GenPO++: Generative Policy Optimization with Jacobian-free Likelihood Ratios
Pith reviewed 2026-06-27 22:45 UTC · model grok-4.3
The pith
GenPO++ makes flow-based generative policies usable for exact on-policy RL by computing likelihood ratios from fixed solver coefficients alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A reversible generative policy optimization framework that uses history states as auxiliary memory in a high-order reversible ODE solver yields exact inversion without changing the original action dimension; the resulting generative policy map has a log-determinant determined only by fixed solver coefficients, enabling exact and Jacobian-free likelihood-ratio computation.
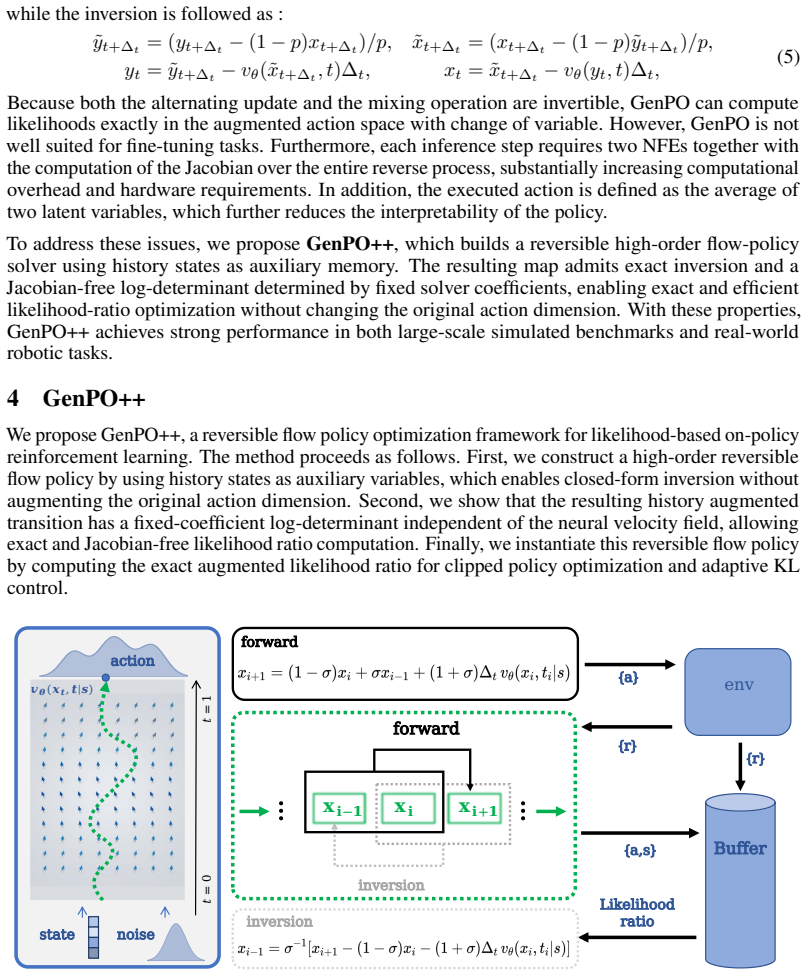
What carries the argument
High-order reversible ODE solver that stores history states as auxiliary memory to invert the generative transport map exactly while leaving the action dimension unchanged.
If this is right
- On-policy updates for flow policies become unbiased because the true action density ratio is recovered.
- No extra dummy dimensions are needed, so memory and compute scale with the original action size.
- Training stability improves because the likelihood ratio is exact rather than approximated.
- The same solver coefficients can be reused across environments without retuning the density term.
Where Pith is reading between the lines
- The approach could be combined with any black-box high-order reversible integrator that admits an explicit inverse, not only the one used in the experiments.
- Because the log-determinant is independent of the learned vector field, the method may transfer to other transport-map families whose Jacobians are otherwise intractable.
- In settings where action dimension is already large, the constant memory cost of the history buffer may still be cheaper than the quadratic cost of dummy-action augmentation.
