VOLT: Vision and Language Trajectory Segmentation for Faster-than-Demonstration Policies
Pith reviewed 2026-06-28 00:46 UTC · model grok-4.3
The pith
Vision and language cues from demonstrations let robots selectively accelerate safe trajectory segments while preserving precision where needed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
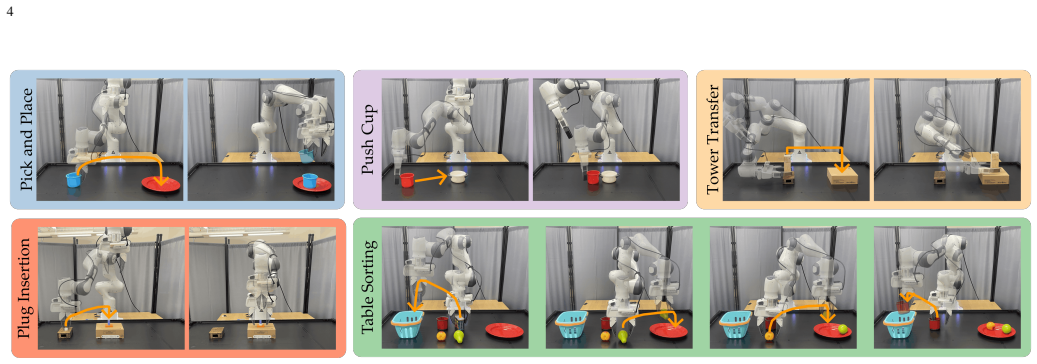
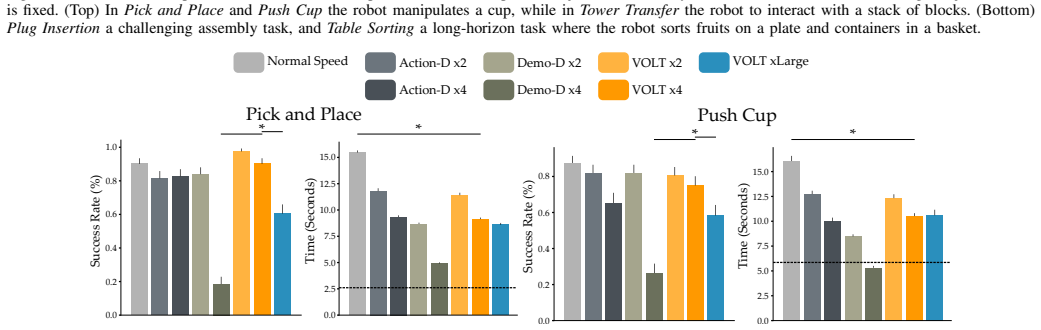
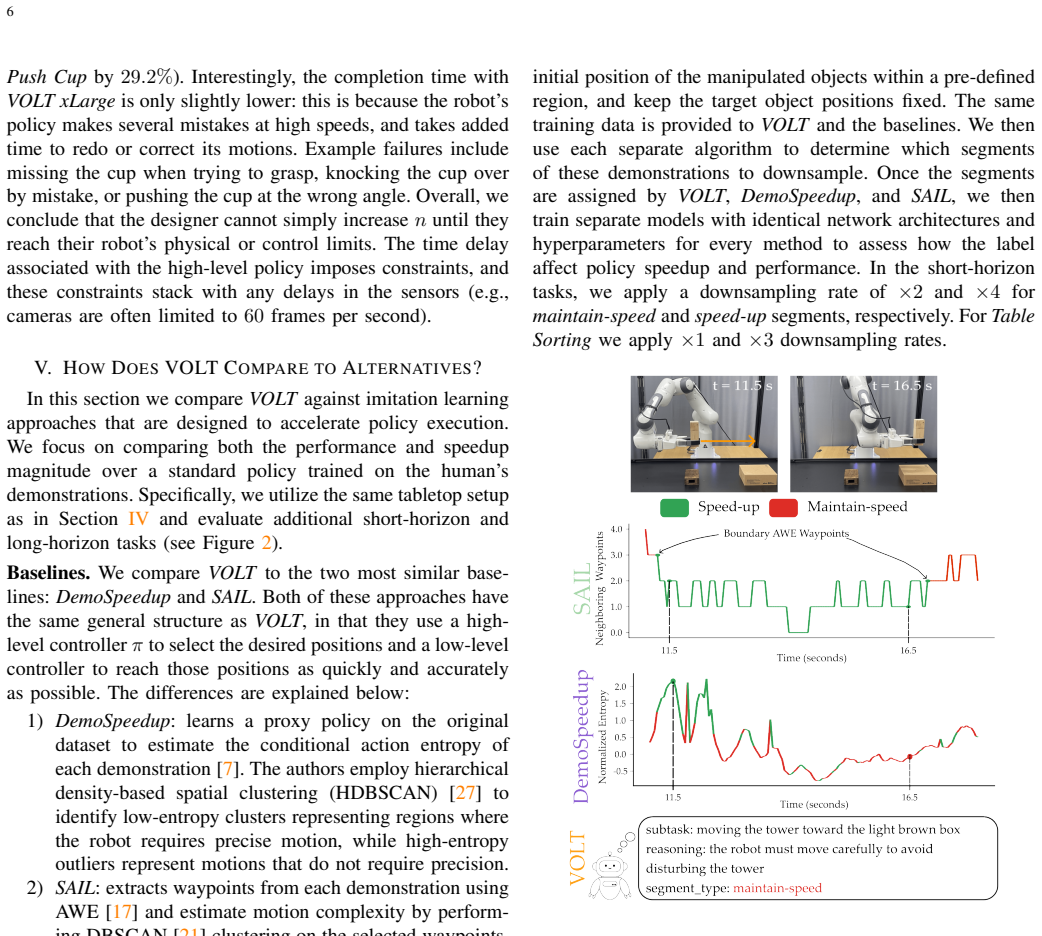
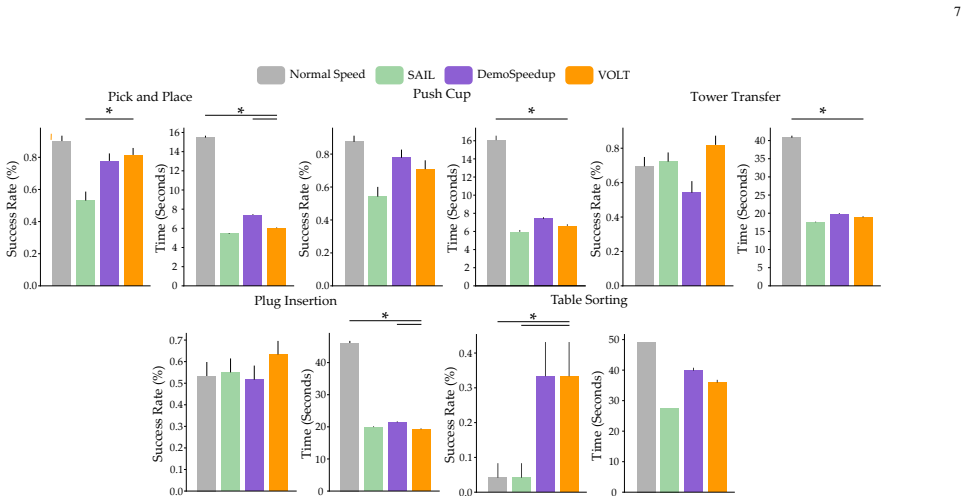
VOLT identifies segments in demonstration trajectories where slow deliberate motion is necessary by reasoning over visual and linguistic contextual cues, then selectively downsamples the remaining segments so that standard imitation learning methods such as diffusion policies produce faster-than-demonstration execution while maintaining task success.
What carries the argument
VOLT, a vision-and-language trajectory segmentation method that reasons over video demonstrations to decide where acceleration is appropriate.
If this is right
- Policies trained on VOLT-reformatted trajectories execute tasks faster than those trained on uniformly downsampled or unsegmented data.
- Segmentation quality directly determines whether the resulting policy is overly cautious or unreliable.
- Standard imitation learning algorithms can be used without modification once trajectories have been selectively accelerated.
- The method applies to tasks involving both unconstrained motion and fine manipulation within the same demonstration.
Where Pith is reading between the lines
- The same segmentation logic could be tested on non-video inputs such as force or proprioceptive signals to see whether language remains necessary.
