Evidence-Based Intelligent Diagnostic and Therapeutic Visualization System with Large Language Models: Multi-Turn Interaction and Multimodal Treatment Plan Generation
Pith reviewed 2026-06-27 22:10 UTC · model grok-4.3
The pith
A knowledge graph constrains large language models to produce more standard and transparent outputs for traditional Chinese medicine diagnosis and treatment planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The system uses a knowledge graph of 241 syndromes, 1,263 symptoms, and 2,485 relations together with exact, semantic, fuzzy, and LLM-verified matching plus genetically optimized proactive questions to constrain LLM outputs, resulting in a 32 percent drop in non-standard responses and statistically significant gains in trust (Cohen's d = 1.82) and reference credibility (4.21 versus 2.95) across automated paired comparisons of 30 cases.
What carries the argument
Knowledge graph constraints on large language model generation, enforced through a four-stage symptom matching pipeline and information-gain questioning strategy.
If this is right
- Knowledge graph constraints reduce non-standard outputs by 32 percent.
- Diagnostic trust rises with a large effect size (Cohen's d = 1.82, p < 0.001).
- Cognitive load decreases across four of five measured dimensions.
- Credibility scores for evidence-based references increase from 2.95 to 4.21.
- The workflow supports patient self-assessment, clinician diagnosis, and education through multimodal visualizations.
Where Pith is reading between the lines
- The same constraint-plus-visualization pattern could be tested in other pattern-recognition medical domains where LLMs currently produce variable outputs.
- Longer-term studies would be needed to check whether higher trust scores translate into changed clinical decisions or patient adherence.
- The genetic-algorithm optimization of questioning might scale to larger symptom sets if the graph relations remain stable.
- Multimodal elements such as 3D meridian models could be isolated in follow-up work to measure their separate contribution to understanding.
Load-bearing premise
Gains in perceived trust and reduced cognitive load measured on 30 simulated cases will correspond to improved real clinical diagnostic accuracy and safety.
What would settle it
A head-to-head clinical trial that tracks actual diagnostic error rates and patient outcomes when clinicians use the system versus standard methods.
Figures


read the original abstract
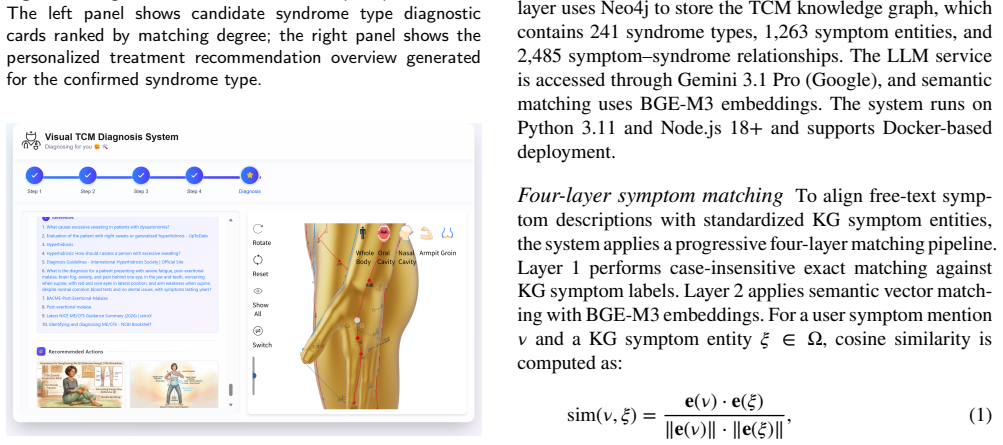
Aim: Existing AI-assisted traditional Chinese medicine diagnostic tools suffer from opaque reasoning processes, passive interaction, and limited treatment plan presentation. This study proposes a knowledge-enhanced visual diagnostic system to improve the transparency and interpretability of syndrome differentiation and treatment. Methods: The system is built upon a Neo4j knowledge graph comprising 241 syndromes, 1,263 symptoms, and 2,485 relations. It incorporates a four-stage symptom matching pipeline (exact, semantic, fuzzy, and large language model verification), an information gain-driven proactive questioning strategy optimized with genetic algorithms, and a multimodal treatment presentation integrating artificial intelligence-generated illustrations, three-dimensional meridian-acupoint models, and evidence-based literature. Results: Knowledge graph constraints reduced non-standard outputs by 32%. Case studies validated the effectiveness of the interactive workflow across patient self-assessment, clinician-assisted diagnosis, and traditional Chinese medicine education. Automated paired-comparison evaluation across 30 cases further demonstrated significant improvements in diagnostic trust (Cohen's d = 1.82, p < 0.001), reduced cognitive load (improvements in four of five dimensions), and higher credibility of evidence-based references (4.21 vs. 2.95). Conclusions: The proposed system enhances the transparency of traditional Chinese medicine