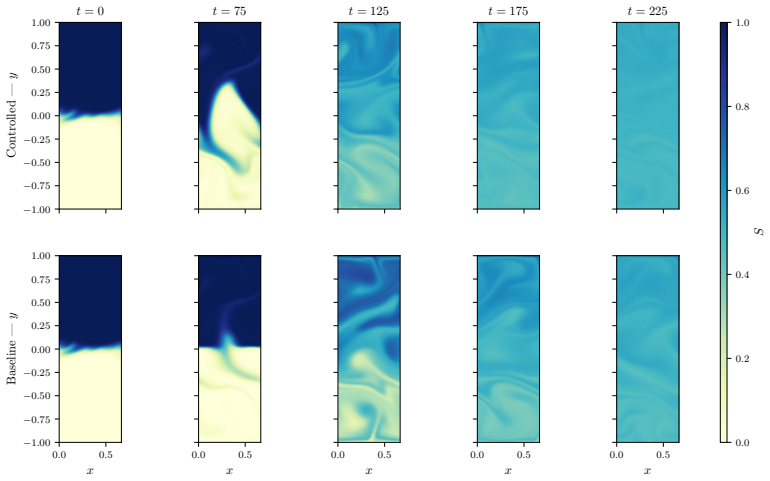

read the original abstract
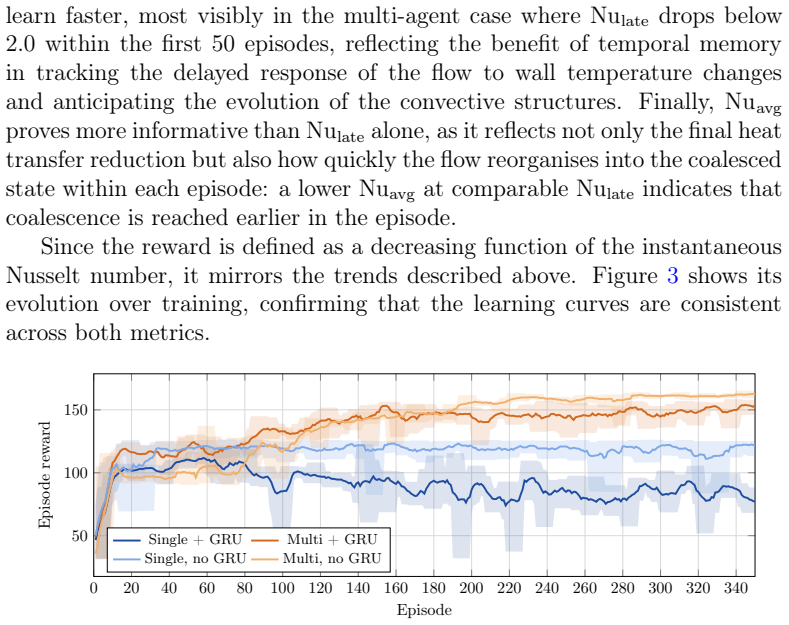
Deep reinforcement learning (DRL) applied to thermal convection control consistently produces \textit{degenerate actuation}: wall-temperature policies whose outputs are saturated, pseudo-random, or spatially incoherent. Two compounding deficiencies are responsible: multilayer-perceptron policies that discard spatial flow structure, and memoryless policies that cannot distinguish self-induced flow changes from background evolution. Together they prevent the discovery of physically meaningful control laws even when cell coalescence (the merging of convection rolls into fewer, larger structures), which would reduce $\mathrm{Nu}$, is accessible to boundary actuation. The present framework addresses both causes through four targeted design choices: convolutional policy networks, Gated Recurrent Unit (GRU) memory, off-policy training (TD3/MADDPG), and action-smoothness constraints. A systematic $2\times2$ factorial design isolates the contribution of each component. On Rayleigh--B\'{e}nard convection at $\mathrm{Ra}=10{,}000$, all four configurations achieve cell coalescence and reduce $\mathrm{Nu}$ to as low as $1.83$ ($26\%$ below the uncontrolled baseline) in 350 episodes, without the full-field data augmentation required by prior work. Crucially, coalescence is achieved even by the single-agent configuration, demonstrating that the multi-agent formulation is not a prerequisite once the policy architecture is sufficiently expressive. Applied to double-diffusive convection in the salt-finger regime, the framework spontaneously discovers a travelling-wave actuation whose phase speed adapts to the evolving mixing state of the flow, enhancing heat transfer by $19.1\%$ and reducing salinity variance by $21.0\%$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that four design choices—convolutional policy networks, GRU memory, off-policy training (TD3/MADDPG), and action-smoothness constraints—enable DRL agents to discover physically meaningful control laws for buoyancy-driven flows. A 2×2 factorial design on Rayleigh-Bénard convection at Ra=10,000 shows that all four configurations achieve cell coalescence, reducing Nu to as low as 1.83 (26% below the uncontrolled baseline) after 350 episodes without requiring full-field data augmentation; crucially, this holds even for the single-agent case. The same framework applied to double-diffusive convection in the salt-finger regime spontaneously produces an adaptive travelling-wave actuation that increases heat transfer by 19.1% while reducing salinity variance by 21.0%.
