JA-SIREN: Deterministic Initialization for Sinusoidal Networks via Spectral Matching
Pith reviewed 2026-06-28 01:54 UTC · model grok-4.3
The pith
Sinusoidal networks receive closed-form initial weights that exactly match the target's frequency content via its Discrete Sine Transform.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
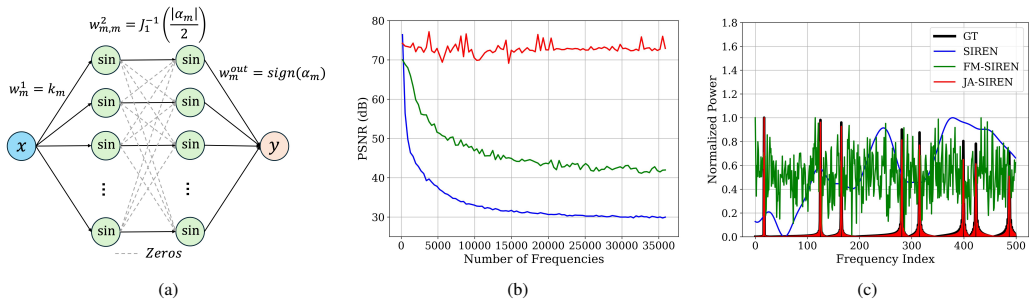
By computing the Discrete Sine Transform of the target signal and leveraging the Jacobi-Anger expansion, closed-form weights are derived for a two-layer sinusoidal MLP that analytically match the network's initial spectral response to the target signal, requiring no random seed or additional hyperparameter tuning.
What carries the argument
The Discrete Sine Transform of the target combined with the Jacobi-Anger expansion to convert frequency coefficients into exact sinusoidal-network weights for initial spectral matching.
If this is right
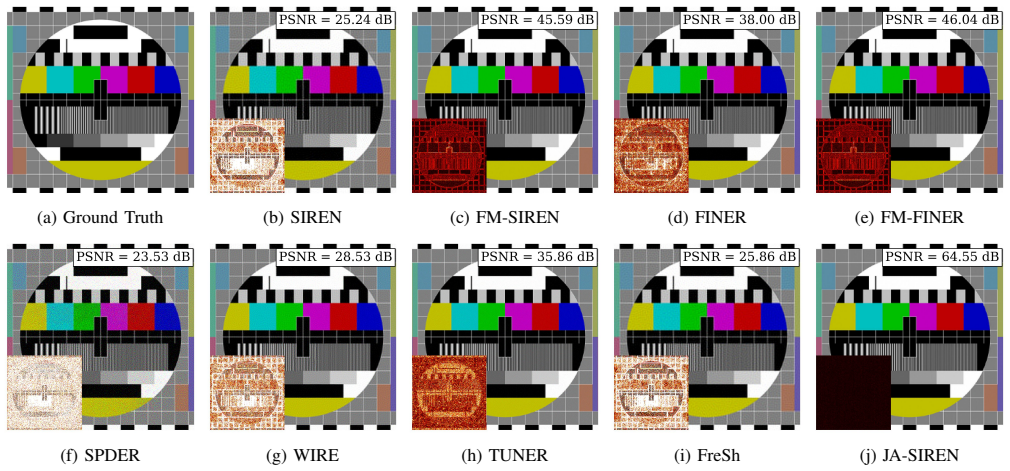
- Mean PSNR on the Kodak dataset reaches 67.18 dB, exceeding the best baseline by 21.30 dB.
- Run-to-run variance drops to zero because the initialization contains no randomness.
- No random seed or extra hyperparameter search is needed once the DST is computed.
- The same closed-form procedure applies to any signal for which a Discrete Sine Transform can be taken.
Where Pith is reading between the lines
- The spectral-matching step could be repeated after each added layer to keep frequency alignment as depth increases.
- If the method works for images, it may also stabilize fitting of simulation outputs where exact reproducibility matters more than peak accuracy.
- Signals whose DST is sparse might converge even faster because fewer weights need to be set.
Load-bearing premise
That setting only the initial two-layer spectral response to match the target's DST will produce reliable high-quality convergence on arbitrary signals and when the network is deepened.
What would settle it
An experiment in which a JA-SIREN network initialized by this spectral match converges to lower final accuracy than a standard random-initialized SIREN on the same signal, or displays measurable PSNR variation across independent runs.
