CL-CLIP: CLIP-Based Continual Learning Framework with Cost-Volume Category Decoupling for Object Detection
Pith reviewed 2026-06-27 22:11 UTC · model grok-4.3
The pith
CL-CLIP uses a CLIP cost volume to split region features into class-specific pathways so open-vocabulary detectors can learn new categories continually without losing old ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CL-CLIP computes a CLIP image-text similarity cost volume that yields zero-shot category-wise response maps; these maps decompose shared region features into class-specific pathways that are then handled by a Multi-Expert RoI head, enabling continual fine-tuning on new categories while preserving competitive base-class performance on PASCAL VOC and MS-COCO.
What carries the argument
The CLIP cost volume, a set of dense category-wise response maps between visual tokens and class text embeddings, that supplies the zero-shot spatial prior for category decoupling before the multi-expert head.
If this is right
- New categories can be added with smaller drops in accuracy on previously learned classes than in standard fine-tuning.
- The zero-shot capability of the underlying CLIP detector remains usable after continual updates.
- A single training run on mixed base and novel data is no longer required to maintain balanced performance.
- Existing continual object detectors can be compared directly against this CLIP-augmented baseline on standard benchmarks.
Where Pith is reading between the lines
- The same cost-volume decoupling might reduce forgetting when other vision-language models are adapted sequentially to new visual tasks.
- If the cost volume is precomputed once and frozen, the approach could lower the memory cost of storing class-specific experts.
- Testing the framework on streaming video data would reveal whether the spatial priors remain stable when object appearances change over time.
Load-bearing premise
The zero-shot cost volume can split features into class pathways that do not themselves add extra forgetting when the experts are trained one after another.
What would settle it
Measure base-class mAP after sequential training on new classes; if the drop is nearly as large with the multi-expert head as with a single shared head, the claimed decoupling benefit is absent.
Figures

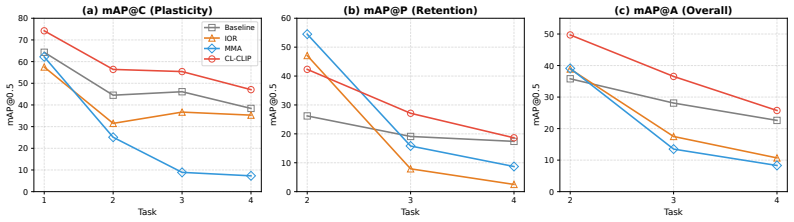
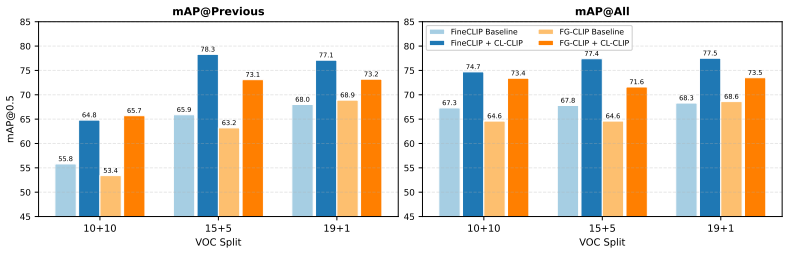

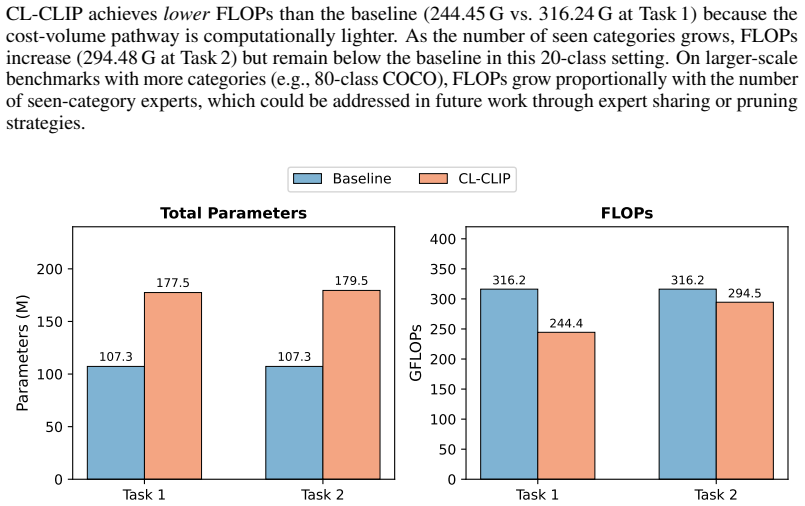
read the original abstract
Continual Object Detection (COD) requires a detector to acquire new categories over time while preserving previously learned ones. This goal is closely related to open-vocabulary detection, since both settings require reasoning over categories that are not fully covered by the annotations available at the current training stage. Recent CLIP-based open-vocabulary detectors have shown strong zero-shot generalization, and frameworks such as F-ViT demonstrate that vision-language pretraining can provide powerful zero-shot detection ability for unseen categories. However, real-world deployments cannot remain purely zero-shot: once these detectors are continually updated on newly introduced categories, they suffer severe catastrophic forgetting and quickly lose their previously calibrated detection ability. We therefore propose CL-CLIP, a CLIP-based COD framework that equips open-vocabulary detectors with