Significance. If the reported quantitative outcomes are statistically robust, the work would establish that targeted spatial-temporal awareness in policy architectures suffices to avoid degenerate actuation and recover interpretable control strategies such as cell coalescence and phase-speed adaptation. The single-agent success and avoidance of full-field augmentation would reduce the perceived necessity of multi-agent formulations in prior DRL fluid-control studies. The systematic 2×2 design offers a structured attribution of component contributions, which is a methodological strength when properly validated.
major comments (2)
- [Abstract] Abstract: the central quantitative claims (Nu reduced to 1.83, 26% reduction; 19.1% heat-transfer increase) are stated without error bars, multi-seed statistics, convergence diagnostics, or hyperparameter-sensitivity results. This directly affects the load-bearing assertion that every configuration in the 2×2 design reliably produces coalescence and that the four components can be isolated.
- [Description of the 2×2 factorial design] Description of the 2×2 factorial design: no tests for factor interactions, seed dependence, or alternative baselines are reported. Given known strong interactions between policy architecture and learning algorithm in DRL, this leaves the attribution of coalescence success (especially the single-agent result) under-determined and prevents confirmation that the design choices, rather than shared factors such as reward shaping or episode length, are responsible.
minor comments (1)
- [Abstract] The abstract contains inline LaTeX markup (\textit, \mathrm) that should be rendered consistently in the published version.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater statistical rigor and clearer attribution in our experimental design. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central quantitative claims (Nu reduced to 1.83, 26% reduction; 19.1% heat-transfer increase) are stated without error bars, multi-seed statistics, convergence diagnostics, or hyperparameter-sensitivity results. This directly affects the load-bearing assertion that every configuration in the 2×2 design reliably produces coalescence and that the four components can be isolated.
Authors: We agree that the abstract and results sections present point estimates without accompanying statistical measures such as error bars or multi-seed averages. While the reported outcomes reflect consistent behavior across the tested configurations, the absence of these diagnostics weakens the claim of reliability. We will revise the manuscript to include multi-seed statistics (at least three independent seeds per configuration), standard deviations, convergence diagnostics for the key metrics (Nu, heat transfer, salinity variance), and a brief hyperparameter sensitivity note. These additions will be placed in the results section and referenced in the abstract. revision: yes
-
Referee: [Description of the 2×2 factorial design] Description of the 2×2 factorial design: no tests for factor interactions, seed dependence, or alternative baselines are reported. Given known strong interactions between policy architecture and learning algorithm in DRL, this leaves the attribution of coalescence success (especially the single-agent result) under-determined and prevents confirmation that the design choices, rather than shared factors such as reward shaping or episode length, are responsible.
