Subspace-Aware Sparse Autoencoders for Effective Mechanistic Interpretability
Pith reviewed 2026-06-28 02:03 UTC · model grok-4.3
The pith
Subspace-aware sparse autoencoders consolidate multi-dimensional model features into single groups when block size meets intrinsic dimension, replacing exponential splitting with polynomial sample complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Once the block size satisfies r ≥ d_i, a single group not only can represent the entire feature slice but is the global minimizer of the SASA objective. This consolidation yields a sample complexity polynomial in d_i rather than exponential -- a decisive advantage given that every training activation costs an LLM forward pass.
What carries the argument
Decoder subspaces with Top-s group gating for block sparsity and nuclear-norm regularization to adapt each group's effective rank.
Load-bearing premise
Model features possess a well-defined intrinsic dimension d_i that is stable across the activation distribution, and the l1-regularized objective's descent directions reliably drive dictionaries into the exponential splitting regime.
What would settle it
Measure intrinsic dimension d_i of a known feature slice, then train both a standard SAE and SASA with block size r equal to that d_i on the same activations and compare the number of latents needed for equivalent reconstruction error.
Figures

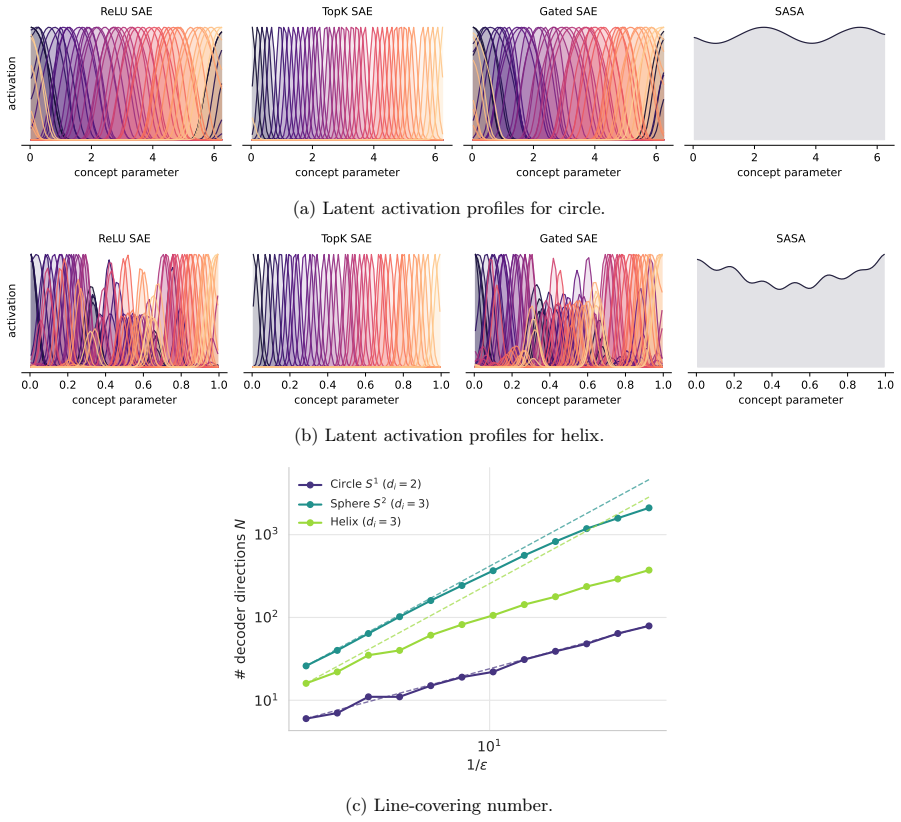



read the original abstract
Sparse Autoencoders (SAEs) are widely used for mechanistic interpretability in large language models, yet their formulation assigns each latent feature a single decoder direction, implicitly assuming features to be one-dimensional. We show that this assumption mismatches with the multi-dimensional structure of model features, provably inducing feature splitting through two distinct mechanisms. Geometrically, reconstructing a feature of intrinsic dimension $d_i \ge 2$ to error $\varepsilon$ with single-direction decoders forces a number of atoms that is exponential in $d_i$. From an end-to-end optimization perspective, this splitting is not merely possible but actively preferred. We prove that there exists a continuous path from the true $d_i$-dimensional basis to a strictly lower risk of the $\ell_1$-regularized SAE objective, whose descent directions drive any trained dictionary into that exponential regime. A single coherent feature is therefore fragmented across many near-collinear latents, producing spurious multiplicity and obscuring the intrinsic geometry. Motivated by this, we introduce Subspace-Aware Sparse Autoencoders (SASA), which replace single-vector decoders with learned decoder subspaces, enforce block sparsity via Top-$s$ group gating, and adapt each group's effective rank with a nuclear-norm regularizer. We then show that once the block size satisfies $r \ge d_i$, a single group not only can represent the entire feature slice but is the global minimizer of the SASA objective. This consolidation yields a sample complexity polynomial in $d_i$ rather than exponential -- a decisive advantage given that every training activation costs an LLM forward pass. Empirically, on GPT-2 and Mistral-7B, SASA reduces feature splitting and absorption, improves monosemanticity and interpretability, and matches or exceeds standard SAEs while training on roughly half the token budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard SAEs induce feature splitting