RTLScout: Joint Agentic Code and Synthesis Optimization for Efficient Digital Circuits
Pith reviewed 2026-06-28 03:56 UTC · model grok-4.3
The pith
LLM agents autonomously refine RTL code and synthesis to cut area by 35% and delay by 45% on a 16-bit floating-point multiplier.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
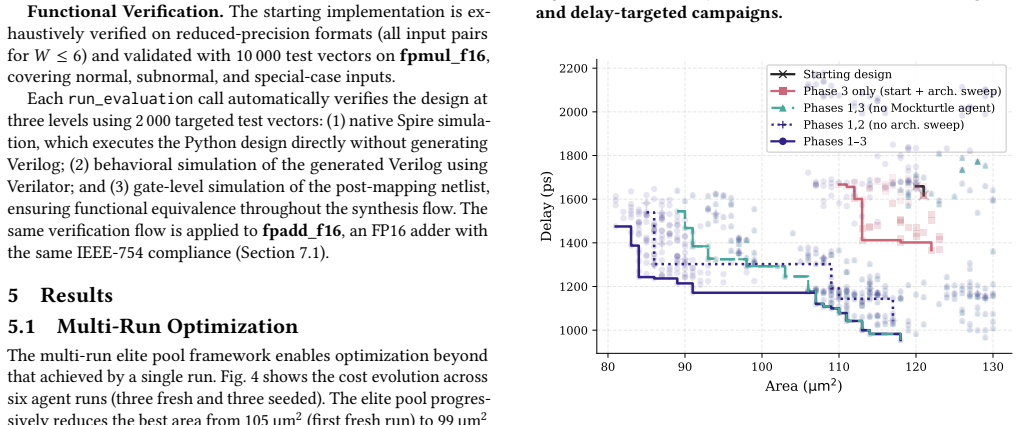
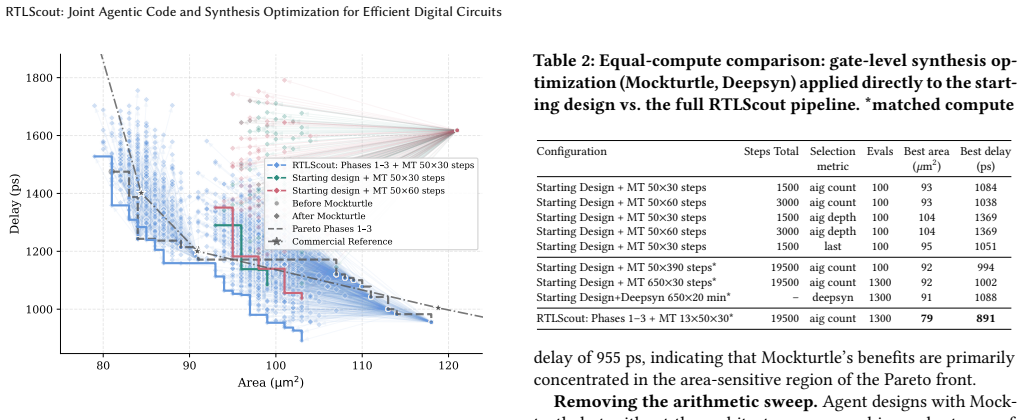
RTLScout demonstrates that an LLM-agent pipeline operating in four phases—agentic code optimization, agentic gate-level rewriting, arithmetic architecture sweeps, and optional high-effort gate-level refinement—can generate functionally correct RTL that, after synthesis, yields 35% smaller area and 45% lower delay than an initial design in ASAP7 technology, with the resulting Pareto front outperforming a commercial reference on the same node.
