RECAP: Regression Evaluation for Continual Adaptation of Prompts
Pith reviewed 2026-06-28 02:22 UTC · model grok-4.3
The pith
Prompt optimization methods show no significant improvement under proactive adaptation to evolving constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
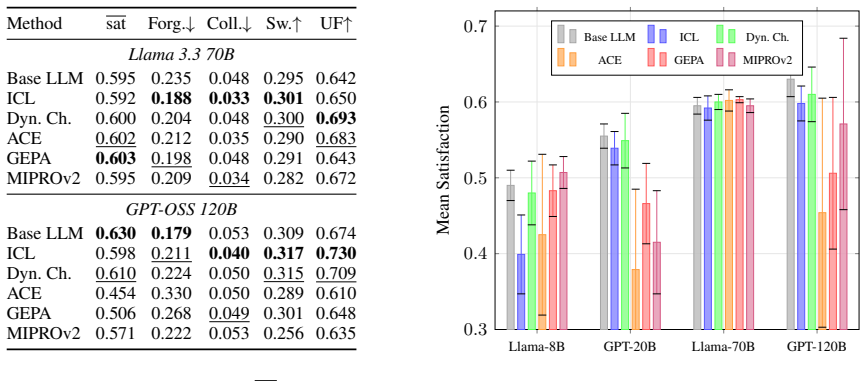
The RECAP benchmark measures continual-learning effects at the constraint level under a strictly proactive adapt-then-test protocol where prompt optimization receives only the constraint specification and must generalize before seeing test data; evaluations of six methods across four LLMs and three evolving schedules show these methods produce no significant performance improvement despite higher latency, indicating they remain inadequate for the proactive paradigm.
What carries the argument
The RECAP benchmark, which applies a proactive adapt-then-test protocol to track forgetting, regression, and forward transfer at the individual constraint level.
If this is right
- Methods built for offline or reactive settings cannot reliably meet proactive adaptation demands.
- Performance remains flat even when methods incur extra latency for constraint handling.
- Production systems need new prompt adaptation techniques that stay robust as constraints change from one interaction to the next.
- Evaluation must shift to protocols that withhold test data until after the adaptation step.
Where Pith is reading between the lines
- The benchmark could be applied to measure adaptation speed when constraints arrive in batches rather than singly.
- Similar proactive testing might reveal comparable gaps in non-prompt continual learning settings such as fine-tuning or retrieval updates.
- Designers of agentic pipelines may need to budget for fallback mechanisms until proactive methods improve.
Load-bearing premise
The constraint specifications and update schedules chosen for the benchmark match the evolving requirements that appear in actual production agentic systems.
What would settle it
A prompt method that records a statistically significant accuracy increase on the RECAP benchmark when adapting to new constraints without any exposure to the corresponding test examples.
Figures



read the original abstract
Production agentic systems routinely face evolving constraints and must comply from the very next interaction. Scenarios like a tool-call notification changing a compliance threshold or a policy update adding disclosure requirements fit this criteria, having close to no room for errors in production. This proactive adaptation setting is common in deployment, but absent from current benchmarks, which assume either static constraint sets or reactive protocols with evaluation feedback. We introduce RECAP, a benchmark that measures continual-learning phenomena (forgetting, regression, forward transfer) at the constraint level under a strictly proactive adapt-then-test protocol: prompt optimization methods receive only the constraint specification and must generalize before seeing any test data. Evaluating six methods across four LLMs and three schedules with evolving constraints, we find that these methods show no significant improvement in performance, even after incurring a higher latency. These methods, designed for offline or reactive settings, are inadequate for the proactive paradigm. Our work emphasizes the growing need for designing proactive prompt adaptation methods, where the models must remain robust to evolving needs in deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RECAP, a benchmark for evaluating prompt optimization methods under a strictly proactive adapt-then-test protocol with evolving constraints (no test data feedback allowed). It evaluates six methods across four LLMs and three synthetic schedules, reporting no significant performance gains despite increased latency, and concludes that existing offline/reactive methods are inadequate for proactive production settings in agentic systems.
Significance. If the benchmark design is representative, the work is significant for identifying a gap in prompt adaptation techniques and motivating proactive methods that handle constraint-level forgetting, regression, and forward transfer. The strictly proactive protocol and constraint-level metrics are clear strengths that distinguish it from static or reactive benchmarks.
major comments (2)
- [Benchmark Construction and Schedules] The central claim that current methods are inadequate for the proactive paradigm rests on the three evolution schedules accurately representing real production constraint changes, but the manuscript provides no external validation (e.g., against production logs of policy updates or tool notifications) for schedule parameters such as frequency, interdependence, or type distribution.
