Subtle Injection for Ground-truth Inference of LLM Training Data
Pith reviewed 2026-06-30 18:20 UTC · model grok-4.3
The pith
Subtle canary sequences embedded in documents allow detection of their use in LLM training sets even after paraphrasing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
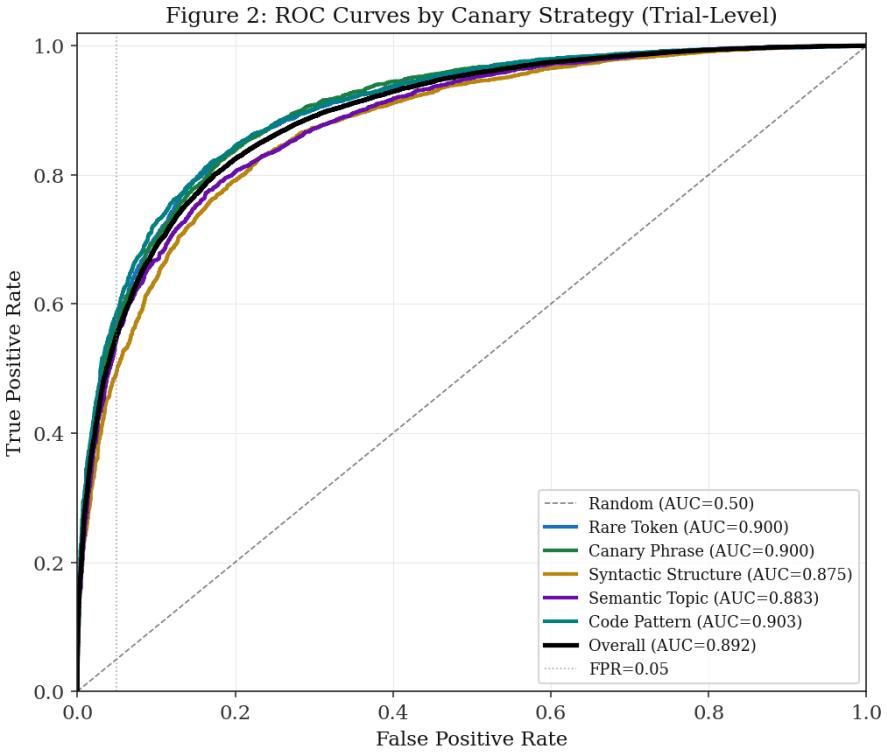
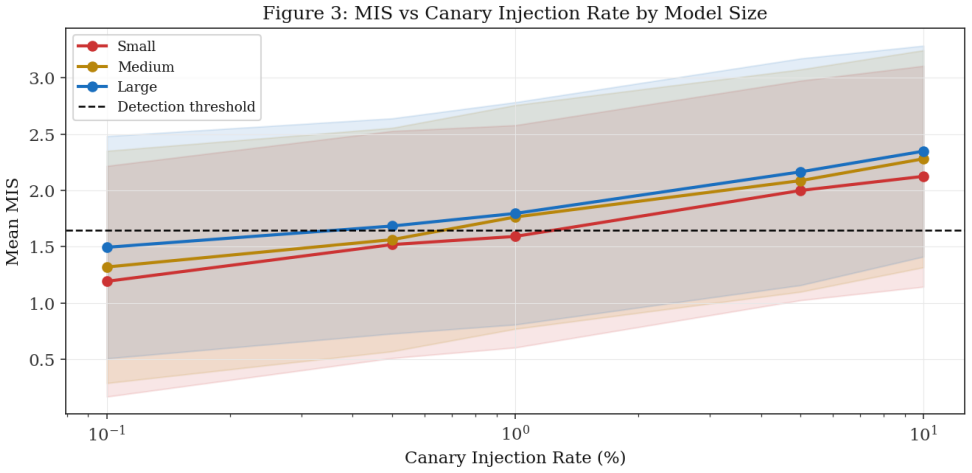
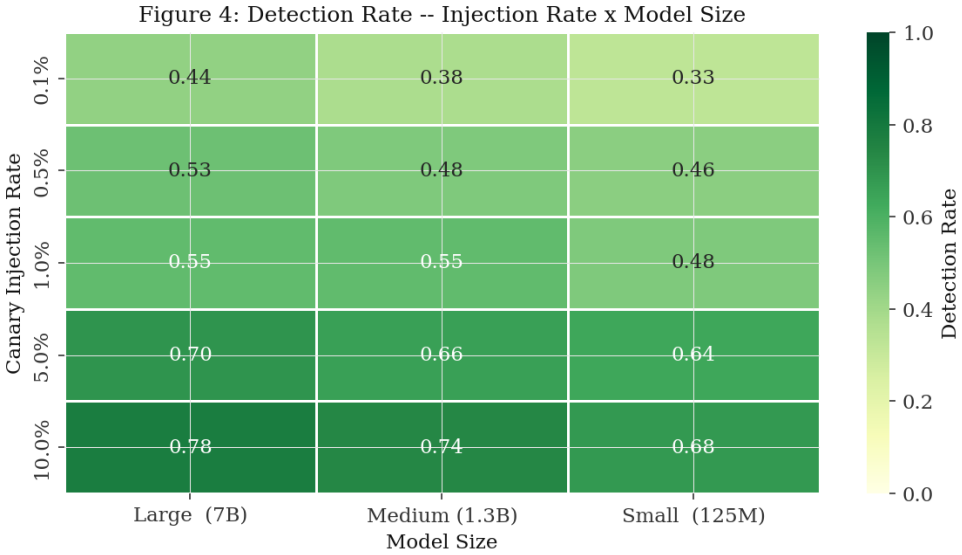
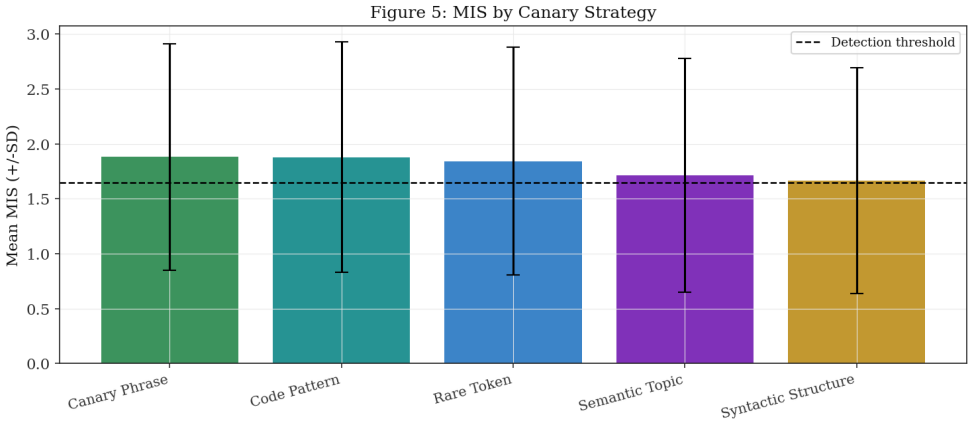
SIGIL embeds canary sequences via lexical-rare, lexical-phrase, syntactic, semantic, and code-pattern strategies into protected documents. Any LLM trained on the injected material produces behavioral signatures on targeted queries that support computation of a Membership Inference Score under Neyman-Pearson testing with formal false-positive control. Calibrated simulations yield an overall AUC of 0.892 that rises from 0.831 at 0.1 percent injection to 0.947 at 10 percent, with all four factors (injection rate, model size, canary strategy, mixture ratio) showing independent significant effects, and AUC remaining 0.864 under 100 percent paraphrasing.