- If segmentation errors are the main failure mode, adding explicit human feedback on segment boundaries might further improve speed without retraining the policy.
- The approach suggests that demonstration datasets could be post-processed once and reused across multiple robot platforms or task variants.
Load-bearing premise
Vision and language contextual cues from video demonstrations can reliably determine when acceleration is appropriate versus when precise slower motion is required.
What would settle it
A set of held-out demonstrations in which VOLT's segmentation decisions produce either task failure or execution times no faster than uniform downsampling baselines.
Figures

read the original abstract
Humans often take longer to demonstrate a task than a robot would need to execute it. Rather than learning to replicate the demonstration at the same pace, many industrial and practical applications require robots to perform tasks as quickly as possible. In this paper, we investigate several hypotheses for learning policies that operate faster-than-demonstrations. Our experiments show that the most effective strategy is to downsample recorded demonstrations and train the robot's policy on this accelerated data. However, uniformly downsampling an entire trajectory can be problematic. Some parts of a task can be safely sped up (e.g., unconstrained motion), while others demand slower, more precise motion (e.g., object interactions or fine manipulation). To address this challenge, we introduce VOLT, a vision-and-language trajectory segmentation method that reasons over video demonstrations, and leverages contextual cues to determine when acceleration is appropriate and when careful precision is required. VOLT identifies segments where slow, deliberate motion is necessary, then selectively downsamples the remaining segments. The resulting reformatted trajectories can be used with standard imitation learning approaches, such as diffusion policies. Our results highlight that segmentation quality is critical -- baseline methods often misidentify when acceleration is possible, leading to overly cautious or unreliable policies. Compared to state-of-the-art alternatives, VOLT allows robots to execute tasks faster while maintaining strong performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that uniform downsampling of human demonstrations is suboptimal for learning fast robot policies because some trajectory segments (e.g., unconstrained motion) can be safely accelerated while others (e.g., object interactions) require precision. It introduces VOLT, a vision-and-language trajectory segmentation method that uses contextual cues from video demonstrations to identify precision-critical segments, selectively downsamples the rest, and trains standard imitation learning policies (e.g., diffusion policies) on the reformatted data. Experiments are said to demonstrate that segmentation quality is critical, that baselines misidentify accelerable segments, and that VOLT enables faster execution than state-of-the-art alternatives while preserving strong performance.
Significance. If the segmentation reliably distinguishes accelerable from precision segments and the speed-up claims hold with quantitative validation, the work could enable more practical deployment of imitation-learned policies in time-sensitive industrial and manipulation tasks by addressing a common mismatch between demonstration pace and robot capability.
major comments (2)
- [Abstract] Abstract: The central claim that 'VOLT allows robots to execute tasks faster while maintaining strong performance' and that 'segmentation quality is critical' rests on the premise that vision-language cues can reliably isolate accelerable segments, yet the abstract provides no quantitative segmentation metrics (e.g., precision/recall on segment labels), human agreement scores, or failure-mode analysis to substantiate that baselines 'misidentify when acceleration is possible.'
- [Abstract] Abstract: The statement that 'our experiments show that the most effective strategy is to downsample recorded demonstrations' and that VOLT outperforms alternatives lacks any reported details on tasks, success rates, execution-time reductions, baseline implementations, or statistical comparisons, making it impossible to assess whether the speed-up preserves performance or merely trades one for the other.
minor comments (1)
- [Abstract] The abstract refers to 'standard imitation learning approaches, such as diffusion policies' without specifying which exact method or hyperparameters are used in the reported experiments.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for more quantitative detail in the abstract. The full manuscript contains the requested metrics, task descriptions, success rates, and comparisons in the experiments section. We will revise the abstract to include key quantitative results while preserving conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'VOLT allows robots to execute tasks faster while maintaining strong performance' and that 'segmentation quality is critical' rests on the premise that vision-language cues can reliably isolate accelerable segments, yet the abstract provides no quantitative segmentation metrics (e.g., precision/recall on segment labels), human agreement scores, or failure-mode analysis to substantiate that baselines 'misidentify when acceleration is possible.'