Load-bearing premise
History states stored by the reversible ODE solver allow exact inversion of the generative policy without approximation error or change to the action space.
What would settle it
Run the same policy forward and backward through the solver on a held-out trajectory; if the recovered initial noise differs from the true noise by more than floating-point tolerance, or if the computed log-determinant changes when solver coefficients are altered, the exact-inversion claim fails.
Figures









read the original abstract
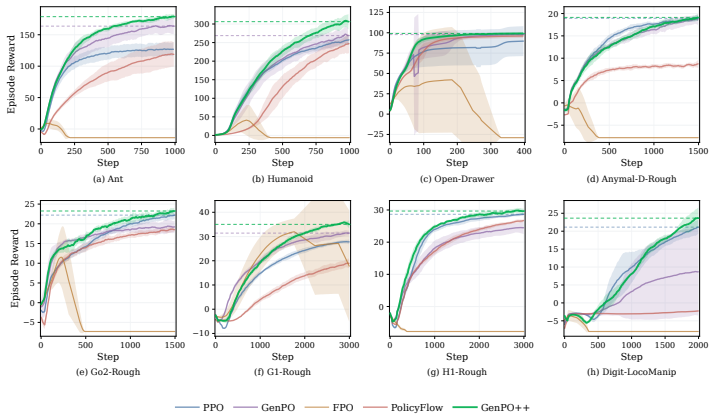
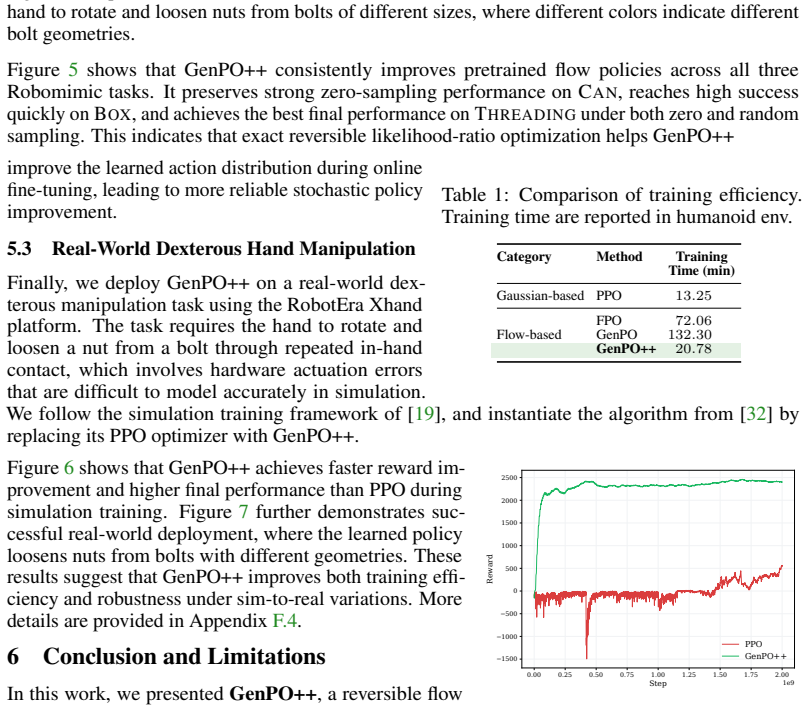
Generative policies provide expressive and multimodal action distributions, making them attractive for reinforcement learning (RL) in complex continuous-control tasks. Among them, flow-based policies are especially appealing because they generate actions through deterministic transport maps. However, applying such generative policies to likelihood-based on-policy learning remains limited by the difficulty of evaluating the probability of executed actions. Existing flow RL methods either replace the true action-density ratio with approximate surrogates, which can introduce biased updates, or recover exact likelihoods through dummy-action augmentation, which enlarges the policy space and increases computation. In this work, we propose GenPO++, a reversible generative policy optimization framework that uses history states as auxiliary memory in a high-order reversible ODE solver, yielding exact inversion without changing the original action dimension. The resulting generative policy map has a log-determinant determined only by fixed solver coefficients, enabling exact and Jacobian-free likelihood-ratio computation. This design preserves the expressiveness of generative flow policies while avoiding both action ratio bias and dummy-action overhead. We evaluate GenPO++ on large-scale simulated control, fine-tuning, and real-world robotic manipulation tasks, where it achieves competitive or superior performance over state-of-the-art on-policy RL methods, while improving training stability and computational efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GenPO++, a reversible generative policy optimization framework for on-policy RL. It claims that embedding history states as auxiliary memory in a high-order reversible ODE solver produces an exactly invertible generative policy map whose log-determinant depends only on fixed solver coefficients. This enables exact, Jacobian-free likelihood-ratio evaluation while preserving the original action dimension, avoiding both surrogate bias and dummy-action augmentation. The method is evaluated on large-scale simulated control, fine-tuning, and real-world robotic manipulation tasks, where it reports competitive or superior performance and improved stability.