diagnostic reasoning and the interpretability of treatment plans through knowledge graph-driven visualization and multimodal interaction, offering a practical solution for trustworthy artificial intelligence-assisted traditional Chinese medicine applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a knowledge-enhanced visual diagnostic system for traditional Chinese medicine (TCM) built on a Neo4j knowledge graph (241 syndromes, 1,263 symptoms, 2,485 relations). It incorporates a four-stage symptom matching pipeline (exact, semantic, fuzzy, LLM verification), information-gain-driven proactive questioning optimized by genetic algorithms, and multimodal treatment plan visualization. The central claims are that KG constraints reduce non-standard outputs by 32% and that an automated paired-comparison evaluation on 30 cases shows significant gains in diagnostic trust (Cohen's d = 1.82, p < 0.001), cognitive load, and evidence-based reference credibility (4.21 vs. 2.95), validated through case studies across self-assessment, clinician-assisted diagnosis, and education.
Significance. If the evaluation protocol and metrics can be shown to reflect objective diagnostic improvements, the work would offer a concrete example of combining KG constraints with LLMs and multimodal interfaces to increase transparency in TCM syndrome differentiation. The explicit KG scale, staged matching pipeline, and multimodal output components are strengths that could support reproducibility and extension. The proactive questioning strategy and visualization elements address real usability gaps in existing AI-assisted TCM tools.
major comments (3)
- [Results] Results paragraph: The headline claim that 'Knowledge graph constraints reduced non-standard outputs by 32%' provides no definition of non-standard outputs, no description of the baseline system, no selection criteria for the 30 cases, and no indication whether the comparison was blinded. These omissions are load-bearing because the 32% figure is presented as primary quantitative evidence for the KG's benefit.
- [Results] Results paragraph: The automated paired-comparison evaluation reports Cohen's d = 1.82 for diagnostic trust and credibility scores (4.21 vs. 2.95) based on perceived transparency and reference quality, yet supplies no expert-rated diagnostic correctness against ground truth, no inter-rater agreement with TCM specialists, and no downstream clinical outcome measures. This gap directly affects the central claim that the system improves trustworthy diagnostic reasoning rather than only perceived interpretability.
- [Methods] Methods (four-stage pipeline description): No ablation results or per-stage performance metrics (precision/recall for exact vs. semantic vs. fuzzy vs. LLM verification) are reported, making it impossible to determine which component drives the claimed reduction in non-standard outputs or the trust improvements.
minor comments (2)
- [Abstract] The abstract would benefit from a brief parenthetical note on how the 30 cases were sampled and what the baseline comparator was, even if full details appear later.
- [Figures] Figure captions for the multimodal treatment visualizations should explicitly state whether the AI-generated illustrations and 3D models were evaluated for clinical accuracy by domain experts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on evaluation clarity and scope. We address each major comment below and will revise the manuscript to strengthen the presentation of results and methods.
read point-by-point responses
-
Referee: [Results] Results paragraph: The headline claim that 'Knowledge graph constraints reduced non-standard outputs by 32%' provides no definition of non-standard outputs, no description of the baseline system, no selection criteria for the 30 cases, and no indication whether the comparison was blinded. These omissions are load-bearing because the 32% figure is presented as primary quantitative evidence for the KG's benefit.