Authors: The 2×2 design was constructed to compare the presence or absence of each component while holding other elements fixed, and the uniform success in achieving coalescence supports the contribution of the proposed choices. Nevertheless, we acknowledge that formal tests for interactions, explicit seed-dependence analysis, and additional baselines (e.g., alternative reward formulations) are not provided. We will add a dedicated subsection discussing potential interactions between architecture and algorithm, report results across multiple random seeds to quantify variability, and include a short comparison against a simple baseline policy to strengthen attribution. We maintain that the single-agent result is enabled by the spatial-temporal policy components, but the expanded analysis will make this clearer. revision: partial
Circularity Check
No circularity: empirical DRL outcomes are direct simulation measurements
full rationale
The paper reports observed Nusselt-number reductions and cell-coalescence events obtained from direct numerical simulations of the controlled flow at Ra=10,000. These quantities are measured outputs of the DRL-trained policies; they are not algebraically or statistically forced by any fitted parameter, self-referential normalization, or ansatz internal to the paper. The 2×2 factorial is an experimental design whose results (success in all four cells, single-agent coalescence) stand as independent evidence rather than a renaming or re-derivation of the design choices themselves. No load-bearing self-citation or uniqueness theorem is invoked to close the argument.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Boussinesq approximation and incompressible Navier-Stokes equations govern the buoyancy-driven flow in the numerical simulation
Reference graph
Works this paper leans on
-
[1]
, author Koumoutsakos, P
author Bae, H.J. , author Koumoutsakos, P. , year 2022 . title Scientific multi-agent reinforcement learning for wall-models of turbulent flows . journal Nature Communications volume 13 , pages 1443
2022
-
[2]
, author Corbetta, A
author Beintema, G. , author Corbetta, A. , author Biferale, L. , author Toschi, F. , year 2020 . title Controlling Rayleigh--B\'enard convection via reinforcement learning . journal Journal of Turbulence volume 21 , pages 585--605
2020
-
[3]
Improving turbulence control through explainable deep learning
author Beneitez, M. , author Cremades, A. , author Guastoni, L. , author Vinuesa, R. , year 2025 . title Improving turbulence control through explainable deep learning . journal arXiv preprint arXiv:2504.02354
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
, author Noack, B.R
author Brunton, S.L. , author Noack, B.R. , author Koumoutsakos, P. , year 2020 . title Machine learning for fluid mechanics . journal Annual Review of Fluid Mechanics volume 52 , pages 477--508
2020
-
[5]
, author Guastoni, L
author Cavallazzi, G.M. , author Guastoni, L. , author Vinuesa, R. , author Pinelli, A. , year 2025 . title Deep reinforcement learning for the management of the wall regeneration cycle in wall-bounded turbulent flows . journal Flow, Turbulence and Combustion volume 115 , pages 1291--1317
2025
-
[6]
, author Constante-Amores, C.R
author Chen, Q. , author Constante-Amores, C.R. , year 2025 . title Stabilizing Rayleigh--B\'enard convection with reinforcement learning trained on a reduced-order model . journal arXiv preprint arXiv:2510.26705
-
[7]
, author van Merrienboer, B
author Cho, K. , author van Merrienboer, B. , author Gulcehre, C. , author Bahdanau, D. , author Bougares, F. , author Schwenk, H. , author Bengio, Y. , year 2014 . title Learning phrase representations using RNN encoder--decoder for statistical machine translation , in: booktitle Proceedings of the 2014 Conference on Empirical Methods in Natural Language...
