Robots Need More than VLA and World Models
Pith reviewed 2026-06-28 00:58 UTC · model grok-4.3
The pith
The central bottleneck for generalist robots is the absence of interfaces that turn unstructured behavioral data into grounded supervision, beyond scaling VLA models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
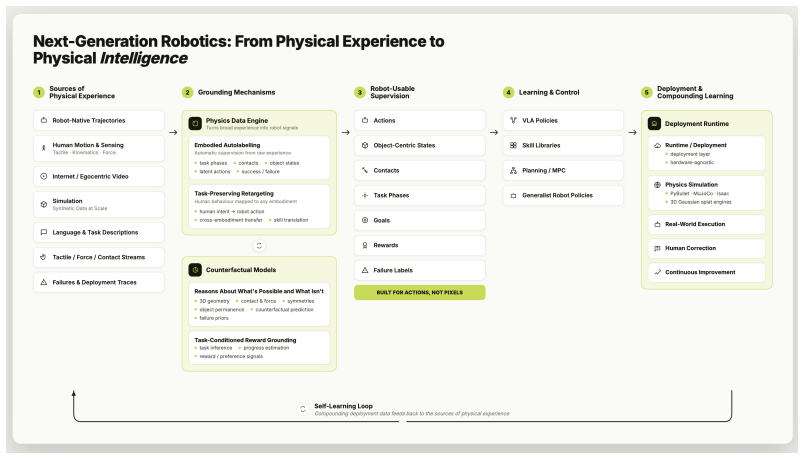
The authors state that generalist robot intelligence is incomplete when framed only as policy scaling; the central bottleneck is the absence of mechanisms that convert unstructured behavioural data into grounded robot supervision, and they identify four missing components: data interfaces for autolabelling unstructured behaviour, embodiment interfaces for retargeting human motion to robot actions, world-model interfaces for physics-grounded 3D reasoning, and reward interfaces for inferring task progress and success from video and language.
What carries the argument
The four interfaces (data autolabelling for task semantics and action labels, embodiment retargeting from human to robot, world-model interfaces for physics-grounded reasoning, and reward interfaces for inferring progress from observations) that convert unstructured behavioural data into forms usable by robot policies.
If this is right
- Robot learning systems can draw supervision from human motion, internet video, simulation rollouts, and interactive demonstrations in addition to robot demonstrations.
- Data autolabelling methods must supply embodiment-specific action labels and task semantics that current datasets lack.
- Embodiment retargeting must map human motion onto robot kinematics while preserving contact and constraint information.
- World-model interfaces must supply physics-grounded 3D representations that allow reasoning about failures and physical limits.
- Reward interfaces must extract task progress and success signals directly from video and language without hand-engineered rewards.
Where Pith is reading between the lines
- If the interfaces prove workable, data collection for robotics could shift from active robot teleoperation toward large-scale passive recording of human and simulated behavior.
- Progress on these interfaces may depend more on advances in video understanding and cross-embodiment transfer than on further increases in model parameter count.
- The approach opens the possibility that robots could acquire new skills by observing the physical world without explicit demonstration of every task.
Load-bearing premise
That the four proposed interfaces are the primary and sufficient missing components rather than other factors such as hardware limits or scaling laws themselves.
What would settle it
A controlled comparison showing that a VLA model scaled solely on robot demonstrations achieves comparable generalization across diverse tasks and embodiments to a system that incorporates the four interfaces on unstructured data would falsify the central claim.