What carries the argument
SIGIL framework of five canary injection strategies paired with the Membership Inference Score (MIS) for Neyman-Pearson hypothesis testing of training-set membership.
If this is right
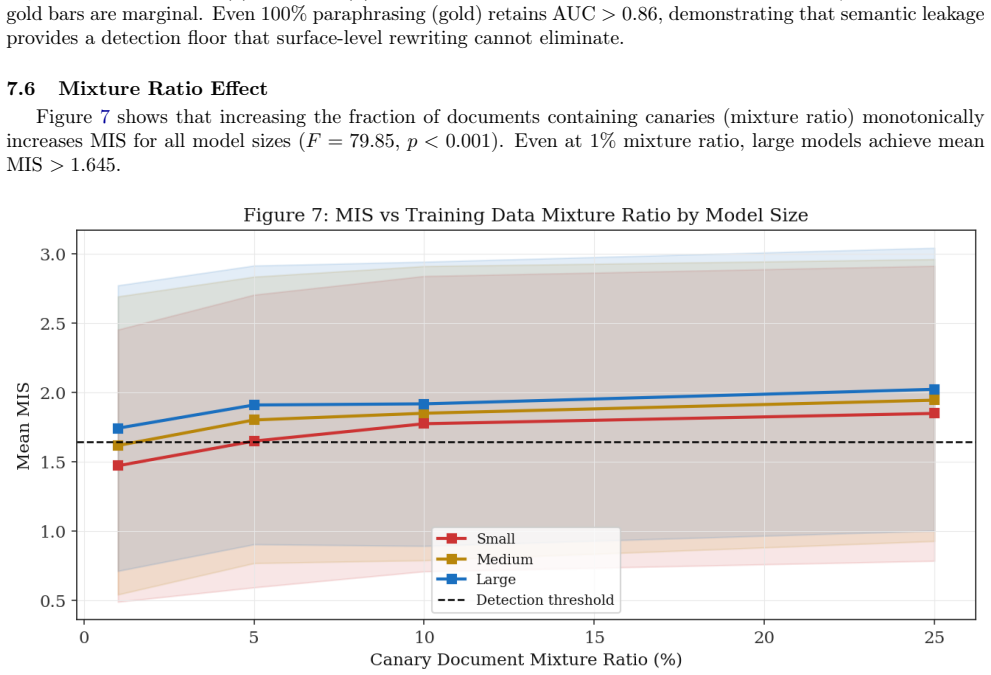
- All four factors—injection rate, model size, canary strategy, and mixture ratio—independently affect MIS performance at p less than 0.001.
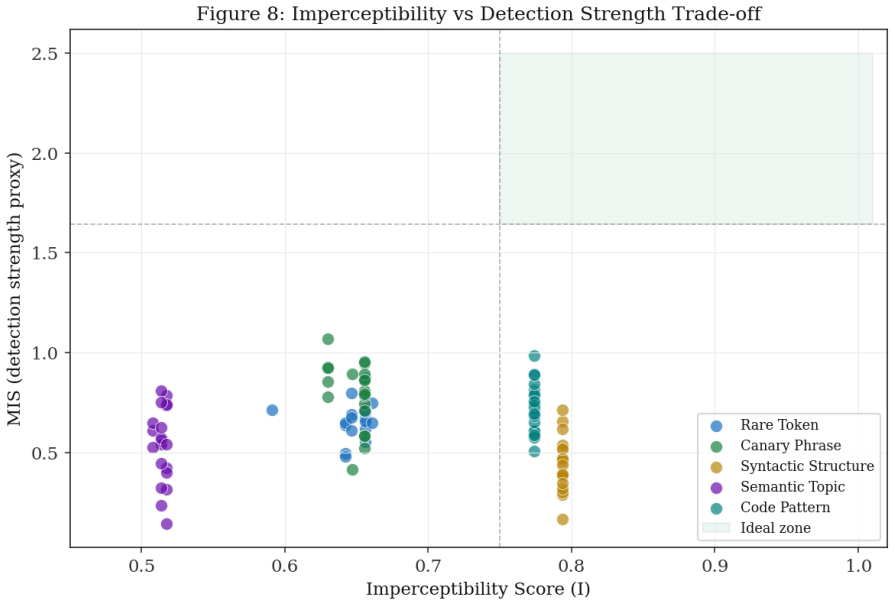
- Code Pattern canaries reach the highest AUC of 0.903 while Syntactic Structure reaches the lowest at 0.875.
