Where Should Knowledge Enter? A Layered Framework for Knowledge Infusion in Multimodal Iterative Generative Model
Pith reviewed 2026-06-28 01:26 UTC · model grok-4.3
The pith
Knowledge enters generative models most effectively when infused at four distinct layers of the iterative process rather than through isolated techniques.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
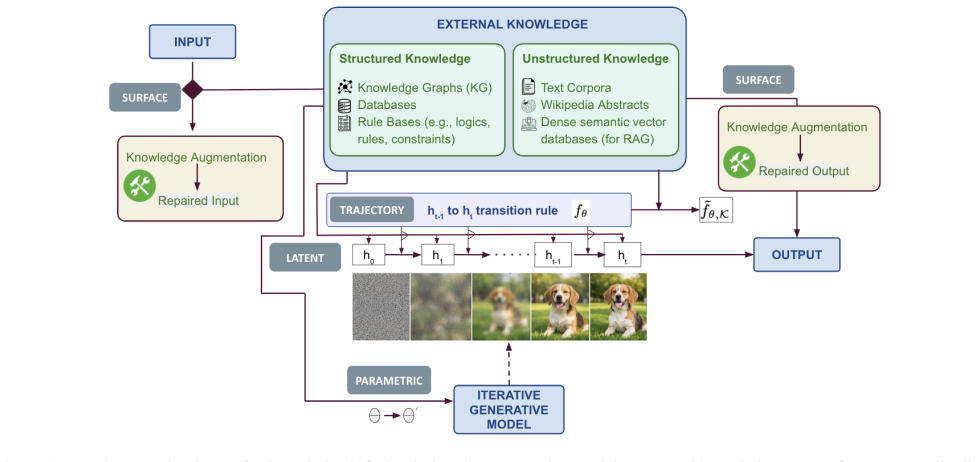
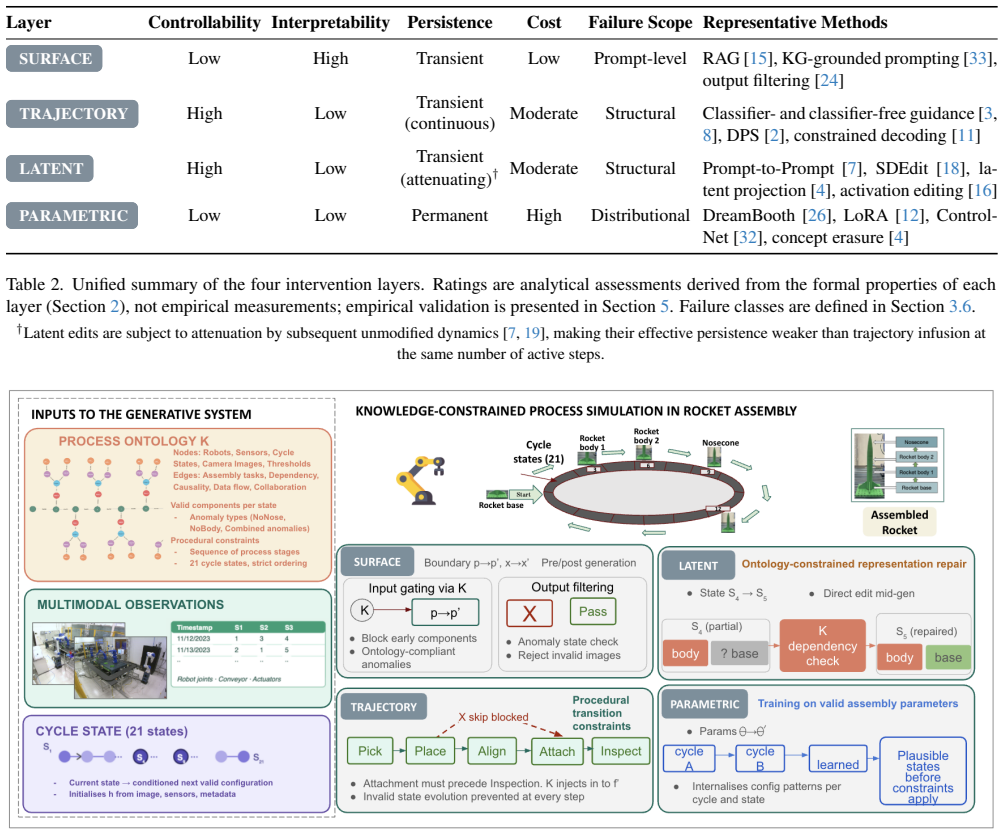
We argue that knowledge infusion in iterative generative models is fundamentally an intervention-layer problem. Since the generative process unfolds as a trajectory of internal states, knowledge can act on four structurally distinct components of this process: the input/output boundary, the transition function, the intermediate state, and the model parameters. This maps to four intervention layers: surface, trajectory, latent, and parametric infusion. We instantiate the framework in diffusion models, map representative methods to all four layers, and derive design principles for multi-layer composition.