better continual learning ability through cost-volume-guided category decoupling. Specifically, following CAT-Seg, we compute a CLIP image-text similarity cost volume, defined as dense category-wise response maps between visual tokens and class text embeddings. This zero-shot spatial prior decomposes shared region features into class-specific pathways, which are then processed by a Multi-Expert RoI head. Extensive experiments on PASCAL VOC and MS-COCO show that CL-CLIP substantially improves the F-ViT baseline under continual fine-tuning and achieves competitive performance with existing continual object detectors, especially in adapting to newly introduced categories while preserving competitive base-class performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CL-CLIP, a CLIP-based continual object detection framework that augments open-vocabulary detectors (e.g., F-ViT) with cost-volume-guided category decoupling. Following CAT-Seg, it computes a zero-shot CLIP image-text similarity cost volume as dense category-wise response maps between visual tokens and class text embeddings. This prior is claimed to decompose shared region features into class-specific pathways that are then fed to a Multi-Expert RoI head, enabling sequential training on new categories while mitigating catastrophic forgetting on base classes. Experiments on PASCAL VOC and MS-COCO are reported to show substantial gains over the F-ViT baseline and competitive results versus existing continual object detectors.
Significance. If the cost-volume decoupling demonstrably isolates pathways without cross-expert leakage or feature drift, the approach would offer a lightweight way to retrofit existing CLIP-based open-vocabulary detectors for continual learning, addressing a practical deployment gap. The reliance on a fixed external CLIP prior without new trainable parameters is a methodological strength that could generalize beyond the tested datasets.
major comments (3)
- [Method] Method section (description of Multi-Expert RoI head and training protocol): the manuscript supplies no details on expert freezing, gradient routing, or whether the cost volume is recomputed/held fixed when new class text embeddings are introduced. Without this, it is impossible to verify that the claimed class-specific pathways actually block interference during sequential training, which is load-bearing for the improvement over F-ViT.
- [Experiments] Experiments section: no ablation is presented that isolates the contribution of the cost-volume decoupling (e.g., comparing against a version with shared pathways or random decoupling). The central claim that the zero-shot spatial prior “decomposes shared region features into class-specific pathways” therefore rests on an untested assumption about isolation quality, especially for novel categories where CLIP priors may be weaker.
- [Abstract] Abstract and results: the statements of “substantially improves the F-ViT baseline” and “competitive performance” are not accompanied by any quantitative tables, per-class metrics, or forgetting measures in the provided text, preventing assessment of whether gains are robust or driven by post-hoc choices.
minor comments (2)
- [Abstract] The reference to “following CAT-Seg” should include a full citation and a brief recap of the cost-volume construction to make the method self-contained.