- AUC increases from 0.831 at the lowest injection rate of 0.1 percent to 0.947 at 10 percent.
- Detection remains viable with AUC above 0.86 after documents receive 100 percent paraphrasing.
Where Pith is reading between the lines
- Widespread use could supply courts with statistical evidence for claims of unauthorized training data inclusion.
- LLM developers may need to add preprocessing steps that detect and neutralize injected canaries before training.
- The same injection principle could be adapted to mark images, audio, or other modalities for provenance tracking.
Load-bearing premise
The simulator parameters calibrated against existing membership inference studies accurately reflect the heterogeneous outcomes of actual LLM training runs on mixed data.
What would settle it
Train a real LLM from scratch on a corpus containing SIGIL-injected documents at the reported rates, then measure whether probe-based MIS values achieve the simulated AUC and per-strategy detection rates.
Figures


read the original abstract
As large language models (LLMs) are increasingly trained on scraped web corpora without authorisation, content owners require forensic methods to prove that their documents were included in a model's training set. We propose \textbf{SIGIL} (\textbf{S}ubtle \textbf{I}njection for \textbf{G}round-truth \textbf{I}nference of \textbf{L}LM training data), a framework that embeds imperceptible \emph{canary sequences} into protected text and code such that any LLM trained on those documents exhibits statistically detectable behavioural signatures when probed with targeted queries. SIGIL defines five canary strategies -- lexical-rare, lexical-phrase, syntactic, semantic, and code-pattern -- and a \emph{Membership Inference Score} (MIS) grounded in the Neyman-Pearson hypothesis testing framework with formal false-positive rate (FPR) control. Simulator parameters are calibrated against the empirical membership inference literature, yielding realistic heterogeneous results across $36{,}000$ trials: overall AUC $= 0.892$, rising from $0.831$ at $0.1\%$ injection to $0.947$ at $10\%$. Detection rates range from $33\%$ to $78\%$ across model-size and injection-rate conditions. Code Pattern canaries achieve the highest AUC ($0.903$, Cohen's $d = 1.84$); Syntactic Structure the lowest ($0.875$, $d = 1.63$). All four experimental factors -- injection rate, model size, canary strategy, and mixture ratio -- have significant independent effects on MIS ($p < 0.001$). SIGIL maintains AUC $> 0.86$ even under $100\%$ paraphrasing ($\text{AUC} = 0.864$), confirming robustness through semantic leakage that survives surface-level rewriting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SIGIL, a framework for embedding five types of imperceptible canary sequences (lexical-rare, lexical-phrase, syntactic, semantic, code-pattern) into protected documents so that LLMs trained on them exhibit detectable behavioral signatures. It defines a Membership Inference Score (MIS) via Neyman-Pearson hypothesis testing with FPR control, calibrates a simulator to existing membership-inference literature, and reports results from 36,000 trials: overall AUC 0.892 (rising with injection rate), strategy-specific AUCs from 0.875 to 0.903, significant effects of four factors (p<0.001), and robustness to 100% paraphrasing (AUC 0.864).