Figures
read the original abstract
Generalist robot intelligence is often framed as a policy-scaling problem: collect more robot demonstrations, train larger Vision-Language-Action (VLA) models, and expect broader generalisation. In this position paper, we argue that this framing is incomplete. The central bottleneck is not only policy learning, but the absence of mechanisms that convert the world's abundant unstructured behavioural data into grounded robot supervision. Human motion, internet video, simulation rollouts, and interactive demonstrations contain rich information about tasks, goals, contacts, failures, and physical constraints, yet most of this information is not directly usable by robot policies because it lacks embodiment-specific action labels, task semantics, and reward structure. We identify four missing components for the next generation of robotics: data interfaces for autolabelling unstructured behaviour, embodiment interfaces for retargeting human motion to robot actions, world-model interfaces for physics-grounded 3D reasoning, and reward interfaces for inferring task progress and success from video and language. We survey recent progress in robot foundation models, cross-embodiment datasets, learning from video, world models, and reward modelling, and propose a research agenda for building robotics systems that can learn not only from robot demonstrations, but from the broader physical world.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a position paper arguing that generalist robot intelligence cannot be achieved solely by scaling Vision-Language-Action (VLA) models on robot demonstrations. The central bottleneck is instead the lack of mechanisms to convert abundant unstructured behavioral data (human motion, internet video, simulation rollouts, interactive demonstrations) into grounded robot supervision with embodiment-specific labels, task semantics, and reward structure. It identifies four missing interface categories—data autolabelling, embodiment retargeting, world-model interfaces for physics-grounded 3D reasoning, and reward interfaces for inferring progress from video/language—surveys related work in robot foundation models, cross-embodiment datasets, video learning, world models, and reward modelling, and proposes a corresponding research agenda.
Significance. If the four interfaces are the primary bottlenecks, the paper could usefully redirect robotics research toward systems that exploit non-robot data at scale, addressing data scarcity and grounding limitations beyond current VLA approaches. Its conceptual framing and survey of recent progress provide a coherent research agenda whose value will be determined by whether it inspires concrete implementations and empirical tests.
minor comments (1)
- [Title and Abstract] The title states that robots need 'more than VLA and World Models,' yet the body positions world-model interfaces as one of the four required components; this tension could be clarified in the title or abstract to prevent misreading.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript and for recommending minor revision. The referee's assessment correctly identifies the paper as a position piece that frames the four interfaces as central bottlenecks and surveys related work to outline a research agenda. No specific major comments were raised in the report.
Circularity Check
No significant circularity in position paper
full rationale
The manuscript is a position paper that identifies four interface categories as missing components and surveys related work, without presenting new empirical results, formal derivations, or falsifiable predictions. The central claim is therefore an argument for a research agenda rather than a proposition whose internal consistency or empirical support can be load-bearingly tested. No equations, fitted parameters, self-citations that are load-bearing, or self-referential derivations are present; the argument is high-level and conceptual.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2403.12945 , year=
Droid: A large-scale in-the-wild robot manipulation dataset , author=. arXiv preprint arXiv:2403.12945 , year=
-
[2]
arXiv preprint arXiv:2512.13080 , year=
Spatial-Aware VLA Pretraining through Visual-Physical Alignment from Human Videos , author=. arXiv preprint arXiv:2512.13080 , year=