Authors: We agree the original text omitted key operational details. In revision we will explicitly define non-standard outputs as LLM-generated syndromes or relations that violate the Neo4j graph constraints (i.e., no supporting edge exists between the proposed syndrome and the observed symptoms). The baseline is the identical LLM pipeline run without the four-stage KG filtering step. The 30 cases were drawn from a curated set of common TCM presentations documented in standard textbooks; selection was performed by stratified sampling across symptom clusters. Because the comparison is fully automated, blinding does not apply and we will state this explicitly. These additions will be placed in a new subsection of Results. revision: yes
-
Referee: [Results] Results paragraph: The automated paired-comparison evaluation reports Cohen's d = 1.82 for diagnostic trust and credibility scores (4.21 vs. 2.95) based on perceived transparency and reference quality, yet supplies no expert-rated diagnostic correctness against ground truth, no inter-rater agreement with TCM specialists, and no downstream clinical outcome measures. This gap directly affects the central claim that the system improves trustworthy diagnostic reasoning rather than only perceived interpretability.
Authors: The study deliberately measured perceived trust, cognitive load, and reference credibility because its stated aim is improved transparency and interpretability rather than diagnostic accuracy per se. No ground-truth expert ratings or clinical outcome data were collected. We will revise the Results and Discussion sections to (a) state this scope limitation clearly and (b) temper the language so that claims refer to gains in perceived trustworthiness and evidence-based interpretability rather than to verified diagnostic correctness. No new data collection is feasible at this stage, so the revision will be limited to clarification and scope adjustment. revision: partial
-
Referee: [Methods] Methods (four-stage pipeline description): No ablation results or per-stage performance metrics (precision/recall for exact vs. semantic vs. fuzzy vs. LLM verification) are reported, making it impossible to determine which component drives the claimed reduction in non-standard outputs or the trust improvements.
Authors: We accept that the absence of per-stage metrics and ablations limits interpretability of the 32 % figure. In the revised manuscript we will add a new table reporting precision, recall, and F1 for each of the four stages on the same 30-case set, together with an ablation that successively removes each stage and re-measures the non-standard output rate. These results will be placed in Methods and Results. revision: yes
Circularity Check
No circularity; claims rest on direct empirical evaluations of implemented system
full rationale
The paper presents an applied system whose headline results (32% reduction in non-standard outputs, Cohen's d=1.82 on trust, credibility scores 4.21 vs 2.95) are obtained from automated paired-comparison runs on 30 cases plus user studies. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the knowledge-graph pipeline, genetic-algorithm questioning, and multimodal outputs are described as engineered components whose performance is measured externally rather than derived by construction from their own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bioinformatics , volume=
A benchmark for automatic medical consultation system: frameworks, tasks and datasets , author=. Bioinformatics , volume=. 2023 , doi=
2023
-
[2]
Nature medicine , volume=
Large language models in medicine , author=. Nature medicine , volume=. 2023 , doi=
2023
-
[3]
Informatics , volume=
Large language models in healthcare and medical domain: A review , author=. Informatics , volume=. 2024 , doi=
2024
-
[4]
Multimodal
Belyaeva, Anastasiya and Cosentino, Justin and Hormozdiari, Farhad and Eswaran, Krish and Shetty, Shravya and Corrado, Greg and Carroll, Andrew and McLean, Cory Y and Furlotte, Nicholas A , booktitle=. Multimodal. 2023 , doi=
2023
-
[8]
Health Care Science , volume=
Large language models in health care: Development, applications, and challenges , author=. Health Care Science , volume=. 2023 , doi=
2023
-
[9]
A survey on recent advances in