What carries the argument
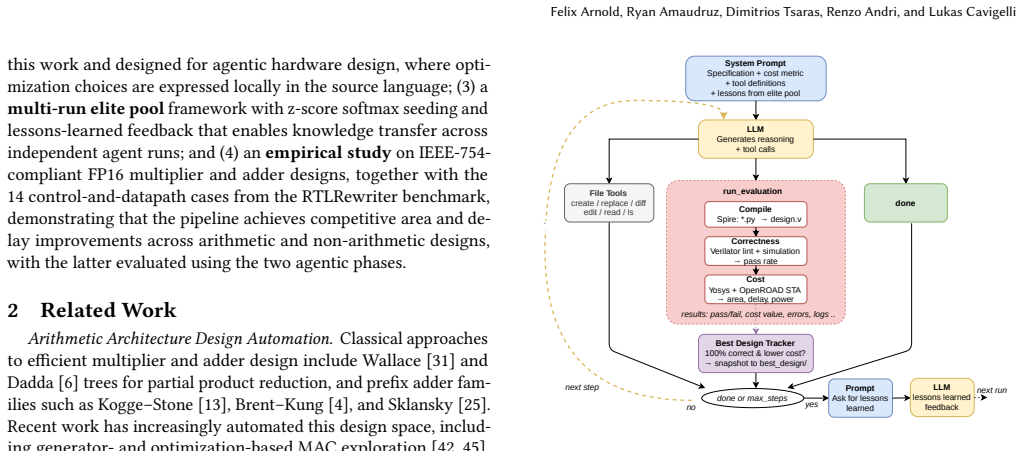
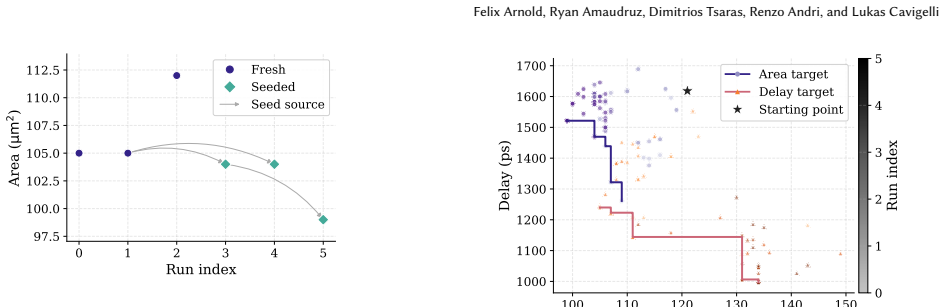
The multi-run elite pool framework, in which the highest-quality designs and learned lessons from prior agent runs seed the next runs, operating across the four complementary optimization phases.
If this is right
- Each of the four phases supplies distinct improvements that compound when applied in sequence.
- High-effort gate-level refinement yields the largest gains when used after the earlier agentic and sweep stages rather than in isolation.
- The final Pareto front lies strictly above the curve obtained from a commercial synthesis tool reference on identical technology.
- The elite-pool transfer of designs and lessons enables progressive improvement across successive agent runs without restarting from scratch.
Where Pith is reading between the lines
- The same phased agentic loop could be applied to other arithmetic blocks such as adders or dividers to test whether the reported gains generalize.
- Adding automated equivalence checking after each agent edit would reduce the risk that an undetected functional bug survives into the final PPA numbers.
- If the method scales to larger modules, it would shorten the number of manual RTL iterations needed to reach a target area-delay point.
Load-bearing premise
The LLM agents produce functionally correct and synthesizable RTL code without introducing bugs that would invalidate the reported power, performance, and area measurements.
What would settle it
A full functional verification suite or formal equivalence check on the final optimized RTL designs that reveals mismatches with the IEEE-754 specification for any input, including subnormals.