by assuming one-dimensional decoder directions, with two proofs (a geometric lower bound requiring exponentially many atoms for d_i >=2 reconstruction error epsilon, and an optimization argument showing a continuous descent path from the true d_i-basis to lower l1-regularized risk). It introduces SASA, which uses learned decoder subspaces, Top-s group gating for block sparsity, and nuclear-norm regularization to adapt rank. The central result is that when block size r >= d_i a single group is the global minimizer of the SASA objective, yielding polynomial rather than exponential sample complexity in d_i. Empirics on GPT-2 and Mistral-7B report reduced splitting/absorption and improved monosemanticity with roughly half the token budget.
Significance. If the proofs and global-minimizer claim hold, the work would be significant for mechanistic interpretability by directly targeting a structural mismatch between SAE assumptions and multi-dimensional model features, with a concrete sample-complexity advantage that matters given the cost of LLM activations. The explicit derivation of consolidation from the regularized objective and the empirical comparison on two models are strengths worth crediting.
major comments (3)
- [Abstract] Abstract (global-minimizer claim): the statement that 'once the block size satisfies r >= d_i, a single group ... is the global minimizer of the SASA objective' is load-bearing for the polynomial-sample-complexity conclusion, yet the abstract provides no derivation; without it, it is impossible to confirm that the nuclear-norm + Top-s objective excludes lower-risk configurations that split the slice across groups or inflate effective rank when d_i is only approximately stable.
- [Abstract] Abstract (two proofs): the geometric lower bound and the existence of a continuous descent path are presented as establishing that splitting is both necessary and actively preferred, but the abstract supplies neither the explicit population-loss expression, the precise form of the l1-regularized objective, nor any finite-sample error bounds; this leaves open whether the claimed exponential regime is an artifact of post-hoc hyperparameter choices or dataset-specific activation statistics.
- [Abstract] Abstract (empirical validation): the reported reductions in splitting and absorption on GPT-2/Mistral are central to the practical claim, yet the abstract gives no error bars, dataset sizes, or hyperparameter details; without these it is impossible to assess whether the observed improvements are robust or sensitive to the same post-hoc choices that could affect the theoretical claims.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We respond point-by-point to the major comments, all of which concern the level of detail provided in the abstract. The abstract is a concise summary of the key claims and results; the full derivations, proofs, and experimental details appear in the body of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (global-minimizer claim): the statement that 'once the block size satisfies r >= d_i, a single group ... is the global minimizer of the SASA objective' is load-bearing for the polynomial-sample-complexity conclusion, yet the abstract provides no derivation; without it, it is impossible to confirm that the nuclear-norm + Top-s objective excludes lower-risk configurations that split the slice across groups or inflate effective rank when d_i is only approximately stable.