Yi, Zihao and Ouyang, Jiarui and Xu, Zhe and Liu, Yuwen and Liao, Tianhao and Luo, Haohao and Shen, Ying , journal=. A survey on recent advances in. 2025 , doi=
2025
-
[10]
Future Generation Computer Systems , volume=
Visualizing large knowledge graphs: A performance analysis , author=. Future Generation Computer Systems , volume=. 2018 , doi=
2018
-
[11]
Sukhwal, Prakash C and Rajan, Vaibhav and Kankanhalli, Atreyi , journal=. A Joint. 2025 , doi=
2025
-
[12]
PLOS Digital Health , volume=
Retrieval augmented generation for large language models in healthcare: A systematic review , author=. PLOS Digital Health , volume=. 2025 , doi=
2025
-
[14]
IEEE transactions on visualization and computer graphics , volume=
A multi-level typology of abstract visualization tasks , author=. IEEE transactions on visualization and computer graphics , volume=. 2013 , doi=
2013
-
[15]
IEEE Transactions on Visualization and Computer Graphics , volume=
Node, node-link, and node-link-group diagrams: An evaluation , author=. IEEE Transactions on Visualization and Computer Graphics , volume=. 2014 , doi=
2014
-
[16]
2025 , doi=
Yan, Youfu and Hou, Yu and Xiao, Yongkang and Zhang, Rui and Wang, Qianwen , journal=. 2025 , doi=
2025
-
[17]
Proactive conversational agents in the post-
Liao, Lizi and Yang, Grace Hui and Shah, Chirag , booktitle=. Proactive conversational agents in the post-. 2023 , doi=
2023
-
[18]
2007 , edition=
Zhongyi Zhenduan Xue (Diagnostics of Traditional Chinese Medicine) , author=. 2007 , edition=
2007
-
[19]
npj Digital Medicine , volume=
Diagnostic reasoning prompts reveal the potential for large language model interpretability in medicine , author=. npj Digital Medicine , volume=. 2024 , doi=
2024
-
[20]
Beyond transparency and explainability: on the need for adequate and contextualized user guidelines for
Barman, Kristian Gonz. Beyond transparency and explainability: on the need for adequate and contextualized user guidelines for. Ethics and Information Technology , volume=. 2024 , doi=
2024
-
[21]
Evaluating the appropriateness, consistency, and readability of
Balta, Kaan Y and Javidan, Arshia P and Walser, Eric and Arntfield, Robert and Prager, Ross , journal=. Evaluating the appropriateness, consistency, and readability of. 2025 , doi=
2025
-
[22]
ACM Transactions on Information Systems , volume=
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions , author=. ACM Transactions on Information Systems , volume=. 2025 , doi=
2025
-
[24]
Considerations on the use of artificial intelligence in generating anatomical images: Comment on ``Evaluating
Cornwall, Jon and Krebs, Claudia and Hildebrandt, Sabine and Gregory, Jill and Pennefather, Patrick , journal=. Considerations on the use of artificial intelligence in generating anatomical images: Comment on ``Evaluating. 2024 , doi=
2024
-
[25]
IEEE transactions on visualization and computer graphics , volume=
Polyphony: An interactive transfer learning framework for single-cell data analysis , author=. IEEE transactions on visualization and computer graphics , volume=. 2023 , doi=
2023
-
[26]
2025 , doi=
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and others , journal=. 2025 , doi=
2025
-
[27]
Knowledge-tuning large language models with structured medical knowledge bases for trustworthy response generation in
Wang, Haochun and Zhao, Sendong and Qiang, Zewen and Li, Zijian and Liu, Chi and Xi, Nuwa and Du, Yanrui and Qin, Bing and Liu, Ting , journal=. Knowledge-tuning large language models with structured medical knowledge bases for trustworthy response generation in. 2025 , doi=
2025
-
[28]
2023 , doi=
Chen, Yirong and Wang, Zhenyu and Xing, Xiaofen and Zheng, Huimin and Xu, Zhipei and Fang, Kai and Wang, Junhong and Li, Sihang and Wu, Jieling and Liu, Qi and Xu, Xiangmin , journal=. 2023 , doi=
2023
-
[30]
Evidence-based complementary and alternative medicine : eCAM , volume=
Visualization of the Meridian System Based on Biomedical Information about Acupuncture Treatment , author=. Evidence-based complementary and alternative medicine : eCAM , volume=. 2013 , doi=
2013
-
[31]
2025 , publisher=
Zhao, Xuejiao and Liu, Siyan and Yang, Su-Yin and Miao, Chunyan , booktitle=. 2025 , publisher=
2025
-
[33]
International Journal of Human-Computer Studies , volume=