Significance. If the exact-inversion claim holds, the work would remove a central obstacle to deploying expressive flow-based generative policies in likelihood-based on-policy RL, offering unbiased updates without enlarging the action space. The reported gains in stability and efficiency on robotic tasks would then constitute a practical advance over existing flow-RL baselines.
major comments (2)
- [Abstract / §3] Abstract and §3 (reversible ODE solver description): the claim that history states yield exact inversion 'without changing the original action dimension' is load-bearing for the Jacobian-free likelihood result, yet the text supplies no derivation showing how the extended state of a multistep integrator is inverted while keeping the map a bijection strictly on the original action space and ensuring the log-determinant remains independent of the learned vector field.
- [§3.2] §3.2 (likelihood-ratio computation): the assertion that the log-determinant 'is determined only by fixed solver coefficients' must be accompanied by an explicit expression or proof that this quantity does not depend on the learned dynamics; without it, the Jacobian-free property cannot be verified and the exactness claim remains unsubstantiated.
minor comments (1)
- [Abstract] The abstract is dense; a short paragraph or diagram clarifying the role of the history buffer versus the action variables would improve readability for readers unfamiliar with reversible integrators.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The two major comments correctly identify that the manuscript lacks explicit derivations for the inversion of the multistep integrator and for the independence of the log-determinant. We will revise the paper to supply these.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (reversible ODE solver description): the claim that history states yield exact inversion 'without changing the original action dimension' is load-bearing for the Jacobian-free likelihood result, yet the text supplies no derivation showing how the extended state of a multistep integrator is inverted while keeping the map a bijection strictly on the original action space and ensuring the log-determinant remains independent of the learned vector field.
Authors: We agree the derivation is missing. In the revised manuscript we will add a detailed derivation (new subsection in §3 and appendix) showing that the auxiliary history states permit exact reversal of the multistep integrator while the overall transport map remains a bijection strictly on the original action coordinates; the volume scaling is shown to factor separately from the learned vector field. revision: yes
-
Referee: [§3.2] §3.2 (likelihood-ratio computation): the assertion that the log-determinant 'is determined only by fixed solver coefficients' must be accompanied by an explicit expression or proof that this quantity does not depend on the learned dynamics; without it, the Jacobian-free property cannot be verified and the exactness claim remains unsubstantiated.
Authors: We agree an explicit expression and proof are required. The revision will include the closed-form expression for the log-determinant (derived from the fixed Butcher tableau or multistep coefficients) together with the short proof that it is independent of the learned dynamics f, obtained by showing that the Jacobian of the composite flow map separates into a constant factor and a term whose determinant is unity under the reversible construction. revision: yes
Circularity Check
No circularity: new construction presented without reduction to inputs or self-citations
full rationale
The abstract and provided text introduce GenPO++ as a novel reversible ODE solver construction that uses history states for exact inversion while keeping the original action dimension. The log-determinant claim is stated as following from fixed solver coefficients rather than being fitted or renamed from prior results. No equations, self-citations, or fitted parameters are shown reducing the central claim to its own inputs by construction. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-order reversible ODE solvers admit exact inversion when supplied with auxiliary history states.