What carries the argument
The four intervention layers (surface, trajectory, latent, parametric) that map to distinct components of the generative trajectory and allow complementary knowledge interventions.
If this is right
- Each additional layer addresses failure classes unreachable by prior layers alone.
- Cumulative use of three layers produces a 70.97 percent reduction in knowledge-violating outputs relative to vanilla generation.
- Representative existing methods can be mapped onto each of the four layers.
- Design principles for composing multiple layers can be derived from the structural distinctions among the components they modify.
Where Pith is reading between the lines
- Testing the parametric layer in the same safety-alignment setup could reveal whether further reductions beyond 70.97 percent are attainable.
- The framework offers a diagnostic lens for why single-technique knowledge infusion sometimes fails in practice.
- The layering idea may extend to other iterative generators such as autoregressive models without requiring diffusion-specific mechanics.
Load-bearing premise
The concrete implementations chosen for surface, trajectory, and latent interventions in the experiment map directly onto the abstract layers without substantial overlap or other factors that could produce the observed complementarity.
What would settle it
An experiment that reassigns the same intervention methods to different layers or introduces controlled overlap and finds that the reduction in knowledge-violating outputs no longer increases reliably with each added layer.
Figures

read the original abstract
Multimodal generative models produce fluent outputs but remain unreliable when generation must respect structured, domain-specific, or safety-critical knowledge. Existing methods incorporate knowledge through mechanisms such as prompt augmentation, guidance, latent editing, or fine-tuning, yet they are typically categorized by technique rather than by the component of the generative process they modify. We argue that knowledge infusion in iterative generative models is fundamentally anintervention-layer problem. Since thegenerative process unfolds as a trajectory of internal states, knowledge can act on four structurally distinct components of this process: the input/output boundary, the transition function, the intermediate state, and the model parameters. This maps to four intervention layers: surface, trajectory, latent, and parametric infusion. We instantiate the framework in diffusion models, map representative methods to all four layers, and derive design principles for multi-layer composition. In a controlled safety-alignment experiment using a multimodal knowledge graph with two diffusion backbones, we implement three of the four layers cumulatively, surface (input-side and output-side) and trajectory--latent (mid-generation). We show empirically that each additional layer addresses failure classes that prior layers cannot reach, reducing knowledge-violating outputs by 70.97% compared to vanilla generation and empirically confirming the framework's complementarity prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a four-layer framework (surface, trajectory, latent, parametric) for knowledge infusion in iterative multimodal generative models, arguing that interventions act on distinct components of the generative trajectory. It maps existing methods to the layers, derives composition principles, and reports a controlled safety-alignment experiment on diffusion models using a multimodal knowledge graph and two backbones. In the experiment, cumulative application of surface (input/output) and combined trajectory-latent (mid-generation) interventions reduces knowledge-violating outputs by 70.97% relative to vanilla generation, with each added layer claimed to address failure classes unreachable by prior layers.