Operationalizing selective transparency using progressive disclosure in artificial intelligence clinical diagnosis systems , author=. International Journal of Human-Computer Studies , volume=. 2025 , doi=
2025
-
[34]
JAMA Network Open , volume=
Generative Artificial Intelligence to Transform Inpatient Discharge Summaries to Patient-Friendly Language and Format , author=. JAMA Network Open , volume=. 2024 , doi=
2024
-
[35]
npj Digital Medicine , volume=
Augmented non-hallucinating large language models as medical information curators , author=. npj Digital Medicine , volume=. 2024 , doi=
2024
-
[36]
BMC Health Services Research , volume=
The effectiveness of visual-based interventions on health literacy in health care: a systematic review and meta-analysis , author=. BMC Health Services Research , volume=. 2024 , doi=
2024
-
[37]
Annals of Translational Medicine , volume=
Current status and trends of artificial intelligence research on the four traditional Chinese medicine diagnostic methods: a scientometric study , author=. Annals of Translational Medicine , volume=. 2023 , doi=
2023
-
[38]
, booktitle=
Liu, Xinyi and Sun, Dachun and Fung, Yi and Hakkani-Tur, Dilek and Abdelzaher, Tarek F. , booktitle=. 2025 , address=
2025
-
[39]
Liu, Wenge and Cheng, Yi and Wang, Hao and Tang, Jianheng and Liu, Yafei and Zhao, Ruihui and Li, Wenjie and Zheng, Yefeng and Liang, Xiaodan , booktitle=. ``. 2022 , doi=
2022
-
[42]
Health Education & Behavior , volume=
The Application of Cognitive Load Theory to the Design of Health and Behavior Change Programs: Principles and Recommendations , author=. Health Education & Behavior , volume=. 2025 , doi=
2025
-
[43]
Large language models in medicine
Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. Large language models in medicine. Nature medicine , 29(8):1930--1940, 2023
1930
-
[44]
Large language models in health care: Development, applications, and challenges
Rui Yang, Ting Fang Tan, Wei Lu, Arun James Thirunavukarasu, Daniel Shu Wei Ting, and Nan Liu. Large language models in health care: Development, applications, and challenges. Health Care Science , 2(4):255--263, 2023
2023
-
[45]
Large language models in healthcare and medical domain: A review
Zabir Al Nazi and Wei Peng. Large language models in healthcare and medical domain: A review. Informatics , 11(3):57, 2024
2024
-
[46]
Knowledge-tuning large language models with structured medical knowledge bases for trustworthy response generation in Chinese
Haochun Wang, Sendong Zhao, Zewen Qiang, Zijian Li, Chi Liu, Nuwa Xi, Yanrui Du, Bing Qin, and Ting Liu. Knowledge-tuning large language models with structured medical knowledge bases for trustworthy response generation in Chinese . ACM Transactions on Knowledge Discovery from Data , 19(2):1--17, 2025
2025
-
[47]
Yirong Chen, Zhenyu Wang, Xiaofen Xing, Huimin Zheng, Zhipei Xu, Kai Fang, Junhong Wang, Sihang Li, Jieling Wu, Qi Liu, and Xiangmin Xu. BianQue : Balancing the questioning and suggestion ability of health LLM s with multi-turn health conversations polished by ChatGPT . arXiv preprint arXiv:2310.15896 , 2023. Preprint
arXiv 2023
-
[48]
Towards injecting medical visual knowledge into multimodal LLM s at scale
Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xidong Wang, Zhenyang Cai, Ke Ji, Xiang Wan, and Benyou Wang. Towards injecting medical visual knowledge into multimodal LLM s at scale. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages 7346--7370, Miami, Florida, USA, 2024...
2024
-
[49]
Visualizing large knowledge graphs: A performance analysis
Juan G \'o mez-Romero, Miguel Molina-Solana, Axel Oehmichen, and Yike Guo. Visualizing large knowledge graphs: A performance analysis. Future Generation Computer Systems , 89:224--238, 2018
2018
-
[50]
Node, node-link, and node-link-group diagrams: An evaluation
Bahador Saket, Paolo Simonetto, Stephen Kobourov, and Katy B rner. Node, node-link, and node-link-group diagrams: An evaluation. IEEE Transactions on Visualization and Computer Graphics , 20(12):2231--2240, 2014
2014
-
[51]
A multi-level typology of abstract visualization tasks
Matthew Brehmer and Tamara Munzner. A multi-level typology of abstract visualization tasks. IEEE transactions on visualization and computer graphics , 19(12):2376--2385, 2013
