Tensor Algebraic Property Skeletons: Amplifying Property-Based Testing for AI Compilers
Pith reviewed 2026-06-27 23:58 UTC · model grok-4.3
The pith
Tensor algebraic property skeletons enable reliable property-based testing for deep learning compilers by providing reusable oracles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
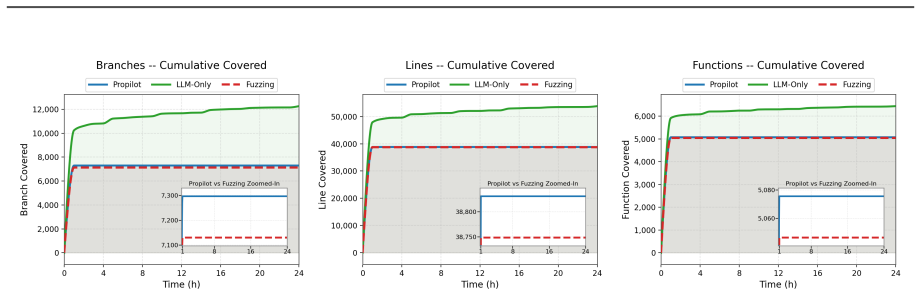
Propilot instantiates 20 property skeletons into 4,579 executable PBTs for 212 TVM operators, reducing redundancy by 49% compared to direct LLM generation and eliminating invalid tests, which allows detection of semantic errors and numerical discrepancies.
What carries the argument
Property skeletons, which are reusable representations of tensor algebra knowledge each coupled with operator constraints and oracle templates.
If this is right
- 4,579 PBTs can be generated for 212 operators using 20 skeletons.
- Redundancy in generated tests is reduced by 49%.
- Invalid tests are eliminated through validation.
- Semantic errors and numerical discrepancies in the compiler can be identified.
Where Pith is reading between the lines
- If the skeletons capture all relevant invariants, the approach could be extended to additional compilers.
- The validation loop might allow iterative improvement of test quality beyond the initial setup.
- Similar skeleton-based methods could apply to other optimization domains with algebraic properties.
Load-bearing premise
The property skeletons accurately capture the algebraic invariants preserved by graph transformations, and the generated oracles correctly identify compiler bugs without being undermined by generation errors.
What would settle it
Observing that a known semantic error in an operator transformation on TVM is not caught by any PBT generated from the 20 skeletons, or that a correct transformation triggers a false positive oracle failure.
Figures

read the original abstract
Deep learning (DL) compilers such as TVM and ONNX-MLIR lower tensor computation graphs into optimized executables for target backends. Testing these compilers has made substantial progress in generating well-formed inputs in the context of fuzzing. However, such generation alone does not catch semantic drifts from algebraic invariants that graph transformations and optimizations are expected to preserve. While tensor algebra has been studied for decades, it has not been transformed into executable property-based tests (PBTs) for DL compilers because doing so requires the time-consuming and error-prone task of jointly constructing operators, tensors, and oracles. The central challenge is no longer generating well-formed inputs for fuzzing DL compilers, but bootstrapping executable PBTs with such inputs and correct oracles based on tensor algebra. We realize this vision in Propilot, an LLM-driven agentic property-based testing framework for DL compilers. First, Propilot represents tensor algebra knowledge as reusable property skeletons, each coupled with operator constraints and oracle templates. Second, given a target compiler, Propilot instantiates these skeletons into executable PBTs by generating paired tensor computation graphs, tensor inputs, and expected semantic relations as oracles. Third, to prevent generated tests from degenerating into invalid or uninformative PBTs, Propilot validates each PBT candidate before execution for applicability and safety. Validation feedback, execution results, and coverage signals guide subsequent generation. We evaluate Propilot on TVM with 212 operators and 20 property skeletons, generating 4,579 PBTs. Compared with direct LLM-based PBT generation, Propilot reduces redundancy by 49% and eliminates invalid tests through explicit property skeletons. This effectiveness translates into finding semantic errors and numerical discrepancies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Propilot, an LLM-driven agentic framework for property-based testing (PBT) of deep learning compilers such as TVM. It encodes tensor algebra knowledge into 20 reusable property skeletons (each with operator constraints and oracle templates), uses LLMs to instantiate them into executable PBTs that pair computation graphs, tensor inputs, and semantic oracles, and applies applicability/safety validation before execution. On 212 TVM operators the system generates 4,579 PBTs, claims a 49% redundancy reduction versus direct LLM-based generation, eliminates invalid tests, and reports discovery of semantic errors and numerical discrepancies.