-
[3]
Conference on Robot Learning , pages=
Real-world robot learning with masked visual pre-training , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[4]
arXiv preprint arXiv:2509.25358 , year=
SARM: Stage-Aware Reward Modeling for Long Horizon Robot Manipulation , author=. arXiv preprint arXiv:2509.25358 , year=
-
[5]
IEEE Robotics and Automation Letters , year=
Sous vide: Cooking visual drone navigation policies in a gaussian splatting vacuum , author=. IEEE Robotics and Automation Letters , year=
-
[6]
arXiv preprint arXiv:2509.18610 , year=
SINGER: An onboard generalist vision-language navigation policy for drones , author=. arXiv preprint arXiv:2509.18610 , year=
-
[7]
2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
GRaD-Nav: Efficiently learning visual drone navigation with gaussian radiance fields and differentiable dynamics , author=. 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2025 , organization=
2025
-
[8]
IEEE Robotics and Automation Letters , volume=
Grad-nav++: Vision-language model enabled visual drone navigation with gaussian radiance fields and differentiable dynamics , author=. IEEE Robotics and Automation Letters , volume=. 2025 , publisher=
2025
-
[9]
Proceedings of Robotics: Science and Systems (RSS) , year=
RMA: Rapid motor adaptation for legged robots , author=. Proceedings of Robotics: Science and Systems (RSS) , year=
-
[10]
arXiv preprint arXiv:2510.11689 , year=
Phys2Real: Fusing VLM Priors with Interactive Online Adaptation for Uncertainty-Aware Sim-to-Real Manipulation , author=. arXiv preprint arXiv:2510.11689 , year=
-
[11]
arXiv preprint arXiv:2512.05927 , year=
World Models That Know When They Don't Know: Controllable Video Generation with Calibrated Uncertainty , author=. arXiv preprint arXiv:2512.05927 , year=
-
[12]
arXiv preprint arXiv:2603.06987 , year=
Foundational World Models Accurately Detect Bimanual Manipulator Failures , author=. arXiv preprint arXiv:2603.06987 , year=
-
[13]
arXiv preprint arXiv:2504.16680 , year=
Uncertainty-Aware Robotic World Model Makes Offline Model-Based Reinforcement Learning Work on Real Robots , author=. arXiv preprint arXiv:2504.16680 , year=
-
[14]
ICLR 2026 the 2nd Workshop on World Models: Understanding, Modelling and Scaling , year=
World Action Models are Zero-shot Policies , author=. ICLR 2026 the 2nd Workshop on World Models: Understanding, Modelling and Scaling , year=
2026
-
[15]
arXiv preprint arXiv:2503.00200 , year=
Unified video action model , author=. arXiv preprint arXiv:2503.00200 , year=
-
[16]
arXiv preprint arXiv:2307.00595 , year=
Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot , author=. arXiv preprint arXiv:2307.00595 , year=
-
[17]
2025 , month = feb, day =
2025
-
[18]
arXiv preprint arXiv:2604.07993 , year=
HEX: Humanoid-Aligned Experts for Cross-Embodiment Whole-Body Manipulation , author=. arXiv preprint arXiv:2604.07993 , year=
-
[19]
2026 , eprint=
Humanoid Manipulation Interface: Humanoid Whole-Body Manipulation from Robot-Free Demonstrations , author=. 2026 , eprint=
2026
-
[20]
Building the General-Purpose Robotic Brain , year =
-
[21]
arXiv preprint arXiv:2512.11047 , year=
Wholebodyvla: Towards unified latent vla for whole-body loco-manipulation control , author=. arXiv preprint arXiv:2512.11047 , year=
-
[22]
arXiv preprint arXiv:2506.13751 , year=
Leverb: Humanoid whole-body control with latent vision-language instruction , author=. arXiv preprint arXiv:2506.13751 , year=
-
[23]
arXiv preprint arXiv:2510.21746 , year=
Avi: Action from Volumetric Inference , author=. arXiv preprint arXiv:2510.21746 , year=
-
[24]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Graphcot-vla: A 3d spatial-aware reasoning vision-language-action model for robotic manipulation with ambiguous instructions , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[25]
arXiv preprint arXiv:2508.09071 , year=
Geovla: Empowering 3d representations in vision-language-action models , author=. arXiv preprint arXiv:2508.09071 , year=
-
[26]
9th Annual Conference on Robot Learning , year=
3ds-vla: A 3d spatial-aware vision language action model for robust multi-task manipulation , author=. 9th Annual Conference on Robot Learning , year=
-
[27]
2025 , eprint=
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model , author=. 2025 , eprint=
2025
-
[28]