2013
-
[52]
KNowNEt : Guided health information seeking from LLM s via knowledge graph integration
Youfu Yan, Yu Hou, Yongkang Xiao, Rui Zhang, and Qianwen Wang. KNowNEt : Guided health information seeking from LLM s via knowledge graph integration. IEEE Transactions on Visualization and Computer Graphics , 31(1):547--557, 2025
2025
-
[53]
A joint LLM - KG system for disease Q&A
Prakash C Sukhwal, Vaibhav Rajan, and Atreyi Kankanhalli. A joint LLM - KG system for disease Q&A . IEEE Journal of Biomedical and Health Informatics , 29(3):2257--2270, 2025
2025
-
[54]
Polyphony: An interactive transfer learning framework for single-cell data analysis
Furui Cheng, Mark S Keller, Huamin Qu, Nils Gehlenborg, and Qianwen Wang. Polyphony: An interactive transfer learning framework for single-cell data analysis. IEEE transactions on visualization and computer graphics , 29(1):591--601, 2023
2023
-
[55]
Multimodal LLM s for health grounded in individual-specific data
Anastasiya Belyaeva, Justin Cosentino, Farhad Hormozdiari, Krish Eswaran, Shravya Shetty, Greg Corrado, Andrew Carroll, Cory Y McLean, and Nicholas A Furlotte. Multimodal LLM s for health grounded in individual-specific data. In Machine Learning for Multimodal Healthcare Data , pages 86--102. Springer Nature Switzerland, 2023
2023
-
[56]
Knowledge graphs meet multi-modal learning: A comprehensive survey
Zhuo Chen, Yichi Zhang, Yin Fang, Yuxia Geng, Lingbing Guo, Xiang Chen, Qian Li, Wen Zhang, Jiaoyan Chen, Yushan Zhu, et al. Knowledge graphs meet multi-modal learning: A comprehensive survey. arXiv preprint arXiv:2402.05391 , 2024. Preprint
arXiv 2024
-
[57]
Visualization of the meridian system based on biomedical information about acupuncture treatment
In-Seon Lee, Soon-Ho Lee, Song-Yi Kim, Hyejung Lee, Hi-Joon Park, and Younbyoung Chae. Visualization of the meridian system based on biomedical information about acupuncture treatment. Evidence-based complementary and alternative medicine : eCAM , 2013:872142, 2013
2013
-
[58]
Jon Cornwall, Claudia Krebs, Sabine Hildebrandt, Jill Gregory, and Patrick Pennefather. Considerations on the use of artificial intelligence in generating anatomical images: Comment on ``evaluating AI -powered text-to-image generators for anatomical illustration: A comparative study''. Anatomical sciences education , 17(5):1097--1099, 2024
2024
-
[59]
Med-HALT : Medical domain hallucination test for large language models
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Med-HALT : Medical domain hallucination test for large language models. In Proceedings of the 27th Conference on Computational Natural Language Learning (CoNLL) , pages 314--334, Singapore, 2023. Association for Computational Linguistics
2023
-
[60]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems , 43(2):1--55, 2025
2025
-
[61]
Medical hallucination in foundation models and their impact on healthcare
Yubin Kim, Hyewon Jeong, Shan Chen, Shuyue Stella Li, Chanwoo Park, Mingyu Lu, Kumail Alhamoud, Jimin Mun, Cristina Grau, Minseok Jung, et al. Medical hallucination in foundation models and their impact on healthcare. medRxiv , 2025. Preprint
2025
-
[62]
Retrieval augmented generation for large language models in healthcare: A systematic review
Lameck Mbangula Amugongo, Pietro Mascheroni, Steven Brooks, Stefan Doering, and Jan Seidel. Retrieval augmented generation for large language models in healthcare: A systematic review. PLOS Digital Health , 4(6):e0000877, 2025
2025
-
[63]
Augmented non-hallucinating large language models as medical information curators
Stephen Gilbert, Jakob Nikolas Kather, and Aidan Hogan. Augmented non-hallucinating large language models as medical information curators. npj Digital Medicine , 7(1):100, 2024
2024
-
[64]
Zhongyi Zhenduan Xue (Diagnostics of Traditional Chinese Medicine)
Wenfeng Zhu. Zhongyi Zhenduan Xue (Diagnostics of Traditional Chinese Medicine). China Press of Traditional Chinese Medicine, Beijing, 2 edition, 2007
2007
-
[65]
Large language models in medicine
Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. Large language models in medicine. Nature medicine, 29 0 (8): 0 1930--1940, 2023. doi:10.1038/s41591-023-02448-8
-
[66]
Large language models in healthcare and medical domain: A review