Figures

read the original abstract
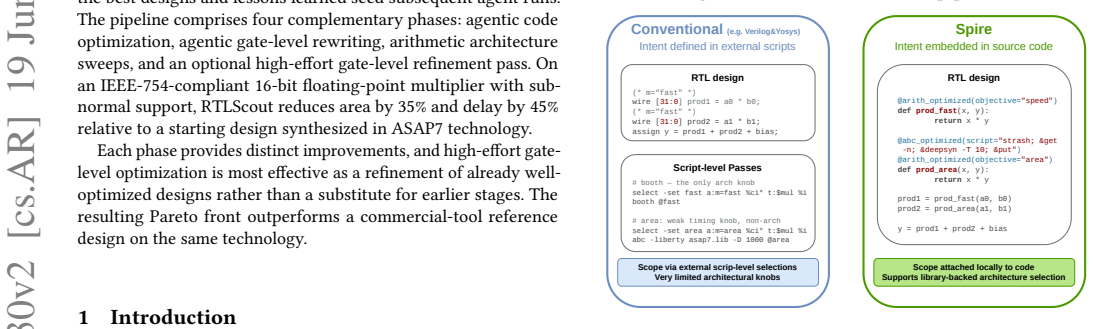
We present RTLScout, an autonomous system that combines LLM-driven agentic design with circuit-level synthesis optimization and arithmetic architecture sweeps. An LLM agent iteratively writes, evaluates, and refines RTL designs using tool calls, guided by quantitative PPA (power, performance, area) feedback from Yosys and OpenROAD. We introduce a multi-run elite pool framework, where the best designs and lessons learned seed subsequent agent runs. The pipeline comprises four complementary phases: agentic code optimization, agentic gate-level rewriting, arithmetic architecture sweeps, and an optional high-effort gate-level refinement pass. On an IEEE-754-compliant 16-bit floating-point multiplier with subnormal support, RTLScout reduces area by 35% and delay by 45% relative to a starting design synthesized in ASAP7 technology. Each phase provides distinct improvements, and high-effort gate-level optimization is most effective as a refinement of already well-optimized designs rather than a substitute for earlier stages. The resulting Pareto front outperforms a commercial-tool reference design on the same technology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. RTLScout is an autonomous LLM-agent system that iteratively generates and refines RTL code for digital circuits, guided by PPA feedback from Yosys and OpenROAD synthesis. It incorporates a multi-run elite-pool framework and four phases (agentic code optimization, gate-level rewriting, arithmetic architecture sweeps, and optional high-effort refinement). On an IEEE-754 16-bit floating-point multiplier with subnormal support in ASAP7 technology, the system reports 35% area and 45% delay reductions relative to a baseline design, with the resulting Pareto front outperforming a commercial-tool reference.
Significance. If the reported designs are functionally correct, the work demonstrates a practical integration of agentic LLMs with synthesis-driven optimization that could reduce manual effort in RTL design exploration. The multi-phase pipeline and elite-pool seeding provide a concrete empirical template for combining code generation with gate-level feedback.
major comments (2)
- [Abstract] Abstract: The headline claims of 35% area and 45% delay reduction (and the Pareto-front comparison to the commercial reference) are load-bearing for the paper's contribution, yet the manuscript provides no evidence that any of the retained elite designs are functionally equivalent to the IEEE-754 specification. No formal equivalence checking, exhaustive subnormal test-vector coverage, or post-synthesis simulation results are reported, leaving open the possibility that synthesizable but incorrect RTL inflates the PPA gains.
- [Pipeline description] The description of the multi-run elite-pool framework (which seeds subsequent agent runs with best designs and lessons) does not specify how functional correctness is enforced or verified across iterations; without this, the transfer of 'useful lessons' cannot be distinguished from retention of buggy but low-PPA candidates.