Significance. If the 20 skeletons correctly encode the algebraic invariants that graph transformations must preserve and the validation step reliably distinguishes compiler bugs from oracle or generation errors, the framework would provide a practical way to bootstrap oracle-based PBTs from decades-old tensor algebra, reducing manual construction effort and improving semantic testing coverage for DL compiler optimizations.
major comments (3)
- [Abstract] Abstract: the claim of a 49% redundancy reduction is presented without any description of the baseline generation procedure, the number of independent runs, error bars, or statistical test; this information is load-bearing for the central quantitative claim.
- [Abstract] Abstract (paragraph on three-step process): the evaluation reports discovery of semantic errors and numerical discrepancies on TVM but supplies no account of how failures were triaged to confirm they indicate real compiler bugs rather than incomplete skeletons, LLM generation artifacts, or validation false negatives.
- [Abstract] Abstract: the assertion that the 20 property skeletons correctly capture the algebraic invariants required for 212 operators rests on an unexamined assumption; no evidence is given that the skeleton set is complete or that omitted invariants would not affect the reported bug-finding results.
minor comments (1)
- [Abstract] The abstract refers to "direct LLM-based PBT generation" as the baseline but does not define its prompt template or sampling parameters, hindering reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, proposing revisions to the manuscript where the concerns identify gaps in the presented evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of a 49% redundancy reduction is presented without any description of the baseline generation procedure, the number of independent runs, error bars, or statistical test; this information is load-bearing for the central quantitative claim.
Authors: We agree the abstract should reference the baseline for clarity. The baseline is direct LLM generation of PBTs without property skeletons or the three-step instantiation/validation process. The 49% reduction is computed from the count of unique executable PBTs produced across the 212 operators. In revision we will add a short clause in the abstract describing the baseline and will ensure the evaluation section reports the number of independent generation runs, any observed variance, and the statistical test applied. revision: yes
-
Referee: [Abstract] Abstract (paragraph on three-step process): the evaluation reports discovery of semantic errors and numerical discrepancies on TVM but supplies no account of how failures were triaged to confirm they indicate real compiler bugs rather than incomplete skeletons, LLM generation artifacts, or validation false negatives.
Authors: The full manuscript describes the triage procedure: each failing PBT is re-executed against a reference CPU implementation, cross-checked with an independent oracle, and manually inspected by the authors to rule out skeleton incompleteness or generation artifacts. We will revise the abstract to include one sentence summarizing this validation workflow so that the bug-finding claims are supported at the abstract level as well. revision: yes
-
Referee: [Abstract] Abstract: the assertion that the 20 property skeletons correctly capture the algebraic invariants required for 212 operators rests on an unexamined assumption; no evidence is given that the skeleton set is complete or that omitted invariants would not affect the reported bug-finding results.
Authors: The 20 skeletons were derived from standard tensor-algebra identities in the literature and were chosen to cover the semantics of every one of the 212 TVM operators under test. The paper shows that PBTs were successfully instantiated for all 212 operators and that the discovered discrepancies match independently reported TVM issues. While a formal completeness proof for all possible tensor invariants is outside the paper's scope, we will add an explicit paragraph in the revised manuscript describing the selection criteria and the empirical coverage achieved. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper describes an empirical engineering framework (Propilot) that encodes known tensor algebra as 20 reusable property skeletons, then uses an LLM agent to instantiate executable PBTs for 212 TVM operators, followed by applicability/safety validation. Reported outcomes (49% redundancy reduction, 4579 generated PBTs, semantic error detection) are direct measurements from system execution rather than outputs of any equation or fitted parameter that references its own inputs. No mathematical derivation chain, self-referential definitions, uniqueness theorems, or load-bearing self-citations appear in the provided text; the work re-uses decades-old tensor algebra and adds explicit validation, rendering the argument self-contained on its own terms.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tensor algebra properties can be captured once in reusable skeletons that remain valid across different tensor shapes and operator instances.