Significance. If the empirical complementarity result holds after addressing controls for intervention strength and failure-class overlap, the framework supplies a useful organizing taxonomy that could improve systematic design of knowledge-infused systems in safety-critical settings. The use of multiple diffusion backbones and a structured knowledge graph strengthens the experiment's scope relative to single-model studies.
major comments (2)
- [Experiment description] Abstract and experiment description: the claim that 'each additional layer addresses failure classes that prior layers cannot reach' is load-bearing for the complementarity prediction, yet the manuscript reports only the cumulative 70.97% reduction without a per-layer breakdown of addressed failure classes (e.g., via table or figure showing incremental error types). This omission prevents verification that observed gains arise from structural layer distinctions rather than additive intervention effects.
- [Methods] Methods (trajectory-latent bundling): combining trajectory and latent interventions into a single mid-generation step creates potential functional overlap, since surface-level prompt changes can already alter denoising trajectories in diffusion models; without strength-matched ablations or separate controls for compute/intervention dosage, the design does not isolate whether incremental gains confirm the four-layer structure or simply reflect more total interventions.
minor comments (2)
- [Abstract] Abstract contains a typographical error ('Since thegenerative process') that should be corrected for clarity.
- [Framework section] Notation for the four layers is introduced conceptually but would benefit from an explicit summary table mapping representative methods to each layer to aid reader navigation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key gaps in the experimental reporting and controls. We agree that both points require additional analysis and will revise the manuscript accordingly to strengthen the evidence for the framework.
read point-by-point responses
-
Referee: [Experiment description] Abstract and experiment description: the claim that 'each additional layer addresses failure classes that prior layers cannot reach' is load-bearing for the complementarity prediction, yet the manuscript reports only the cumulative 70.97% reduction without a per-layer breakdown of addressed failure classes (e.g., via table or figure showing incremental error types). This omission prevents verification that observed gains arise from structural layer distinctions rather than additive intervention effects.
Authors: We agree that the manuscript lacks the per-layer breakdown needed to verify the complementarity claim. The current results report only the cumulative reduction. In revision we will add a table (or figure) that enumerates the distinct failure classes reduced at each cumulative stage, allowing direct inspection of whether each added layer targets error types unreachable by prior layers. revision: yes
-
Referee: [Methods] Methods (trajectory-latent bundling): combining trajectory and latent interventions into a single mid-generation step creates potential functional overlap, since surface-level prompt changes can already alter denoising trajectories in diffusion models; without strength-matched ablations or separate controls for compute/intervention dosage, the design does not isolate whether incremental gains confirm the four-layer structure or simply reflect more total interventions.
Authors: The referee is correct that bundling trajectory and latent interventions risks confounding additive dosage with layer-specific effects. The manuscript does not include strength-matched ablations or dosage controls. We will add separate ablations that apply trajectory and latent interventions independently (where feasible) together with matched intervention-strength and compute controls to better isolate the contribution of each layer. revision: yes
Circularity Check
No circularity: framework is a structural categorization of interventions; experiment tests cumulative effects without reducing claims to fitted inputs or self-citations.
full rationale
The paper defines four intervention layers by the component of the generative trajectory they target (input/output boundary, transition function, intermediate state, model parameters). It maps existing methods to these layers, derives composition principles, and reports an experiment implementing three layers cumulatively on diffusion models. The central empirical result (70.97% reduction and distinct failure-class coverage) is presented as confirmation of a derived prediction rather than a fit. No equations, parameter-fitting steps, or self-citations are shown that would make any claim equivalent to its inputs by construction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The generative process unfolds as a trajectory of internal states with four structurally distinct components where knowledge can intervene.