arXiv preprint arXiv:2407.01310 , year=
Multi-State-Action Tokenisation in Decision Transformers for Multi-Discrete Action Spaces , author=. arXiv preprint arXiv:2407.01310 , year=
-
[29]
arXiv preprint arXiv:2507.01925 , year=
A survey on vision-language-action models: An action tokenization perspective , author=. arXiv preprint arXiv:2507.01925 , year=
-
[30]
arXiv preprint arXiv:2602.15397 , year=
ActionCodec: What Makes for Good Action Tokenizers , author=. arXiv preprint arXiv:2602.15397 , year=
-
[31]
arXiv preprint arXiv:2512.04952 , year=
FASTer: Toward Efficient Autoregressive Vision Language Action Modeling via Neural Action Tokenization , author=. arXiv preprint arXiv:2512.04952 , year=
-
[32]
arXiv preprint arXiv:2501.09747 , year=
Fast: Efficient action tokenization for vision-language-action models , author=. arXiv preprint arXiv:2501.09747 , year=
-
[33]
Advances in Neural Information Processing Systems , volume=
Robomamba: Efficient vision-language-action model for robotic reasoning and manipulation , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
arXiv preprint arXiv:2411.19650 , year=
Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation , author=. arXiv preprint arXiv:2411.19650 , year=
-
[35]
arXiv preprint arXiv:2410.07864 , year=
Rdt-1b: a diffusion foundation model for bimanual manipulation , author=. arXiv preprint arXiv:2410.07864 , year=
-
[36]
arXiv preprint arXiv:2411.03540 , year=
Vla-3d: A dataset for 3d semantic scene understanding and navigation , author=. arXiv preprint arXiv:2411.03540 , year=
-
[37]
Optical Memory and Neural Networks , volume=
Spatial traces: Enhancing vla models with spatial-temporal understanding , author=. Optical Memory and Neural Networks , volume=. 2025 , publisher=
2025
-
[38]
arXiv preprint arXiv:2501.15830 , year=
Spatialvla: Exploring spatial representations for visual-language-action model , author=. arXiv preprint arXiv:2501.15830 , year=
-
[39]
arXiv preprint arXiv:2205.06175 , year=
A generalist agent , author=. arXiv preprint arXiv:2205.06175 , year=
-
[40]
arXiv preprint arXiv:2503.20020 , year=
Gemini robotics: Bringing ai into the physical world , author=. arXiv preprint arXiv:2503.20020 , year=
-
[41]
arXiv preprint arXiv:2504.16693 , year=
PIN-WM: Learning Physics-INformed World Models for Non-Prehensile Manipulation , author=. arXiv preprint arXiv:2504.16693 , year=
-
[42]
2026 , eprint=
ContactGaussian-WM: Learning Physics-Grounded World Model from Videos , author=. 2026 , eprint=
2026
-
[43]
arXiv preprint arXiv:2503.14734 , year=
Gr00t n1: An open foundation model for generalist humanoid robots , author=. arXiv preprint arXiv:2503.14734 , year=
-
[44]
arXiv preprint arXiv:2508.17600 , year=
GWM: Towards Scalable Gaussian World Models for Robotic Manipulation , author=. arXiv preprint arXiv:2508.17600 , year=
-
[45]
Proceedings of the 18th international conference on autonomous agents and multiagent systems , pages=
Safe policy search using Gaussian process models , author=. Proceedings of the 18th international conference on autonomous agents and multiagent systems , pages=
-
[46]
2024 , eprint=
PhysGaussian: Physics-Integrated 3D Gaussians for Generative Dynamics , author=. 2024 , eprint=
2024
-
[47]
2020 , eprint=
Learning to Simulate Complex Physics with Graph Networks , author=. 2020 , eprint=
2020
-
[48]
2018 , eprint=
Graph networks as learnable physics engines for inference and control , author=. 2018 , eprint=
2018
-
[49]
2017 , eprint=
A Compositional Object-Based Approach to Learning Physical Dynamics , author=. 2017 , eprint=
2017
-
[50]
Peter W. Battaglia and Razvan Pascanu and Matthew Lai and Danilo Jimenez Rezende and Koray Kavukcuoglu , title =. CoRR , volume =. 2016 , url =. 1612.00222 , timestamp =
Pith/arXiv arXiv 2016
-
[51]
Yaofeng Desmond Zhong and Biswadip Dey and Amit Chakraborty , title =. CoRR , volume =. 2019 , url =. 1909.12077 , timestamp =
arXiv 2019
-
[52]
Cranmer and Sam Greydanus and Stephan Hoyer and Peter W
Miles D. Cranmer and Sam Greydanus and Stephan Hoyer and Peter W. Battaglia and David N. Spergel and Shirley Ho , title =. CoRR , volume =. 2020 , url =. 2003.04630 , timestamp =
arXiv 2020
-
[53]
Sam Greydanus and Misko Dzamba and Jason Yosinski , title =. CoRR , volume =. 2019 , url =. 1906.01563 , timestamp =
arXiv 2019
-
[54]