- [Method] Notation for the cost volume (e.g., how visual tokens and text embeddings are indexed) is introduced without an equation or diagram, which reduces clarity for readers unfamiliar with CAT-Seg.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where additional clarity and evidence would strengthen the manuscript. We address each major point below and commit to revisions where appropriate.
read point-by-point responses
-
Referee: [Method] Method section (description of Multi-Expert RoI head and training protocol): the manuscript supplies no details on expert freezing, gradient routing, or whether the cost volume is recomputed/held fixed when new class text embeddings are introduced. Without this, it is impossible to verify that the claimed class-specific pathways actually block interference during sequential training, which is load-bearing for the improvement over F-ViT.
Authors: We agree that the current method description lacks sufficient implementation details on these aspects. In the revised manuscript we will expand Section 3 to explicitly state: the CLIP cost volume is computed once per image using the fixed pre-trained CLIP encoder (no gradients flow through it) and is held fixed throughout training of a given task; when a new task introduces additional class text embeddings they are simply appended to the existing set and the volume is recomputed only for the new embeddings; each expert in the Multi-Expert RoI head is trained exclusively on its assigned category and then frozen; gradient routing occurs by selecting the expert corresponding to the argmax of the per-region cost-volume response, thereby enforcing class-specific pathways. These clarifications will allow readers to verify the isolation mechanism. revision: yes
-
Referee: [Experiments] Experiments section: no ablation is presented that isolates the contribution of the cost-volume decoupling (e.g., comparing against a version with shared pathways or random decoupling). The central claim that the zero-shot spatial prior “decomposes shared region features into class-specific pathways” therefore rests on an untested assumption about isolation quality, especially for novel categories where CLIP priors may be weaker.
Authors: We acknowledge that a targeted ablation isolating the decoupling mechanism is absent. While the main experiments already contrast CL-CLIP against the F-ViT baseline (which uses shared pathways), this does not fully isolate the cost-volume component. We will add a new ablation subsection that (i) replaces the cost-volume routing with a shared expert and with random expert assignment, and (ii) reports results separately on base and novel categories to examine isolation quality when CLIP priors are weaker. The revised paper will include these results. revision: yes
-
Referee: [Abstract] Abstract and results: the statements of “substantially improves the F-ViT baseline” and “competitive performance” are not accompanied by any quantitative tables, per-class metrics, or forgetting measures in the provided text, preventing assessment of whether gains are robust or driven by post-hoc choices.
Authors: The full manuscript contains Tables 1–4 in the experiments section that report mAP, per-class AP, and forgetting metrics on both PASCAL VOC and MS-COCO splits, directly supporting the abstract claims. The provided excerpt may have omitted these tables. To improve accessibility we will add a short “key results” paragraph immediately after the abstract that highlights the main numerical gains (e.g., +X mAP over F-ViT on VOC, forgetting reduced by Y %) while keeping the abstract itself concise. revision: partial
Circularity Check
No significant circularity; empirical claims rest on external CLIP and standard benchmarks
full rationale
The paper's central contribution is an empirical framework (CL-CLIP) that applies a fixed zero-shot cost volume from a pre-trained CLIP model (following CAT-Seg) to decompose features for a multi-expert RoI head, then reports performance gains on PASCAL VOC and MS-COCO against the F-ViT baseline. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The cost-volume definition is a direct computation from external embeddings, not a self-referential construct, and the continual-learning improvements are measured externally rather than forced by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ior: Inversed objects replay for incremental object detection