Authors: The abstract states the global-minimizer result at a high level. The complete proof that a single group is the global minimizer of the nuclear-norm + Top-s objective when r >= d_i (including the exclusion of splitting or rank-inflation configurations) is given in Section 4. Space constraints preclude reproducing the full derivation in the abstract; the claim is substantiated in the main text. revision: no
-
Referee: [Abstract] Abstract (two proofs): the geometric lower bound and the existence of a continuous descent path are presented as establishing that splitting is both necessary and actively preferred, but the abstract supplies neither the explicit population-loss expression, the precise form of the l1-regularized objective, nor any finite-sample error bounds; this leaves open whether the claimed exponential regime is an artifact of post-hoc hyperparameter choices or dataset-specific activation statistics.
Authors: The geometric lower bound and continuous-descent argument are summarized in the abstract. The explicit population loss, l1-regularized objective, and supporting analysis (including why the exponential regime is not an artifact) appear in Sections 3.1 and 3.2. Finite-sample aspects are addressed via the polynomial-vs-exponential sample-complexity comparison in the same sections. The abstract cannot contain the full expressions. revision: no
-
Referee: [Abstract] Abstract (empirical validation): the reported reductions in splitting and absorption on GPT-2/Mistral are central to the practical claim, yet the abstract gives no error bars, dataset sizes, or hyperparameter details; without these it is impossible to assess whether the observed improvements are robust or sensitive to the same post-hoc choices that could affect the theoretical claims.
Authors: The abstract reports the high-level empirical outcomes. Full details on token budgets, datasets, hyperparameters, and any error bars or robustness checks are provided in Section 5 and the appendix. Abstracts conventionally omit such granular information; the reported improvements hold across two models with the stated token-budget reduction. revision: no
Circularity Check
No significant circularity; central claims are presented as direct derivations from the SASA objective.
full rationale
The paper states its key theoretical result ('once the block size satisfies r ≥ d_i, a single group ... is the global minimizer of the SASA objective') as a proof from the nuclear-norm + Top-s regularized loss and geometric reconstruction arguments. No self-citation chain, fitted-input-as-prediction, or self-definitional reduction is exhibited in the abstract or described claims. The derivation is framed as independent of any prior fitted quantities or author-specific uniqueness theorems. The stability of d_i is an assumption, not a circular reduction. This is the common case of a self-contained theoretical argument.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Model activations contain features with stable intrinsic dimension d_i ≥ 2 that can be recovered from finite samples.
- domain assumption The ℓ1-regularized reconstruction objective is the correct loss for measuring feature quality in mechanistic interpretability.
invented entities (1)
-
Learned decoder subspace with Top-s group gating
no independent evidence
Reference graph
Works this paper leans on
-
[1]
and Liao, Isaac and Gurnee, Wes and Tegmark, Max , year=
Engels, Joshua and Michaud, Eric J. and Liao, Isaac and Gurnee, Wes and Tegmark, Max , year=. Not All Language Model Features Are One-Dimensionally Linear , url=. doi:10.48550/arXiv.2405.14860 , abstractNote=
-
[2]
The Origins of Representation Manifolds in Large Language Models , url=
Modell, Alexander and Rubin-Delanchy, Patrick and Whiteley, Nick , year=. The Origins of Representation Manifolds in Large Language Models , url=. doi:10.48550/arXiv.2505.18235 , abstractNote=
-
[3]
Cambridge University Press, September 2018