Reference graph
Works this paper leans on
-
[1]
CoverUp: Effective High Coverage Test Generation for Python.Proc. ACM Softw. Eng.2, FSE, Article FSE128 (June 2025), 23 pages. doi:10.1145/3729398 Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Meghan Cowan, Haichen Shen, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos Guestrin, and Arvind Krishnamurthy
-
[2]
arXiv:2002.12543 [cs.SE]https://arxiv.org/abs/2002.12543 Koen Claessen and John Hughes
Metamorphic Testing: A New Approach for Generating Next Test Cases. arXiv:2002.12543 [cs.SE]https://arxiv.org/abs/2002.12543 Koen Claessen and John Hughes
arXiv 2002
-
[3]
QuickCheck: a lightweight tool for random testing of Haskell programs.SIGPLAN Not.35, 9 (Sept. 2000), 268–279. doi:10.1145/357766.351266 Yinlin Deng, Chunqiu Steven Xia, Haoran Peng, Chenyuan Yang, and Lingming Zhang
-
[4]
Large Language Models Are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models. InProceedings of the 32nd ACM SIGSOFT International Symposium on Software T esting and Analysis(Seattle, WA, USA)(ISSTA 2023). Association for Computing Machinery, New York, NY, USA, 423–435. doi:10.1145/3597926.3598067 Yinlin Deng, Chunqiu Steven Xia, ...
-
[5]
Large Language Models are Edge-Case Generators: Crafting Unusual Programs for Fuzzing Deep Learning Libraries. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering(Lisbon, Portugal)(ICSE ’24). Association for Computing Machinery, New York, NY, USA, Article 70, 13 pages. doi:10.1145/3597503.3623343 Yinlin Deng, Chenyuan Yang,...
-
[6]
Fuzzing deep-learning libraries via automated relational API inference. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering(Singapore, Singapore)(ESEC/FSE 2022). Association for Computing Machinery, New York, NY, USA, 44–56. doi: 10.1145/3540250. 3549085 George Fink and Matt Bishop
-
[7]
Property-based testing: a new approach to testing for assurance. SIGSOFT Softw. Eng. Notes22, 4 (July 1997), 74–80. doi:10.1145/263244.263267 Soneya Binta Hossain and Matthew B. Dwyer
-
[8]
TOGLL: Correct and Strong Test Oracle Generation with LLMs. InProceedings of the IEEE/ACM 47th International Conference on Software Engineering(Ottawa, Ontario, Canada)(ICSE ’25). IEEE Press, 1475–1487. doi:10.1109/ICSE55347.2025.00098 Kush Jain and Claire Le Goues
-
[9]
TestForge: Feedback-Driven, Agentic Test Suite Generation. arXiv:2503.14713 [cs.SE]https://arxiv.org/abs/2503.14713 Zhihao Jia, Oded Padon, James Thomas, Todd Warszawski, Matei Zaharia, and Alex Aiken
-
[10]
TASO: optimizing deep learning computation with automatic generation of graph substitutions. InProceedings of the 27th ACM Symposium on Operating Systems Principles(Huntsville, Ontario, Canada)(SOSP ’19). Association for Computing Machinery, New York, NY, USA, 47–62. doi:10.1145/3341301.3359630 Tian Jin, Gheorghe-Teodor Bercea, Tung D Le, Tong Chen, Gong ...
-
[11]
Fredrik Kjolstad, Shoaib Kamil, Stephen Chou, David Lugato, and Saman Amarasinghe
Compiling onnx neural network models using mlir.arXiv preprint arXiv:2008.08272(2020). Fredrik Kjolstad, Shoaib Kamil, Stephen Chou, David Lugato, and Saman Amarasinghe
arXiv 2008
-
[12]
The tensor algebra compiler.Proc. ACM Program. Lang.1, OOPSLA, Article 77 (Oct. 2017), 29 pages. doi:10.1145/3133901 Michael Konstantinou, Renzo Degiovanni, and Mike Papadakis
-
[13]
Do LLMs generate test oracles that capture the actual or the expected program behaviour? arXiv:2410.21136 [cs.SE] https://arxiv.org/ abs/2410.21136 Ben Limpanukorn, Jiyuan Wang, Hong Jin Kang, Zitong Zhou, and Miryung Kim
-
[14]
1109/ICSE55347.2025.00037 Jiawei Liu, Jinkun Lin, Fabian Ruffy, Cheng Tan, Jinyang Li, Aurojit Panda, and Lingming Zhang. 2023a. NNSmith: Generating Diverse and Valid Test Cases for Deep Learning Compilers. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(Vancouver, B...