Authors: The abstract summarizes high-level findings, but the manuscript reports quantitative segmentation metrics (precision/recall for VOLT vs. baselines), human agreement scores, and failure-mode analysis in the experiments section. We will revise the abstract to include representative numbers, such as VOLT's segmentation precision and the performance gap versus baselines that misidentify accelerable segments. revision: yes
-
Referee: [Abstract] Abstract: The statement that 'our experiments show that the most effective strategy is to downsample recorded demonstrations' and that VOLT outperforms alternatives lacks any reported details on tasks, success rates, execution-time reductions, baseline implementations, or statistical comparisons, making it impossible to assess whether the speed-up preserves performance or merely trades one for the other.
Authors: Detailed task descriptions, success rates (with and without speed-up), execution-time reductions, baseline implementations, and statistical comparisons appear in the experiments section. We will update the abstract to report specific quantitative outcomes, including success rates and speed-up factors, to allow readers to evaluate the performance-speed trade-off directly from the abstract. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper presents VOLT as a new vision-and-language segmentation method to selectively downsample trajectories for faster execution. No equations, fitted parameters, or predictions are described that reduce by construction to inputs. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central contribution relies on external imitation learning baselines and empirical results rather than self-referential fitting or renaming. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
VOLT segmentation method
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey of imitation learning: Algorithms, recent developments, and challenges,
M. Zare, P. M. Kebria, A. Khosravi, and S. Nahavandi, “A survey of imitation learning: Algorithms, recent developments, and challenges,” IEEE Transactions on Cybernetics, 2024
2024
-
[2]
Discriminator-weighted offline imitation learning from suboptimal demonstrations,
H. Xu, X. Zhan, H. Yin, and H. Qin, “Discriminator-weighted offline imitation learning from suboptimal demonstrations,” inInternational Conference on Machine Learning, 2022
2022
-
[3]
Data quality in imitation learning,
S. Belkhale, Y . Cui, and D. Sadigh, “Data quality in imitation learning,” inAdvances in Neural Information Processing Systems, 2023
2023
-
[4]
Curating demonstra- tions using online experience,
A. S. Chen, A. M. Lessing, Y . Liu, and C. Finn, “Curating demonstra- tions using online experience,”Robotics: Science and Systems, 2025
2025
-
[5]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,”Robotics: Science and Systems, 2023
2023
-
[6]
SpeedAug: Policy acceleration via tempo- enriched policy and RL fine-tuning,
T. Nam and S. J. Hwang, “SpeedAug: Policy acceleration via tempo- enriched policy and RL fine-tuning,”arXiv preprint arXiv:2512.00062, 2025
Pith/arXiv arXiv 2025
-
[7]
DemoSpeedup: Accelerating visuomotor policies via entropy-guided demonstration acceleration,
L. Guo, Z. Xue, Z. Xu, and H. Xu, “DemoSpeedup: Accelerating visuomotor policies via entropy-guided demonstration acceleration,” in Conference on Robot Learning, 2025
2025
-
[8]
SAIL: Faster-than-demonstration execution of imitation learning policies,
N. R. Arachchige, Z. Chen, W. Jung, W. C. Shinet al., “SAIL: Faster-than-demonstration execution of imitation learning policies,” in Conference on Robot Learning, 2025
2025
-
[9]
π 0: A vision-language- action flow model for general robot control,
K. Black, N. Brown, D. Driess, A. Esmailet al., “π 0: A vision-language- action flow model for general robot control,”Robotics: Science and Systems, 2025
2025
-
[10]
CIVIL: Causal and intuitive visual imitation learning,
Y . Dai, R. Ramirez Sanchez, R. Jeronimus, S. Sagheb, C. M. Nunez, H. Nemlekar, and D. P. Losey, “CIVIL: Causal and intuitive visual imitation learning,”arXiv preprint arXiv:2504.17959, 2025
arXiv 2025
-
[11]
MimicPlay: Long-horizon imitation learning by watching human play,