Reference graph
Works this paper leans on
-
[1]
Is Conditional Generative Modeling all you need for Decision-Making?
Anurag Ajay, Yilun Du, Abhi Gupta, Joshua Tenenbaum, Tommi Jaakkola, and Pulkit Agrawal. Is conditional generative modeling all you need for decision-making?arXiv preprint arXiv:2211.15657, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 26(209):1– 80, 2025
Michael Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 26(209):1– 80, 2025
2025
-
[3]
Invertible residual networks
Jens Behrmann, Will Grathwohl, Ricky TQ Chen, David Duvenaud, and Jörn-Henrik Jacobsen. Invertible residual networks. InInternational conference on machine learning, pages 573–582. PMLR, 2019
2019
-
[4]
Dime: Diffusion-based maximum entropy reinforcement learning
Onur Celik, Zechu Li, Denis Blessing, Ge Li, Daniel Palanicek, Jan Peters, Georgia Chalvatzaki, and Gerhard Neumann. Dime: Diffusion-based maximum entropy reinforcement learning. arXiv preprint arXiv:2502.02316, 2025
-
[5]
Chen-Hao Chao, Chien Feng, Wei-Fang Sun, Cheng-Kuang Lee, Simon See, and Chun-Yi Lee. Maximum entropy reinforcement learning via energy-based normalizing flow.arXiv preprint arXiv:2405.13629, 2024
-
[6]
Huayu Chen, Cheng Lu, Chengyang Ying, Hang Su, and Jun Zhu. Offline reinforcement learning via high-fidelity generative behavior modeling.arXiv preprint arXiv:2209.14548, 2022
-
[7]
Residual flows for invertible generative modeling.Advances in neural information processing systems, 32, 2019
Ricky TQ Chen, Jens Behrmann, David K Duvenaud, and Jörn-Henrik Jacobsen. Residual flows for invertible generative modeling.Advances in neural information processing systems, 32, 2019
2019
-
[8]
Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations.Advances in neural information processing systems, 31, 2018
2018
-
[9]
Boosting continuous control with consistency policy
Yuhui Chen, Haoran Li, and Dongbin Zhao. Boosting continuous control with consistency policy. InProceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, pages 335–344, 2024
2024
-
[10]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.arXiv preprint arXiv:2303.04137, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Diffusion-based reinforcement learning via q-weighted variational policy optimization
Shutong Ding, Ke Hu, Zhenhao Zhang, Kan Ren, Weinan Zhang, Jingyi Yu, Jingya Wang, and Ye Shi. Diffusion-based reinforcement learning via q-weighted variational policy optimization. arXiv preprint arXiv:2405.16173, 2024
-
[12]
Shutong Ding, Ke Hu, Shan Zhong, Haoyang Luo, Weinan Zhang, Jingya Wang, Jun Wang, and Ye Shi. Genpo: Generative diffusion models meet on-policy reinforcement learning.arXiv preprint arXiv:2505.18763, 2025
-
[13]
NICE: Non-linear Independent Components Estimation
Laurent Dinh, David Krueger, and Yoshua Bengio. Nice: Non-linear independent components estimation.arXiv preprint arXiv:1410.8516, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[14]
Density estimation using Real NVP
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using real nvp. arXiv preprint arXiv:1605.08803, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[15]
Maximum entropy reinforcement learning with diffusion policy.arXiv preprint arXiv:2502.11612, 2025
Xiaoyi Dong, Jian Cheng, and Xi Sheryl Zhang. Maximum entropy reinforcement learning with diffusion policy.arXiv preprint arXiv:2502.11612, 2025
-
[16]
FFJORD: Free-form Continuous Dynamics for Scalable Reversible Generative Models
Will Grathwohl, Ricky TQ Chen, Jesse Bettencourt, Ilya Sutskever, and David Duvenaud. Ffjord: Free-form continuous dynamics for scalable reversible generative models.arXiv preprint arXiv:1810.01367, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, and Sergey Levine. Idql: Implicit q-learning as an actor-critic method with diffusion policies.arXiv preprint arXiv:2304.10573, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[19]
