MedSIGHT: Towards Grounded Visual Comprehension in Medical Large Vision-Language Models
Pith reviewed 2026-06-28 01:27 UTC · model grok-4.3
The pith
MedSIGHT unifies medical image comprehension and segmentation in large vision-language models by adding a Region Perceiver and codebook.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
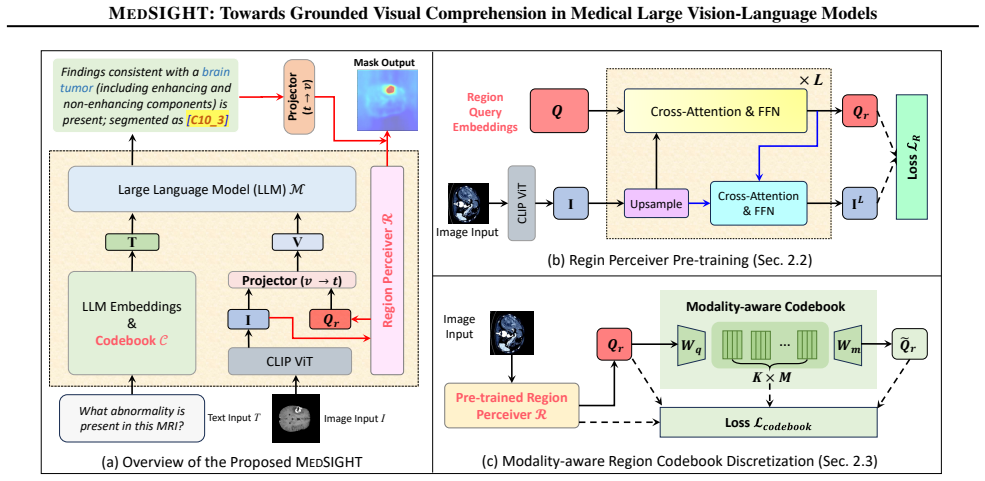
MedSIGHT equips Med-LVLMs with structured, pixel-level understanding for grounded visual comprehension. It introduces a Region Perceiver module that produces region-centric tokens encoding spatial information directly into the language model's representation space. A medical region codebook is added to the LLM vocabulary, allowing the model to generate discrete region codes as symbolic representations of anatomical and pathological regions. These codes are decoded through the Region Perceiver to reconstruct segmentation masks, achieving end-to-end spatial grounding. The components are combined via a progressive training strategy to align the modules stably, yielding state-of-the-art performa
What carries the argument
The Region Perceiver module that produces region-centric tokens encoding spatial information directly into the language model's representation space, paired with a medical region codebook inserted into the LLM vocabulary so discrete codes can be generated and decoded back to segmentation masks.
If this is right
- The model performs both comprehension and segmentation through the same forward pass by outputting and decoding region codes.
- Discrete codes function as inspectable symbolic stand-ins for anatomical and pathological regions.
- Progressive training keeps alignment stable when new modules are added to the base language model.
- State-of-the-art results appear across multiple imaging modalities despite the small training set size.
Where Pith is reading between the lines
- The codebook approach could make spatial outputs more human-inspectable than continuous mask regression in clinical review tools.
- The limited-data training path suggests the same unification pattern might transfer to other image domains that lack large paired datasets.
- End-to-end code generation opens the possibility of chaining the model with downstream symbolic reasoning systems that operate on region labels.
Load-bearing premise
The Region Perceiver can encode spatial information directly into the language model's representation space and the medical region codebook can be added to the LLM vocabulary such that discrete codes decode reliably to segmentation masks via end-to-end training on only 72K pairs.
What would settle it
A held-out test set where the model outputs region codes that fail to reconstruct accurate segmentation masks, or where enabling the codebook measurably lowers scores on standard medical comprehension benchmarks.
Figures




read the original abstract
Medical large vision-language models (Med-LVLMs) have recently achieved remarkable progress in vision-language comprehension and medical image segmentation. However, existing models still struggle to unify these two capabilities, which is essential for achieving clinically reasoning that connects visual findings with semantic interpretation. We present MedSIGHT, a unified framework that equips Med-LVLMs with structured, pixel-level understanding for grounded visual comprehension. MedSIGHT introduces a novel Region Perceiver module that produces region-centric tokens, encoding spatial information directly into representation space of the language model. We further propose a medical region codebook into the LLM vocabulary, allowing the model to generate discrete region codes as symbolic representations of anatomical and pathological regions. These codes are decoded through the Region Perceiver to reconstruct segmentation mask, achieving end-to-end spatial grounding. Lastly, MedSIGHT combines Region Perceiver, Codebook and LLM using our proposed progressive training strategy to gradually aligns these modules stably. Trained on only 72K multimodal instruction pairs, MedSIGHT achieves state-of-the-art performance across diverse imaging modalities on both medical comprehension and segmentation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MedSIGHT, a unified framework for medical large vision-language models that combines vision-language comprehension and image segmentation. It proposes a Region Perceiver to generate region-centric tokens that encode spatial information into the LLM representation space, insertion of a medical region codebook into the LLM vocabulary so that the model can output discrete region codes, and a progressive training strategy to align the components. The framework is trained on 72K multimodal instruction pairs and claims state-of-the-art results on both comprehension and segmentation across imaging modalities.