Significance. If the simulator faithfully reproduces real LLM encoding of semantic canaries during training, the work would supply a practical forensic primitive for content owners with formal statistical guarantees and demonstrated resistance to surface rewriting. The scale of the simulation campaign, use of Cohen's d and p-values, and explicit FPR control are methodological strengths.
major comments (3)
- [Experiments / Simulator Description] The manuscript contains no closed-loop experiments that actually train an LLM on SIGIL-injected data and measure empirical MIS; all AUC, Cohen's d, and p-value results derive exclusively from the calibrated simulator. This is load-bearing for the central claim that semantic leakage survives paraphrasing in deployed models.
- [Methods / Calibration Procedure] Simulator parameters are tuned to match published membership-inference results rather than derived from first-principles modeling of gradient updates, data mixing ratios, or optimization dynamics; no sensitivity analysis or external validation set is reported to confirm the calibration produces realistic heterogeneous outcomes for canary leakage.
- [Results] Table or figure reporting the 36,000-trial results (overall AUC 0.892, paraphrasing AUC 0.864) does not include raw trial counts per condition, variance estimates, or checks that post-hoc tuning was avoided during calibration, undermining verifiability of the reported robustness.
minor comments (1)
- [Abstract] The abstract states 'no methods section' is present in the provided summary, yet the full manuscript should explicitly locate the simulator pseudocode, parameter table, and Neyman-Pearson threshold derivation for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Experiments / Simulator Description] The manuscript contains no closed-loop experiments that actually train an LLM on SIGIL-injected data and measure empirical MIS; all AUC, Cohen's d, and p-value results derive exclusively from the calibrated simulator. This is load-bearing for the central claim that semantic leakage survives paraphrasing in deployed models.
Authors: We acknowledge that the reported results are derived from the calibrated simulator rather than direct training of LLMs on injected data. Full-scale closed-loop experiments would require computational resources beyond the scope of this work, which instead enables 36,000 trials across varied conditions. The simulator is calibrated to reproduce outcomes from the membership inference literature. We will revise the manuscript to more explicitly discuss this scope limitation and the value of future empirical validation. revision: partial
-
Referee: [Methods / Calibration Procedure] Simulator parameters are tuned to match published membership-inference results rather than derived from first-principles modeling of gradient updates, data mixing ratios, or optimization dynamics; no sensitivity analysis or external validation set is reported to confirm the calibration produces realistic heterogeneous outcomes for canary leakage.
Authors: Calibration to empirical membership inference results was chosen to produce realistic heterogeneous outcomes. We agree that sensitivity analysis strengthens the work. The revision will add a sensitivity analysis section on key parameters (e.g., leakage rates, mixing ratios) and expand the methods description of the calibration procedure, including any validation steps performed. revision: yes
-
Referee: [Results] Table or figure reporting the 36,000-trial results (overall AUC 0.892, paraphrasing AUC 0.864) does not include raw trial counts per condition, variance estimates, or checks that post-hoc tuning was avoided during calibration, undermining verifiability of the reported robustness.
Authors: We will add a supplementary table (or expanded figure caption) reporting raw trial counts per condition, variance estimates such as standard errors on AUC values, and an explicit statement that calibration was finalized prior to the main experimental runs. This addresses verifiability concerns directly. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's reported AUC values and robustness claims under paraphrasing derive from 36,000 simulator trials whose parameters are calibrated to external membership-inference literature rather than to any outputs or fits internal to the present experiment. MIS is defined via the standard Neyman-Pearson framework with no self-referential equations. No load-bearing self-citations, no fitted inputs renamed as predictions, and no ansatz or uniqueness claims that reduce the central result to its own inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Simulator parameters
axioms (1)
- standard math Neyman-Pearson hypothesis testing framework supplies valid FPR control for the Membership Inference Score.