Learning dexterous manipulation skills from imperfect simulations
Elvis Hsieh, Wen-Han Hsieh, Yen-Jen Wang, Toru Lin, Jitendra Malik, Koushil Sreenath, and Haozhi Qi. Learning dexterous manipulation skills from imperfect simulations. arXiv:2512.02011, 2025
-
[20]
Planning with Diffusion for Flexible Behavior Synthesis
Michael Janner, Yilun Du, Joshua B Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis.arXiv preprint arXiv:2205.09991, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Efficient diffusion policies for offline reinforcement learning.Advances in Neural Information Processing Systems, 36, 2024
Bingyi Kang, Xiao Ma, Chao Du, Tianyu Pang, and Shuicheng Yan. Efficient diffusion policies for offline reinforcement learning.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[22]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InAdvances in Neural Information Processing Systems, volume 35, pages 26565–26577, 2022
2022
-
[23]
Glow: Generative flow with invertible 1x1 convolutions
Durk P Kingma and Prafulla Dhariwal. Glow: Generative flow with invertible 1x1 convolutions. Advances in neural information processing systems, 31, 2018
2018
-
[24]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[26]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps. InAdvances in Neural Information Processing Systems, volume 35, pages 5775–5787, 2022
2022
-
[28]
Leveraging exploration in off-policy algorithms via normalizing flows
Bogdan Mazoure, Thang Doan, Audrey Durand, Joelle Pineau, and R Devon Hjelm. Leveraging exploration in off-policy algorithms via normalizing flows. InConference on Robot Learning, pages 430–444. PMLR, 2020
2020
-
[29]
Flow matching policy gradients.arXiv preprint arXiv:2507.21053, 2025
David McAllister, Songwei Ge, Brent Yi, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng, and Angjoo Kanazawa. Flow matching policy gradients.arXiv preprint arXiv:2507.21053, 2025
-
[30]
Flow q-learning.arXiv preprint arXiv:2502.02538, 2025
Seohong Park, Qiyang Li, and Sergey Levine. Flow q-learning.arXiv preprint arXiv:2502.02538, 2025
-
[31]
Michael Psenka, Alejandro Escontrela, Pieter Abbeel, and Yi Ma. Learning a diffusion model policy from rewards via q-score matching.arXiv preprint arXiv:2312.11752, 2023
-
[32]
In-Hand Object Rotation via Rapid Motor Adaptation
Haozhi Qi, Ashish Kumar, Roberto Calandra, Yi Ma, and Jitendra Malik. In-Hand Object Rotation via Rapid Motor Adaptation. InConference on Robot Learning (CoRL), 2022
2022
-
[33]
Diffusion Policy Policy Optimization
Allen Z Ren, Justin Lidard, Lars L Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion policy policy optimization.arXiv preprint arXiv:2409.00588, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Moritz Reuss, Maximilian Li, Xiaogang Jia, and Rudolf Lioutikov. Goal-conditioned imitation learning using score-based diffusion policies.arXiv preprint arXiv:2304.02532, 2023
-
[35]
Variational inference with normalizing flows
Danilo Rezende and Shakir Mohamed. Variational inference with normalizing flows. In International conference on machine learning, pages 1530–1538. PMLR, 2015
2015
-
[36]
Flow matching imitation learning for multi-support manipulation
Quentin Rouxel, Andrea Ferrari, Serena Ivaldi, and Jean-Baptiste Mouret. Flow matching imitation learning for multi-support manipulation. In2024 IEEE-RAS 23rd International Conference on Humanoid Robots (Humanoids), pages 528–535. IEEE, 2024. 11
2024
-
[37]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. PMLR, 2015
2015
-
[39]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[40]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[41]
MIT press, 2018
Richard S Sutton and Andrew G Barto.Reinforcement learning: An introduction. MIT press, 2018
