Improving Cross-Lingual Factual Recall via Consistency-Driven Reinforcement Learning
Pith reviewed 2026-06-28 01:47 UTC · model grok-4.3
The pith
GRPO training improves cross-lingual factual consistency and generalization in LLMs more than supervised fine-tuning or continual pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
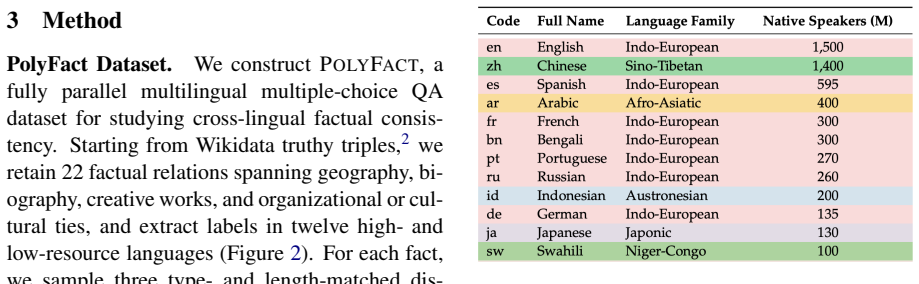
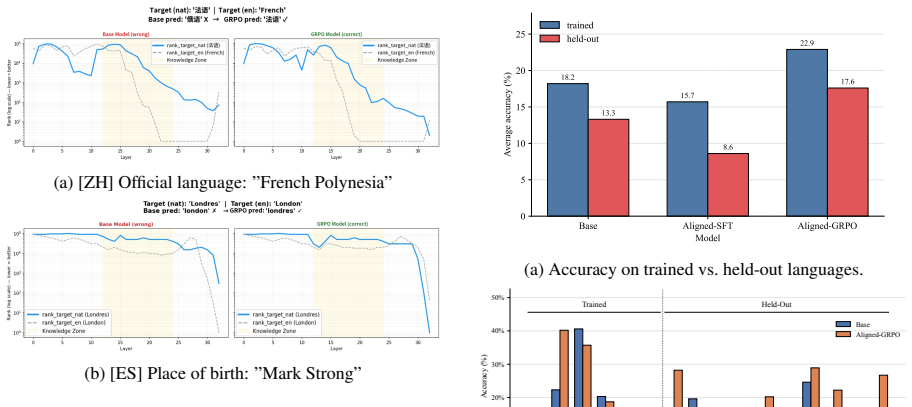
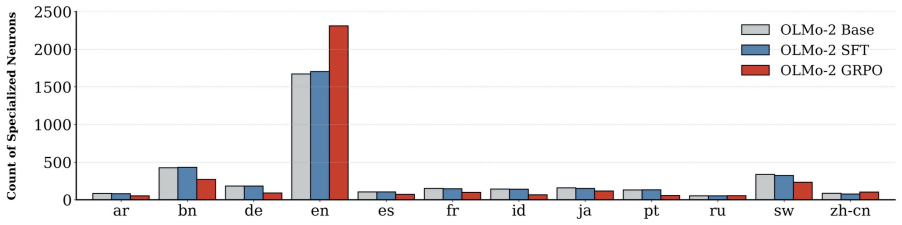
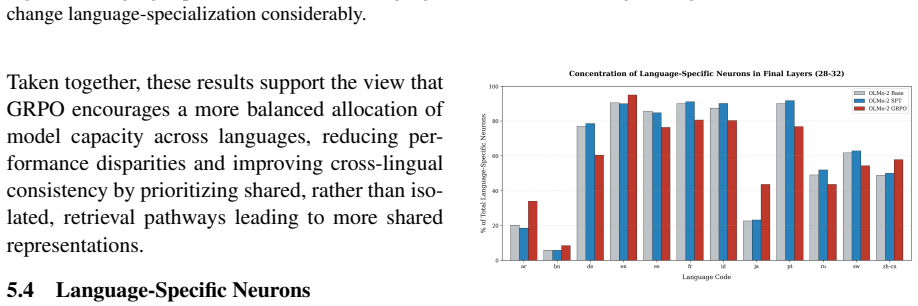
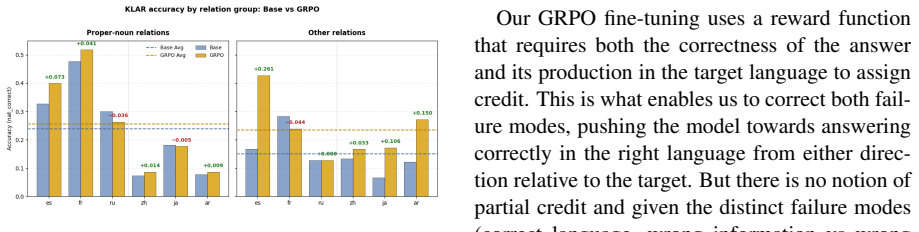
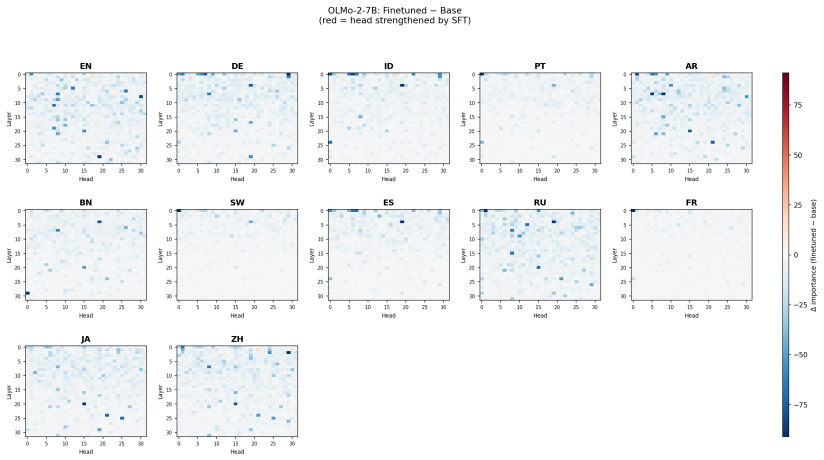
Using PolyFact, GRPO consistently outperforms SFT on cross-lingual factual recall and consistency while also generalizing to languages absent from training; CPT on parallel data adds only limited value. GRPO achieves these results by reorganizing multilingual routing, specifically by reducing language specialization in MLP layers and attention heads and thereby promoting more shared cross-lingual representations.
What carries the argument
Group Relative Policy Optimization (GRPO) applied as consistency-driven reinforcement learning on parallel factual data.
If this is right
- GRPO improves factual recall on both training languages and unseen languages.
- GRPO reduces language specialization in MLP layers and attention heads.
- Continual pretraining on parallel data yields only limited additional gains over the base models.
- The resulting models exhibit higher cross-lingual consistency on factual questions.
- The same training approach can be applied to the two tested 7B-scale models.
Where Pith is reading between the lines
- PolyFact could serve as a reusable benchmark for measuring cross-lingual consistency beyond the methods tested here.
- Similar consistency-driven RL objectives might address other forms of internal inconsistency, such as in multi-step reasoning across languages.
- If language specialization is the main bottleneck, further reductions could improve transfer to very low-resource languages not included in PolyFact.
Load-bearing premise
The observed gains in consistency and generalization are produced by the GRPO objective rather than by differences in training compute, hyperparameter choices, or properties of the PolyFact data construction.
What would settle it
A controlled experiment that equalizes total training steps, learning rate schedule, batch size, and data composition between GRPO and SFT and finds no remaining advantage for GRPO would falsify the claim.