Figures

read the original abstract
Existing implicit neural representation (INR) approaches suffer from stochastic initialization that does not guarantee consistent or high-quality performance across runs, with variations reaching more than 2.5 dB (78%) in image regression. This variation is problematic for scientific computing and simulation, where result reproducibility is crucial. To address this problem, we present Jacobi-Anger Sinusoidal Representation Network (JA-SIREN), a deterministic initialization scheme for sinusoidal networks grounded in classical spectral analysis. By computing the Discrete Sine Transform (DST) of the target signal and leveraging the Jacobi-Anger expansion, we derive closed-form weights for a two-layer sinusoidal MLP that analytically match the network's initial spectral response to the target signal, requiring no random seed or additional hyperparameter tuning. On the Kodak dataset, JA-SIREN achieves a mean PSNR of 67.18 dB, a 21.30 dB improvement over the best baseline. This is achieved with zero run-to-run variance, confirming that spectrally-informed initialization is a more effective and reproducible alternative to stochastic initialization for sinusoidal INRs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing INR methods suffer from stochastic initialization causing >2.5 dB run-to-run variation; JA-SIREN addresses this by using the DST of the target plus the Jacobi-Anger expansion to derive closed-form weights for a two-layer sinusoidal MLP whose initial spectrum analytically matches the target, yielding deterministic, high-quality fits. On Kodak this produces 67.18 dB mean PSNR (21.3 dB above the best baseline) with zero variance.
Significance. A correct, generalizable deterministic spectral initialization for sinusoidal networks would be significant for reproducibility in scientific INR applications. The grounding in classical identities (DST + Jacobi-Anger) rather than fitted hyperparameters is a methodological strength if the construction extends beyond the two-layer case.
major comments (2)
- [Abstract, derivation section] Abstract and the derivation section: closed-form weights are derived only for a two-layer sinusoidal MLP via DST coefficients and Jacobi-Anger; the Kodak results (67 dB PSNR) are characteristic of deeper (typically 4–8 layer) SIRENs, yet no section, equation, or appendix shows how the first-layer spectral match controls the composite spectrum after additional sin activations.
- [Experiments] Experiments: the abstract asserts that spectral matching is the causal factor for the 21 dB gain and zero variance, but no ablation, error analysis, or controlled comparison isolating the DST/Jacobi-Anger initialization from network depth or width is reported.
minor comments (2)
- State explicitly the layer count, hidden width, and activation scaling used for the Kodak runs so readers can verify whether the reported architecture is two-layer or deeper.
- Add a short paragraph contrasting the two-layer analytic construction with any practical multi-layer implementation that may have been used.
Simulated Author's Rebuttal
We thank the referee for the careful reading and insightful comments. We address each major comment below, clarifying the scope of the work and indicating where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, derivation section] Abstract and the derivation section: closed-form weights are derived only for a two-layer sinusoidal MLP via DST coefficients and Jacobi-Anger; the Kodak results (67 dB PSNR) are characteristic of deeper (typically 4–8 layer) SIRENs, yet no section, equation, or appendix shows how the first-layer spectral match controls the composite spectrum after additional sin activations.
Authors: The JA-SIREN construction and all reported results are explicitly limited to the two-layer sinusoidal MLP, as stated throughout the abstract and derivation. The 67.18 dB PSNR demonstrates that spectral matching via DST and Jacobi-Anger enables a shallow network to reach performance levels typically associated with deeper architectures. Because the network contains only two layers, there are no additional sin activations whose composite spectrum would need to be analyzed. We will insert a brief clarifying paragraph in the introduction and conclusion to emphasize the two-layer scope and the resulting implications for reproducibility. revision: partial
-
Referee: [Experiments] Experiments: the abstract asserts that spectral matching is the causal factor for the 21 dB gain and zero variance, but no ablation, error analysis, or controlled comparison isolating the DST/Jacobi-Anger initialization from network depth or width is reported.
Authors: All baselines and JA-SIREN use identical two-layer architectures, so the 21.3 dB gain and zero variance are isolated to the choice of deterministic spectral initialization rather than depth. Width is likewise fixed across comparisons. While these controlled settings already attribute the improvement to the DST/Jacobi-Anger weights, we agree that an explicit width ablation would further strengthen the causal claim. We will add this ablation study to the experiments section in the revision. revision: partial
Circularity Check
No circularity; derivation applies classical DST and Jacobi-Anger identities to set two-layer weights
full rationale
The claimed result is a closed-form weight derivation for a two-layer sinusoidal MLP that matches the target's DST spectrum via the Jacobi-Anger expansion. This is a direct mathematical construction from external classical tools (DST, Jacobi-Anger), not a fit to final performance, not a self-definition, and not dependent on self-citations. The paper does not rename a known result or smuggle an ansatz; the initialization scheme is the explicit output of the derivation rather than a tautology. Standard use of deeper networks is an assumption about generalization, not a circularity in the two-layer derivation itself.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Jacobi-Anger expansion provides a usable closed-form relation between sinusoidal activations and the target spectrum via Bessel functions.