Zabir Al Nazi and Wei Peng. Large language models in healthcare and medical domain: A review. Informatics, 11 0 (3): 0 57, 2024. doi:10.3390/informatics11030057
-
[67]
Large language models in health care: Development, applications, and challenges
Rui Yang, Ting Fang Tan, Wei Lu, Arun James Thirunavukarasu, Daniel Shu Wei Ting, and Nan Liu. Large language models in health care: Development, applications, and challenges. Health Care Science, 2 0 (4): 0 255--263, 2023. doi:10.1002/hcs2.61
-
[68]
Thomas Savage, Ashwin Nayak, Robert Gallo, Ekanath Rangan, and Jonathan H. Chen. Diagnostic reasoning prompts reveal the potential for large language model interpretability in medicine. npj Digital Medicine, 7 0 (1): 0 20, 2024. doi:10.1038/s41746-024-01010-1
-
[69]
Kristian Gonz \'a lez Barman, Nathan Wood, and Pawel Pawlowski. Beyond transparency and explainability: on the need for adequate and contextualized user guidelines for LLM use. Ethics and Information Technology, 26 0 (3): 0 47, 2024. doi:10.1007/s10676-024-09778-2
-
[70]
STaR-GATE : Teaching language models to ask clarifying questions
Chinmaya Andukuri, Jan-Philipp Fr \"a nken, Tobias Gerstenberg, and Noah D Goodman. STaR-GATE : Teaching language models to ask clarifying questions. arXiv preprint arXiv:2403.19154, 2024. doi:10.48550/arXiv.2403.19154. URL https://arxiv.org/abs/2403.19154. Preprint
-
[71]
Proactive conversational agents in the post- ChatGPT world
Lizi Liao, Grace Hui Yang, and Chirag Shah. Proactive conversational agents in the post- ChatGPT world. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 3452--3455, 2023. doi:10.1145/3539618.3594250
-
[72]
Jonah Zaretsky, Jeong Min Kim, Samuel Baskharoun, Yunan Zhao, Jonathan Austrian, Yindalon Aphinyanaphongs, Ravi Gupta, Saul B. Blecker, and Jonah Feldman. Generative artificial intelligence to transform inpatient discharge summaries to patient-friendly language and format. JAMA Network Open, 7 0 (3): 0 e240357, 2024. doi:10.1001/jamanetworkopen.2024.0357
-
[73]
Baxter, Nidhi Sachdeva, and Sabine Baker
Kimberley A. Baxter, Nidhi Sachdeva, and Sabine Baker. The application of cognitive load theory to the design of health and behavior change programs: Principles and recommendations. Health Education & Behavior, 52 0 (4): 0 469--477, 2025. doi:10.1177/10901981251327185
-
[74]
Med-HALT : Medical domain hallucination test for large language models
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Med-HALT : Medical domain hallucination test for large language models. In Proceedings of the 27th Conference on Computational Natural Language Learning (CoNLL), pages 314--334, Singapore, 2023. Association for Computational Linguistics. doi:10.18653/v1/2023.conll-1.21. URL https://aclantholo...
-
[75]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems, 43 0 (2): 0 1--55, 2025. doi:10.1145/3703155
-
[76]
Medical hallucination in foundation models and their impact on healthcare
Yubin Kim, Hyewon Jeong, Shan Chen, Shuyue Stella Li, Chanwoo Park, Mingyu Lu, Kumail Alhamoud, Jimin Mun, Cristina Grau, Minseok Jung, et al. Medical hallucination in foundation models and their impact on healthcare. medRxiv, 2025. doi:10.1101/2025.02.28.25323115. URL https://www.medrxiv.org/content/10.1101/2025.02.28.25323115v2. Preprint
-
[77]
A benchmark for automatic medical consultation system: frameworks, tasks and datasets
Wei Chen, Zhiwei Li, Hongyi Fang, Qianyuan Yao, Cheng Zhong, Jianye Hao, Qi Zhang, Xuanjing Huang, Jiajie Peng, and Zhongyu Wei. A benchmark for automatic medical consultation system: frameworks, tasks and datasets. Bioinformatics, 39 0 (1): 0 btac817, 2023 a . doi:10.1093/bioinformatics/btac817
-
[78]
A survey on recent advances in LLM -based multi-turn dialogue systems
Zihao Yi, Jiarui Ouyang, Zhe Xu, Yuwen Liu, Tianhao Liao, Haohao Luo, and Ying Shen. A survey on recent advances in LLM -based multi-turn dialogue systems. ACM Computing Surveys, 58 0 (6): 0 1--38, 2025. doi:10.1145/3771090
-
[79]
Abdelzaher
Xinyi Liu, Dachun Sun, Yi Fung, Dilek Hakkani-Tur, and Tarek F. Abdelzaher. DocCHA : Towards LLM -augmented interactive online diagnosis system. In Proceedings of the 26th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 609--619, Avignon, France, 2025. Association for Computational Linguistics. URL https://aclanthology.org/20...