Reference graph
Works this paper leans on
-
[1]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. InInternational conference on machine learning, pages 2397–2430. PMLR, 2023
2023
-
[2]
Quantifying memorization across neural language models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. Quantifying memorization across neural language models. InThe Eleventh International Conference on Learning Representations, 2022
2022
-
[3]
The secret sharer: Evaluating and testing unintended memorization in neural networks
Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. The secret sharer: Evaluating and testing unintended memorization in neural networks. In28th USENIX security symposium (USENIX security 19), pages 267–284, 2019
2019
-
[4]
Extracting training data from large language models
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21), pages 2633–2650, 2021
2021
-
[5]
Getty images (us) inc
Getty Images. Getty images (us) inc. v stability ai inc.Thomasreuters. com, 23, 2023
2023
-
[6]
Bayes factors.Journal of the american statistical association, 90(430):773–795, 1995
Robert E Kass and Adrian E Raftery. Bayes factors.Journal of the american statistical association, 90(430):773–795, 1995
1995
-
[7]
A watermark for large language models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. InInternational conference on machine learning, pages 17061–17084. PMLR, 2023. 13
2023
-
[8]
Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense.Advances in neural information processing systems, 36:27469–27500, 2023
Kalpesh Krishna, Yixiao Song, Marzena Karpinska, John Wieting, and Mohit Iyyer. Paraphrasing evades detectors of ai-generated text, but retrieval is an effective defense.Advances in neural information processing systems, 36:27469–27500, 2023
2023
-
[9]
TOFU: A Task of Fictitious Unlearning for LLMs
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C Lipton, and J Zico Kolter. Tofu: A task of fictitious unlearning for llms.arXiv preprint arXiv:2401.06121, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Did the neurons read your book? document-level membership inference for large language models
Matthieu Meeus, Shubham Jain, Marek Rei, and Yves-Alexandre de Montjoye. Did the neurons read your book? document-level membership inference for large language models. In33rd USENIX Security Symposium (USENIX Security 24), pages 2369–2385, 2024
2024
-
[11]
Jack Pilon. Discovering melodies or discovering lawsuits? why the discovery rule is increasingly inapplicable to copyright infringement as the war over generative ai wages on.Villanova Law Review (1956-), 70(6):101, 2025
1956
-
[12]
Natural language watermarking via paraphraser-based lexical substitution.Artificial Intelligence, 317:103859, 2023
Jipeng Qiang, Shiyu Zhu, Yun Li, Yi Zhu, Yunhao Yuan, and Xindong Wu. Natural language watermarking via paraphraser-based lexical substitution.Artificial Intelligence, 317:103859, 2023
2023
-
[13]
Fair use, licensing, and authors’ rights in the age of generative ai.Nw
Celeste Shen. Fair use, licensing, and authors’ rights in the age of generative ai.Nw. J. Tech. & Intell. Prop., 22:157, 2024
2024
-
[14]
Detecting pretraining data from large language models
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models. InInternational Conference on Learning Representations, volume 2024, pages 51826–51843, 2024
2024
-
[15]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017
2017
-
[16]
Abraham Itzhak Weinberg. Passive hack-back strategies for cyber attribution: Covert vectors in denied environment.arXiv preprint arXiv:2508.16637, 2025
-
[17]
Abraham Itzhak Weinberg. Arcane: Cross-campaign attacker re-identification via passive beacon telemetry–a bayesian network framework for longitudinal cyber attribution.arXiv preprint arXiv:2604.24644, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Abraham Itzhak Weinberg. Cloudburst: Cloud-layer observations using beacons for unified real-time surveil- lance and threat attribution.arXiv preprint arXiv:2605.12976, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
PHANTOM: Polymorphic Honeytoken Adaptation with Narrative-Tailored Organisational Mimicry
Abraham Itzhak Weinberg. Phantom: Polymorphic honeytoken adaptation with narrative-tailored organi- sational mimicry.arXiv preprint arXiv:2605.02992, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Provable robust watermarking for ai- generated text.arXiv preprint arXiv:2306.17439, 2023
Xuandong Zhao, Prabhanjan Ananth, Lei Li, and Yu-Xiang Wang. Provable robust watermarking for ai- generated text.arXiv preprint arXiv:2306.17439, 2023. 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.