Significance. If the unification mechanism succeeds, the work would be significant for enabling clinically relevant grounded reasoning that links visual findings to semantic interpretation within a single Med-LVLM. The reported training scale of only 72K pairs would be noteworthy if accompanied by rigorous verification that spatial fidelity and language capability are both preserved.
major comments (2)
- [Abstract] Abstract: the central claim that region-centric tokens from the Region Perceiver carry pixel-level spatial information into the LLM representation space, that the medical region codebook can be inserted into the vocabulary without disrupting language modeling, and that LLM-generated codes can be inverted by the Perceiver into accurate masks, is asserted without any equations, architecture diagrams, or ablation results that would confirm information preservation or successful joint optimization.
- [Abstract] Abstract: the SOTA claim across modalities on both comprehension and segmentation tasks is presented with no quantitative results, baselines, ablation studies, or error analysis, leaving the unification benefit unverified and the load-bearing assumption that end-to-end training on 72K pairs suffices untested.
minor comments (1)
- [Abstract] Abstract: the phrase '72K multimodal instruction pairs' is used without specifying dataset composition, sources, or how the pairs cover both comprehension and segmentation annotations.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback on our work. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that region-centric tokens from the Region Perceiver carry pixel-level spatial information into the LLM representation space, that the medical region codebook can be inserted into the vocabulary without disrupting language modeling, and that LLM-generated codes can be inverted by the Perceiver into accurate masks, is asserted without any equations, architecture diagrams, or ablation results that would confirm information preservation or successful joint optimization.
Authors: The abstract is intentionally concise as a high-level summary. The full manuscript provides the requested supporting material: the Region Perceiver architecture and equations for token generation and mask inversion are detailed in Section 3.2 with Figure 1 showing the overall diagram; codebook insertion into the LLM vocabulary and its impact on language modeling are formalized in Section 3.3; and ablation studies confirming information preservation and joint optimization appear in Section 4.3. To improve clarity, we will revise the abstract to explicitly reference these sections and highlight key ablation outcomes. revision: yes
-
Referee: [Abstract] Abstract: the SOTA claim across modalities on both comprehension and segmentation tasks is presented with no quantitative results, baselines, ablation studies, or error analysis, leaving the unification benefit unverified and the load-bearing assumption that end-to-end training on 72K pairs suffices untested.
Authors: The abstract summarizes the overall findings while the main body contains the supporting evidence: Tables 1 and 2 report quantitative SOTA results with baselines across modalities for both tasks; Section 4 presents ablation studies on the progressive training strategy and the 72K-pair scale; and Section 5 includes error analysis. We agree that including representative metrics would make the abstract more informative. We will revise the abstract to incorporate key quantitative results and a brief note on the training verification. revision: yes
Circularity Check
No circularity: new architecture and training presented without self-referential derivations
full rationale
The paper introduces a Region Perceiver, medical region codebook, and progressive training as novel components, then reports empirical results from training on 72K pairs. No equations, first-principles derivations, or predictions are described that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The central claims concern the success of the new construction in unifying tasks, which is an empirical engineering claim rather than a mathematical reduction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked in the provided text. This is the expected non-finding for a model-proposal paper.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Region Perceiver
no independent evidence
-
medical region codebook
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Towards injecting medical visual knowledge into multimodal llms at scale
Chen, J., Gui, C., Ouyang, R., Gao, A., Chen, S., Chen, G., Wang, X., Cai, Z., Ji, K., Wan, X., et al. Towards injecting medical visual knowledge into multimodal llms at scale. InProceedings of the 2024 Conference on Em- pirical Methods in Natural Language Processing, pp. 7346–7370, 2024a. Chen, Y ., Xu, D., Huang, Y ., Zhan, S., Wang, H., Chen, D., Wang,...