minor comments (2)
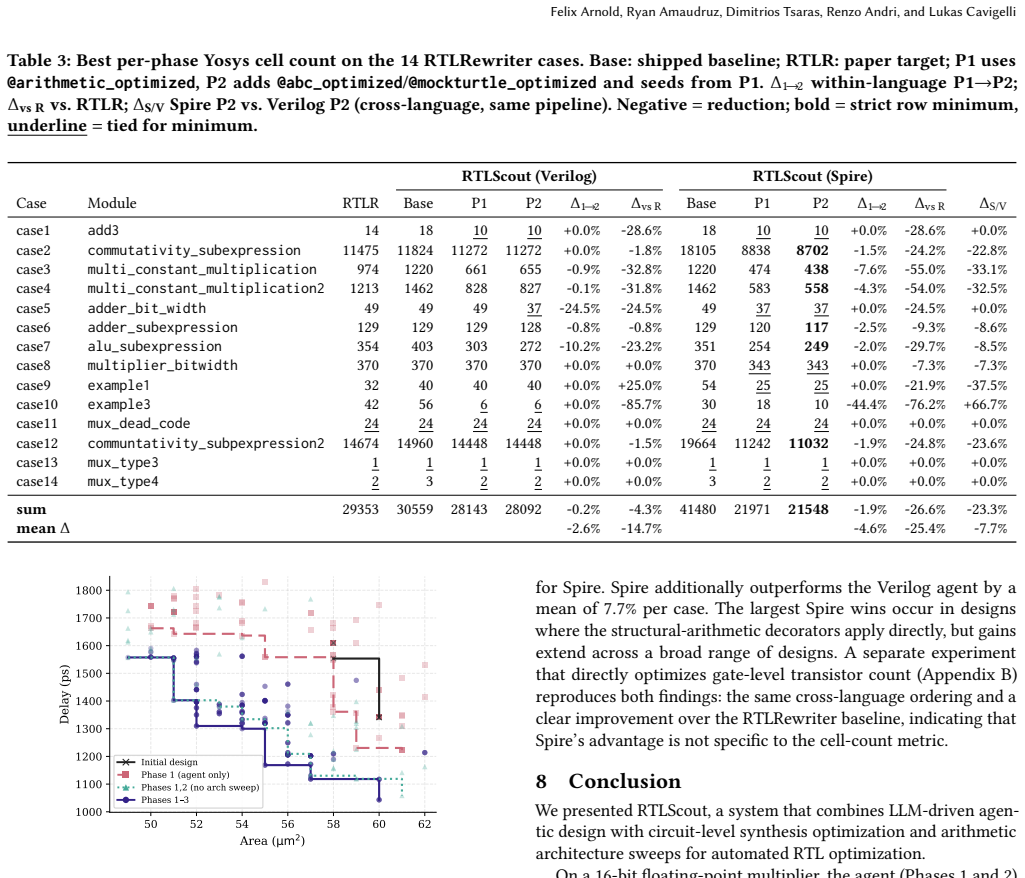
- The four phases are listed but their relative contributions to the final Pareto front are not quantified with per-phase ablation tables or incremental PPA deltas.
- Notation for the commercial-tool reference design and the starting baseline should be standardized (e.g., consistent naming across text and any figures).
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of functional verification, which is critical to substantiate our PPA claims. We agree that the original manuscript insufficiently documented verification procedures and will revise accordingly to provide explicit evidence of correctness for the reported designs.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims of 35% area and 45% delay reduction (and the Pareto-front comparison to the commercial reference) are load-bearing for the paper's contribution, yet the manuscript provides no evidence that any of the retained elite designs are functionally equivalent to the IEEE-754 specification. No formal equivalence checking, exhaustive subnormal test-vector coverage, or post-synthesis simulation results are reported, leaving open the possibility that synthesizable but incorrect RTL inflates the PPA gains.
Authors: We acknowledge this gap in the submitted manuscript. In the revision we will add a new subsection (likely in Section 4 or 5) that details the verification methodology: a directed-random testbench exercising all IEEE-754 16-bit cases including subnormals, NaNs, and rounding modes, with 100% coverage of the 65,536 possible input pairs for the multiplier. All elite-pool designs were required to pass these simulations both pre- and post-synthesis before PPA metrics were recorded. While we did not run commercial formal equivalence tools, the exhaustive simulation results (which will be summarized with pass/fail counts and a link to the test suite) provide concrete evidence that the reported 35%/45% gains are not artifacts of functionally incorrect RTL. We will also clarify that the commercial reference was likewise verified with the same testbench. revision: yes
-
Referee: [Pipeline description] The description of the multi-run elite-pool framework (which seeds subsequent agent runs with best designs and lessons) does not specify how functional correctness is enforced or verified across iterations; without this, the transfer of 'useful lessons' cannot be distinguished from retention of buggy but low-PPA candidates.