Reference graph
Works this paper leans on
-
[1]
Usc-sipi image database,
USC Signal and Image Processing Institute, “Usc-sipi image database,” https://sipi.usc.edu/database/, 1973
1973
-
[2]
Where do we stand with implicit neural representations? a technical and performance survey,
E. et al., “Where do we stand with implicit neural representations? a technical and performance survey,”arXiv preprint arXiv:2411.03688, 2024
-
[3]
Multilayer perceptron and neural networks,
M.-C. Popescu, V . E. Balas, L. Perescu-Popescu, and N. Mastorakis, “Multilayer perceptron and neural networks,”WSEAS Transactions on Circuits and Systems, vol. 8, no. 7, pp. 579–588, 2009
2009
-
[4]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, 2021
2021
-
[5]
Acorn: Adaptive coordinate networks for neural scene representation,
J. N. Martel, D. B. Lindell, C. Z. Lin, E. R. Chan, M. Monteiro, and G. Wetzstein, “Acorn: Adaptive coordinate networks for neural scene representation,”arXiv preprint arXiv:2105.02788, 2021
-
[6]
Signal processing for implicit neural representations,
D. Xu, P. Wang, Y . Jiang, Z. Fan, and Z. Wang, “Signal processing for implicit neural representations,”Advances in Neural Information Processing Systems, vol. 35, pp. 13 404–13 418, 2022
2022
-
[7]
Normal-guided detail-preserving neural implicit function for high-fidelity 3d surface reconstruction,
A. Patel, H. Laga, and O. Sharma, “Normal-guided detail-preserving neural implicit function for high-fidelity 3d surface reconstruction,”Pro- ceedings of the ACM on computer graphics and interactive techniques, vol. 8, no. 1, pp. 1–24, 2025
2025
-
[8]
Scene representation networks: Continuous 3d- structure-aware neural scene representations,
V . Sitzmannet al., “Scene representation networks: Continuous 3d- structure-aware neural scene representations,” inAdvances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[9]
Implicit neural representation in medical imaging: A comparative survey,
A. Molaei, A. Aminimehr, A. Tavakoli, A. Kazerouni, B. Azad, R. Azad, and D. Merhof, “Implicit neural representation in medical imaging: A comparative survey,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 2381–2391
2023
-
[10]
Implicit neural representations for image compression,
Y . Str ¨umpler, J. Postels, R. Yang, L. V . Gool, and F. Tombari, “Implicit neural representations for image compression,” inEuropean conference on computer vision. Springer, 2022, pp. 74–91
2022
-
[11]
Implicit neural representations with periodic activation functions,
V . Sitzmann, J. N. Martel, A. W. Bergman, D. B. Lindell, and G. Wetzstein, “Implicit neural representations with periodic activation functions,” inProc. NeurIPS, 2020
2020
-
[12]
Finer: Flexible spectral-bias tuning in implicit neural representation by variable-periodic activation functions,
Z. Liu, H. Zhu, Q. Zhang, J. Fu, W. Deng, Z. Ma, Y . Guo, and X. Cao, “Finer: Flexible spectral-bias tuning in implicit neural representation by variable-periodic activation functions,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[13]
Wire: Wavelet implicit neural representations,
V . Saragadam, D. LeJeune, J. Tan, G. Balakrishnan, A. Veeraraghavan, and R. G. Baraniuk, “Wire: Wavelet implicit neural representations,” in Conf. Computer Vision and Pattern Recognition, 2023
2023
-
[14]
Mire: Matched implicit neural representations,
D. Jayasundara, H. Zhao, D. Labate, and V . M. Patel, “Mire: Matched implicit neural representations,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 8279–8288
2025
-
[15]
Spder: Semiperiodic damping-enabled object representation,
K. Shah and C. Sitawarin, “Spder: Semiperiodic damping-enabled object representation,” inInternational Conference on Learning Representa- tions, 2024
2024
-
[16]
Tuning the frequencies: Robust training for sinusoidal neural networks,
T. Novello, D. Aldana, A. Araujo, and L. Velho, “Tuning the frequencies: Robust training for sinusoidal neural networks,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025
2025
-
[17]
Fourier features let networks learn high frequency functions in low dimensional domains,
M. Tancik, P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ramamoorthi, J. Barron, and R. Ng, “Fourier features let networks learn high frequency functions in low dimensional domains,” Advances in neural information processing systems, vol. 33, 2020