2024
-
[2]
Chen, Z., Wang, W., Cao, Y ., Liu, Y ., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al. Expanding per- formance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024b. Cheng, B., Schwing, A., and Kirillov, A. Per-pixel clas- sification is not all you need for semantic segment...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Sam-med2d.arXiv preprint arXiv:2308.16184,
Cheng, J., Ye, J., Deng, Z., Chen, J., Li, T., Wang, H., Su, Y ., Huang, Z., Chen, J., Jiang, L., et al. Sam-med2d.arXiv preprint arXiv:2308.16184,
-
[4]
Codella, N., Rotemberg, V ., Tschandl, P., Celebi, M. E., Dusza, S., Gutman, D., Helba, B., Kalloo, A., Liopyris, K., Marchetti, M., et al. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic).arXiv preprint arXiv:1902.03368,
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
arXiv preprint arXiv:2003.10778 (2020)
Gamper, J., Koohbanani, N. A., Benes, K., Graham, S., Jahanifar, M., Khurram, S. A., Azam, A., Hewitt, K., and Rajpoot, N. Pannuke dataset extension, insights and baselines.arXiv preprint arXiv:2003.10778,
-
[6]
PathVQA: 30000+ Questions for Medical Visual Question Answering
He, X., Zhang, Y ., Mou, L., Xing, E., and Xie, P. Pathvqa: 30000+ questions for medical visual question answering. arXiv preprint arXiv:2003.10286,
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[7]
Heller, N., Isensee, F., Trofimova, D., Tejpaul, R., Zhao, Z., Chen, H., Wang, L., Golts, A., Khapun, D., Shats, D., et al. The kits21 challenge: Automatic segmentation of kidneys, renal tumors, and renal cysts in corticomedullary-phase ct.arXiv preprint arXiv:2307.01984,
-
[8]
U., Kunhimon, S., Naseer, M., Khan, S., and Khan, F
Khattak, M. U., Kunhimon, S., Naseer, M., Khan, S., and Khan, F. S. Unimed-clip: Towards a unified image-text pretraining paradigm for diverse medical imaging modal- ities.arXiv preprint arXiv:2412.10372,
-
[9]
Le-Duc, K., Nguyen, D. M., Trinh, P. T., Nguyen, T.-P., Diep, N. T., Ngo, A., Vu, T., Vuong, T., Nguyen, A.-T., Nguyen, M., et al. S-chain: Structured visual chain-of- thought for medicine.arXiv preprint arXiv:2510.22728,
-
[10]
R., Shen, Y ., Lu, Y ., Li, X., Chen, Q., and Chen, J
Liu, A., Xue, R., Cao, X. R., Shen, Y ., Lu, Y ., Li, X., Chen, Q., and Chen, J. Medsam3: Delving into seg- ment anything with medical concepts.arXiv preprint arXiv:2511.19046,
-
[11]
Luo, L., Tang, B., Chen, X., Han, R., and Chen, T. Vividmed: Vision language model with versatile visual grounding for medicine.arXiv preprint arXiv:2410.12694,
-
[12]
Medsam2: Segment anything in 3d medical images and videos.arXiv preprint arXiv:2504.03600,
Ma, J., Yang, Z., Kim, S., Chen, B., Baharoon, M., Fallah- pour, A., Asakereh, R., Lyu, H., and Wang, B. Medsam2: Segment anything in 3d medical images and videos.arXiv preprint arXiv:2504.03600,
-
[13]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Lasagna: Language-based segmentation assistant for complex queries.arXiv preprint arXiv:2404.08506,
Wei, C., Tan, H., Zhong, Y ., Yang, Y ., and Ma, L. Lasagna: Language-based segmentation assistant for complex queries.arXiv preprint arXiv:2404.08506,
-
[15]
Y ., Xie, C., et al
Xie, Y ., Zhou, C., Gao, L., Wu, J., Li, X., Zhou, H.-Y ., Liu, S., Xing, L., Zou, J. Y ., Xie, C., et al. Medtrinity- 25m: A large-scale multimodal dataset with multigranular annotations for medicine. InInternational Conference on Learning Representations, volume 2025, pp. 6036–6060,
2025
-
[16]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Xu, W., Chan, H. P., Li, L., Aljunied, M., Yuan, R., Wang, J., Xiao, C., Chen, G., Liu, C., Li, Z., et al. Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning.arXiv preprint arXiv:2506.07044,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Yang, S., Qu, T., Lai, X., Tian, Z., Peng, B., Liu, S., and Jia, J. Lisa++: An improved baseline for reasoning seg- mentation with large language model.arXiv preprint arXiv:2312.17240,
-
[19]
Ye, J., Cheng, J., Chen, J., Deng, Z., Li, T., Wang, H., Su, Y ., Huang, Z., Chen, J., Jiang, L., et al. Sa-med2d-20m dataset: Segment anything in 2d medical imaging with 20 million masks.arXiv preprint arXiv:2311.11969,
-
[20]
ai.arXiv preprint arXiv:2403.04652,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Detailed Training Objectives A.1
12 MEDSIGHT: Towards Grounded Visual Comprehension in Medical Large Vision-Language Models A. Detailed Training Objectives A.1. Region Perceiver Given the final set of region queriesQr ={q i}N i=1,q i ∈R d, and the highest–resolution visual feature map after upsampling Ir ∈R H L×W L×d, the Region Perceiver predicts a segmentation mask for each region by c...