Authors: We agree the description was incomplete. The revised manuscript will explicitly state that every RTL candidate generated by the agent undergoes the same simulation-based functional verification described above before it is scored for PPA or admitted to the elite pool. Only passing designs are retained; failed designs are discarded and their failure modes are logged but never used for seeding or lesson extraction. This policy was applied uniformly across all four phases and all multi-run iterations, ensuring that transferred lessons derive exclusively from functionally correct implementations. revision: yes
Circularity Check
No circularity; empirical PPA results from tool-guided optimization
full rationale
The paper describes an iterative LLM-agent pipeline for RTL design refinement using Yosys/OpenROAD PPA feedback and an elite-pool seeding mechanism, then reports measured area/delay reductions on an IEEE-754 16-bit FP multiplier benchmark relative to a baseline and a commercial reference. No equations, fitted parameters, self-definitional metrics, or load-bearing self-citations appear in the derivation; the central claims are direct experimental comparisons without any reduction of outputs to inputs by construction. The method is self-contained against external synthesis tools and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tutu Ajayi, Vidya A Chhabria, Mateus Fogaça, Soheil Hashemi, Abdelrahman Hosny, Andrew B Kahng, Minsoo Kim, Jeongsup Lee, Uday Mallappa, Marina Neseem, et al. 2019. Toward an open-source digital flow: First learnings from the openroad project. InProceedings of the 56th Annual Design Automation Conference
2019
-
[2]
Felix Arnold, Maxence Bouvier, Ryan Amaudruz, Renzo Andri, and Lukas Cav- igelli. 2025. The Art of Beating the Odds with Predictor-Guided Random Design Space Exploration.arXiv preprint arXiv:2502.17936(2025)
arXiv 2025
-
[3]
Robert Brayton and Alan Mishchenko. 2010. ABC: An Academic Industrial- Strength Verification Tool. InProc. International Conference on Computer Aided Verification (CA V). Springer, 24–40
2010
-
[4]
Brent and H
Richard P. Brent and H. T. Kung. 1982. A Regular Layout for Parallel Adders. IEEE Trans. Comput.C-31, 3 (1982), 260–264
1982
-
[5]
Chen Chen, Guangyu Hu, Dongsheng Zuo, Cunxi Yu, Yuzhe Ma, and Hongce Zhang. 2024. E-syn: E-graph rewriting with technology-aware cost functions for logic synthesis. InProceedings of the 61st ACM/IEEE Design Automation Conference. 1–6
2024
-
[6]
Luigi Dadda. 1965. Some Schemes for Parallel Multipliers.Alta Frequenza34 (1965), 349–356
1965
-
[7]
Matthew DeLorenzo, Animesh Basak Chowdhury, Vasudev Gohil, Shailja Thakur, Ramesh Karri, Siddharth Garg, and Jeyavijayan Rajendran. 2024. Make Every Move Count: LLM-based High-Quality RTL Code Generation Using MCTS.arXiv preprint arXiv:2402.03289(2024)
arXiv 2024
-
[8]
Ruogu Ding, Xin Ning, Ulf Schlichtmann, and Weikang Qian. 2026. PrefixGPT: Prefix Adder Optimization by a Generative Pre-trained Transformer. InProceed- ings of the AAAI Conference on Artificial Intelligence, Vol. 40. 20808–20815
2026
-
[9]
Wenji Fang, Yao Lu, Shang Liu, Jing Wang, Ziyan Guo, Junxian He, Fengbin Tu, and Zhiyao Xie. 2026. Dr. RTL: Autonomous Agentic RTL Optimization through Tool-Grounded Self-Improvement.arXiv preprint arXiv:2604.14989(2026)
Pith/arXiv arXiv 2026
-
[10]