2014
-
[8]
, author Alc \'a ntara- \'A vila, F
author Font, B. , author Alc \'a ntara- \'A vila, F. , author Rabault, J. , author Vinuesa, R. , author Lehmkuhl, O. , year 2025 . title Deep reinforcement learning for active flow control in a turbulent separation bubble . journal Nature Communications volume 16 , pages 1422
2025
-
[9]
, author van Hoof, H
author Fujimoto, S. , author van Hoof, H. , author Meger, D. , year 2018 . title Addressing function approximation error in actor-critic methods , in: booktitle Proceedings of the 35th International Conference on Machine Learning (ICML) , pp. pages 1587--1596
2018
-
[10]
, author Mir\'o, A
author Garcia, X. , author Mir\'o, A. , author Su\'arez, P. , author Alc\'antara-\'Avila, F. , author Rabault, J. , author Font, B. , author Lehmkuhl, O. , author Vinuesa, R. , year 2025 . title Deep-reinforcement-learning-based separation control in a two-dimensional airfoil . journal International Journal of Heat and Fluid Flow volume 116 , pages 109913
2025
-
[11]
, author Viquerat, J
author Garnier, P. , author Viquerat, J. , author Rabault, J. , author Larcher, A. , author Kuhnle, A. , author Hachem, E. , year 2021 . title A review on deep reinforcement learning for fluid mechanics . journal Computers & Fluids volume 225 , pages 104973
2021
-
[12]
, author Rabault, J
author Guastoni, L. , author Rabault, J. , author Schlatter, P. , author Azizpour, H. , author Vinuesa, R. , year 2023 . title Deep reinforcement learning for turbulent drag reduction in channel flows . journal The European Physical Journal E volume 46 , pages 27
2023
-
[13]
, author Schmidhuber, J
author Hochreiter, S. , author Schmidhuber, J. , year 1997 . title Long short-term memory . journal Neural Computation volume 9 , pages 1735--1780
1997
-
[14]
author Holme, K. , author Rabault, J. , author Vinuesa, R. , author Mortensen, M. , year 2026 . title Timescale separation enables deep reinforcement learning control of rotating detonation engine mode transitions . journal arXiv preprint arXiv:2604.14398
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
, author Xu, H
author Jia, W. , author Xu, H. , year 2025 . title State-augmented deep reinforcement learning for active flow control around an elliptical cylinder . journal International Journal of Heat and Fluid Flow volume 116 , pages 109950
2025
-
[16]
, author Yousif, M.Z
author Jiren, M. , author Yousif, M.Z. , author Song, J. , author Lim, H.C. , year 2025 . title A comprehensive review of control strategies for Rayleigh--B\'enard convection from classical feedback methods to artificial intelligence-driven optimization . journal Physics of Fluids volume 37 , pages 101304
2025
-
[17]
, author Ostrovski, G
author Kapturowski, S. , author Ostrovski, G. , author Quan, J. , author Munos, R. , author Dabney, W. , year 2019 . title Recurrent experience replay in distributed reinforcement learning , in: booktitle International Conference on Learning Representations
2019
-
[18]
, author Roovers, R
author Kenjere s , S. , author Roovers, R. , year 2025 . title Modulation of the local mass and heat transfer of turbulent double-diffusive convection under stable thermal stratifications . journal International Journal of Heat and Fluid Flow volume 111 , pages 109636
2025
-
[19]
, author Kaushik, R
author Kurz, M. , author Kaushik, R. , author Blind, M. , author Kopper, P. , author Schwarz, A. , author Rodach, F. , author Beck, A. , year 2025 . title Invariant control strategies for active flow control using graph neural networks . journal Computers and Fluids volume 303 , pages 106854
2025
-
[20]
, author Hunt, J.J
author Lillicrap, T.P. , author Hunt, J.J. , author Pritzel, A. , author Heess, N. , author Erez, T. , author Tassa, Y. , author Silver, D. , author Wierstra, D. , year 2016 . title Continuous control with deep reinforcement learning . journal International Conference on Learning Representations (ICLR)
2016
-
[21]
, author Wu, Y
author Lowe, R. , author Wu, Y. , author Tamar, A. , author Harb, J. , author Abbeel, P. , author Mordatch, I. , year 2017 . title Multi-agent actor-critic for mixed cooperative-competitive environments , in: booktitle Advances in Neural Information Processing Systems (NeurIPS) , pp. pages 6382--6393
2017
-
[22]