- [Experimental Results and Analysis] The repeated assertion of 'no significant improvement' across methods, LLMs, and schedules lacks reported statistical tests, confidence intervals, or effect sizes to support the null result; without these, the empirical evidence for the inadequacy conclusion remains under-specified.
minor comments (2)
- [Methods] Notation for constraint specifications and schedules could be clarified with a single summary table to aid reproducibility.
- [Abstract and Introduction] The abstract states results for 'six methods' but the full experimental section should explicitly list them with citations in the first paragraph for immediate context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on benchmark construction and statistical reporting. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Benchmark Construction and Schedules] The central claim that current methods are inadequate for the proactive paradigm rests on the three evolution schedules accurately representing real production constraint changes, but the manuscript provides no external validation (e.g., against production logs of policy updates or tool notifications) for schedule parameters such as frequency, interdependence, or type distribution.
Authors: We agree that external validation against real production logs would strengthen claims of representativeness. The schedules are synthetic and were constructed to reflect the proactive scenarios described in the introduction (e.g., tool-call notifications changing compliance thresholds and policy updates adding disclosure requirements). We do not have access to proprietary production logs for parameter validation. We will revise the manuscript to (1) explicitly label the schedules as illustrative/synthetic, (2) add a limitations paragraph discussing the absence of external validation, and (3) clarify that the central claim concerns performance under these controlled evolving-constraint conditions rather than claiming universal representativeness of all production environments. revision: partial
-
Referee: [Experimental Results and Analysis] The repeated assertion of 'no significant improvement' across methods, LLMs, and schedules lacks reported statistical tests, confidence intervals, or effect sizes to support the null result; without these, the empirical evidence for the inadequacy conclusion remains under-specified.
Authors: We thank the referee for this observation. The current manuscript reports raw performance numbers and states 'no significant improvement' without formal statistical support. We will revise the experimental results section to include appropriate statistical tests (e.g., paired t-tests or non-parametric equivalents across methods), 95% confidence intervals, and effect sizes (e.g., Cohen's d) for all key comparisons. These additions will be presented in updated tables and text to better substantiate the null-result claims. revision: yes
Circularity Check
No circularity: empirical benchmark with independent experimental outcomes
full rationale
The paper introduces RECAP as a new benchmark and reports performance of six methods across LLMs and schedules under a proactive protocol. No equations, fitted parameters, or derivations are present; the central claim (methods show no significant improvement) rests directly on measured metrics rather than reducing to self-defined quantities, self-citations, or renamed known results. The benchmark design and conclusion are self-contained against external validation needs, with no load-bearing self-citation chains or ansatz smuggling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
RECAST: Expanding the Boundaries of LLMs' Complex Instruction Following with Multi-Constraint Data , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[2]
The Fourteenth International Conference on Learning Representations , year=
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models , author=. The Fourteenth International Conference on Learning Representations , year=
-
[3]
Second Conference on Language Modeling , year=
Tulu 3: Pushing Frontiers in Open Language Model Post-Training , author=. Second Conference on Language Modeling , year=
-
[4]
arXiv preprint arXiv:2311.07911 , year=
Instruction-Following Evaluation for Large Language Models , author=. arXiv preprint arXiv:2311.07911 , year=
-
[5]
Proceedings of the European conference on computer vision (ECCV) , pages=
Riemannian walk for incremental learning: Understanding forgetting and intransigence , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[6]
Advances in neural information processing systems , volume=
Gradient episodic memory for continual learning , author=. Advances in neural information processing systems , volume=
-
[7]
Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory
Suzgun, Mirac and Yuksekgonul, Mert and Bianchi, Federico and Jurafsky, Dan and Zou, James. Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory. Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers). 2026. doi:10.18653/v1/2026.eacl-long.333
-
[8]
The Twelfth International Conference on Learning Representations , year=
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines , author=. The Twelfth International Conference on Learning Representations , year=
-
[9]
arXiv preprint arXiv:2310.06762 , year=
Trace: A comprehensive benchmark for continual learning in large language models , author=. arXiv preprint arXiv:2310.06762 , year=
-
[10]
2021 IEEE Symposium on Security and Privacy (SP) , year=
Machine Unlearning , author=. 2021 IEEE Symposium on Security and Privacy (SP) , year=
2021
-
[11]
2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P) , year=
Unrolling SGD: Understanding Factors Influencing Machine Unlearning , author=. 2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P) , year=
2022
-
[12]
Wang, Yifan and Liu, Yafei and Shi, Chufan and Li, Haoling and Chen, Chen and Lu, Haonan and Yang, Yujiu. I ns CL : A Data-efficient Continual Learning Paradigm for Fine-tuning Large Language Models with Instructions. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technolog...