Reference graph
Works this paper leans on
-
[1]
Attend-and-excite: Attention- based semantic guidance for text-to-image diffusion models.ACM transactions on Graphics (TOG), 42 (4):1–10, 2023
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention- based semantic guidance for text-to-image diffusion models.ACM transactions on Graphics (TOG), 42 (4):1–10, 2023. 5
2023
-
[2]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems.arXiv preprint arXiv:2209.14687, 2022. 4, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Diffusion models beat gans on image synthesis, 2021
Prafulla Dhariwal and Alex Nichol. Diffusion models beat gans on image synthesis, 2021. 1, 4, 6
2021
-
[4]
Erasing concepts from dif- fusion models
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto- Kaufman, and David Bau. Erasing concepts from dif- fusion models. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 2426– 2436, 2023. 4, 5, 6
2023
-
[5]
Retrieval-augmented generation for large language models: A survey, 2024
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey, 2024. 1
2024
-
[6]
Ramy Harik, Fadi El Kalach, Jad Samaha, Devon Clark, Drew Sander, Philip Samaha, Liam Burns, Ibrahim Yousif, Victor Gadow, Theodros Tarekegne, et al. Analog and multi-modal manufacturing datasets acquired on the future factories platform.arXiv preprint arXiv:2401.15544, 2024. 5
-
[7]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aber- man, Yael Pritch, and Daniel Cohen-Or. Prompt- to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626, 2022. 1, 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Classifier-free diffu- sion guidance, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffu- sion guidance, 2022. 1, 4, 6
2022
-
[9]
Denoising diffusion probabilistic models.Advances in neural in- formation processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural in- formation processing systems, 33:6840–6851, 2020. 2
2020
-
[10]
Rashid, Anisa Rula, Lukas Schmelzeisen, Juan Sequeda, Steffen Staab, and Antoine Zimmermann
Aidan Hogan, Eva Blomqvist, Michael Cochez, Clau- dia D’amato, Gerard De Melo, Claudio Gutierrez, Sabrina Kirrane, Jos ´e Emilio Labra Gayo, Roberto Navigli, Sebastian Neumaier, Axel-Cyrille Ngonga Ngomo, Axel Polleres, Sabbir M. Rashid, Anisa Rula, Lukas Schmelzeisen, Juan Sequeda, Steffen Staab, and Antoine Zimmermann. Knowledge graphs.ACM Computing Sur...
2021
-
[11]
Lexically constrained decoding for sequence generation using grid beam search
Chris Hokamp and Qun Liu. Lexically constrained decoding for sequence generation using grid beam search. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pages 1535–1546, 2017. 4, 6
2017
-
[12]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022. 1, 4, 5, 6
2022
-
[13]
A survey on hallucination in large language mod- els: Principles, taxonomy, challenges, and open ques- tions.ACM Transactions on Information Systems, 43 (2):1–55, 2025
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Wei- hua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language mod- els: Principles, taxonomy, challenges, and open ques- tions.ACM Transactions on Information Systems, 43 (2):1–55, 2025. 1
2025
-
[14]
Survey of hallucination in natural language generation.ACM Computing Sur- veys, 55(12):1–38, 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM Computing Sur- veys, 55(12):1–38, 2023. 1, 4
2023
-
[15]
Retrieval- augmented generation for knowledge-intensive nlp tasks, 2021
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨uttler, Mike Lewis, Wen tau Yih, Tim Rockt ¨aschel, Sebastian Riedel, and Douwe Kiela. Retrieval- augmented generation for knowledge-intensive nlp tasks, 2021. 1, 4, 6
2021
-
[16]
Inference-time inter- vention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530, 2023
Kenneth Li, Oam Patel, Fernanda Vi ´egas, Hanspeter Pfister, and Martin Wattenberg. Inference-time inter- vention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530, 2023. 4, 6
2023
-
[17]
Learn to explain: Multi- modal reasoning via thought chains for science ques- tion answering, 2022
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai- Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multi- modal reasoning via thought chains for science ques- tion answering, 2022. 1
2022
-
[18]
Sdedit: Guided image synthesis and editing with stochastic differential equations, 2022
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations, 2022. 1, 4, 6
2022
-
[19]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InPro- ceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 6038–6047, 2023. 4, 6
2023
-
[20]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agar- wal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Alt- man, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haim- ing Bao, Mohammad Bavarian, Jeff Belgum, Ir- wan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christop...