Zijia An, Boyu Diao, Libo Huang, Ruiqi Liu, Zhulin An, and Yongjun Xu. Ior: Inversed objects replay for incremental object detection. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
2025
-
[2]
Preventing catastrophic forgetting through memory networks in continuous detection
Gaurav Bhatt, James Ross, and Leonid Sigal. Preventing catastrophic forgetting through memory networks in continuous detection. InEuropean Conference on Computer Vision, pages 442–458. Springer, 2024
2024
-
[3]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean conference on computer vision, pages 213–229. Springer, 2020. 9
2020
-
[4]
Modeling missing annotations for incremental learning in object detection
Fabio Cermelli, Antonino Geraci, Dario Fontanel, and Barbara Caputo. Modeling missing annotations for incremental learning in object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3700–3710, 2022
2022
-
[5]
MMDetection: Open MMLab Detection Toolbox and Benchmark
Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, et al. Mmdetection: Open mmlab detection toolbox and benchmark. arxiv 2019. arXiv preprint arXiv:1906.07155, 5, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[6]
Cat-seg: Cost aggregation for open-vocabulary semantic segmentation
Seokju Cho, Heeseong Shin, Sunghwan Hong, Anurag Arnab, Paul Hongsuck Seo, and Seungryong Kim. Cat-seg: Cost aggregation for open-vocabulary semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4113–4123, 2024
2024
-
[7]
The pascal visual object classes (voc) challenge.International journal of computer vision, 88(2):303–338, 2010
Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge.International journal of computer vision, 88(2):303–338, 2010
2010
-
[8]
Overcoming catastrophic forgetting in incremental object detection via elastic response distillation
Tao Feng, Mang Wang, and Hangjie Yuan. Overcoming catastrophic forgetting in incremental object detection via elastic response distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9427–9436, 2022
2022
-
[9]
Ow-detr: Open-world detection transformer
Akshita Gupta, Sanath Narayan, KJ Joseph, Salman Khan, Fahad Shahbaz Khan, and Mubarak Shah. Ow-detr: Open-world detection transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9235–9244, 2022
2022
-
[10]
Incremental object detection with clip.arXiv preprint arXiv:2310.08815, 2023
Ziyue Huang, Yupeng He, Qingjie Liu, and Yunhong Wang. Incremental object detection with clip.arXiv preprint arXiv:2310.08815, 2023
-
[11]
Fineclip: Self-distilled region-based clip for better fine-grained understanding.Advances in Neural Information Processing Systems, 37:27896–27918, 2024
Dong Jing, Xiaolong He, Yutian Luo, Nanyi Fei, Guoxing Yang, Wei Wei, Huiwen Zhao, and Zhiwu Lu. Fineclip: Self-distilled region-based clip for better fine-grained understanding.Advances in Neural Information Processing Systems, 37:27896–27918, 2024
2024
-
[12]
Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
2017
-
[13]
Weicheng Kuo, Yin Cui, Xiuye Gu, AJ Piergiovanni, and Anelia Angelova. F-vlm: Open-vocabulary object detection upon frozen vision and language models.arXiv preprint arXiv:2209.15639, 2022
-
[14]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10965–10975, 2022
2022
-
[15]
Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017
2017
-
[16]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[17]
Feature pyramid networks for object detection
Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017
2017
-
[18]
Incdet: In defense of elastic weight consolidation for incremental object detection.IEEE transactions on neural networks and learning systems, 32(6):2306–2319, 2020
Liyang Liu, Zhanghui Kuang, Yimin Chen, Jing-Hao Xue, Wenming Yang, and Wayne Zhang. Incdet: In defense of elastic weight consolidation for incremental object detection.IEEE transactions on neural networks and learning systems, 32(6):2306–2319, 2020
2020
-
[19]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pages 38–55. Springer, 2024
2024
-
[20]
Augmented box replay: Overcoming foreground shift for incremental object detection
Yuyang Liu, Yang Cong, Dipam Goswami, Xialei Liu, and Joost Van De Weijer. Augmented box replay: Overcoming foreground shift for incremental object detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 11367–11377, 2023
2023
-
[21]
Gradient decomposition and alignment for incremental object detection