Figures









read the original abstract
Large language models (LLMs) trained predominantly on English data encode substantial world knowledge, yet often fail to express it reliably in other languages, a phenomenon known as cross-lingual factual inconsistency. To study and address this, we introduce PolyFact, a large-scale parallel multilingual factual QA dataset containing 100K Wikidata-grounded facts across 12 typologically diverse languages. Using PolyFact, we compare light continual pretraining (CPT), supervised fine-tuning (SFT), and reinforcement learning via Group Relative Policy Optimization (GRPO) for improving cross-lingual factual recall in Qwen-2.5-7B and OLMo-2-1124-7B. We find that GRPO consistently outperforms SFT, improving both cross-lingual consistency and generalization to unseen languages, while CPT on parallel data yields limited additional gains. Mechanistic analyses further show that GRPO reorganizes multilingual routing by reducing language specialization in MLP layers and attention heads, thereby promoting more shared cross-lingual representations. We release our code, models, and dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PolyFact, a parallel multilingual factual QA dataset with 100K Wikidata-grounded facts across 12 languages. It evaluates light continual pretraining (CPT), supervised fine-tuning (SFT), and Group Relative Policy Optimization (GRPO) on Qwen-2.5-7B and OLMo-2-7B, claiming that GRPO consistently outperforms SFT in cross-lingual factual consistency and generalization to unseen languages while CPT yields limited gains. Mechanistic analyses indicate that GRPO reduces language specialization in MLP layers and attention heads to promote shared representations. The work releases code, models, and the dataset.
Significance. If the reported superiority of GRPO holds after controlling for training compute and data artifacts, the contribution would be significant for addressing cross-lingual factual inconsistency. The new dataset and the release of code/models/data support reproducibility and further work on multilingual routing. The mechanistic findings, if rigorously validated, could inform representation learning in multilingual models.
major comments (2)
- [Experimental setup] Experimental setup section: The comparisons of GRPO against SFT and CPT on Qwen-2.5-7B and OLMo-2-7B do not report matched training compute, FLOPs, gradient steps, wall-clock time, or token budgets. This is load-bearing for the central claim that performance differences are caused by the GRPO objective rather than optimization effort or PolyFact construction artifacts.
- [Mechanistic analyses] Mechanistic analyses section: The methods used to quantify language specialization in MLP layers and attention heads, and to demonstrate reorganization of multilingual routing, are unspecified. This undermines evaluation of the claim that GRPO promotes more shared cross-lingual representations.
minor comments (1)
- [Abstract] Abstract and results sections lack explicit quantitative metrics, error bars, or statistical tests for the reported outperformance, which should be added for clarity even if present in tables.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify important gaps in reporting that affect the strength of our central claims. We address each below and commit to revisions that will improve clarity and rigor without altering the core findings.
read point-by-point responses
-
Referee: [Experimental setup] Experimental setup section: The comparisons of GRPO against SFT and CPT on Qwen-2.5-7B and OLMo-2-7B do not report matched training compute, FLOPs, gradient steps, wall-clock time, or token budgets. This is load-bearing for the central claim that performance differences are caused by the GRPO objective rather than optimization effort or PolyFact construction artifacts.
Authors: We agree that matched training compute is essential for attributing gains to the GRPO objective. The current manuscript reports only epoch counts and does not provide token budgets, gradient steps, or FLOPs. In the revision we will add a dedicated table (or subsection) listing exact token counts processed, number of gradient updates, and estimated FLOPs for each method on both models. Where exact matching was not performed, we will state the compute differential and discuss its potential impact on the results. revision: yes
-
Referee: [Mechanistic analyses] Mechanistic analyses section: The methods used to quantify language specialization in MLP layers and attention heads, and to demonstrate reorganization of multilingual routing, are unspecified. This undermines evaluation of the claim that GRPO promotes more shared cross-lingual representations.