C. Wang, L. Fan, J. Sun, R. Zhang, L. Fei-Fei, D. Xu, Y . Zhu, and A. Anandkumar, “MimicPlay: Long-horizon imitation learning by watching human play,” inConference on Robot Learning, 2023
2023
-
[12]
RECON: Reducing causal confusion with human-placed markers,
R. Ramirez Sanchez, H. Nemlekar, S. Sagheb, C. M. Nunez, and D. P. Losey, “RECON: Reducing causal confusion with human-placed markers,” inIEEE/RSJ International Conference on Intelligent Robots and Systems, 2025
2025
-
[13]
Action-free reasoning for policy generalization,
J. Clark, S. Mirchandani, D. Sadigh, and S. Belkhale, “Action-free reasoning for policy generalization,” inICRA Workshop on F oundation Models and Neuro-Symbolic AI for Robotics, 2025
2025
-
[14]
OpenVLA: An open-source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiaoet al., “OpenVLA: An open-source vision-language-action model,” inConference on Robot Learning, 2025
2025
-
[15]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, 2025
2025
-
[16]
Towards balanced behavior cloning from imbalanced datasets,
S. Parekh, H. Nemlekar, and D. P. Losey, “Towards balanced behavior cloning from imbalanced datasets,”Autonomous Robots, 2026
2026
-
[17]
Waypoint-based imitation learning for robotic manipulation,
L. X. Shi, A. Sharma, T. Z. Zhao, and C. Finn, “Waypoint-based imitation learning for robotic manipulation,” inConference on Robot Learning, 2023
2023
-
[18]
PRIME: Scaffolding manipulation tasks with behavior primitives for data-efficient imitation learning,
T. Gao, S. Nasiriany, H. Liu, Q. Yang, and Y . Zhu, “PRIME: Scaffolding manipulation tasks with behavior primitives for data-efficient imitation learning,”IEEE Robotics and Automation Letters, 2024
2024
-
[19]
HYDRA: Hybrid robot actions for imitation learning,
S. Belkhale, Y . Cui, and D. Sadigh, “HYDRA: Hybrid robot actions for imitation learning,” inConference on Robot Learning, 2023
2023
-
[20]
Speedtuning: Speeding up policy execution with lightweight reinforcement learning,
D. D. Yuan, T. Z. Zhao, K. Burns, and C. Finn, “Speedtuning: Speeding up policy execution with lightweight reinforcement learning,” inIEEE International Conference on Robotics and Automation, 2025
2025
-
[21]
A density-based algorithm for discovering clusters in large spatial databases with noise,
M. Ester, H.-P. Kriegel, J. Sander, X. Xuet al., “A density-based algorithm for discovering clusters in large spatial databases with noise,” inKnowledge Discovery and Data Mining, 1996
1996
-
[22]
B. Kim, J. Pahk, C. Lee, J. Kim, J. Lee, T. T. Kim, K. Shim, J. K. Lee, and B.-T. Zhang, “ESPADA: Execution speedup via semantics aware demonstration data downsampling for imitation learning,”arXiv preprint arXiv:2512.07371, 2025
Pith/arXiv arXiv 2025
-
[23]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inInternational Conference on Learning Representations, 2021
2021
-
[24]
GELLO: A general, low- cost, and intuitive teleoperation framework for robot manipulators,
P. Wu, Y . Shentu, Z. Yi, X. Lin, and P. Abbeel, “GELLO: A general, low- cost, and intuitive teleoperation framework for robot manipulators,” in IEEE/RSJ International Conf. on Intelligent Robots and Systems, 2024
2024
-
[25]
S. Bai, Y . Cai, R. Chen, K. Chenet al., “Qwen3-VL technical report,” arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[26]
DROID: A large-scale in-the-wild robot manipulation dataset,
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishnaet al., “DROID: A large-scale in-the-wild robot manipulation dataset,” inRSS 2024 Workshop: Data Generation for Robotics, 2024
2024
-
[27]
hdbscan: Hierarchical density based clustering,
L. McInnes, J. Healy, S. Astelset al., “hdbscan: Hierarchical density based clustering,”Journal of Open Source Software, 2017
2017
-
[28]
AutoMate: Specialist and generalist assembly policies over diverse geometries,
B. Tang, I. Akinola, J. Xu, B. Wen, A. Handaet al., “AutoMate: Specialist and generalist assembly policies over diverse geometries,” Robotics: Science and Systems, 2024
2024
-
[29]
Training-time ac- tion conditioning for efficient real-time chunking,
K. Black, A. Z. Ren, M. Equi, and S. Levine, “Training-time ac- tion conditioning for efficient real-time chunking,”arXiv preprint arXiv:2512.05964, 2025
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.