Amur Ghose, Andrew B Kahng, Sayak Kundu, and Zhiang Wang. 2025. Orfs- agent: Tool-using agents for chip design optimization. In2025 ACM/IEEE 7th Symposium on Machine Learning for CAD (MLCAD). IEEE, 1–13
2025
-
[11]
Chia-Tung Ho, Haoxing Ren, and Brucek Khailany. 2025. VerilogCoder: Au- tonomous Verilog Coding Agents with Graph-based Planning and Abstract Syntax Tree (AST)-based Waveform Tracing Tool. InProc. AAAI Conference on Artificial Intelligence (AAAI)
2025
-
[12]
Wei-Po Hsin, Ren-Hao Deng, Yao-Ting Hsieh, En-Ming Huang, and Shih-Hao Hung. 2026. EvolVE: Evolutionary Search for LLM-based Verilog Generation and Optimization.arXiv preprint arXiv:2601.18067(2026)
arXiv 2026
-
[13]
Kogge and Harold S
Peter M. Kogge and Harold S. Stone. 1973. A Parallel Algorithm for the Efficient Solution of a General Class of Recurrence Equations.IEEE Trans. Comput.C-22, 8 (1973), 786–793
1973
-
[14]
Pan, and Ping Luo
Yao Lai, Jinxin Liu, David Z. Pan, and Ping Luo. 2024. Scalable and Effective Arithmetic Tree Generation for Adder and Multiplier Designs. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[15]
Per Larsson-Edefors. 2025. Energy-Efficient Computation of TensorFloat32 Numbers on an FP32 Multiplier. InIEEE/IFIP International Conference on VLSI and System-on-Chip (VLSI-SoC). IEEE
2025
-
[16]
Siang-Yun Lee, Alessandro Tempia Calvino, Heinz Riener, and Giovanni De Micheli. 2024. Late Breaking Results: Majority-Inverter Graph Minimiza- tion by Design Space Exploration. InProceedings of the 61st ACM/IEEE De- sign Automation Conference(San Francisco, CA, USA)(DAC ’24). Associa- tion for Computing Machinery, New York, NY, USA, Article 353, 2 pages....
-
[17]
Mingjie Liu, Nathaniel Pinckney, Brucek Khailany, and Haoxing Ren. 2023. Ver- ilogEval: Evaluating Large Language Models for Verilog Code Generation. In Proc. IEEE/ACM International Conference on Computer-Aided Design (ICCAD). 1–8
2023
-
[18]
Shang Liu, Wenji Fang, Yao Lu, Qijun Zhang, Hongce Zhang, and Zhiyao Xie
-
[19]
RTLCoder: Outperforming GPT-3.5 in Design RTL Generation with Our Open-Source Dataset and Lightweight Solution.arXiv preprint arXiv:2312.08617 (2023)
arXiv 2023
-
[20]
Yao Lu, Shang Liu, Qijun Zhang, and Zhiyao Xie. 2024. RTLLM: An Open-Source Benchmark for Design RTL Generation with Large Language Models. InProc. Asia and South Pacific Design Automation Conference (ASP-DAC). 722–727
2024
-
[21]
Kyungjun Min, Kyumin Cho, Junhwan Jang, and Seokhyeong Kang. 2026. REvolu- tion: An Evolutionary Framework for RTL Generation driven by Large Language Models. InProc. Asia and South Pacific Design Automation Conference (ASP-DAC)
2026
-
[22]
Jingyu Pan, Guanglei Zhou, Chen-Chia Chang, Isaac Jacobson, Jiang Hu, and Yiran Chen. 2025. A Survey of Research in Large Language Models for Elec- tronic Design Automation.ACM Transactions on Design Automation of Electronic Systems30, 3 (2025), 1–21. doi:10.1145/3715324
-
[23]
Suresh Purini, Siddhant Garg, Mudit Gaur, Sankalp Bhat, Sohan Mupparapu, and Arun Ravindran. 2025. ArchXBench: A Complex Digital Systems Benchmark Suite for LLM Driven RTL Synthesis. In7th ACM/IEEE Symposium on Machine Learning for CAD, MLCAD 2025, Santa Cruz, CA, USA, September 8-10, 2025. IEEE, 1–10. doi:10.1109/MLCAD65511.2025.11189156
-
[24]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi
-
[25]
Mathematical Discoveries from Program Search with Large Language Models.Nature625 (2024), 468–475
2024
-
[26]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, Alice Oh, Tristan Nauman...