2025
-
[80]
Yirong Chen, Zhenyu Wang, Xiaofen Xing, Huimin Zheng, Zhipei Xu, Kai Fang, Junhong Wang, Sihang Li, Jieling Wu, Qi Liu, and Xiangmin Xu. BianQue : Balancing the questioning and suggestion ability of health LLM s with multi-turn health conversations polished by ChatGPT . arXiv preprint arXiv:2310.15896, 2023 b . doi:10.48550/arXiv.2310.15896. URL https://a...
-
[81]
Visualizing large knowledge graphs: A performance analysis
Juan G \'o mez-Romero, Miguel Molina-Solana, Axel Oehmichen, and Yike Guo. Visualizing large knowledge graphs: A performance analysis. Future Generation Computer Systems, 89: 0 224--238, 2018. doi:10.1016/j.future.2018.06.015
-
[82]
Knowledge graphs meet multi-modal learning: A comprehensive survey
Zhuo Chen, Yichi Zhang, Yin Fang, Yuxia Geng, Lingbing Guo, Xiang Chen, Qian Li, Wen Zhang, Jiaoyan Chen, Yushan Zhu, et al. Knowledge graphs meet multi-modal learning: A comprehensive survey. arXiv preprint arXiv:2402.05391, 2024 a . doi:10.48550/arXiv.2402.05391. URL https://arxiv.org/abs/2402.05391. Preprint
-
[83]
KNowNEt : Guided health information seeking from LLM s via knowledge graph integration
Youfu Yan, Yu Hou, Yongkang Xiao, Rui Zhang, and Qianwen Wang. KNowNEt : Guided health information seeking from LLM s via knowledge graph integration. IEEE Transactions on Visualization and Computer Graphics, 31 0 (1): 0 547--557, 2025. doi:10.1109/TVCG.2024.3456364
-
[84]
A joint LLM - KG system for disease Q&A
Prakash C Sukhwal, Vaibhav Rajan, and Atreyi Kankanhalli. A joint LLM - KG system for disease Q&A . IEEE Journal of Biomedical and Health Informatics, 29 0 (3): 0 2257--2270, 2025. doi:10.1109/JBHI.2024.3514659
-
[85]
Xuejiao Zhao, Siyan Liu, Su-Yin Yang, and Chunyan Miao. MedRAG : Enhancing retrieval-augmented generation with knowledge graph-elicited reasoning for healthcare copilot. In Proceedings of the ACM on Web Conference 2025, pages 4442--4457. ACM, 2025. doi:10.1145/3696410.3714782
-
[86]
Normalising medical concepts in social media texts by learning semantic representation
Nut Limsopatham and Nigel Collier. Normalising medical concepts in social media texts by learning semantic representation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1014--1023, Berlin, Germany, 2016. Association for Computational Linguistics. doi:10.18653/v1/P16-1096. URL http...
-
[87]
Sudha Rao and Hal Daum \'e III. Learning to ask good questions: Ranking clarification questions using neural expected value of perfect information. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2737--2746, Melbourne, Australia, 2018. Association for Computational Linguistics. doi:...
-
[88]
Elisa Galmarini, Laura Marciano, and Peter Johannes Schulz. The effectiveness of visual-based interventions on health literacy in health care: a systematic review and meta-analysis. BMC Health Services Research, 24 0 (1): 0 718, 2024. doi:10.1186/s12913-024-11138-1
-
[89]
Task-oriented dialogue system for automatic diagnosis
Zhongyu Wei, Qianlong Liu, Baolin Peng, Huaixiao Tou, Ting Chen, Xuanjing Huang, Kam-fai Wong, and Xiangying Dai. Task-oriented dialogue system for automatic diagnosis. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 201--207, Melbourne, Australia, 2018. Association for Computation...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.