2024
-
[21]
Unifying large language models and knowledge graphs: A roadmap.IEEE Transactions on Knowledge and Data Engineering, 36 (7):3580–3599, 2024
Shirui Pan, Linhao Luo, Yufei Wang, Chen Chen, Ji- apu Wang, and Xindong Wu. Unifying large language models and knowledge graphs: A roadmap.IEEE Transactions on Knowledge and Data Engineering, 36 (7):3580–3599, 2024. 1
2024
-
[22]
Assemai: Interpretable image-based anomaly detection for manufacturing pipelines
Renjith Prasad, Chathurangi Shyalika, Fadi El Kalach, Revathy Venkataramanan, Ramtin Zand, Ramy Harik, and Amit Sheth. Assemai: Interpretable image-based anomaly detection for manufacturing pipelines. In 2024 International Conference on Machine Learning and Applications (ICMLA), pages 1720–1727. IEEE,
2024
-
[23]
Renjith Prasad, Abhilekh Borah, Hasnat Md Abdul- lah, Chathurangi Shyalika, Gurpreet Singh, Ritvik Garimella, Rajarshi Roy, Harshul Surana, Nasrin Imanpour, Suranjana Trivedy, et al. Detonate: A benchmark for text-to-image alignment and kernel- ized direct preference optimization.arXiv preprint arXiv:2506.14903, 2025. 7
-
[24]
Red-teaming the stable diffusion safety filter.arXiv preprint arXiv:2210.04610,
Javier Rando, Daniel Paleka, David Lindner, Lennart Heim, and Florian Tram`er. Red-teaming the stable dif- fusion safety filter.arXiv preprint arXiv:2210.04610,
-
[25]
High- resolution image synthesis with latent diffusion mod- els, 2022
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High- resolution image synthesis with latent diffusion mod- els, 2022. 1, 2
2022
-
[26]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500–22510, 2023. 1, 4, 6
2023
-
[27]
Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kam- yar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding, 2022. 1
2022
-
[28]
Safe latent diffu- sion: Mitigating inappropriate degeneration in diffu- sion models
Patrick Schramowski, Manuel Brack, Bj ¨orn Deis- eroth, and Kristian Kersting. Safe latent diffu- sion: Mitigating inappropriate degeneration in diffu- sion models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22522–22531, 2023. 7
2023
-
[29]
Shades of knowledge-infused learning for enhancing deep learning.IEEE Internet Computing, 23(6):54–63, 2020
Amit Sheth, Manas Gaur, Ugur Kursuncu, and Ruwan Wickramarachchi. Shades of knowledge-infused learning for enhancing deep learning.IEEE Internet Computing, 23(6):54–63, 2020. 2
2020
-
[30]
Nsf-map: neurosymbolic multimodal fusion for robust and interpretable anomaly prediction in assembly pipelines
Chathurangi Shyalika, Renjith Prasad, Fadi El Kalach, Revathy Venkataramanan, Ramtin Zand, Ramy Harik, and Amit Sheth. Nsf-map: neurosymbolic multimodal fusion for robust and interpretable anomaly prediction in assembly pipelines. InProceedings of the Thirty- Fourth International Joint Conference on Artificial In- telligence, pages 9330–9338, 2025. 5
2025
-
[31]
Jaehong Yoon, Shoubin Yu, Vaidehi Patil, Huaxiu Yao, and Mohit Bansal. Safree: Training-free and adaptive guard for safe text-to-image and video gen- eration.arXiv preprint arXiv:2410.12761, 2024. 7
-
[32]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 3836– 3847, 2023. 1, 4, 6
2023
-
[33]
Knowgpt: Knowl- edge graph based prompting for large language mod- els.Advances in neural information processing sys- tems, 37:6052–6080, 2024
Qinggang Zhang, Junnan Dong, Hao Chen, Daochen Zha, Zailiang Yu, and Xiao Huang. Knowgpt: Knowl- edge graph based prompting for large language mod- els.Advances in neural information processing sys- tems, 37:6052–6080, 2024. 4, 6
2024
-
[34]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down ap- proach to ai transparency, 2023.URL https://arxiv. org/abs/2310.01405, 97, 2022. 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.