-
[13]
arXiv preprint arXiv:2406.01775 , year=
Olora: Orthonormal low-rank adaptation of large language models , author=. arXiv preprint arXiv:2406.01775 , year=
-
[14]
2026 , url=
Lakshya A Agrawal and Shangyin Tan and Dilara Soylu and Noah Ziems and Rishi Khare and Krista Opsahl-Ong and Arnav Singhvi and Herumb Shandilya and Michael J Ryan and Meng Jiang and Christopher Potts and Koushik Sen and Alex Dimakis and Ion Stoica and Dan Klein and Matei Zaharia and Omar Khattab , booktitle=. 2026 , url=
2026
-
[15]
Proceedings of the National Academy of Sciences , year=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the National Academy of Sciences , year=
-
[16]
International Conference on Learning Representations , year=
Progressive Prompts: Continual Learning for Language Models , author=. International Conference on Learning Representations , year=
-
[17]
ACM Computing Surveys , year=
Continual Learning of Large Language Models: A Comprehensive Survey , author=. ACM Computing Surveys , year=
-
[18]
Advances in Neural Information Processing Systems , volume=
Achieving forgetting prevention and knowledge transfer in continual learning , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
arXiv preprint arXiv:2402.01364 , url=
Continual learning for large language models: A survey , author=. arXiv preprint arXiv:2402.01364 , url=
-
[20]
Jiang, Yuxin and Wang, Yufei and Zeng, Xingshan and Zhong, Wanjun and Li, Liangyou and Mi, Fei and Shang, Lifeng and Jiang, Xin and Liu, Qun and Wang, Wei. F ollow B ench: A Multi-level Fine-grained Constraints Following Benchmark for Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: ...
-
[21]
Dawid, A. P. , title =. Journal of the Royal Statistical Society: Series A (General) , volume =. doi:https://doi.org/10.2307/2981683 , url =. https://rss.onlinelibrary.wiley.com/doi/pdf/10.2307/2981683 , abstract =
-
[22]
Efficient Lifelong Learning with A-
Arslan Chaudhry and Marc’Aurelio Ranzato and Marcus Rohrbach and Mohamed Elhoseiny , booktitle=. Efficient Lifelong Learning with A-. 2019 , url=
2019
-
[23]
arXiv preprint arXiv:1902.10486 , year=
On tiny episodic memories in continual learning , author=. arXiv preprint arXiv:1902.10486 , year=
Pith/arXiv arXiv 1902
-
[24]
IEEE transactions on pattern analysis and machine intelligence , volume=
A continual learning survey: Defying forgetting in classification tasks , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2021 , publisher=
2021
-
[25]
The Eleventh International Conference on Learning Representations , year=
Continual evaluation for lifelong learning: Identifying the stability gap , author=. The Eleventh International Conference on Learning Representations , year=
-
[26]
Re-evaluating Continual Learning Scenarios:
Yen. Re-evaluating Continual Learning Scenarios:. CoRR , volume =. 2018 , url =. 1810.12488 , timestamp =
Pith/arXiv arXiv 2018
-
[27]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Learning to prompt for continual learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[28]
European conference on computer vision , pages=
Dualprompt: Complementary prompting for rehearsal-free continual learning , author=. European conference on computer vision , pages=. 2022 , organization=
2022
-
[29]
Conference on Neural Information Processing Systems (NeurIPS) , year=
S-Prompts Learning with Pre-trained Transformers: An Occam's Razor for Domain Incremental Learning , author=. Conference on Neural Information Processing Systems (NeurIPS) , year=
-
[30]
I n F o B ench: Evaluating Instruction Following Ability in Large Language Models
Qin, Yiwei and Song, Kaiqiang and Hu, Yebowen and Yao, Wenlin and Cho, Sangwoo and Wang, Xiaoyang and Wu, Xuansheng and Liu, Fei and Liu, Pengfei and Yu, Dong. I n F o B ench: Evaluating Instruction Following Ability in Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.772
-
[31]
Nature , year=
Optimizing generative AI by backpropagating language model feedback , author=. Nature , year=
-
[32]
International Conference on Learning Representations , volume=
Large language models as optimizers , author=. International Conference on Learning Representations , volume=
-
[33]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[34]
Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs
Opsahl-Ong, Krista and Ryan, Michael J and Purtell, Josh and Broman, David and Potts, Christopher and Zaharia, Matei and Khattab, Omar. Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.525
-
[35]
CCTU: A Benchmark for Tool Use under Complex Constraints , author =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2603.15309 , eprinttype =
-
[36]
2025 , url=
Debangshu Banerjee and Tarun Suresh and Shubham Ugare and Sasa Misailovic and Gagandeep Singh , booktitle=. 2025 , url=
2025
-
[37]
arXiv preprint arXiv:2508.10925 , year=
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
-
[38]
Claude Sonnet 4.5 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.