2020
-
[18]
Viˆ 3nr: Variance informed initialization for implicit neural representa- tions,
C. H. Koneputugodage, Y . Ben-Shabat, S. Ramasinghe, and S. Gould, “Viˆ 3nr: Variance informed initialization for implicit neural representa- tions,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 13 477–13 486
2025
-
[19]
Jacobi-anger expansion,
E. W. Weisstein, “Jacobi-anger expansion,” https://mathworld.wolfram. com/Jacobi-AngerExpansion.html, from MathWorld–A Wolfram Re- source
-
[20]
Beyond periodicity: Towards a unifying framework for activations in coordinate-mlps,
S. Ramasinghe and S. Lucey, “Beyond periodicity: Towards a unifying framework for activations in coordinate-mlps,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 142–158
2022
-
[21]
Improved implicit neural representation with fourier reparameterized training,
K. Shi, X. Zhou, and S. Gu, “Improved implicit neural representation with fourier reparameterized training,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 25 985–25 994
2024
-
[22]
FM-SIREN & FM-FINER: Implicit Neural Representation Using Nyquist-based Orthogonality
M. Alsakabi, W. Mobeirek, J. M. Dolan, and O. K. Tonguz, “Fm-siren & fm-finer: Nyquist-informed frequency multiplier for implicit neural rep- resentation with periodic activation,”arXiv preprint arXiv:2509.23438, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Understanding the difficulty of training deep feedforward neural networks,
X. Glorot and Y . Bengio, “Understanding the difficulty of training deep feedforward neural networks,” inProceedings of the thirteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2010, pp. 249–256
2010
-
[24]
Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,
K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1026–1034
2015
-
[25]
Sal: Sign agnostic learning of shapes from raw data,
M. Atzmon and Y . Lipman, “Sal: Sign agnostic learning of shapes from raw data,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2565–2574
2020
-
[26]
Digs: Divergence guided shape implicit neural representation for unoriented point clouds,
Y . Ben-Shabat, C. H. Koneputugodage, and S. Gould, “Digs: Divergence guided shape implicit neural representation for unoriented point clouds,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 19 323–19 332
2022
-
[27]
Fresh: Frequency shifting for accelerated neural representation learning,
A. Kania, M. Mihajlovic, S. Prokudin, J. Tabor, P. Spureket al., “Fresh: Frequency shifting for accelerated neural representation learning,”arXiv preprint arXiv:2410.05050, 2024
-
[28]
Discrete cosine transform,
N. Ahmed, T. Natarajan, and K. R. Rao, “Discrete cosine transform,” IEEE transactions on Computers, vol. 100, no. 1, pp. 90–93, 2006
2006
-
[29]
Theory of generalized bessel functions,
G. Dattoli, L. Giannessi, L. Mezi, and A. Torre, “Theory of generalized bessel functions,”Il Nuovo Cimento B (1971-1996), vol. 105, no. 3, pp. 327–348, 1990
1971
-
[30]
Philips circle pattern,
Wikipedia contributors, “Philips circle pattern,” 2025
2025
-
[31]
Kodak Lossless True Color Image Suite,
S. Mehta, “Kodak Lossless True Color Image Suite,” 2020. [Online]. Available: https://www.kaggle.com/datasets/sherylmehta/kodak-dataset
2020
-
[32]
Mining the spoken wikipedia for speech data and beyond,
A. K ¨ohn, F. Stegen, and T. Baumann, “Mining the spoken wikipedia for speech data and beyond,” inProceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), N. C. C. Chair), K. Choukri, T. Declerck, M. Grobelnik, B. Maegaard, J. Mariani, A. Moreno, J. Odijk, and S. Piperidis, Eds. Paris, France: European Language R...
2016
-
[33]
Pytorch: An imperative style, high-performance deep learning library,
P. et al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[34]
Optimization methods for large- scale machine learning,
L. Bottou, F. E. Curtis, and J. Nocedal, “Optimization methods for large- scale machine learning,”SIAM review, vol. 60, no. 2, 2018
2018
-
[35]
Image quality metrics: Psnr vs. ssim,
A. Hore and D. Ziou, “Image quality metrics: Psnr vs. ssim,” in2010 20th international conference on pattern recognition. IEEE, 2010
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.