2023
-
[27]
Jack Sklansky. 1960. Conditional-Sum Addition Logic.IRE Transactions on Electronic ComputersEC-9, 2 (1960), 226–231
1960
-
[28]
2003–2026
Wilson Snyder. 2003–2026. Verilator – Open-Source SystemVerilog Simulator and Lint System. https://www.veripool.org/verilator/
2003
-
[29]
Mathias Soeken, Heinz Riener, Winston Haaswijk, and Giovanni De Micheli
-
[30]
arXiv:1805.05121 http://arxiv.org/abs/1805.05121
The EPFL Logic Synthesis Libraries.CoRRabs/1805.05121 (2018). arXiv:1805.05121 http://arxiv.org/abs/1805.05121
arXiv 2018
-
[31]
Shailja Thakur, Baleegh Ahmad, Hammond Pearce, Benjamin Tan, Brendan Dolan-Gavitt, Ramesh Karri, and Siddharth Garg. 2024. VeriGen: A Large Lan- guage Model for Verilog Code Generation.ACM Trans. Design Autom. Electr. Syst.29, 3 (2024), 46:1–46:31. doi:10.1145/3643681
-
[32]
Kiran Thorat et al. 2025. LLM-VeriPPA: Power, Performance, and Area Optimiza- tion aware Verilog Code Generation with Large Language Models.arXiv preprint arXiv:2510.15899(2025)
arXiv 2025
-
[33]
Vinay Vashishtha, Manoj Vangala, and Lawrence T. Clark. 2017. ASAP7 Predic- tive Design Kit Development and Cell Design Technology Co-optimization. In IEEE/ACM International Conference on Computer-Aided Design (ICCAD). IEEE, 992–998
2017
-
[34]
C. S. Wallace. 1964. A Suggestion for a Fast Multiplier.IEEE Transactions on Electronic ComputersEC-13, 1 (1964), 14–17
1964
-
[35]
Yiting Wang, Wanghao Ye, Ping Guo, Yexiao He, Ziyao Wang, Bowei Tian, Shwai He, Guoheng Sun, Zheyu Shen, Sihan Chen, Ankur Srivastava, Qingfu Zhang, Gang Qu, and Ang Li. 2025. SymRTLO: Enhancing RTL Code Optimization with LLMs and Neuron-Inspired Symbolic Reasoning.CoRRabs/2504.10369 (2025). arXiv:2504.10369 doi:10.48550/ARXIV.2504.10369
-
[36]
Zhihai Wang, Jie Wang, Dongsheng Zuo, Ji Yunjie, Xilin Xia, Yuzhe Ma, Jianye Hao, Mingxuan Yuan, Yongdong Zhang, and Feng Wu. 2024. A hierarchical adaptive multi-task reinforcement learning framework for multiplier circuit design. InForty-first international conference on machine learning
2024
-
[37]
Clifford Wolf and Johann Glaser. 2013. Yosys – A Free Verilog Synthesis Suite. InProc. Austrochip
2013
-
[38]
Xilin Xia, Jie Wang, Wanbo Zhang, Zhihai Wang, Mingxuan Yuan, Jianye Hao, and Feng Wu. 2026. High-performance arithmetic circuit optimization via differ- entiable architecture search.Advances in Neural Information Processing Systems 38 (2026), 22208–22241
2026
-
[39]
Chenhao Xue, Kezhi Li, Jiaxing Zhang, Yi Ren, Zhengyuan Shi, Chen Zhang, Yibo Lin, Lining Zhang, Qiang Xu, and Guangyu Sun. 2026. AC-Refiner: Efficient Arithmetic Circuit Optimization Using Conditional Diffusion Models. In2026 31st Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 289–296
2026
-
[40]
Chenhao Xue, Yi Ren, Jinwei Zhou, Kezhi Li, Chen Zhang, Yibo Lin, Lining Zhang, Qiang Xu, and Guangyu Sun. 2025. Domac: Differentiable optimization for high- speed multipliers and multiply-accumulators. In2025 International Symposium of Electronics Design Automation (ISEDA). IEEE, 250–255
2025
-
[41]
Guang Yang et al. 2025. Large Language Model for Verilog Code Generation: Literature Review and the Road Ahead.arXiv preprint arXiv:2512.00020(2025)
arXiv 2025
-
[42]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR)
2023
-
[43]
Xufeng Yao et al. 2024. RTLRewriter: Methodologies for Large Models aided RTL Code Optimization. InProc. IEEE/ACM International Conference on Computer- Aided Design (ICCAD)
2024
-
[44]