Vershynin, Roman , year=. High-Dimensional Probability: An Introduction with Applications in Data Science , ISBN=. doi:10.1017/9781108231596 , abstractNote=
-
[4]
Toy Models of Superposition , journal=
Elhage, Nelson and Hume, Tristan and Olsson, Catherine and Schiefer, Nicholas and Henighan, Tom and Kravec, Shauna and Hatfield-Dodds, Zac and Lasenby, Robert and Drain, Dawn and Chen, Carol and Grosse, Roger and McCandlish, Sam and Kaplan, Jared and Amodei, Dario and Wattenberg, Martin and Olah, Christopher , year=. Toy Models of Superposition , journal=
-
[5]
The linear representation hypothesis and the geometry of large language models , abstractNote=
Park, Kiho and Choe, Yo Joong and Veitch, Victor , year=. The linear representation hypothesis and the geometry of large language models , abstractNote=. Proceedings of the 41st International Conference on Machine Learning , publisher=
-
[6]
Understanding intermediate layers using linear classifier probes
Alain, Guillaume and Bengio, Yoshua , year=. Understanding intermediate layers using linear classifier probes , url=. doi:10.48550/arXiv.1610.01644 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1610.01644
-
[7]
Scaling and evaluating sparse autoencoders
Gao, Leo and Tour, Tom Dupré la and Tillman, Henk and Goh, Gabriel and Troll, Rajan and Radford, Alec and Sutskever, Ilya and Leike, Jan and Wu, Jeffrey , year=. Scaling and evaluating sparse autoencoders , url=. doi:10.48550/arXiv.2406.04093 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.04093
-
[8]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Cunningham, Hoagy and Ewart, Aidan and Riggs, Logan and Huben, Robert and Sharkey, Lee , year=. Sparse Autoencoders Find Highly Interpretable Features in Language Models , url=. doi:10.48550/arXiv.2309.08600 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.08600
-
[9]
The American Mathematical Monthly , author=
An Upper Bound for Spherical Caps , volume=. The American Mathematical Monthly , author=. 2012 , pages=. doi:10.4169/amer.math.monthly.119.07.606 , number=
-
[10]
and Hockenmaier, Julia , year=
Lee, Sewoong and Davies, Adam and Canby, Marc E. and Hockenmaier, Julia , year=. Evaluating and Designing Sparse Autoencoders by Approximating Quasi-Orthogonality , url=. doi:10.48550/arXiv.2503.24277 , abstractNote=
-
[11]
A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders , url=
Chanin, David and Wilken-Smith, James and Dulka, Tomáš and Bhatnagar, Hardik and Golechha, Satvik and Bloom, Joseph , year=. A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders , url=
-
[12]
User-Friendly Tail Bounds for Sums of Random Matrices , volume=. Foundations of Computational Mathematics , author=. 2012 , month=aug, pages=. doi:10.1007/s10208-011-9099-z , abstractNote=
-
[13]
Yu, Y. and Wang, T. and Samworth, R. J. , title =. Biometrika , volume =. 2014 , month =. doi:10.1093/biomet/asv008 , url =
-
[14]
Knyazev, Andrew and Jujunashvili, Abram and Argentati, Merico , year=. Angles between infinite dimensional subspaces with applications to the Rayleigh–Ritz and alternating projectors methods , volume=. Journal of Functional Analysis , publisher=. doi:10.1016/j.jfa.2010.05.018 , number=
-
[15]
Horn, Roger A. and Johnson, Charles R. , year=. Matrix Analysis , url=. doi:10.1017/CBO9780511810817 , abstractNote=
-
[16]
Doumas, Aristides V. and Papanicolaou, Vassilis G. , year=. The Coupon Collector’s Problem Revisited: Generalizing the Double Dixie Cup Problem of Newman and Shepp , url=. doi:10.48550/arXiv.1412.3626 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1412.3626
-
[17]
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , journal=
Bricken, Trenton and Templeton, Adly and Batson, Joshua and Chen, Brian and Jermyn, Adam and Conerly, Tom and Turner, Nick and Anil, Cem and Denison, Carson and Askell, Amanda and Lasenby, Robert and Wu, Yifan and Kravec, Shauna and Schiefer, Nicholas and Maxwell, Tim and Joseph, Nicholas and Hatfield-Dodds, Zac and Tamkin, Alex and Nguyen, Karina and McL...