author Markmann, T. , author Straat, M. , author Peitz, S. , author Hammer, B. , year 2025 . title Control of Rayleigh--B\'enard convection: effectiveness of reinforcement learning in the turbulent regime . journal arXiv preprint arXiv:2504.12000
-
[23]
, author Mabsout, B
author Mysore, S. , author Mabsout, B. , author Mancuso, R. , author Saenko, K. , year 2021 . title Regularizing action policies for smooth control with reinforcement learning , in: booktitle 2021 IEEE International Conference on Robotics and Automation (ICRA) , pp. pages 1810--1816
2021
-
[24]
, author Kuchta, M
author Rabault, J. , author Kuchta, M. , author Jensen, A. , author R \'e glade, U. , author Cerardi, N. , year 2019 . title Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control . journal Journal of Fluid Mechanics volume 865 , pages 281--302
2019
-
[25]
, author Peet, Y.T
author Sakievich, P.J. , author Peet, Y.T. , author Adrian, R.J. , year 2016 . title Large-scale thermal motions of turbulent Rayleigh--B\'enard convection in a wide aspect-ratio cylindrical domain . journal International Journal of Heat and Fluid Flow volume 61 , pages 183--196
2016
-
[26]
, author Lever, G
author Silver, D. , author Lever, G. , author Heess, N. , author Degris, T. , author Wierstra, D. , author Riedmiller, M. , year 2014 . title Deterministic policy gradient algorithms , in: booktitle Proceedings of the 31st International Conference on Machine Learning (ICML) , pp. pages 387--395
2014
-
[27]
, year 1960
author Stern, M.E. , year 1960 . title The ``salt-fountain'' and thermohaline convection . journal Tellus volume 12 , pages 172--175
1960
-
[28]
, author Alc \'a ntara- \'A vila, F
author Su \'a rez, P. , author Alc \'a ntara- \'A vila, F. , author Font, B. , author Lehmkuhl, O. , author Vinuesa, R. , year 2025 a. title Flow control of three-dimensional cylinders transitioning to turbulence via multi-agent reinforcement learning . journal Communications Engineering volume 4 , pages 113
2025
-
[29]
, author Alc \'a ntara- \'A vila, F
author Su \'a rez, P. , author Alc \'a ntara- \'A vila, F. , author Miro, A. , author Rabault, J. , author Font, B. , author Lehmkuhl, O. , author Vinuesa, R. , year 2025 b. title Active flow control for drag reduction through multi-agent reinforcement learning on a turbulent cylinder at Re_D = 3900 . journal Flow, Turbulence and Combustion volume 115 , p...
2025
-
[30]
, year 1974
author Turner, J.S. , year 1974 . title Double-diffusive phenomena . journal Annual Review of Fluid Mechanics volume 6 , pages 37--56
1974
-
[31]
, year 1986
author Van Kan, J. , year 1986 . title A second-order accurate pressure-correction scheme for viscous incompressible flow . journal SIAM journal on scientific and statistical computing volume 7 , pages 870--891
1986
-
[32]
, author Rabault, J
author Vasanth, J. , author Rabault, J. , author Alc \'a ntara- \'A vila, F. , author Mortensen, M. , author Vinuesa, R. , year 2025 . title Multi-agent reinforcement learning for the control of three-dimensional Rayleigh--B\'enard convection . journal Flow, Turbulence and Combustion volume 115 , pages 1319--1355
2025
-
[33]
, author Rabault, J
author Vignon, C. , author Rabault, J. , author Vasanth, J. , author Alc \'a ntara- \'A vila, F. , author Mortensen, M. , author Vinuesa, R. , year 2023 . title Effective control of two-dimensional Rayleigh--B\'enard convection: invariant multi-agent reinforcement learning is all you need . journal Physics of Fluids volume 35 , pages 065146
2023
-
[34]
, author Brunton, S.L
author Vinuesa, R. , author Brunton, S.L. , year 2022 . title Enhancing computational fluid dynamics with machine learning . journal Nature Computational Science volume 2 , pages 358--366
2022
-
[35]
, author He, X.J
author Wang, Y.Z. , author He, X.J. , author Hua, Y. , author Chen, Z.H. , author Wu, W.T. , author Zhou, Z.F. , year 2023 . title Closed-loop forced heat convection control using deep reinforcement learning . journal International Journal of Heat and Mass Transfer volume 202 , pages 123655
2023
-
[36]
, author Peng, J.Z
author Wang, Y.Z. , author Peng, J.Z. , author Aubry, N. , author Li, Y.B. , author Chen, Z.H. , author Wu, W.T. , year 2024 . title Control policy transfer of deep reinforcement learning based intelligent forced heat convection control . journal International Journal of Thermal Sciences volume 195 , pages 108618
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.