Zhongzhi Yu, Mingjie Liu, Michael Zimmer, Yingyan Celine Lin, Yong Liu, and Haoxing Ren. 2025. Spec2RTL-Agent: Automated Hardware Code Generation from Complex Specifications Using LLM Agent Systems.CoRRabs/2506.13905 (2025). arXiv:2506.13905 doi:10.48550/ARXIV.2506.13905
-
[45]
Jiaxi Zhang, Qiuyang Gao, Yijiang Guo, Bizhao Shi, and Guojie Luo. 2022. Easymac: Design exploration-enabled multiplier-accumulator generator using a canonical architectural representation. In2022 27th Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 647–653
2022
-
[46]
Niansong Zhang, Chenhui Deng, Johannes Maximilian Kuehn, Chia-Tung Ho, Cunxi Yu, Zhiru Zhang, and Haoxing Ren. 2025. ASPEN: LLM-Guided E-Graph Rewriting for RTL Datapath Optimization. In2025 ACM/IEEE 7th Symposium on Machine Learning for CAD (MLCAD). IEEE, 1–9
2025
-
[47]
Yizheng Zhao, Haoyu Zhang, Hao Huang, Zhuo Yu, and Junhua Zhao. 2025. MAGE: A Multi-Agent Engine for Automated RTL Code Generation. InProc. Felix Arnold, Ryan Amaudruz, Dimitrios Tsaras, Renzo Andri, and Lukas Cavigelli ACM/IEEE Design Automation Conference (DAC)
2025
-
[48]
Dongsheng Zuo, Jiadong Zhu, Chenglin Li, and Yuzhe Ma. 2024. Ufo-mac: A uni- fied framework for optimization of high-performance multipliers and multiply- accumulators. InProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design. 1–9
2024
-
[49]
Dongsheng Zuo, Jiadong Zhu, Yang Luo, and Yuzhe Ma. 2025. PrefixAgent: An LLM-Powered Design Framework for Efficient Prefix Adder Optimization.arXiv preprint arXiv:2507.06127(2025). Appendix A: LLM Prompts, Feedback Reports, and Decisions This appendix illustrates, for the fpmul_f16 and fpadd_f16 bench- marks, the prompts provided to the agent, the feedba...
arXiv 2025
-
[50]
Try to cover a diverse set of approaches in your plan to increase the chances of finding a good solution [...]
Lay out an action plan. Try to cover a diverse set of approaches in your plan to increase the chances of finding a good solution [...]. Once you find a new best solution, explore close solutions. Trade off exploration with exploitation
-
[51]
[...] [...]
First, create a simple, straightforward design that is functionally correct. [...] [...]
-
[52]
If an optimization breaks correctness, revert and try a different approach
-
[53]
Keep iterating until you run out of steps [...]. The API reference also foregrounds a recurring pitfall: Spire infers signal widths from expressions, meaning concatenations can silently mispack outputs: ### Signal Width Inference - CRITICAL for correct output packing Spire automatically infers signal widths from arithmetic expressions. The result of an ad...
-
[54]
Identify the computationally intensive functions in your design (mux trees, normalization, rounding, etc.)
-
[55]
Wrap them with @mockturtle_optimized using small parameters first (iterations=1, mockturtle_chains=1, mockturtle_chain_len=2) to confirm the flow runs and helps
-
[56]
If optimization times out: either reduce the search budget (see tips above) or split the function into smaller sub-functions and decorate each one
-
[57]
Evaluate after each change to verify correctness and measure cost improvement. For fpmul_f16 and fpadd_f16, the specification embedded in the system prompt points the agent at a provided, already-correct starting_point.py implementation in its workspace and instructs it to optimize from that baseline. These runs therefore begin from a functionally correct...
arXiv 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.