-
[18]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Wang, Kevin and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , year=. Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small , url=. doi:10.48550/arXiv.2211.00593 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.00593
-
[19]
and Lynch, Aengus and Heimersheim, Stefan and Garriga-Alonso, Adrià , year=
Conmy, Arthur and Mavor-Parker, Augustine N. and Lynch, Aengus and Heimersheim, Stefan and Garriga-Alonso, Adrià , year=. Towards automated circuit discovery for mechanistic interpretability , abstractNote=. Proceedings of the 37th International Conference on Neural Information Processing Systems , publisher=
-
[20]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , author=
Detecting and understanding vulnerabilities in language models via mechanistic interpretability , ISBN=. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , author=. 2024 , collection=. doi:10.24963/ijcai.2024/43 , abstractNote=
-
[21]
Using Mechanistic Interpretability to Craft Adversarial Attacks against Large Language Models , url=
Winninger, Thomas and Addad, Boussad and Kapusta, Katarzyna , year=. Using Mechanistic Interpretability to Craft Adversarial Attacks against Large Language Models , url=. doi:10.48550/arXiv.2503.06269 , abstractNote=
-
[22]
Refusal in Language Models Is Mediated by a Single Direction
Arditi, Andy and Obeso, Oscar and Syed, Aaquib and Paleka, Daniel and Panickssery, Nina and Gurnee, Wes and Nanda, Neel , year=. Refusal in Language Models Is Mediated by a Single Direction , url=. doi:10.48550/arXiv.2406.11717 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.11717
-
[23]
Lee, Andrew and Bai, Xiaoyan and Pres, Itamar and Wattenberg, Martin and Kummerfeld, Jonathan K. and Mihalcea, Rada , year=. A Mechanistic Understanding of Alignment Algorithms: A Case Study on DPO and Toxicity , url=. doi:10.48550/arXiv.2401.01967 , abstractNote=
-
[24]
The Geometry of Categorical and Hierarchical Concepts in Large Language Models , url=
Park, Kiho and Choe, Yo Joong and Jiang, Yibo and Veitch, Victor , year=. The Geometry of Categorical and Hierarchical Concepts in Large Language Models , url=. doi:10.48550/arXiv.2406.01506 , abstractNote=
-
[25]
Sharkey, Lee and Chughtai, Bilal and Batson, Joshua and Lindsey, Jack and Wu, Jeff and Bushnaq, Lucius and Goldowsky-Dill, Nicholas and Heimersheim, Stefan and Ortega, Alejandro and Bloom, Joseph and Biderman, Stella and Garriga-Alonso, Adria and Conmy, Arthur and Nanda, Neel and Rumbelow, Jessica and Wattenberg, Martin and Schoots, Nandi and Miller, Jose...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.16496
-
[26]
OpenWebText Corpus , url=
Gokaslan, Aaron and Cohen, Vanya and Pavlick, Ellie and Tellex, Stefanie , year=. OpenWebText Corpus , url=
-
[27]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and Presser, Shawn and Leahy, Connor , year=. The Pile: An 800GB Dataset of Diverse Text for Language Modeling , url=. doi:10.48550/arXiv.2101.00027 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2101.00027
-
[28]
SAELens , url=
Bloom, Joseph and Tigges, Curt and Duong, Anthony and Chanin, David , year=. SAELens , url=
-
[29]
2024 , howpublished =
SAELens , author =. 2024 , howpublished =
2024
-
[30]
Alice and Bob Meet Banach: The Interface of Asymptotic Geometric Analysis and Quantum Information Theory , ISBN=
Szarek, Stanislaw and Aubrun, Guillaume , year=. Alice and Bob Meet Banach: The Interface of Asymptotic Geometric Analysis and Quantum Information Theory , ISBN=
-
[31]
Leask, Patrick and Nanda, Neel and Moubayed, Noura Al , year=. Inference-Time Decomposition of Activations (ITDA): A Scalable Approach to Interpreting Large Language Models , url=. doi:10.48550/arXiv.2505.17769 , abstractNote=
-
[32]
Distributional Structure , volume=. WORD , author=. 1954 , month=aug, pages=. doi:10.1080/00437956.1954.11659520 , number=
-
[33]
Improving Dictionary Learning with Gated Sparse Autoencoders
Rajamanoharan, Senthooran and Conmy, Arthur and Smith, Lewis and Lieberum, Tom and Varma, Vikrant and Kramár, János and Shah, Rohin and Nanda, Neel , year=. Improving Dictionary Learning with Gated Sparse Autoencoders , url=. doi:10.48550/arXiv.2404.16014 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.16014
-
[34]