Authors: The manuscript describes the high-level approach (activation patching and routing entropy) but omits the precise metrics and implementation details. We will expand Section 4.2 with the exact formulas used to compute language specialization scores for MLP neurons and attention heads, the procedure for measuring cross-lingual routing reorganization, and any statistical tests applied. This will allow readers to reproduce the mechanistic claims. revision: yes
Circularity Check
No significant circularity in empirical comparisons
full rationale
The paper presents empirical results from training and evaluating GRPO, SFT, and CPT on the PolyFact dataset for cross-lingual factual recall in two base models. All load-bearing claims (outperformance of GRPO, mechanistic changes in routing) are grounded in measured performance metrics and layer analyses against external baselines, not in any paper-internal equations, fitted parameters renamed as predictions, or self-citation chains that reduce the result to its own inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of ACL 2025 , year =
Lost in Multilinguality: Dissecting Cross-lingual Factual Inconsistency in Transformer Language Models , author =. Proceedings of ACL 2025 , year =
2025
-
[2]
Proceedings of ACL 2025 , year =
Just Go Parallel: Improving the Multilingual Capabilities of Large Language Models , author =. Proceedings of ACL 2025 , year =
2025
-
[3]
Proceedings of EMNLP 2025 , year =
From Unaligned to Aligned: Scaling Multilingual LLMs with Multi-Way Parallel Corpora , author =. Proceedings of EMNLP 2025 , year =
2025
-
[4]
2024 , url =
Zhao, Jun and Zhang, Zhihao and Zhang, Qi and Gui, Tao and Huang, Xuanjing , journal=. 2024 , url =
2024
-
[5]
Continual Pre-Training for Cross-Lingual
Kazuki Fujii and Taishi Nakamura and Genta Indra Winata and others , journal =. Continual Pre-Training for Cross-Lingual. 2024 , url =
2024
-
[6]
Teaching
Kuulmets, Hele-Andra and Purason, Taido and Luhtaru, Agnes and Fishel, Mark , booktitle =. Teaching. 2024 , url =
2024
-
[7]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[8]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[9]
Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models
Tang, Tianyi and Luo, Wenyang and Huang, Haoyang and Zhang, Dongdong and Wang, Xiaolei and Zhao, Xin and Wei, Furu and Wen, Ji-Rong. Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1...
-
[10]
Do Multilingual
Lisa Schut and Yarin Gal and Sebastian Farquhar , booktitle=. Do Multilingual. 2025 , url=
2025
-
[11]
2025 , eprint=
Languages Still Left Behind: Toward a Better Multilingual Machine Translation Benchmark , author=. 2025 , eprint=
2025
-
[12]
2022 , eprint=
Language Models are Multilingual Chain-of-Thought Reasoners , author=. 2022 , eprint=
2022
-
[13]
2025 , eprint=
Focusing on Language: Revealing and Exploiting Language Attention Heads in Multilingual Large Language Models , author=. 2025 , eprint=
2025
-
[14]
Proceedings of EMNLP 2024 (System Demonstrations) , year =
Tufanov, Igor and Wendler, Karen and Vesel. Proceedings of EMNLP 2024 (System Demonstrations) , year =
2024
-
[15]
Global MMLU : Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation
Singh, Shivalika and Romanou, Angelika and Fourrier, Cl \'e mentine and Adelani, David Ifeoluwa and Ngui, Jian Gang and Vila-Suero, Daniel and Limkonchotiwat, Peerat and Marchisio, Kelly and Leong, Wei Qi and Susanto, Yosephine and Ng, Raymond and Longpre, Shayne and Ruder, Sebastian and Ko, Wei-Yin and Bosselut, Antoine and Oh, Alice and Martins, Andre a...
-
[16]
Nature645(8081), 633–638 (Sep 2025)
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong , year=. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , volume=. Nature , publisher=. doi:10.1038/s41586-025-09422-z , number=
-
[17]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[18]
2023 , version =
Habib, Nathan and Fourrier, Clémentine and Kydlíček, Hynek and Wolf, Thomas and Tunstall, Lewis , title =. 2023 , version =
2023
-
[19]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[20]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[21]
2022 , eprint=
No Language Left Behind: Scaling Human-Centered Machine Translation , author=. 2022 , eprint=
2022
-
[22]
arXiv preprint arXiv:2503.19786 , year =
Kamath, Aishwarya and Ferret, Johan and Pathak, Shreya and Vieillard, Nino and Merhej, Ramona and Perrin, Sarah and Matejovicova, Tatiana and Ram. arXiv preprint arXiv:2503.19786 , year =