2020
-
[22]
image_id
and Mask2Former (Cheng et al., 2022), we use the Binary Cross-Entropy loss: Lbce(Ir,Q r) = BCE ˜M(Ir,Q r),M gt .(4) Similarly, the Dice loss is also included: Ldice(Ir,Q r) = Dice ˜M(Ir,Q r),M gt .(5) The combined segmentation objective is: Lseg(Ir,Q r) =λ 1 Lbce(Ir,Q r) +λ 2 Ldice(Ir,Q r).(6) Region-level classification loss.To endow region queries with ...
2022
-
[23]
For the Region Perceiver, we set the number of layers to L= 3 and use 20 region query tokens
as the visual encoder. For the Region Perceiver, we set the number of layers to L= 3 and use 20 region query tokens. Pre-training is conducted on the BiomedParse training set for 20 epochs with a learning rate of 1×10 −4. In the segmentation loss LR, we specify the hyperparameters λ1 and λ2 both as 5 following Mask2Former (Cheng et al., 2022). The codeboo...
2022
-
[24]
For the OmniMed benchmark, we also adopt the modality selection used in HealthGPT
Following HealthGPT (Lin et al., 2025), we use the validation split of MMMU-Med for all comparisons. For the OmniMed benchmark, we also adopt the modality selection used in HealthGPT. Specifically, the evaluation covers the following imaging modalities: Computed Tomography, X-ray Radiography, Fundus Photography, Microscopy Imaging, Optical Coherence Tomog...
2025
-
[25]
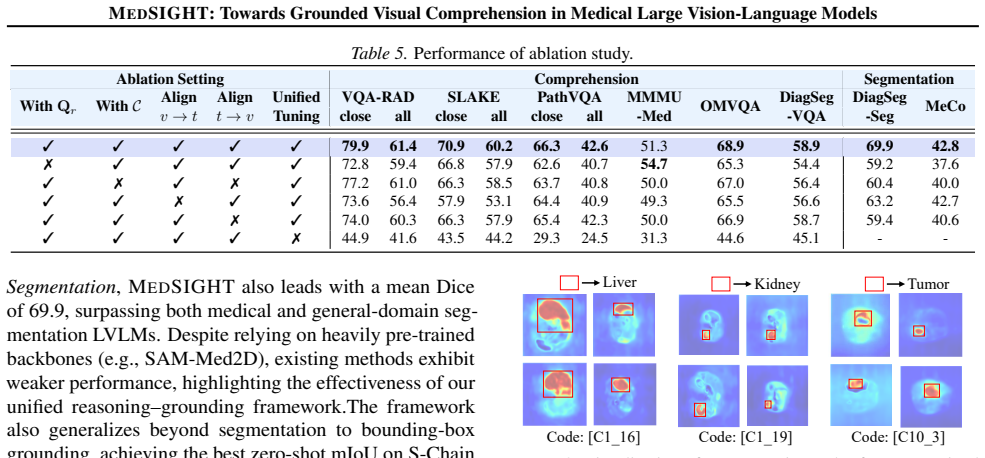
The highly concentrated distributions show that region codes remain semantically consistent across samples rather than being arbitrarily assigned
Using 100 abdominal CT images from the BiomedParse test set, we analyze the Top-3 code assignments for liver and kid- ney regions. The highly concentrated distributions show that region codes remain semantically consistent across samples rather than being arbitrarily assigned. F.3. Case Study To further demonstrate the capabilities of MEDSIGHT, we present...
2021
-
[26]
and MedPLIB (Huang et al., 2025), MEDSIGHT naturally supports bounding-box localization byderiving bounding boxes from the decoded segmentation masks, which is a standard practice in grounding-based frameworks. To validate this grounding capacity beyond segmentation, we conduct additionalzero-shotbounding-box localization experiments on two recent visual ...
2025
-
[27]
For S-Chain, we evaluate zero-shot performance on a randomly sampled subset of 100 images from the English test set
and MedTrinity- 25M (Xie et al., 2025). For S-Chain, we evaluate zero-shot performance on a randomly sampled subset of 100 images from the English test set. For MedTrinity-25M, since parts of the dataset are annotated using automated grounding models (as it is primarily designed for training), we restrict evaluation to a subset withexpert-annotatedboundin...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.