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders
Rajamanoharan, Senthooran and Lieberum, Tom and Sonnerat, Nicolas and Conmy, Arthur and Varma, Vikrant and Kramár, János and Nanda, Neel , year=. Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders , url=. doi:10.48550/arXiv.2407.14435 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.14435
-
[35]
BatchTopK Sparse Autoencoders , url=
Bussmann, Bart and Leask, Patrick and Nanda, Neel , year=. BatchTopK Sparse Autoencoders , url=. doi:10.48550/arXiv.2412.06410 , abstractNote=
-
[36]
Learning Multi-Level Features with Matryoshka Sparse Autoencoders , url=
Bussmann, Bart and Nabeshima, Noa and Karvonen, Adam and Nanda, Neel , year=. Learning Multi-Level Features with Matryoshka Sparse Autoencoders , url=. doi:10.48550/arXiv.2503.17547 , abstractNote=
-
[37]
and Gorton, Liv and McGrath, Tom , year=
Michaud, Eric J. and Gorton, Liv and McGrath, Tom , year=. Understanding sparse autoencoder scaling in the presence of feature manifolds , url=. doi:10.48550/arXiv.2509.02565 , abstractNote=
-
[38]
Journal of the Royal Statistical Society Series B: Statistical Methodology , author=
Model Selection and Estimation in Regression with Grouped Variables , volume=. Journal of the Royal Statistical Society Series B: Statistical Methodology , author=. 2006 , month=feb, pages=. doi:10.1111/j.1467-9868.2005.00532.x , abstractNote=
-
[39]
Foundations of Computational Mathematics , author=
Exact Matrix Completion via Convex Optimization , volume=. Foundations of Computational Mathematics , author=. 2009 , month=dec, pages=. doi:10.1007/s10208-009-9045-5 , abstractNote=
-
[40]
On the convergence of group-sparse autoencoders , url=
Theodosis, Emmanouil and Tolooshams, Bahareh and Tankala, Pranay and Tasissa, Abiy and Ba, Demba , year=. On the convergence of group-sparse autoencoders , url=. doi:10.48550/arXiv.2102.07003 , abstractNote=
-
[41]
Analyzing the Generalization and Reliability of Steering Vectors , url=
Tan, Daniel and Chanin, David and Lynch, Aengus and Kanoulas, Dimitrios and Paige, Brooks and Garriga-Alonso, Adria and Kirk, Robert , year=. Analyzing the Generalization and Reliability of Steering Vectors , url=. doi:10.48550/arXiv.2407.12404 , abstractNote=
-
[42]
The Universal Weight Subspace Hypothesis , url=
Kaushik, Prakhar and Chaudhari, Shravan and Vaidya, Ankit and Chellappa, Rama and Yuille, Alan , year=. The Universal Weight Subspace Hypothesis , url=. doi:10.48550/arXiv.2512.05117 , abstractNote=
-
[43]
The Platonic Representation Hypothesis
Huh, Minyoung and Cheung, Brian and Wang, Tongzhou and Isola, Phillip , year=. The Platonic Representation Hypothesis , url=. doi:10.48550/arXiv.2405.07987 , abstractNote=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.07987
-
[44]
Identifying Functionally Important Features with End-to-End Sparse Dictionary Learning , url=
Braun, Dan and Taylor, Jordan and Goldowsky-Dill, Nicholas and Sharkey, Lee , year=. Identifying Functionally Important Features with End-to-End Sparse Dictionary Learning , url=. doi:10.48550/arXiv.2405.12241 , abstractNote=
-
[45]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Regression shrinkage and selection via the lasso , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 1996 , publisher=
1996
-
[46]
International conference on machine learning , pages=
Loss landscapes of regularized linear autoencoders , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[47]
arXiv preprint arXiv:2604.28119 , year=
Do Sparse Autoencoders Capture Concept Manifolds? , author=. arXiv preprint arXiv:2604.28119 , year=
-
[48]
arXiv preprint arXiv:0807.4581 , year=
Robust recovery of signals from a structured union of subspaces , author=. arXiv preprint arXiv:0807.4581 , year=
-
[49]
IEEE Transactions on Signal Processing , volume=
Block-sparse signals: Uncertainty relations and efficient recovery , author=. IEEE Transactions on Signal Processing , volume=. 2010 , publisher=
2010
-
[50]
Proceedings of the American Mathematical Society , volume=
A matrix subadditivity inequality for symmetric norms , author=. Proceedings of the American Mathematical Society , volume=
-
[51]
2013 , publisher=
Approximation theory and harmonic analysis on spheres and balls , author=. 2013 , publisher=
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.