-
[23]
2026 , eprint=
The Role of Mixed-Language Documents for Multilingual Large Language Model Pretraining , author=. 2026 , eprint=
2026
-
[24]
Inside-Out: Hidden Factual Knowledge in
Zorik Gekhman and Eyal Ben-David and Hadas Orgad and Eran Ofek and Yonatan Belinkov and Idan Szpektor and Jonathan Herzig and Roi Reichart , booktitle=. Inside-Out: Hidden Factual Knowledge in. 2025 , url=
2025
-
[25]
The Twelfth International Conference on Learning Representations , year=
The Reasonableness Behind Unreasonable Translation Capability of Large Language Model , author=. The Twelfth International Conference on Learning Representations , year=
-
[26]
How Far can 100 Samples Go? Unlocking Zero-Shot Translation with Tiny Multi-Parallel Data
Wu, Di and Tan, Shaomu and Meng, Yan and Stap, David and Monz, Christof. How Far can 100 Samples Go? Unlocking Zero-Shot Translation with Tiny Multi-Parallel Data. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.896
-
[27]
From Translation to Multilinguality: Revisit the Role of Parallel Data in Multilingual
Haobin Lin and Yan Zhao and Wenhan Han and Ping Guo and BINBINLIU and Yifan Zhang and Bingni Zhang and Taifeng Wang and Yin Zheng , year=. From Translation to Multilinguality: Revisit the Role of Parallel Data in Multilingual
-
[28]
Investigating and Scaling up Code-Switching for Multilingual Language Model Pre-Training
Wang, Zhijun and Li, Jiahuan and Zhou, Hao and Weng, Rongxiang and Wang, Jingang and Huang, Xin and Han, Xue and Feng, Junlan and Deng, Chao and Huang, Shujian. Investigating and Scaling up Code-Switching for Multilingual Language Model Pre-Training. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.575
-
[29]
Paths Not Taken: Understanding and Mending the Multilingual Factual Recall Pipeline
Lu, Meng and Zhang, Ruochen and Eickhoff, Carsten and Pavlick, Ellie. Paths Not Taken: Understanding and Mending the Multilingual Factual Recall Pipeline. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.762
-
[30]
Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers
Wendler, Chris and Veselovsky, Veniamin and Monea, Giovanni and West, Robert. Do Llamas Work in E nglish? On the Latent Language of Multilingual Transformers. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.820
-
[31]
2024 , eprint=
2 OLMo 2 Furious , author=. 2024 , eprint=
2024
-
[32]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =. 2022 , url =
2022
-
[33]
Hugging Face repository , howpublished =
FineTranslations , author=. Hugging Face repository , howpublished =. 2026 , publisher =
2026
-
[34]
2024 , eprint=
Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models , author=. 2024 , eprint=
2024
-
[35]
arXiv preprint arXiv:2510.10280 , year =
On the Entity-Level Alignment in Crosslingual Consistency , author =. arXiv preprint arXiv:2510.10280 , year =
-
[36]
arXiv preprint arXiv:2603.17070 , year =
Large Reasoning Models Struggle to Transfer Parametric Knowledge Across Scripts , author =. arXiv preprint arXiv:2603.17070 , year =
-
[37]
2025 , url =
Matsutani, Kohsei and Takashiro, Shota and Minegishi, Gouki and Kojima, Takeshi and Iwasawa, Yusuke and Matsuo, Yutaka , journal =. 2025 , url =
2025
-
[38]
2026 , url =
Hu, Hanxu and Wang, Yuxuan and Huan, Maggie and Vamvas, Jannis and Huang, Yinya and Guo, Zhijiang and Sennrich, Rico , journal =. 2026 , url =
2026
-
[39]
2025 , url =
Ye, Xiao and Shrivastava, Shaswat and Li, Zhaonan and Dineen, Jacob and Lu, Shijie and Ahuja, Avneet and Shen, Ming and Xu, Zhikun and Zhou, Ben , journal =. 2025 , url =
2025
-
[40]
arXiv preprint arXiv:2601.14896 , year =
Language-Coupled Reinforcement Learning for Multilingual Retrieval-Augmented Generation , author =. arXiv preprint arXiv:2601.14896 , year =
-
[41]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[42]
arXiv preprint arXiv:2505.14297 , year =
Cross-Lingual Optimization for Language Transfer in Large Language Models , author =. arXiv preprint arXiv:2505.14297 , year =
-
[43]
A Glimpse into Babel: An Analysis of Multilinguality in
Kaffee, Lucie-Aim. A Glimpse into Babel: An Analysis of Multilinguality in. Proceedings of the 13th International Symposium on Open Collaboration (OpenSym '17) , year =. doi:10.1145/3125433.3125465 , publisher =
-
[44]
arXiv preprint arXiv:2512.22712 , year =
Beg to Differ: Understanding Reasoning-Answer Misalignment Across Languages , author =. arXiv preprint arXiv:2512.22712 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.