-
[15]
Coverage-guided tensor compiler fuzzing with joint IR-pass mutation.Proc. ACM Program. Lang.6, OOPSLA1, Article 73 (April 2022), 26 pages. doi:10.1145/3527317 Haoyang Ma, Qingchao Shen, Yongqiang Tian, Junjie Chen, and Shing-Chi Cheung
-
[16]
Fuzzing Deep Learning Compilers with HirGen. InProceedings of the 32nd ACM SIGSOFT International Symposium on Software T esting and Analysis(Seattle, WA, USA)(ISSTA 2023). Association for Computing Machinery, New York, NY, USA, 248–260. doi:10.1145/3597926.3598053 Muhammad Maaz, Liam DeVoe, Zac Hatfield-Dodds, and Nicholas Carlini
-
[17]
Agentic Property-Based Testing: Finding Bugs Across the Python Ecosystem. arXiv:2510.09907 [cs.SE] https://arxiv.org/ abs/2510.09907 Yanzhou Mu, Juan Zhai, Chunrong Fang, Xiang Chen, Zhixiang Cao, Peiran Yang, Kexin Zhao, An Guo, and Zhenyu Chen
-
[18]
Improving Deep Learning Framework Testing with Model-Level Metamorphic Testing.Proc. ACM Softw. Eng.2, ISSTA, Article ISSTA095 (June 2025), 23 pages. doi: 10.1145/3728972 Rohan Padhye, Caroline Lemieux, and Koushik Sen. 2019a. JQF: Coverage-Guided Property-Based Testing in Java. InProceedings of the 28th ACM SIGSOFT International Symposium on Software T e...
-
[19]
Find- ing Compiler-Platform Interaction Bugs in Deep Learning Pipelines via Cross-Layer Constraints. arXiv:2606.18421 [cs.SE]https://arxiv.org/abs/2606.18421 Qingchao Shen, Haoyang Ma, Junjie Chen, Yongqiang Tian, Shing-Chi Cheung, and Xiang Chen
-
[20]
A comprehensive study of deep learning compiler bugs. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (Athens, Greece)(ESEC/FSE 2021). Association for Computing Machinery, New York, NY, USA, 968–980. doi:10.1145/3468264.3468591 Qingchao Shen, Zan Wang, Haoyang...
-
[21]
Optimization-Aware Test Generation for Deep Learning Compilers. arXiv:2511.18918 [cs.SE]https://arxiv.org/abs/2511.18918 Vasudev Vikram, Caroline Lemieux, Joshua Sunshine, and Rohan Padhye
-
[22]
04346 Zihan Wang, Pengbo Nie, Xinyuan Miao, Yuting Chen, Chengcheng Wan, Lei Bu, and Jianjun Zhao
Can Large Language Models Write Good Property-Based Tests? arXiv:2307.04346 [cs.SE] https://arxiv.org/abs/2307. 04346 Zihan Wang, Pengbo Nie, Xinyuan Miao, Yuting Chen, Chengcheng Wan, Lei Bu, and Jianjun Zhao
-
[23]
GenCoG: A DSL-Based Approach to Generating Computation Graphs for TVM Testing. InProceedings of the 32nd ACM SIGSOFT International Symposium on Software T esting and Analysis(Seattle, WA, USA) (ISSTA 2023). Association for Computing Machinery, New York, NY, USA, 904–916. doi: 10.1145/ 3597926.3598105 Max Willsey, Chandrakana Nandi, Yisu Remy Wang, Oliver ...
arXiv 2023
-
[24]
egg: Fast and extensible equality saturation.Proc. ACM Program. Lang.5, POPL, Article 23 (Jan. 2021), 29 pages. doi:10.1145/3434304 Yichen Yang, Phitchaya Mangpo Phothilimtha, Yisu Remy Wang, Max Willsey, Sudip Roy, and Jacques Pienaar
-
[25]
Equality Saturation for Tensor Graph Superoptimization. arXiv:2101.01332 [cs.AI] https://arxiv.org/abs/2101.01332 Chijin Zhou, Bingzhou Qian, Gwihwan Go, Quan Zhang, Shanshan Li, and Yu Jiang
-
[26]
PolyJuice: Detecting Mis-compilation Bugs in Tensor Compilers with Equality Saturation Based Rewriting.Proc. ACM Program. Lang.8, OOPSLA2, Article 317 (Oct. 2024), 27 pages. doi:10.1145/3689757 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.