Michael Lutter and Christian Ritter and Jan Peters , title =. CoRR , volume =. 2019 , url =. 1907.04490 , timestamp =
Pith/arXiv arXiv 2019
-
[55]
2025 , eprint=
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning , author=. 2025 , eprint=
2025
-
[56]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Self-supervised learning from images with a joint-embedding predictive architecture , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[57]
2, 2022-06-27 , author=
A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27 , author=. Open Review , volume=
2022
-
[58]
Assessing Transferability From Simulation to Reality for Reinforcement Learning , volume=
Muratore, Fabio and Gienger, Michael and Peters, Jan , year=. Assessing Transferability From Simulation to Reality for Reinforcement Learning , volume=. IEEE Transactions on Pattern Analysis and Machine Intelligence , publisher=. doi:10.1109/tpami.2019.2952353 , number=
-
[59]
Machine Learning , volume=
Samba: Safe model-based & active reinforcement learning , author=. Machine Learning , volume=. 2022 , publisher=
2022
-
[60]
Proceedings of the 28th International Conference on machine learning (ICML-11) , pages=
PILCO: A model-based and data-efficient approach to policy search , author=. Proceedings of the 28th International Conference on machine learning (ICML-11) , pages=
-
[61]
Andrew and Peters, Jan , title =
Kober, Jens and Bagnell, J. Andrew and Peters, Jan , title =. International Journal of Robotics Research , volume =. 2013 , doi =
2013
-
[62]
2025 , eprint=
ParticleFormer: A 3D Point Cloud World Model for Multi-Object, Multi-Material Robotic Manipulation , author=. 2025 , eprint=
2025
-
[63]
2026 , eprint=
PointWorld: Scaling 3D World Models for In-The-Wild Robotic Manipulation , author=. 2026 , eprint=
2026
-
[64]
2025 , eprint=
Object-Centric World Model for Language-Guided Manipulation , author=. 2025 , eprint=
2025
-
[65]
2023 , eprint=
FOCUS: Object-Centric World Models for Robotics Manipulation , author=. 2023 , eprint=
2023
-
[66]
Forty-first International Conference on Machine Learning , year=
Genie: Generative Interactive Environments , author=. Forty-first International Conference on Machine Learning , year=
-
[67]
2024 , eprint=
Learning Interactive Real-World Simulators , author=. 2024 , eprint=
2024
-
[68]
2024 , eprint=
RoboDreamer: Learning Compositional World Models for Robot Imagination , author=. 2024 , eprint=
2024
-
[69]
2022 , eprint=
DayDreamer: World Models for Physical Robot Learning , author=. 2022 , eprint=
2022
-
[70]
Nature , volume=
Mastering diverse control tasks through world models , author=. Nature , volume=. 2025 , publisher=
2025
-
[71]
arXiv preprint arXiv:2509.26627 , year=
TimeRewarder: Learning Dense Reward from Passive Videos via Frame-wise Temporal Distance , author=. arXiv preprint arXiv:2509.26627 , year=
-
[72]
2019 , eprint=
RLBench: The Robot Learning Benchmark & Learning Environment , author=. 2019 , eprint=
2019
-
[73]
Lillicrap and Mohammad Norouzi and Jimmy Ba , title =
Danijar Hafner and Timothy P. Lillicrap and Mohammad Norouzi and Jimmy Ba , title =. CoRR , volume =. 2020 , url =. 2010.02193 , timestamp =
Pith/arXiv arXiv 2020
-
[74]
International Conference on Machine Learning (ICML) , year=
Learning Latent Dynamics for Planning from Pixels , author=. International Conference on Machine Learning (ICML) , year=
-
[75]
2018 , eprint=
Recurrent World Models Facilitate Policy Evolution , author=. 2018 , eprint=
2018
-
[76]
Lillicrap and Jimmy Ba and Mohammad Norouzi , title =
Danijar Hafner and Timothy P. Lillicrap and Jimmy Ba and Mohammad Norouzi , title =. CoRR , volume =. 2019 , url =. 1912.01603 , timestamp =
Pith/arXiv arXiv 2019
-
[77]
Ha, David and Schmidhuber, Jürgen , title =. 2018 , copyright =. doi:10.5281/ZENODO.1207631 , url =
-
[78]
2022 , eprint=
Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning , author=. 2022 , eprint=
2022
-
[79]
Hwangbo, Jemin and Lee, Joonho and Dosovitskiy, Alexey and Bellicoso, Dario and Tsounis, Vassilios and Koltun, Vladlen and Hutter, Marco , year=. Learning agile and dynamic motor skills for legged robots , volume=. Science Robotics , publisher=. doi:10.1126/scirobotics.aau5872 , number=
-
[80]
2025 , eprint=
RoboGSim: A Real2Sim2Real Robotic Gaussian Splatting Simulator , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.