Wenlong Luo, Shizhou Zhang, De Cheng, Yinghui Xing, Guoqiang Liang, Peng Wang, and Yanning Zhang. Gradient decomposition and alignment for incremental object detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4486–4495, 2025. 10
2025
-
[22]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[23]
Faster ilod: Incremental learning for object detectors based on faster rcnn.Pattern recognition letters, 140:109–115, 2020
Can Peng, Kun Zhao, and Brian C Lovell. Faster ilod: Incremental learning for object detectors based on faster rcnn.Pattern recognition letters, 140:109–115, 2020
2020
-
[24]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021
2021
-
[25]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017
2001
-
[26]
Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information processing systems, 28, 2015
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information processing systems, 28, 2015
2015
-
[27]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale.arXiv preprint arXiv:2303.15389, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Siglip 2: Multilingual vision-language encoders with improved semantic understanding.Localization, and Dense Features, 6, 2025
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding.Localization, and Dense Features, 6, 2025
2025
-
[29]
Gcd: Advancing vision-language models for incremental object detection via global alignment and correspondence distillation
Xu Wang, Zilei Wang, and Zihan Lin. Gcd: Advancing vision-language models for incremental object detection via global alignment and correspondence distillation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 8015–8023, 2025
2025
-
[30]
Cbam: Convolutional block attention module
Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. Cbam: Convolutional block attention module. InProceedings of the European conference on computer vision (ECCV), pages 3–19, 2018
2018
-
[31]
Qirui Wu, Shizhou Zhang, De Cheng, Yinghui Xing, Di Xu, Peng Wang, and Yanning Zhang. Demystifying catastrophic forgetting in two-stage incremental object detector.arXiv preprint arXiv:2502.05540, 2025
-
[32]
Group normalization
Yuxin Wu and Kaiming He. Group normalization. InProceedings of the European conference on computer vision (ECCV), pages 3–19, 2018
2018
-
[33]
Fg-clip: Fine-grained visual and textual alignment.arXiv preprint arXiv:2505.05071, 2025
Chunyu Xie, Bin Wang, Fanjing Kong, Jincheng Li, Dawei Liang, Gengshen Zhang, Dawei Leng, and Yuhui Yin. Fg-clip: Fine-grained visual and textual alignment.arXiv preprint arXiv:2505.05071, 2025
-
[34]
Continual object detection via prototypical task correlation guided gating mechanism
Binbin Yang, Xinchi Deng, Han Shi, Changlin Li, Gengwei Zhang, Hang Xu, Shen Zhao, Liang Lin, and Xiaodan Liang. Continual object detection via prototypical task correlation guided gating mechanism. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9255–9264, 2022
2022
-
[35]
Pseudo object replay and mining for incremental object detection
Dongbao Yang, Yu Zhou, Xiaopeng Hong, Aoting Zhang, Xin Wei, Linchengxi Zeng, Zhi Qiao, and Weipinng Wang. Pseudo object replay and mining for incremental object detection. InProceedings of the 31st ACM International Conference on Multimedia, pages 153–162, 2023
2023
-
[36]
Huahui Yi, Wei Xu, Ziyuan Qin, Xi Chen, Xiaohu Wu, Kang Li, and Qicheng Lao. idpa: Instance decoupled prompt attention for incremental medical object detection.arXiv preprint arXiv:2506.00406, 2025
-
[37]
Sylph: A hypernetwork framework for incremental few-shot object detection
Li Yin, Juan M Perez-Rua, and Kevin J Liang. Sylph: A hypernetwork framework for incremental few-shot object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9035–9045, 2022
2022
-
[38]
Learning task-aware language-image representation for class-incremental object detection
Hongquan Zhang, Bin-Bin Gao, Yi Zeng, Xudong Tian, Xin Tan, Zhizhong Zhang, Yanyun Qu, Jun Liu, and Yuan Xie. Learning task-aware language-image representation for class-incremental object detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 7096–7104, 2024
2024
-
[39]
Limitations
Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. Regionclip: Region-based language-image pretraining. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16793–16803, 2022. 11 A Baseline Results on Two-Stage Benchmarks Tab. 7 an...
2022
-
[40]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects 21 Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.