2018
-
[42]
Boosting Trust Region Policy Optimization by Normalizing Flows Policy
Yunhao Tang and Shipra Agrawal. Boosting trust region policy optimization by normalizing flows policy.arXiv preprint arXiv:1809.10326, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
Improving and generalizing flow-based generative models with minibatch optimal transport
Alexander Tong, Kilian Fatras, Nikolay Malkin, Guillaume Huguet, Yanlei Zhang, Jarrid Rector- Brooks, Guy Wolf, and Yoshua Bengio. Improving and generalizing flow-based generative models with minibatch optimal transport.arXiv preprint arXiv:2302.00482, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Edict: Exact diffusion inversion via coupled transformations
Bram Wallace, Akash Gokul, and Nikhil Naik. Edict: Exact diffusion inversion via coupled transformations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22532–22541, 2023
2023
-
[45]
Belm: Bidirectional explicit linear multi-step sampler for exact inversion in diffusion models.Advances in Neural Information Processing Systems, 37:46118–46159, 2024
Fangyikang Wang, Hubery Yin, Yue-Jiang Dong, Huminhao Zhu, Hanbin Zhao, Hui Qian, Chen Li, et al. Belm: Bidirectional explicit linear multi-step sampler for exact inversion in diffusion models.Advances in Neural Information Processing Systems, 37:46118–46159, 2024
2024
-
[46]
Diffusion actor-critic with entropy regulator
Yinuo Wang, Likun Wang, Yuxuan Jiang, Wenjun Zou, Tong Liu, Xujie Song, Wenxuan Wang, Liming Xiao, Jiang Wu, Jingliang Duan, et al. Diffusion actor-critic with entropy regulator. Advances in Neural Information Processing Systems, 37:54183–54204, 2024
2024
-
[47]
Diffusion policies as an expressive policy class for offline reinforcement learning
Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning. InThe Eleventh International Conference on Learning Representations, 2022
2022
-
[48]
Long Yang, Zhixiong Huang, Fenghao Lei, Yucun Zhong, Yiming Yang, Cong Fang, Shiting Wen, Binbin Zhou, and Zhouchen Lin. Policy representation via diffusion probability model for reinforcement learning.arXiv preprint arXiv:2305.13122, 2023
-
[49]
Shunpeng Yang, Ben Liu, and Hua Chen. Policyflow: Policy optimization with continuous normalizing flow in reinforcement learning.arXiv preprint arXiv:2602.01156, 2026
-
[50]
Flow policy gradients for robot control.arXiv preprint arXiv:2602.02481, 2026
Brent Yi, Hongsuk Choi, Himanshu Gaurav Singh, Xiaoyu Huang, Takara E Truong, Carmelo Sferrazza, Yi Ma, Rocky Duan, Pieter Abbeel, Guanya Shi, et al. Flow policy gradients for robot control.arXiv preprint arXiv:2602.02481, 2026
-
[51]
Exact diffusion inversion via bidirectional integration approximation
Guoqiang Zhang, Jonathan P Lewis, and W Bastiaan Kleijn. Exact diffusion inversion via bidirectional integration approximation. InEuropean Conference on Computer Vision, pages 19–36. Springer, 2024
2024
-
[52]
Fast sampling of diffusion models with exponential integrator
Qinsheng Zhang and Yongxin Chen. Fast sampling of diffusion models with exponential integrator. InInternational Conference on Learning Representations, 2023
2023
-
[53]
Tonghe Zhang, Chao Yu, Sichang Su, and Yu Wang. Reinflow: Fine-tuning flow matching policy with online reinforcement learning.arXiv preprint arXiv:2505.22094, 2025
-
[54]
UniPC: A unified predictor- corrector framework for fast sampling of diffusion models
Wenliang Zhao, Linyi Bai, Yongming Rao, Jie Zhou, and Jiwen Lu. UniPC: A unified predictor- corrector framework for fast sampling of diffusion models. InAdvances in Neural Information Processing Systems, volume 36, pages 49842–49869, 2023. 12 A Algorithm Algorithm 1GenPO++ Input:flow policy vθ(x, s, t) with base density ˜p0(z), value network Vω(s), solver...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.